当磁盘容量接近或者超过 mon_osd_full_ratio 时,该怎么去扩容?
本文主要讲述在ceph运行过程中,当磁盘容量接近或者超过mon_osd_full_ratio时,在整个ceph集群拒绝任何读写的情况下如何去扩容这样一个问题。文章主要包括如下几个部分:
- 环境介绍
- 故障模拟
- 故障解决
- 环境恢复
- 总结
1. 环境介绍
当前我们共有9个OSD,每一个OSD有50G的硬盘空间。
[root@ceph001-node1 build]# ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -10 1.34999 failure-domain sata-00 -9 1.34999 replica-domain replica-0 -8 0.45000 host-domain host-group-0-rack-01 -6 0.45000 host ceph001-node1 0 0.14999 osd.0 up 1.00000 1.00000 1 0.14999 osd.1 up 1.00000 1.00000 2 0.14999 osd.2 up 1.00000 1.00000 -11 0.45000 host-domain host-group-0-rack-02 -2 0.45000 host ceph001-node2 3 0.14999 osd.3 up 1.00000 1.00000 4 0.14999 osd.4 up 1.00000 1.00000 5 0.14999 osd.5 up 1.00000 1.00000 -12 0.45000 host-domain host-group-0-rack-03 -4 0.45000 host ceph001-node3 6 0.14999 osd.6 up 1.00000 1.00000 7 0.14999 osd.7 up 1.00000 1.00000 8 0.14999 osd.8 up 1.00000 1.00000 -1 1.34999 root default -3 0.45000 rack rack-02 -2 0.45000 host ceph001-node2 3 0.14999 osd.3 up 1.00000 1.00000 4 0.14999 osd.4 up 1.00000 1.00000 5 0.14999 osd.5 up 1.00000 1.00000 -5 0.45000 rack rack-03 -4 0.45000 host ceph001-node3 6 0.14999 osd.6 up 1.00000 1.00000 7 0.14999 osd.7 up 1.00000 1.00000 8 0.14999 osd.8 up 1.00000 1.00000 -7 0.45000 rack rack-01 -6 0.45000 host ceph001-node1 0 0.14999 osd.0 up 1.00000 1.00000 1 0.14999 osd.1 up 1.00000 1.00000 2 0.14999 osd.2 up 1.00000 1.00000
2. 故障模拟
在故障模拟之前,我们仔细分析故障产生的本质原因是:ceph存储集群中数据达到或超过了mon_osd_full_ratio。 而与ceph存储集群的大小,磁盘的绝对容量是没有关系的。后面我们会看到,故障的解决虽然与mon_osd_full_ratio值的大小有一定关系,但是与绝对容量是不相关的,因此这里模拟故障时,可以不用考虑集群的大小。
如下是整个故障的模拟步骤:
2.1 调整阈值
这里我们调小阀值的原因是为了后面可以通过相应的工具填充数据以尽快达到该阀值(在磁盘容量较小的情况下,也可以不必调整)。我们主要调整mon_osd_nearfull_ratio 和 mon_osd_full_ratio两个参数。结合我们的实际环境,将mon_osd_nearfull_ratio调整为0.1(50 x 9 x 0.1=45G时产生警告),mon_osd_full_ratio调整为0.2(50 x 9 x 0.2=90G时集群为HEALTH_ERR)。
有两种方式两种不同的方式来调整这两个值,下面分别介绍:
修改方式1
修改/etc/ceph/ceph.conf配置文件,在[global] section下添加或修改这两个参数:
mon_osd_nearfull_ratio = 0.1 mon_osd_full_ratio = 0.2
修改完成后,重启所有节点上的OSD,Monitor,RGW。重启完成之后,采用如下命令查看是否更改过来:
ceph daemon mon.{mon-id} config show | grep ratio
ceph daemon osd.{num} config show | grep ratio
ceph daemon client.radosgw.{rgw-name} config show | grep ratio此处请根据集群的实际情况替换{mon-id}、{num}、{rgw-name}. 例如:
[root@ceph001-node1 ~]# ceph daemon mon.ceph001-node1 config show | grep ratio
"mon_osd_min_up_ratio": "0.3",
"mon_osd_min_in_ratio": "0.3",
"mon_cache_target_full_warn_ratio": "0.66",
"mon_osd_full_ratio": "0.2",
"mon_osd_nearfull_ratio": "0.1",
"mds_op_history_duration": "600",
"osd_backfill_full_ratio": "0.85",
"osd_pool_default_cache_target_dirty_ratio": "0.4",
"osd_pool_default_cache_target_full_ratio": "0.8",
"osd_heartbeat_min_healthy_ratio": "0.33",
"osd_scrub_interval_randomize_ratio": "0.5",
"osd_debug_drop_ping_duration": "0",
"osd_debug_drop_pg_create_duration": "1",
"osd_op_history_duration": "600",
"osd_failsafe_full_ratio": "0.97",
"osd_failsafe_nearfull_ratio": "0.9",
"osd_bench_duration": "30",
"rgw_swift_token_expiration": "86400",
修改方式2
此种方式不需要进行重启,但一定要注意命令的正确执行,不能遗漏。
1) 修改pg,mon,osd的阈值
使用如下命令修改:
ceph pg set_nearfull_ratio 0.1
ceph pg set_full_ratio 0.2
ceph tell osd.* injectargs '--mon-osd-nearfull-ratio 0.1'
ceph tell osd.* injectargs '--mon-osd-full-ratio 0.2'
ceph tell mon.* injectargs '--mon-osd-nearfull-ratio 0.1'
ceph tell mon.* injectargs '--mon-osd-full-ratio 0.2'或者:
ceph pg set_nearfull_ratio 0.1
ceph pg set_full_ratio 0.2
sudo ceph daemon mon.{mon-id} config set mon_osd_nearfull_ratio 0.1
sudo ceph daemon mon.{mon-id} config set mon_osd_full_ratio 0.2
sudo ceph daemon osd.{num} config set mon_osd_nearfull_ratio 0.1
sudo ceph daemon osd.{num} config set mon_osd_full_ratio 0.2此处请根据集群的实际情况替换{mon-id}、{num}。这里需要调整所有节点上的OSD,MON的这两个阈值。
实际上,这里最重要的是ceph pg这两个命令的执行,其他的设置并不会作为最终的受控变量参看如下:
代码片段1:
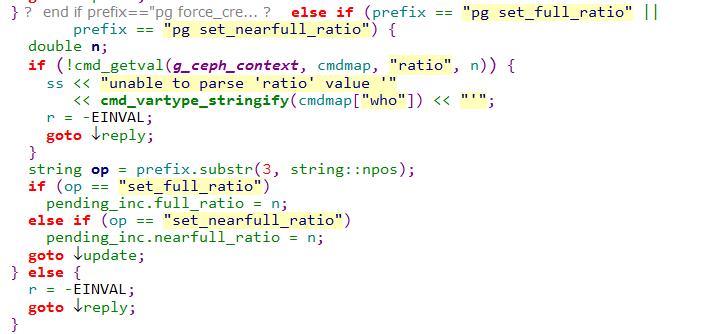
代码片段2:
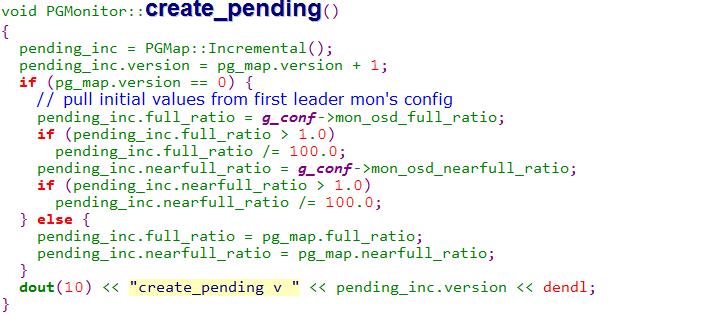 从上面我们可以看到,pending_inc是作为最终的受控变量。
从上面我们可以看到,pending_inc是作为最终的受控变量。
2) 修改rgw的阈值
sudo ceph daemon client.radosgw.{rgw-name} config set mon_osd_nearfull_ratio 0.1
sudo ceph daemon client.radosgw.{rgw-name} config set mon_osd_full_ratio 0.2此处请根据集群的实际情况替换{rgw-name}。这里需要调整所有节点上的RGW的这两个阈值。
3) 查看阈值是否修改成功
ceph daemon mon.{mon-id} config show | grep ratio
ceph daemon osd.{num} config show | grep ratio
ceph daemon client.radosgw.{rgw-name} config show | grep ratio此处请根据集群的实际情况替换{mon-id}、{num}、{rgw-name}:
[root@ceph001-node1 ~]# ceph daemon mon.ceph001-node1 config show | grep ratio
"mon_osd_min_up_ratio": "0.3",
"mon_osd_min_in_ratio": "0.3",
"mon_cache_target_full_warn_ratio": "0.66",
"mon_osd_full_ratio": "0.2",
"mon_osd_nearfull_ratio": "0.1",
"mds_op_history_duration": "600",
"osd_backfill_full_ratio": "0.85",
"osd_pool_default_cache_target_dirty_ratio": "0.4",
"osd_pool_default_cache_target_full_ratio": "0.8",
"osd_heartbeat_min_healthy_ratio": "0.33",
"osd_scrub_interval_randomize_ratio": "0.5",
"osd_debug_drop_ping_duration": "0",
"osd_debug_drop_pg_create_duration": "1",
"osd_op_history_duration": "600",
"osd_failsafe_full_ratio": "0.97",
"osd_failsafe_nearfull_ratio": "0.9",
"osd_bench_duration": "30",
"rgw_swift_token_expiration": "86400",
2.2 建立测试pool
sudo ceph osd pool create benchmark 256 256
sudo ceph osd pool set benchmark crush_ruleset 5
sudo ceph osd pool set benchmark size 3
sudo ceph osd pool set benchmark min_size 2
rados -p benchmark df 建立后如下命令查看:
[root@ceph001-node1 ~]# ceph osd dump
epoch 122
fsid ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
created 2017-07-19 14:47:13.802418
modified 2017-07-20 18:29:51.888154
flags
pool 1 'rbd-01' replicated size 3 min_size 2 crush_ruleset 5 object_hash rjenkins pg_num 128 pgp_num 128 last_change 61 flags hashpspool stripe_width 0
removed_snaps [1~3]
pool 20 'benchmark' replicated size 3 min_size 2 crush_ruleset 5 object_hash rjenkins pg_num 256 pgp_num 256 last_change 122 flags hashpspool stripe_width 0
max_osd 9
2.3 向pool中写数据
重复执行如下命令,向benchmark池中写数据:
rados bench -p benchmark 480 write --no-cleanup2.4 观察ceph集群状态
采用如下命令随时观察集群状态:
ceph -s
ceph -w
ceph df
ceph osd df这里需要重点观察集群磁盘的使用率,与设定的mon_osd_nearfull_ratio和mon_osd_full_ratio做比较。下面我们集群状态变化的几个关键节点:
1) 集群状态由HEALTH_OK->HEALTH_WARN
数据不断的写入到benchmark池中,当至少有一个OSD的磁盘使用率超过了我们设置的mon_osd_nearfull_ration 0.1时,集群就会报告处于HEALTH_WARNING。
[root@ceph001-node2 test]# ceph osd df
ID WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR
0 0.14999 1.00000 51174M 5025M 46148M 9.82 1.07
1 0.14999 1.00000 51174M 5100M 46073M 9.97 1.08
2 0.14999 1.00000 51174M 4164M 47009M 8.14 0.88
3 0.14999 1.00000 51174M 4171M 47002M 8.15 0.89
4 0.14999 1.00000 51174M 4680M 46493M 9.15 0.99
5 0.14999 1.00000 51174M 5246M 45927M 10.25 1.11
6 0.14999 1.00000 51174M 4792M 46381M 9.36 1.02
7 0.14999 1.00000 51174M 5079M 46094M 9.93 1.08
8 0.14999 1.00000 51174M 4147M 47026M 8.10 0.88
3 0.14999 1.00000 51174M 4171M 47002M 8.15 0.89
4 0.14999 1.00000 51174M 4680M 46493M 9.15 0.99
5 0.14999 1.00000 51174M 5246M 45927M 10.25 1.11
6 0.14999 1.00000 51174M 4792M 46381M 9.36 1.02
7 0.14999 1.00000 51174M 5079M 46094M 9.93 1.08
8 0.14999 1.00000 51174M 4147M 47026M 8.10 0.88
0 0.14999 1.00000 51174M 5025M 46148M 9.82 1.07
1 0.14999 1.00000 51174M 5100M 46073M 9.97 1.08
2 0.14999 1.00000 51174M 4164M 47009M 8.14 0.88
TOTAL 449G 42407M 408G 9.21
MIN/MAX VAR: 0.88/1.11 STDDEV: 0.82
[root@ceph001-node2 test]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_WARN
1 near full osd(s)
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e122: 9 osds: 9 up, 9 in
pgmap v4942: 744 pgs, 16 pools, 12984 MB data, 3293 objects
42422 MB used, 408 GB / 449 GB avail
744 active+clean
client io 24454 kB/s wr, 5 op/s
如上所示,OSD.5的磁盘使用率达到了10.25%,已经超过了我们设置的警戒阈值10%,因此集群报告状态为HEALTH_WARNING。但是此时仍可以向benchmark中写入数据,也可以从benchmark中读数据。
此后,随着数据的继续写入,处于near full osd状态的OSD数目不断增加。
2) 集群状态由HEALTH_WARN转为HEALTH_ERR
随着数据的继续写入,当至少一个OSD的磁盘使用率超过了我们设置的mon_osd_full_ratio时,集群就会报告处于HEALTH_ERR状态:
[root@ceph001-node2 test]# ceph osd df
ID WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR
0 0.14999 1.00000 51174M 9673M 41500M 18.90 1.03
1 0.14999 1.00000 51174M 10267M 40906M 20.06 1.10
2 0.14999 1.00000 51174M 8143M 43030M 15.91 0.87
3 0.14999 1.00000 51174M 8424M 42749M 16.46 0.90
4 0.14999 1.00000 51174M 9598M 41575M 18.76 1.03
5 0.14999 1.00000 51174M 10029M 41144M 19.60 1.07
6 0.14999 1.00000 51174M 9848M 41325M 19.24 1.05
7 0.14999 1.00000 51174M 10056M 41117M 19.65 1.07
8 0.14999 1.00000 51174M 8163M 43010M 15.95 0.87
3 0.14999 1.00000 51174M 8424M 42749M 16.46 0.90
4 0.14999 1.00000 51174M 9598M 41575M 18.76 1.03
5 0.14999 1.00000 51174M 10029M 41144M 19.60 1.07
6 0.14999 1.00000 51174M 9848M 41325M 19.24 1.05
7 0.14999 1.00000 51174M 10056M 41117M 19.65 1.07
8 0.14999 1.00000 51174M 8163M 43010M 15.95 0.87
0 0.14999 1.00000 51174M 9673M 41500M 18.90 1.03
1 0.14999 1.00000 51174M 10267M 40906M 20.06 1.10
2 0.14999 1.00000 51174M 8143M 43030M 15.91 0.87
TOTAL 449G 84204M 367G 18.28
MIN/MAX VAR: 0.87/1.10 STDDEV: 1.59
[root@ceph001-node2 test]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_ERR
1 full osd(s)
8 near full osd(s)
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e123: 9 osds: 9 up, 9 in
flags full
pgmap v5170: 744 pgs, 16 pools, 26652 MB data, 6710 objects
84557 MB used, 367 GB / 449 GB avail
744 active+clean
client io 49688 kB/s wr, 12 op/s
此时数据再也写入不进去了。此时我们可以通过如下方式查看,集群的整体磁盘使用率再不能增加了:
[root@ceph001-node2 test]# ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
449G 367G 84142M 18.27
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd-01 1 8 0 119G 1
.rgw 2 0 0 119G 0
.rgw.root 3 848 0 119G 3
.rgw.control 4 0 0 119G 8
.rgw.gc 5 0 0 119G 32
.log 6 0 0 119G 0
.intent-log 7 0 0 119G 0
.usage 8 0 0 119G 0
.users 9 9 0 119G 1
.users.email 10 0 0 119G 0
.users.swift 11 0 0 119G 0
.users.uid 12 394 0 119G 1
.rgw.buckets 13 0 0 119G 0
.rgw.buckets.index 14 0 0 119G 0
.rgw.buckets.extra 15 0 0 119G 0
benchmark 20 26652M 17.36 119G 6664
如上所示,当前保持17.36%的使用率不再变化(比较的是单个OSD的磁盘使用率,而非整体磁盘使用率,因此这里小于我们设定的20%是可以的)。
当集群处于此状态下,我们尝试从benchmark池中读取数据。先从池中获取到一个对象的名称:
rados -p benchmark ls然后从池中读取数据:
rados -p benchmark get {object-name} {output-file}例如:
[root@ceph001-node2 test]# rados -p benchmark get benchmark_data_ceph001-node1_10724_object742 output.bin [root@ceph001-node2 test]# ls output.bin
3) 集群reblance
当集群处于HEALTH_ERR状态后,我们停止写入数据。等待一段时间,你会观察到系统有可能会从HEALTH_ERR状态又变回HEALTH_WARN状态:
[root@ceph001-node2 test]# ceph osd df
ID WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR
0 0.14999 1.00000 51174M 9256M 41917M 18.09 1.04
1 0.14999 1.00000 51174M 9855M 41318M 19.26 1.10
2 0.14999 1.00000 51174M 7719M 43454M 15.08 0.86
3 0.14999 1.00000 51174M 8023M 43150M 15.68 0.90
4 0.14999 1.00000 51174M 9178M 41995M 17.94 1.03
5 0.14999 1.00000 51174M 9629M 41544M 18.82 1.08
6 0.14999 1.00000 51174M 9403M 41770M 18.38 1.05
7 0.14999 1.00000 51174M 9664M 41509M 18.89 1.08
8 0.14999 1.00000 51174M 7758M 43415M 15.16 0.87
3 0.14999 1.00000 51174M 8023M 43150M 15.68 0.90
4 0.14999 1.00000 51174M 9178M 41995M 17.94 1.03
5 0.14999 1.00000 51174M 9629M 41544M 18.82 1.08
6 0.14999 1.00000 51174M 9403M 41770M 18.38 1.05
7 0.14999 1.00000 51174M 9664M 41509M 18.89 1.08
8 0.14999 1.00000 51174M 7758M 43415M 15.16 0.87
0 0.14999 1.00000 51174M 9256M 41917M 18.09 1.04
1 0.14999 1.00000 51174M 9855M 41318M 19.26 1.10
2 0.14999 1.00000 51174M 7719M 43454M 15.08 0.86
TOTAL 449G 80490M 371G 17.48
MIN/MAX VAR: 0.86/1.10 STDDEV: 1.59
[root@ceph001-node2 test]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_WARN
9 near full osd(s)
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e124: 9 osds: 9 up, 9 in
pgmap v5224: 744 pgs, 16 pools, 26664 MB data, 6713 objects
80490 MB used, 371 GB / 449 GB avail
744 active+clean
这是因为,集群会进行rebalance,原来有些OSD的磁盘使用率超过了设定的mon_osd_full_ratio值,经过reblance后有可能重新回调到较小的值。
此时集群为HEALTH_WARN状态,可以进行数据读写。
为了模拟我们的故障,我们可以继续调用rados bench向池中写入数据,直到集群又变为HEALTH_ERR状态。反复执行这个过程,直到ceph集群不能通过reblance重新恢复到HEALTH_WARN状态为止。
[root@ceph001-node2 test]# ceph osd df
ID WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR
0 0.14999 1.00000 51174M 9725M 41448M 19.01 1.03
1 0.14999 1.00000 51174M 10300M 40873M 20.13 1.09
2 0.14999 1.00000 51174M 8258M 42915M 16.14 0.88
3 0.14999 1.00000 51174M 8413M 42760M 16.44 0.89
4 0.14999 1.00000 51174M 9671M 41502M 18.90 1.03
5 0.14999 1.00000 51174M 10157M 41016M 19.85 1.08
6 0.14999 1.00000 51174M 9856M 41317M 19.26 1.05
7 0.14999 1.00000 51174M 10185M 40988M 19.90 1.08
8 0.14999 1.00000 51174M 8235M 42938M 16.09 0.87
3 0.14999 1.00000 51174M 8413M 42760M 16.44 0.89
4 0.14999 1.00000 51174M 9671M 41502M 18.90 1.03
5 0.14999 1.00000 51174M 10157M 41016M 19.85 1.08
6 0.14999 1.00000 51174M 9856M 41317M 19.26 1.05
7 0.14999 1.00000 51174M 10185M 40988M 19.90 1.08
8 0.14999 1.00000 51174M 8235M 42938M 16.09 0.87
0 0.14999 1.00000 51174M 9725M 41448M 19.01 1.03
1 0.14999 1.00000 51174M 10300M 40873M 20.13 1.09
2 0.14999 1.00000 51174M 8258M 42915M 16.14 0.88
TOTAL 449G 84804M 366G 18.41
MIN/MAX VAR: 0.87/1.09 STDDEV: 1.60
[root@ceph001-node2 test]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_ERR
1 full osd(s)
8 near full osd(s)
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e125: 9 osds: 9 up, 9 in
flags full
pgmap v5257: 744 pgs, 16 pools, 27428 MB data, 6904 objects
84923 MB used, 366 GB / 449 GB avail
744 active+clean
2.5 手动验证集群的读写特性
经过前面不断的写入数据,超过设定的mon_osd_full_ratio阈值,集群处于HEALTH_ERR状态,并且在不经过其他人工干预的情况下,集群再不能通过自动reblance恢复到HEALTH_WARN状态。我们在这一极限情况下来测试集群的读写。
1) 测试写特性
执行如下命令向benchmark中写对象数据:
[root@ceph001-node3 test]# pwd /ceph-cluster/test [root@ceph001-node3 test]# echo "hello,world" >> helloworld.txt [root@ceph001-node3 test]# cat helloworld.txt hello,world [root@ceph001-node3 test]# rados put test-object-1 ./helloworld.txt --pool=benchmark 2017-07-21 10:02:31.832149 7fb1f42e37c0 0 client.16502.objecter FULL, paused modify 0x2c0a690 tid 0 ^C
可以看到,提示client.16502.objecter 已经为FULL了,执行过程一直卡在这里。说明在此种情况下并不能再向集群中写入数据。
2) 测试读特性
从benchmark池中找出一个对象:
[root@ceph001-node3 test]# rados -p benchmark ls | less benchmark_data_ceph001-node1_10650_object229 benchmark_data_ceph001-node1_10885_object937 benchmark_data_ceph001-node1_10724_object234 benchmark_data_ceph001-node1_10724_object2268 benchmark_data_ceph001-node1_10724_object361 benchmark_data_ceph001-node1_10885_object736 benchmark_data_ceph001-node1_10885_object2084 benchmark_data_ceph001-node1_10724_object1106 benchmark_data_ceph001-node1_10885_object1563 ....
读取benchmark_data_ceph001-node1_10650_object229对象:
[root@ceph001-node3 test]# rados get benchmark_data_ceph001-node1_10650_object229 output.bin --pool=benchmark [root@ceph001-node3 test]# ls output.bin output.bin [root@ceph001-node3 test]# cat output.bin | less I'm the 229th object!^@zzzzzzzzzzzzzzzzzzzzzzzzzzzzz.....
可以看到即使在集群超过mon_osd_full_ratio的情况下,仍可以对集群进行读操作。
我们再进一步,因为当前已经集群有一个OSD已经为FULL状态,导致整个集群变为HEALTH_ERR:
[root@ceph001-node3 test]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_ERR
1 full osd(s)
8 near full osd(s)
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e127: 9 osds: 9 up, 9 in
flags full
pgmap v6139: 744 pgs, 16 pools, 27848 MB data, 7009 objects
84044 MB used, 367 GB / 449 GB avail
744 active+clean
[root@ceph001-node3 test]# ceph osd df
ID WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR
0 0.14999 1.00000 51174M 9649M 41524M 18.86 1.03
1 0.14999 1.00000 51174M 10236M 40937M 20.00 1.10
2 0.14999 1.00000 51174M 8127M 43046M 15.88 0.87
3 0.14999 1.00000 51174M 8380M 42793M 16.38 0.90
4 0.14999 1.00000 51174M 9599M 41574M 18.76 1.03
5 0.14999 1.00000 51174M 10038M 41135M 19.62 1.07
6 0.14999 1.00000 51174M 9800M 41373M 19.15 1.05
7 0.14999 1.00000 51174M 10081M 41092M 19.70 1.08
8 0.14999 1.00000 51174M 8131M 43042M 15.89 0.87
3 0.14999 1.00000 51174M 8380M 42793M 16.38 0.90
4 0.14999 1.00000 51174M 9599M 41574M 18.76 1.03
5 0.14999 1.00000 51174M 10038M 41135M 19.62 1.07
6 0.14999 1.00000 51174M 9800M 41373M 19.15 1.05
7 0.14999 1.00000 51174M 10081M 41092M 19.70 1.08
8 0.14999 1.00000 51174M 8131M 43042M 15.89 0.87
0 0.14999 1.00000 51174M 9649M 41524M 18.86 1.03
1 0.14999 1.00000 51174M 10236M 40937M 20.00 1.10
2 0.14999 1.00000 51174M 8127M 43046M 15.88 0.87
TOTAL 449G 84044M 367G 18.25
MIN/MAX VAR: 0.87/1.10 STDDEV: 1.60
从上面我们可以看到,当前OSD.1的磁盘使用量为20%,达到了我们的阈值。我们这里尝试从OSD.1中读取数据:
*查看落到OSD.1上PG:*
[root@ceph001-node3 test]# ceph pg ls-by-osd 1 | awk '{print $1,$15}'
pg_stat up_primary
1.3 [4,1,6]
1.7 [1,6,5]
1.c [1,8,4]
1.d [4,6,1]
1.13 [1,6,3]
....
20.ca [7,5,1]
20.cb [3,1,7]
20.d2 [5,6,1]
20.d3 [4,1,7]
20.d5 [8,1,3]
20.d6 [1,5,8]
20.d9 [6,4,1]
20.db [4,7,1]
20.dd [1,6,5]
20.e3 [7,5,1]
20.e7 [1,7,4]
上面我们看到有很多PG被映射到osd.1上,我们选择稍微靠后,即PG值较大的PG(根据经验PG值较小的PG里面可能数据较少或没有数据)。再选择osd.1是作为PG中的master的一个PG。这里我们选择20.dd这个pg [1,6,5].
*查看osd.1上20.dd这个pg的对象*
[root@ceph001-node1 ~]# ls /var/lib/ceph/osd/ceph-1/current/20.dd_head/ benchmark\udata\uceph001-node1\u10650\uobject137__head_7A03E2DD__14 benchmark\udata\uceph001-node1\u10885\uobject1336__head_180E08DD__14 benchmark\udata\uceph001-node1\u10650\uobject184__head_B710E4DD__14 benchmark\udata\uceph001-node1\u10885\uobject1374__head_2FF6B2DD__14 benchmark\udata\uceph001-node1\u10650\uobject392__head_BE508FDD__14 benchmark\udata\uceph001-node1\u10885\uobject137__head_02EC31DD__14 benchmark\udata\uceph001-node1\u10650\uobject506__head_2A1F5CDD__14 benchmark\udata\uceph001-node1\u10885\uobject1436__head_924142DD__14 benchmark\udata\uceph001-node1\u10724\uobject1200__head_99979DDD__14 benchmark\udata\uceph001-node1\u10885\uobject1474__head_5F26AADD__14 benchmark\udata\uceph001-node1\u10724\uobject1285__head_4283FADD__14 benchmark\udata\uceph001-node1\u10885\uobject1605__head_E3440ADD__14 benchmark\udata\uceph001-node1\u10724\uobject1518__head_11FBAEDD__14 benchmark\udata\uceph001-node1\u10885\uobject2215__head_9DB007DD__14 benchmark\udata\uceph001-node1\u10724\uobject1988__head_5FFE91DD__14 benchmark\udata\uceph001-node1\u10885\uobject2360__head_6B72CDDD__14 benchmark\udata\uceph001-node1\u10724\uobject2229__head_BD205FDD__14 benchmark\udata\uceph001-node1\u10885\uobject2521__head_CE1611DD__14 benchmark\udata\uceph001-node1\u10724\uobject2666__head_8A8A54DD__14 benchmark\udata\uceph001-node1\u10885\uobject2622__head_87EEA1DD__14 benchmark\udata\uceph001-node1\u10724\uobject2880__head_BBDFECDD__14 benchmark\udata\uceph001-node1\u10885\uobject2732__head_0CBFC3DD__14 benchmark\udata\uceph001-node1\u10724\uobject324__head_970BE7DD__14 benchmark\udata\uceph001-node1\u10885\uobject2778__head_F45A54DD__14 benchmark\udata\uceph001-node1\u10724\uobject348__head_58E3A8DD__14 benchmark\udata\uceph001-node1\u10885\uobject337__head_38C894DD__14 benchmark\udata\uceph001-node1\u10724\uobject504__head_775BFFDD__14 __head_000000DD__14 benchmark\udata\uceph001-node1\u10885\uobject1205__head_2F5C1DDD__14
*将pg副本数据移除*
这里我们为了确保是从当前为FULL状态的osd.1上读取数据,因此我们先将osd.6与osd.5上的20.dd这个pg数据移除:
[root@ceph001-node2 test]# hostname -s ceph001-node2 [root@ceph001-node2 test]# pwd /ceph-cluster/test [root@ceph001-node2 test]# mv /var/lib/ceph/osd/ceph-5/current/20.dd_head/ ./ [root@ceph001-node2 test]# ls 20.dd_head [root@ceph001-node3 test]# hostname -s ceph001-node3 [root@ceph001-node3 test]# pwd /ceph-cluster/test [root@ceph001-node3 test]# mv /var/lib/ceph/osd/ceph-6/current/20.dd_head/ ./ [root@ceph001-node3 test]# ls 20.dd_head
*读取对象数据*
此时我们再从osd.1这个FULL OSD上读取20.dd中的一个对象:
[root@ceph001-node1 ~]# rados -p benchmark ls | grep object137 benchmark_data_ceph001-node1_10885_object1378 benchmark_data_ceph001-node1_10885_object1375 benchmark_data_ceph001-node1_10885_object1376 benchmark_data_ceph001-node1_10885_object1377 benchmark_data_ceph001-node1_10724_object1372 benchmark_data_ceph001-node1_10724_object1370 benchmark_data_ceph001-node1_10885_object1379 benchmark_data_ceph001-node1_10724_object1376 benchmark_data_ceph001-node1_10724_object1379 benchmark_data_ceph001-node1_10885_object1371 benchmark_data_ceph001-node1_11080_object137 benchmark_data_ceph001-node1_10724_object1378 benchmark_data_ceph001-node1_10724_object137 benchmark_data_ceph001-node1_10885_object1372 benchmark_data_ceph001-node1_10885_object1373 benchmark_data_ceph001-node1_10885_object1370 benchmark_data_ceph001-node1_10724_object1374 benchmark_data_ceph001-node1_10724_object1377 benchmark_data_ceph001-node1_10724_object1371 benchmark_data_ceph001-node1_10724_object1375 benchmark_data_ceph001-node1_10724_object1373 benchmark_data_ceph001-node1_10885_object137 benchmark_data_ceph001-node1_10885_object1374 benchmark_data_ceph001-node1_10650_object137 #此对象为我们20.dd_head目录下的第一个对象 [root@ceph001-node1 ~]# cd /ceph-cluster/test/ [root@ceph001-node1 test]# ls [root@ceph001-node1 test]# rados get benchmark_data_ceph001-node1_10650_object137 output.bin --pool=benchmark [root@ceph001-node1 test]# ls -al total 4096 drwxrwxrwx 2 root root 23 Jul 21 10:54 . drwxrwxrwx 5 root root 44 Jul 18 17:21 .. -rw-r--r-- 1 root root 4194304 Jul 21 10:54 output.bin
如上所示,我们仍然可以从osd.1中读取数据。即FULL OSD也仍然可以读取数据。
*恢复移除的副本pg*
上面我们将osd.6及osd.5上的20.dd这两个PG副本移到了另外的地方,这里将这两个副本先进行恢复:
[root@ceph001-node2 test]# mv ./20.dd_head/ /var/lib/ceph/osd/ceph-5/current/ [root@ceph001-node3 test]# mv 20.dd_head/ /var/lib/ceph/osd/ceph-6/current/
*结论*
在整个集群因为某些FULL OSD导致处于HEALTH_ERR状态下,仍然可以从集群中正常的读取数据。
3)测试集群的删除特性
此时请确保集群仍处于FULL OSD的HEALTH_ERR状态,然后我们执行删除动作:
[root@ceph001-node1 test]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_ERR
1 full osd(s)
8 near full osd(s)
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e127: 9 osds: 9 up, 9 in
flags full
pgmap v6144: 744 pgs, 16 pools, 27848 MB data, 7009 objects
84048 MB used, 367 GB / 449 GB avail
744 active+clean
[root@ceph001-node1 test]# rados -p benchmark cleanup
2017-07-21 11:02:56.926101 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4008290 tid 1
2017-07-21 11:02:56.926114 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x40087e0 tid 2
2017-07-21 11:02:56.926216 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4008e30 tid 3
2017-07-21 11:02:56.926305 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4021aa0 tid 4
2017-07-21 11:02:56.926378 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4028f00 tid 5
2017-07-21 11:02:56.926403 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4030360 tid 6
2017-07-21 11:02:56.926415 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4030a30 tid 7
2017-07-21 11:02:56.926489 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4031100 tid 8
2017-07-21 11:02:56.926584 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4038560 tid 9
2017-07-21 11:02:56.926602 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x403f9c0 tid 10
2017-07-21 11:02:56.926615 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4040090 tid 11
2017-07-21 11:02:56.926704 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4040760 tid 12
2017-07-21 11:02:56.926781 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4047bc0 tid 13
2017-07-21 11:02:56.927128 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x404f020 tid 14
2017-07-21 11:02:56.927155 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4056480 tid 15
2017-07-21 11:02:56.927171 7f4491a667c0 0 client.16517.objecter FULL, paused modify 0x4056b50 tid 16
由上我们可以看到,集群这时候会禁止通过rados删除数据。
2.6 手动移除PG,集群状态变化
我们通过手动将当前处于FULL状态的OSD.1中的部分PG移除,来观察集群的状态变化情况:
[root@ceph001-node1 test]# mv /var/lib/ceph/osd/ceph-1/current/20.d3_head/ ./ [root@ceph001-node1 test]# mv /var/lib/ceph/osd/ceph-1/current/20.d5_head/ ./ [root@ceph001-node1 test]# ls 20.d3_head 20.d5_head
请根据自己当前的磁盘使用状况,决定本测试时需要移除的数据的多少。然后等待一段时间(根据测试,实际上这个时间主要由osd_mon_report_interval_max这个变量来决定,默认值为120),再查看集群状态:
[root@ceph001-node1 test]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_WARN
9 near full osd(s)
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e128: 9 osds: 9 up, 9 in
pgmap v6156: 744 pgs, 16 pools, 27848 MB data, 7009 objects
83795 MB used, 367 GB / 449 GB avail
744 active+clean
由此可见,当我们从那些FULL OSD移除一些数据之后,集群是可以从HEALTH_ERR状态变回HEALTH_WARN状态。进一步联想,我们如果再删除更多的数据,在集群进行scrub之前,集群会变为HEALTH_OK状况。这就为我们后续解决这以HEALTH_ERR故障提供一种思路: 我们可以将full OSD中的非master PG删除,让集群变回HEALTH_WARN状态,通过后续的扩容自动的将数据迁移走,然后通过PG的迁移状况再手动恢复删除的PG或者通过手动触发pg scrub来进行删除数据的恢复。 当然,这是在极端情况不能通过其他手段进行集群恢复的情况下,可以采用此方法
2.7 小结
在由于某些FULL OSD导致集群处于HEALTH_ERR状态时,可以对集群进行读操作,不能通过rados接口对集群进行写操作与删除操作。
3. 故障解决
通过上面的分析,当集群由于某些FULL OSD导致处于HEALTH_ERR状态时,有时候其可以通过自动rebalance恢复到HEALTH_WARN状态,有时候因为磁盘占用较为平均,并不能通过自动reblance恢复。一般情况下,集群由于OSD FULL出现HEALTH_ERR状态,这在实际运维过程中属于较为极端的情况,建议此时对集群进行隔离,禁止外界对集群的读写操作。
下面我们分三种不同的情况来解决该故障:
3.1 自动reblance可以恢复
在此种情况下,可以直接进行扩容操作,让其自动的完成数据的迁移。具体的扩容方式,请参看其他文档。
也可以参看如下3.2方式进行恢复。
3.2 调整ratio可恢复
一般情况下,我们会将mon_osd_nearfull_ratio设置为0.85,将mon_osd_full_ratio设置为0.95。当出现OSD FULL导致集群处于HEALTH_ERR状态时,我们仍有一定的空间可以调整这些ratio值,以使集群恢复到HEALTH_WARN状态。然后进行扩容操作,让集群自动的完成数据迁移。
通过如下方式调整这两个阈值:
ceph pg set_nearfull_ratio {higher-ratio-1}
ceph pg set_full_ratio {higher-ratio-2}
ceph tell osd.* injectargs '--mon-osd-nearfull-ratio {higher-ratio-1}'
ceph tell osd.* injectargs '--mon-osd-full-ratio {higher-ratio-2}'
ceph tell mon.* injectargs '--mon-osd-nearfull-ratio {higher-ratio-1}'
ceph tell mon.* injectargs '--mon-osd-full-ratio {higher-ratio-2}'
再调整所有节点rgw的这两个值:
sudo ceph daemon client.radosgw.{rgw-name} config set mon_osd_nearfull_ratio {higher-ratio-1}
sudo ceph daemon client.radosgw.{rgw-name} config set mon_osd_full_ratio {higher-ratio-2}
请根据自己的实际情况替换{higher-ratio-1}及{higher-ratio-2}这两个值,最大可取值为1.0。 {rgw-name}为radosgw用户名。
扩容并调整完阈值后,等待集群自动完成数据的迁移工作,集群恢复HEALTH_OK。
注意:
1:根绝实际情况,可能需要对如下参数也进行调整
ceph tell osd.* injectargs '--osd_failsafe_full_ratio {ratio-num}'
ceph tell mon.* injectargs '--osd_failsafe_full_ratio {ratio-num}'2:集群恢复之后,请调整mon-osd-nearfull-ratio,mon-osd-full-ratio回适当的值
3.3 删除PG恢复
一般不推荐采用此方法来修复集群,只有当mon-osd-nearfull-ratio与mon-osd-full-ratio已经没有可调空间的情况下使用。
1) 进行OSD扩容
当集群处于此种状态的HEALTH_ERR时,仍然可以进行扩容。只是在扩容后,并不能自动的进行rebalance.
[root@ceph001-node3 build]# ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -10 1.79993 failure-domain sata-00 -9 1.79993 replica-domain replica-0 -8 0.59998 host-domain host-group-0-rack-01 -6 0.59998 host ceph001-node1 0 0.14999 osd.0 up 1.00000 1.00000 1 0.14999 osd.1 up 1.00000 1.00000 2 0.14999 osd.2 up 1.00000 1.00000 9 0.14999 osd.9 up 1.00000 1.00000 -11 0.59998 host-domain host-group-0-rack-02 -2 0.59998 host ceph001-node2 3 0.14999 osd.3 up 1.00000 1.00000 4 0.14999 osd.4 up 1.00000 1.00000 5 0.14999 osd.5 up 1.00000 1.00000 10 0.14999 osd.10 up 1.00000 1.00000 -12 0.59998 host-domain host-group-0-rack-03 -4 0.59998 host ceph001-node3 6 0.14999 osd.6 up 1.00000 1.00000 7 0.14999 osd.7 up 1.00000 1.00000 8 0.14999 osd.8 up 1.00000 1.00000 11 0.14999 osd.11 up 1.00000 1.00000 -1 1.79993 root default -3 0.59998 rack rack-02 -2 0.59998 host ceph001-node2 3 0.14999 osd.3 up 1.00000 1.00000 4 0.14999 osd.4 up 1.00000 1.00000 5 0.14999 osd.5 up 1.00000 1.00000 10 0.14999 osd.10 up 1.00000 1.00000 -5 0.59998 rack rack-03 -4 0.59998 host ceph001-node3 6 0.14999 osd.6 up 1.00000 1.00000 7 0.14999 osd.7 up 1.00000 1.00000 8 0.14999 osd.8 up 1.00000 1.00000 11 0.14999 osd.11 up 1.00000 1.00000 -7 0.59998 rack rack-01 -6 0.59998 host ceph001-node1 0 0.14999 osd.0 up 1.00000 1.00000 1 0.14999 osd.1 up 1.00000 1.00000 2 0.14999 osd.2 up 1.00000 1.00000 9 0.14999 osd.9 up 1.00000 1.00000
扩容后,集群状态为:
[root@ceph001-node3 build]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_ERR
48 pgs degraded
187 pgs peering
11 pgs recovering
9 pgs recovery_wait
156 pgs stuck inactive
287 pgs stuck unclean
recovery 1640/21493 objects degraded (7.630%)
recovery 865/21493 objects misplaced (4.025%)
3 full osd(s)
6 near full osd(s)
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e247: 12 osds: 12 up, 12 in; 63 remapped pgs
flags full
pgmap v6810: 744 pgs, 16 pools, 28444 MB data, 7152 objects
107 GB used, 492 GB / 599 GB avail
1640/21493 objects degraded (7.630%)
865/21493 objects misplaced (4.025%)
416 active+clean
136 peering
51 remapped+peering
45 active+remapped
45 activating
27 activating+degraded
10 active+recovering+degraded
6 active+recovery_wait+degraded+remapped
3 active+recovery_wait+degraded
1 active+degraded
1 remapped
1 active+recovering+degraded+remapped
1 active
1 inactive
recovery io 9347 kB/s, 2 objects/s
2) 手动删除FULL OSD中的一些PG
使用如下命令,找出FULL OSD上的master不是其的PG,然后进行删除.
[root@ceph001-node3 build]# ceph pg ls-by-osd 1 | awk '{print $1,$15}'
pg_stat up_primary
1.3 [4,1,6]
1.7 [1,6,5]
1.c [1,8,4]
1.d [10,6,1]
1.13 [1,6,3]
1.15 [3,1,8]
1.16 [6,4,1]
1.21 [1,4,8]
...
20.b7 [1,11,3]
20.be [11,1,10]
20.c0 [10,1,11]
20.c2 [1,6,10]
20.c5 [4,11,1]
20.ca [7,5,1]
20.cb [3,1,7]
20.d2 [5,6,1]
20.d5 [11,1,3]
20.d9 [6,4,1]
20.db [4,7,1]
20.dd [1,6,5]
20.e3 [7,5,1]
20.e7 [1,7,4]
20.f9 [10,11,1]
如上是OSD.1节点上的PG,将master为非OSD.1的部分PG移除。例如,这里我们移除20.be和20.c0这两个PG:
[root@ceph001-node1 test]# mv /var/lib/ceph/osd/ceph-1/current/20.be_head/ ./ [root@ceph001-node1 test]# mv /var/lib/ceph/osd/ceph-1/current/20.c0_head/ ./ [root@ceph001-node1 test]# ls 20.be_head 20.c0_head [root@ceph001-node1 test]# pwd /ceph-cluster/test
移除后,等待一段时间(根据测试,实际上这个时间主要由osd_mon_report_interval_max这个变量来决定,默认值为120),集群恢复到HEALTH_WARN状态:
[root@ceph001-node1 test]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_WARN
12 near full osd(s)
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e288: 12 osds: 12 up, 12 in
pgmap v7166: 744 pgs, 16 pools, 35056 MB data, 8811 objects
103 GB used, 496 GB / 599 GB avail
744 active+clean
3) 等待数据的自动迁移
执行完上面的步骤,集群处于HEALTH_WARN状态后,此时数据就会进行自动的迁移。此迁移过程根据数据量的大小,耗费的时间不等。 等迁移完成后,集群恢复HEALTH_OK状态:
[root@ceph001-node1 test]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_OK
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e288: 12 osds: 12 up, 12 in
pgmap v7178: 744 pgs, 16 pools, 35056 MB data, 8811 objects
103 GB used, 496 GB / 599 GB avail
744 active+clean
4) 重新检测我们删除的PG情况
因为前面我们手动删除了一些PG(例如:20.be和20.c0),我们这里重新检视这两个PG状况:
[root@ceph001-node1 test]# ceph pg ls-by-pool benchmark | grep 20.be | awk '{print $1,$15}'
20.be [11,1,10]
[root@ceph001-node1 test]# ceph pg ls-by-pool benchmark | grep 20.c0 | awk '{print $1,$15}'
20.c0 [10,1,11]
因为我们在OSD.1上删除了这两个PG,而这两个PG目前还映射到OSD.1上。因此,我们需要检测OSD.1数据目录的这两个PG:
[root@ceph001-node1 test]# ls /var/lib/ceph/osd/ceph-1/current/ | grep 20.be [root@ceph001-node1 test]# ls /var/lib/ceph/osd/ceph-1/current/ | grep 20.c0
此处,我们看到当前集群并未发现20.be和20.c0两个PG各自少了一个副本,其显示的集群状态为HEALTH_OK,这是因为当前集群未做scrub操作。此时我们有3中方式进行处理:
方式一
不做任何处理,等待集群在后续的某个时刻自动进行repair操作。
方式二
将我们删除的数据,自己手动拷贝回相应的目录。(可能会与系统自动的repair操作冲突,但几率极小,影响不大)
方式三
采用如下命令手动触发PG repair操作(注意这里我们移除了20.be和20.c0这两个文件夹,在执行如下命令之前需先手动建立这两个空文件夹):
ceph pg repair <pgid>例如:
[root@ceph001-node1 test]# ceph pg repair 20.be instructing pg 20.be on osd.11 to repair [root@ceph001-node1 test]# ceph pg repair 20.c0 instructing pg 20.c0 on osd.10 to repair
触发后,我们可以看到集群会修复丢失的PG副本:
[root@ceph001-node2 build]# ceph -w
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_ERR
2 pgs inconsistent
79 scrub errors
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e288: 12 osds: 12 up, 12 in
pgmap v7203: 744 pgs, 16 pools, 35056 MB data, 8811 objects
103 GB used, 496 GB / 599 GB avail
742 active+clean
2 active+clean+inconsistent
2017-07-21 15:44:38.044153 osd.10 [ERR] 20.c0 repair 41 errors, 41 fixed
2017-07-21 15:44:46.895304 mon.0 [INF] pgmap v7207: 744 pgs: 744 active+clean; 35056 MB data, 103 GB used, 496 GB / 599 GB avail; 12470 kB/s, 3 objects/s recovering
2017-07-21 15:45:02.464895 mon.0 [INF] HEALTH_OK
通过ceph -s命令也可以查看到这一修复进程:
[root@ceph001-node3 ~]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_WARN
1 pgs recovering
recovery 53/26433 objects degraded (0.201%)
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e288: 12 osds: 12 up, 12 in
pgmap v7206: 744 pgs, 16 pools, 35056 MB data, 8811 objects
103 GB used, 496 GB / 599 GB avail
53/26433 objects degraded (0.201%)
743 active+clean
1 active+recovering
recovery io 12520 kB/s, 3 objects/s
[root@ceph001-node3 ~]# ceph -s
cluster ba47fcbc-b2f7-4071-9c37-be859d8c7e6e
health HEALTH_OK
monmap e1: 3 mons at {ceph001-node1=10.133.134.211:6789/0,ceph001-node2=10.133.134.212:6789/0,ceph001-node3=10.133.134.213:6789/0}
election epoch 10, quorum 0,1,2 ceph001-node1,ceph001-node2,ceph001-node3
osdmap e288: 12 osds: 12 up, 12 in
pgmap v7207: 744 pgs, 16 pools, 35056 MB data, 8811 objects
103 GB used, 496 GB / 599 GB avail
744 active+clean
recovery io 12470 kB/s, 3 objects/s
修复后,我们在查看osd.1中对应的数据目录,看被我们删除的数据是否恢复:
[root@ceph001-node1 test]# ls /var/lib/ceph/osd/ceph-1/current/ | grep 20.be 20.be_TEMP [root@ceph001-node1 test]# ls /var/lib/ceph/osd/ceph-1/current/ | grep 20.c0 20.c0_TEMP
4. 环境恢复
上面我们在模拟故障的过程中,创建了benchmark池,更改了monitor、osd、rgw的mon-osd-nearfull-ratio和mon-osd-full-ratio等变量,这里我们需要进行恢复。
1) 恢复ratio值
恢复Monitor,OSD的ratio值:
ceph pg set_nearfull_ratio {old-nearfull-value}
ceph pg set_full_ratio {od-full-value}
ceph tell osd.* injectargs '--mon-osd-nearfull-ratio {old-nearfull-value}'
ceph tell osd.* injectargs '--mon-osd-full-ratio {olsd-full-value}'
ceph tell mon.* injectargs '--mon-osd-nearfull-ratio {old-nearfull-value}'
ceph tell mon.* injectargs '--mon-osd-full-ratio {old-full-value}'恢复RGW的ratio值:
sudo ceph daemon client.radosgw.{rgw-name} config set mon_osd_nearfull_ratio {old-nearfull-value}
sudo ceph daemon client.radosgw.{rgw-name} config set mon_osd_full_ratio {old-full-value}请用适当的值替换{rgw-name}、{old-nearfull-value}、{old-full-value}
2) 删除benchmark测试池
分别删除池中的数据和池本身:
rados -p benchmark cleanup
ceph osd pool delete benchmark benchmark --yes-i-really-really-mean-it 5. 总结
在此,我们模拟了因OSD FULL导致ceph集群出现HEALTH_ERR的情况,并给出了在此情况下的集群读写、删除等特性。并提供了普通情况与极限情况下集群的修复方法。可以较为彻底的解决此方面的问题。
几个常用命令:
1) 查看ceph当前配置相关
# ceph daemon osd.0 help
# ceph daemon /var/run/ceph/ceph-osd.0.asok help
# ceph daemon /var/run/ceph/radosgw-uat-oss-test-08.asok help2) 查看默认配置参数
# ceph --show-config3) 在指定pool中创建rbd
# rbd create benchmark/ceph-client1-rbd1 --size 10240 -c ceph.conf
