OSD从down到out过程中osdmap的变化(2)
接着上一章,我们这里结合osd3_watch.txt日志文件,以及pgmap_active_clean.txt、pgmap_in_down.txt、pgmap_out_down.txt,从中选出4个具有代表性的PG,来分析一下osd0从in+up到in+down再到out+down这一整个过程中PG所执行的动作。
选取的4个PG如下:
in + up in + down out + down
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
pg_stat up up_primary acting acting_primary pg_stat up up_primary acting acting_primary pg_stat up up_primary acting acting_primary
11.4 [0,3] 0 [0,3] 0 11.4 [3] 3 [3] 3 11.4 [3,2] 3 [3,2] 3
22.2c [0,3] 0 [0,3] 0 22.2c [3] 3 [3] 3 22.2c [5,7] 5 [5,7] 5
22.2a [3,0] 3 [3,0] 3 22.2a [3] 3 [3] 3 22.2a [3,6] 3 [3,6] 3
22.16 [3,7] 3 [3,7] 3 22.16 [3,7] 3 [3,7] 3 22.16 [3,7] 3 [3,7] 3
上面4个PG代表4种典型的场景:
-
PG 11.4 : PG的主osd关闭,在osd out之后,PG的其中一个副本进行remap
-
PG 22.2c: PG的主OSD关闭,在osd out之后,PG的两个副本进行remap
-
PG 22.2a: PG的副本OSD关闭,在osd out之后,PG的其中一个副本进行remap
-
PG 22.16: 关闭的OSD并不是PG的任何副本
使用如下命令从osd3_watch.txt中分别导出该PG相关的日志信息:
# grep -rnw "11.4" ./osd3_watch.txt > ./osd3_watch_pg_11.4.txt
# grep -rnw "22.2c" ./osd3_watch.txt > ./osd3_watch_pg_22.2c.txt
# grep -rnw "22.2a" ./osd3_watch.txt > ./osd3_watch_pg_22.2a.txt
# grep -rnw "22.16" ./osd3_watch.txt > ./osd3_watch_pg_22.16.txt
# ls -al
总用量 32900
drwxr-xr-x 2 root root 4096 9月 12 19:59 .
dr-xr-x---. 8 root root 4096 9月 11 11:32 ..
-rw-r--r-- 1 root root 170772 9月 12 19:58 osd3_watch_pg_11.4.txt
-rw-r--r-- 1 root root 39861 9月 12 19:59 osd3_watch_pg_22.16.txt
-rw-r--r-- 1 root root 127958 9月 12 19:59 osd3_watch_pg_22.2a.txt
-rw-r--r-- 1 root root 96501 9月 12 19:59 osd3_watch_pg_22.2c.txt
-rw-r--r-- 1 root root 33228328 9月 11 14:19 osd3_watch.txt下面我们就针对这4种场景分别来分析。
1. PG 11.4分析
这里我们过滤osd3_watch.txt日志文件,找出所有与PG 11.4相关的日志(如下日志经过了适当的修改)。
1.1 收到e2223版本osdmap
2378:2020-09-11 14:05:19.113264 7fba46937700 20 osd.3 2222 _dispatch 0x7fba6ce1a1c0 osd_map(2223..2223 src has 1514..2223) v3
2379:2020-09-11 14:05:19.113452 7fba46937700 3 osd.3 2222 handle_osd_map epochs [2223,2223], i have 2222, src has [1514,2223]
2380:2020-09-11 14:05:19.113460 7fba46937700 10 osd.3 2222 handle_osd_map got inc map for epoch 2223
2381:2020-09-11 14:05:19.113776 7fba46937700 20 osd.3 2222 got_full_map 2223, nothing requested
2382:2020-09-11 14:05:19.113857 7fba46937700 10 osd.3 2222 write_superblock sb(5341b139-15dc-4c68-925a-179797d894d3 osd.3 e00c8fe5-d49e-42d1-9bfb-4965b9ab75b3 e2223 [1514,2223] lci=[2123,2223])
2383:2020-09-11 14:05:19.113938 7fba46937700 10 osd.3 2222 do_waiters -- start
2384:2020-09-11 14:05:19.113946 7fba46937700 10 osd.3 2222 do_waiters -- finish
2385:2020-09-11 14:05:19.127142 7fba49ec6700 10 osd.3 2222 _committed_osd_maps 2223..2223
2386:2020-09-11 14:05:19.127165 7fba49ec6700 10 osd.3 2222 advance to epoch 2223 (<= last 2223 <= newest_map 2223)
2387:2020-09-11 14:05:19.127175 7fba49ec6700 30 osd.3 2222 get_map 2223 -cached
2388:2020-09-11 14:05:19.127331 7fba49ec6700 7 osd.3 2223 consume_map version 2223
2422:2020-09-11 14:05:19.127924 7fba49ec6700 30 osd.3 pg_epoch: 2222 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] lock
2588:2020-09-11 14:05:19.130667 7fba49ec6700 30 osd.3 pg_epoch: 2222 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] lock
2589:2020-09-11 14:05:19.130679 7fba49ec6700 10 osd.3 pg_epoch: 2222 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] null
3126:2020-09-11 14:05:19.133146 7fba49ec6700 20 osd.3 2223 11.4 heartbeat_peers 0,2,31) osd3接收到CEPH_MSG_OSD_MAP消息
void OSD::_dispatch(Message *m)
{
dout(20) << "_dispatch " << m << " " << *m << dendl;
switch(m->get_type())
{
case CEPH_MSG_OSD_MAP:
handle_osd_map(static_cast<MOSDMap*>(m));
break;
}
...
}2) handle_osd_map()解析osdmap消息,并写入superblock
void OSD::handle_osd_map(MOSDMap *m){
...
epoch_t first = m->get_first();
epoch_t last = m->get_last();
dout(3) << "handle_osd_map epochs [" << first << "," << last << "], i have "
<< superblock.newest_map
<< ", src has [" << m->oldest_map << "," << m->newest_map << "]"
<< dendl;
...
// store new maps: queue for disk and put in the osdmap cache
epoch_t start = MAX(superblock.newest_map + 1, first);
for (epoch_t e = start; e <= last; e++) {
map<epoch_t,bufferlist>::iterator p;
p = m->maps.find(e);
if (p != m->maps.end()) {
dout(10) << "handle_osd_map got full map for epoch " << e << dendl;
OSDMap *o = new OSDMap;
bufferlist& bl = p->second;
o->decode(bl);
ghobject_t fulloid = get_osdmap_pobject_name(e);
t.write(coll_t::meta(), fulloid, 0, bl.length(), bl);
pin_map_bl(e, bl);
pinned_maps.push_back(add_map(o));
got_full_map(e);
continue;
}
...
}
...
// superblock and commit
write_superblock(t);
store->queue_transaction(
service.meta_osr.get(),
std::move(t),
new C_OnMapApply(&service, pinned_maps, last),
new C_OnMapCommit(this, start, last, m), 0);
}在handle_osd_map()函数中解析收到的MOSDMap消息,然后写入superblock中,提交成功后回调C_OnMapCommit(),并触发调用_committed_osd_maps().
3) _committed_osd_maps()
void OSD::_committed_osd_maps(epoch_t first, epoch_t last, MOSDMap *m){
...
// advance through the new maps
for (epoch_t cur = first; cur <= last; cur++) {
dout(10) << " advance to epoch " << cur
<< " (<= last " << last
<< " <= newest_map " << superblock.newest_map
<< ")" << dendl;
OSDMapRef newmap = get_map(cur);
}
// yay!
consume_map();
...
}本函数用于消费被保存的osdmap,其具体实现为consume_map():
void OSD::consume_map()
{
assert(osd_lock.is_locked());
dout(7) << "consume_map version " << osdmap->get_epoch() << dendl;
// scan pg's
{
RWLock::RLocker l(pg_map_lock);
for (ceph::unordered_map<spg_t,PG*>::iterator it = pg_map.begin();it != pg_map.end();++it) {
PG *pg = it->second;
pg->lock();
....
}
}
// scan pg's
{
RWLock::RLocker l(pg_map_lock);
for (ceph::unordered_map<spg_t,PG*>::iterator it = pg_map.begin();it != pg_map.end();++it) {
PG *pg = it->second;
pg->lock();
pg->queue_null(osdmap->get_epoch(), osdmap->get_epoch());
pg->unlock();
}
logger->set(l_osd_pg, pg_map.size());
}
}程序运行到这里,就构造了一个NullEvt到OSD的消息队列,从而触发相应的Peering流程。
1.2 进入peering流程
3478:2020-09-11 14:05:19.134829 7fba3d124700 30 osd.3 pg_epoch: 2222 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] lock
3482:2020-09-11 14:05:19.134849 7fba3d124700 10 osd.3 pg_epoch: 2222 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] handle_advance_map [3]/[3] -- 3/3
3485:2020-09-11 14:05:19.134866 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] state<Started>: Started advmap
3487:2020-09-11 14:05:19.134879 7fba3d124700 20 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] new interval newup [3] newacting [3]
3489:2020-09-11 14:05:19.134892 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] state<Started>: should_restart_peering, transitioning to Reset
3491:2020-09-11 14:05:19.134905 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] exit Started/ReplicaActive/RepNotRecovering 6737.966817 4 0.000070
3493:2020-09-11 14:05:19.134920 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] exit Started/ReplicaActive 6737.966836 0 0.000000
3495:2020-09-11 14:05:19.134936 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] exit Started 6739.036070 0 0.000000
3497:2020-09-11 14:05:19.134951 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] enter Reset
3498:2020-09-11 14:05:19.134961 7fba3d124700 20 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] set_last_peering_reset 2223
3499:2020-09-11 14:05:19.134971 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2223 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] Clearing blocked outgoing recovery messages
3504:2020-09-11 14:05:19.134982 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2223 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] Not blocking outgoing recovery messages
3506:2020-09-11 14:05:19.134992 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2223 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] state<Reset>: Reset advmap
3508:2020-09-11 14:05:19.135007 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2223 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] _calc_past_interval_range: already have past intervals back to 2222
3509:2020-09-11 14:05:19.135020 7fba3d124700 20 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2223 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] new interval newup [3] newacting [3]
3511:2020-09-11 14:05:19.135030 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2223 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] state<Reset>: should restart peering, calling start_peering_interval again
3512:2020-09-11 14:05:19.135040 7fba3d124700 20 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2223 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] set_last_peering_reset 2223
3515:2020-09-11 14:05:19.135065 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [3] r=0 lpr=2223 pi=2215-2222/3 luod=0'0 crt=201'1 lcod 0'0 mlcod 0'0 active] start_peering_interval: check_new_interval output: generate_past_intervals interval(2221-2222 up [0,3](0) acting [0,3](0)): not rw, up_thru 2221 up_from 2220 last_epoch_clean 2222
3519:2020-09-11 14:05:19.135076 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [3] r=0 lpr=2223 pi=2215-2222/3 luod=0'0 crt=201'1 lcod 0'0 mlcod 0'0 active] noting past interval(2221-2222 up [0,3](0) acting [0,3](0) maybe_went_rw)
3521:2020-09-11 14:05:19.135094 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 luod=0'0 crt=201'1 lcod 0'0 mlcod 0'0 active] up [0,3] -> [3], acting [0,3] -> [3], acting_primary 0 -> 3, up_primary 0 -> 3, role 1 -> 0, features acting 576460752032874495 upacting 576460752032874495
3522:2020-09-11 14:05:19.135109 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] clear_primary_state
3524:2020-09-11 14:05:19.135133 7fba3d124700 20 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] agent_stop
3525:2020-09-11 14:05:19.135142 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] on_change
3527:2020-09-11 14:05:19.135151 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] requeue_ops
3528:2020-09-11 14:05:19.135162 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] publish_stats_to_osd 2223:1329
3530:2020-09-11 14:05:19.135172 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] requeue_ops
3531:2020-09-11 14:05:19.135184 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] cancel_copy_ops
3533:2020-09-11 14:05:19.135194 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] cancel_flush_ops
3534:2020-09-11 14:05:19.135205 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] cancel_proxy_ops
3536:2020-09-11 14:05:19.135215 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] requeue_ops
3537:2020-09-11 14:05:19.135225 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] requeue_ops
3538:2020-09-11 14:05:19.135233 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] requeue_ops
3539:2020-09-11 14:05:19.135242 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] on_change_cleanup
3540:2020-09-11 14:05:19.135251 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] on_change
3542:2020-09-11 14:05:19.135263 7fba3d124700 20 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] exit NotTrimming
3543:2020-09-11 14:05:19.135272 7fba3d124700 20 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] enter NotTrimming
3544:2020-09-11 14:05:19.135281 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] clear_stats
3545:2020-09-11 14:05:19.135290 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] requeue_ops
3546:2020-09-11 14:05:19.135302 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] on_role_change
3547:2020-09-11 14:05:19.135312 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] requeue_ops
3548:2020-09-11 14:05:19.135322 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] cancel_recovery
3551:2020-09-11 14:05:19.135331 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] clear_recovery_state
3552:2020-09-11 14:05:19.135342 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] check_recovery_sources no source osds () went down
3554:2020-09-11 14:05:19.135354 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] handle_activate_map
3556:2020-09-11 14:05:19.135365 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] update_heartbeat_peers 0,2,3 -> 3
3559:2020-09-11 14:05:19.135379 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] take_waiters
3561:2020-09-11 14:05:19.135390 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] exit Reset 0.000439 1 0.000486
3563:2020-09-11 14:05:19.135404 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] enter Started
3565:2020-09-11 14:05:19.135414 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] enter Start
3566:2020-09-11 14:05:19.135425 7fba3d124700 1 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] state<Start>: transitioning to Primary
3569:2020-09-11 14:05:19.135439 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] exit Start 0.000024 0 0.000000
3571:2020-09-11 14:05:19.135454 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] enter Started/Primary
3574:2020-09-11 14:05:19.135465 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] enter Started/Primary/Peering
3575:2020-09-11 14:05:19.135478 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] enter Started/Primary/Peering/GetInfo
3578:2020-09-11 14:05:19.135490 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] _calc_past_interval_range: already have past intervals back to 2222
3579:2020-09-11 14:05:19.135505 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior interval(2221-2222 up [0,3](0) acting [0,3](0) maybe_went_rw)
3581:2020-09-11 14:05:19.135519 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior prior osd.0 is down
3583:2020-09-11 14:05:19.135531 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior interval(2220-2220 up [0,3](0) acting [3,2](3))
3585:2020-09-11 14:05:19.135545 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior final: probe 3 down 0 blocked_by {}
3587:2020-09-11 14:05:19.135556 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] up_thru 2221 < same_since 2223, must notify monitor
3589:2020-09-11 14:05:19.135569 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] publish_stats_to_osd 2223:1330
3591:2020-09-11 14:05:19.135583 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] exit Started/Primary/Peering/GetInfo 0.000104 0 0.000000
3593:2020-09-11 14:05:19.135595 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] enter Started/Primary/Peering/GetLog
3596:2020-09-11 14:05:19.135609 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] calc_acting osd.3 11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223)
3599:2020-09-11 14:05:19.135632 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] calc_acting newest update on osd.3 with 11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223)
3601:calc_acting primary is osd.3 with 11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223)
3603:2020-09-11 14:05:19.135659 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] actingbackfill is 3
3605:2020-09-11 14:05:19.135668 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] choose_acting want [3] (== acting) backfill_targets
3607:2020-09-11 14:05:19.135684 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] state<Started/Primary/Peering/GetLog>: leaving GetLog
3609:2020-09-11 14:05:19.135698 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] exit Started/Primary/Peering/GetLog 0.000102 0 0.000000
3611:2020-09-11 14:05:19.135712 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] publish_stats_to_osd 2223: no change since 2020-09-11 14:05:19.135569
3613:2020-09-11 14:05:19.135732 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] enter Started/Primary/Peering/GetMissing
3614:2020-09-11 14:05:19.135743 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] state<Started/Primary/Peering/GetMissing>: still need up_thru update before going active
3616:2020-09-11 14:05:19.135755 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] exit Started/Primary/Peering/GetMissing 0.000023 0 0.000000
3618:2020-09-11 14:05:19.135768 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] publish_stats_to_osd 2223: no change since 2020-09-11 14:05:19.135569
3620:2020-09-11 14:05:19.135782 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] enter Started/Primary/Peering/WaitUpThru
3622:2020-09-11 14:05:19.135793 7fba3d124700 20 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] handle_activate_map: Not dirtying info: last_persisted is 2222 while current is 2223
3626:2020-09-11 14:05:19.135811 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] handle_peering_event: epoch_sent: 2223 epoch_requested: 2223 NullEvt
6672:2020-09-11 14:05:19.153839 7fba496c5700 30 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] lock
6674:2020-09-11 14:05:19.153848 7fba496c5700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] flushed
6719:2020-09-11 14:05:19.153979 7fba3d124700 30 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] lock
6720:2020-09-11 14:05:19.153986 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] handle_peering_event: epoch_sent: 2223 epoch_requested: 2223 FlushedEvt
6722:2020-09-11 14:05:19.153991 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] requeue_ops
6877:2020-09-11 14:05:19.529657 7fba4fd58700 20 osd.3 2223 11.4 heartbeat_peers 3
7047:2020-09-11 14:05:19.862229 7fba49ec6700 30 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] lock
7209:2020-09-11 14:05:19.863342 7fba49ec6700 30 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] lock
7210:2020-09-11 14:05:19.863350 7fba49ec6700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] null
7951:2020-09-11 14:05:19.867042 7fba3d925700 30 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] lock
7953:2020-09-11 14:05:19.867061 7fba3d925700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] handle_advance_map [3]/[3] -- 3/3
7955:2020-09-11 14:05:19.867079 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] state<Started/Primary/Peering>: Peering advmap
7956:2020-09-11 14:05:19.867091 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] adjust_need_up_thru now 2223, need_up_thru now false
7957:2020-09-11 14:05:19.867102 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] state<Started>: Started advmap
7958:2020-09-11 14:05:19.867134 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] check_recovery_sources no source osds () went down
7959:2020-09-11 14:05:19.867154 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] handle_activate_map
7960:2020-09-11 14:05:19.867166 7fba3d925700 7 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] state<Started/Primary>: handle ActMap primary
7961:2020-09-11 14:05:19.867178 7fba3d925700 15 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] publish_stats_to_osd 2223: no change since 2020-09-11 14:05:19.135569
7962:2020-09-11 14:05:19.867196 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] take_waiters
7963:2020-09-11 14:05:19.867209 7fba3d925700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] exit Started/Primary/Peering/WaitUpThru 0.731426 4 0.000514
7964:2020-09-11 14:05:19.867224 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] state<Started/Primary/Peering>: Leaving Peering
7965:2020-09-11 14:05:19.867235 7fba3d925700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] exit Started/Primary/Peering 0.731769 0 0.000000
7966:2020-09-11 14:05:19.867250 7fba3d925700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] enter Started/Primary/Active
7967:2020-09-11 14:05:19.867262 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] state<Started/Primary/Active>: In Active, about to call activate
7968:2020-09-11 14:05:19.867277 7fba3d925700 20 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] activate - purged_snaps [] cached_removed_snaps []
7969:2020-09-11 14:05:19.867288 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] activate - snap_trimq []
7970:2020-09-11 14:05:19.867298 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] activate - no missing, moving last_complete 201'1 -> 201'1
7971:2020-09-11 14:05:19.867310 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] needs_recovery is recovered
7972:2020-09-11 14:05:19.867322 7fba3d925700 15 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] publish_stats_to_osd 2224:1331
7973:2020-09-11 14:05:19.867334 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] state<Started/Primary/Active>: Activate Finished
7974:2020-09-11 14:05:19.867346 7fba3d925700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] enter Started/Primary/Active/Activating
7975:2020-09-11 14:05:19.867358 7fba3d925700 20 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] handle_activate_map: Not dirtying info: last_persisted is 2223 while current is 2224
7976:2020-09-11 14:05:19.867368 7fba3d925700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] handle_peering_event: epoch_sent: 2224 epoch_requested: 2224 NullEvt
9530:2020-09-11 14:05:19.902099 7fba49ec6700 30 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] lock
9532:2020-09-11 14:05:19.902107 7fba49ec6700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] _activate_committed 2224 peer_activated now 3 last_epoch_started 2222 same_interval_since 2223
9533:2020-09-11 14:05:19.902120 7fba49ec6700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] all_activated_and_committed
9535:2020-09-11 14:05:19.902127 7fba49ec6700 30 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] lock
9536:2020-09-11 14:05:19.902133 7fba49ec6700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] flushed
9709:2020-09-11 14:05:19.902680 7fba3d124700 30 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] lock
9713:2020-09-11 14:05:19.902690 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 activating+undersized+degraded] handle_peering_event: epoch_sent: 2224 epoch_requested: 2224 AllReplicasActivated
9715:2020-09-11 14:05:19.902700 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] share_pg_info
9718:2020-09-11 14:05:19.902709 7fba3d124700 15 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] publish_stats_to_osd 2224:1332
9721:2020-09-11 14:05:19.902719 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] check_local
9724:2020-09-11 14:05:19.902727 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] needs_recovery is recovered
9727:2020-09-11 14:05:19.902736 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] needs_backfill does not need backfill
9730:2020-09-11 14:05:19.902745 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] activate all replicas clean, no recovery
9734:2020-09-11 14:05:19.902757 7fba3d124700 15 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] publish_stats_to_osd 2224: no change since 2020-09-11 14:05:19.902708
9736:2020-09-11 14:05:19.902765 7fba3d124700 20 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] hit_set_clear
9738:2020-09-11 14:05:19.902772 7fba3d124700 20 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] agent_stop
9747:2020-09-11 14:05:19.902799 7fba3d124700 30 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] lock
9750:2020-09-11 14:05:19.902808 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] handle_peering_event: epoch_sent: 2224 epoch_requested: 2224 FlushedEvt
9753:2020-09-11 14:05:19.902817 7fba3d124700 15 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] requeue_ops
10071:2020-09-11 14:05:19.904183 7fba3d124700 30 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] lock
10072:2020-09-11 14:05:19.904190 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] handle_peering_event: epoch_sent: 2224 epoch_requested: 2224 AllReplicasRecovered
10073:2020-09-11 14:05:19.904198 7fba3d124700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] exit Started/Primary/Active/Activating 0.036851 4 0.000283
10076:2020-09-11 14:05:19.904207 7fba3d124700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] enter Started/Primary/Active/Recovered
10078:2020-09-11 14:05:19.904216 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] needs_recovery is recovered
10080:2020-09-11 14:05:19.904225 7fba3d124700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] exit Started/Primary/Active/Recovered 0.000018 0 0.000000
10082:2020-09-11 14:05:19.904234 7fba3d124700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] enter Started/Primary/Active/Clean
10084:2020-09-11 14:05:19.904244 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] finish_recovery
10086:2020-09-11 14:05:19.904251 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] clear_recovery_state
10088:2020-09-11 14:05:19.904260 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] trim_past_intervals: trimming interval(2215-2219 up [3,2](3) acting [3,2](3) maybe_went_rw)
10091:2020-09-11 14:05:19.904269 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2220-2222/2 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] trim_past_intervals: trimming interval(2220-2220 up [0,3](0) acting [3,2](3))
10093:2020-09-11 14:05:19.904279 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2221-2222/1 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] trim_past_intervals: trimming interval(2221-2222 up [0,3](0) acting [0,3](0) maybe_went_rw)
10095:2020-09-11 14:05:19.904288 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] share_pg_info
10096:2020-09-11 14:05:19.904298 7fba3d124700 15 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] publish_stats_to_osd 2224:1333
10449:2020-09-11 14:05:20.014523 7fba49ec6700 30 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] lock
10450:2020-09-11 14:05:20.014538 7fba49ec6700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] _finish_recovery
10451:2020-09-11 14:05:20.014548 7fba49ec6700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] purge_strays
10452:2020-09-11 14:05:20.014559 7fba49ec6700 15 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] publish_stats_to_osd 2224: no change since 2020-09-11 14:05:19.904297
10587:2020-09-11 14:05:20.681012 7fba4f557700 25 osd.3 2224 sending 11.4 2224:1333
10674:2020-09-11 14:05:20.893262 7fba46937700 25 osd.3 2224 ack on 11.4 2224:1333
10825:2020-09-11 14:05:21.673551 7fba49ec6700 30 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] lock
11084:2020-09-11 14:05:21.675592 7fba49ec6700 30 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] lock
11088:2020-09-11 14:05:21.675608 7fba49ec6700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] null
11643:2020-09-11 14:05:21.678631 7fba3d124700 30 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] lock
11651:2020-09-11 14:05:21.678651 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] handle_advance_map [3]/[3] -- 3/3
11656:2020-09-11 14:05:21.678682 7fba3d124700 10 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] state<Started/Primary/Active>: Active advmap
11660:2020-09-11 14:05:21.678697 7fba3d124700 10 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] state<Started>: Started advmap
11663:2020-09-11 14:05:21.678711 7fba3d124700 10 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] check_recovery_sources no source osds () went down
11668:2020-09-11 14:05:21.678729 7fba3d124700 10 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] handle_activate_map
11672:2020-09-11 14:05:21.678743 7fba3d124700 10 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] state<Started/Primary/Active>: Active: handling ActMap
11679:2020-09-11 14:05:21.678768 7fba3d124700 10 osd.3 2225 queue_for_recovery queued pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded]
11683:2020-09-11 14:05:21.678778 7fba3d124700 7 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] state<Started/Primary>: handle ActMap primary
11689:2020-09-11 14:05:21.678793 7fba3d124700 15 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] publish_stats_to_osd 2224: no change since 2020-09-11 14:05:19.904297
11692:2020-09-11 14:05:21.678810 7fba3d124700 10 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] take_waiters
11694:2020-09-11 14:05:21.678822 7fba3d124700 20 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] handle_activate_map: Not dirtying info: last_persisted is 2224 while current is 2225
11697:2020-09-11 14:05:21.678833 7fba3d124700 10 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] handle_peering_event: epoch_sent: 2225 epoch_requested: 2225 NullEvt
11703:2020-09-11 14:05:21.678856 7fba37919700 30 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] lock
11706:2020-09-11 14:05:21.678865 7fba37919700 10 osd.3 2225 do_recovery starting 1 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded]
11709:2020-09-11 14:05:21.678871 7fba37919700 10 osd.3 pg_epoch: 2225 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] recovery raced and were queued twice, ignoring!
11710:2020-09-11 14:05:21.678878 7fba37919700 10 osd.3 2225 do_recovery started 0/1 on pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2224/0 2223/2223/2223) [3] r=0 lpr=2223 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded]在上面将PG加入到OSD的peering_wq之后,OSD对应的线程池就会调用process_peering_events()函数来对相应的PG进行处理:
void OSD::process_peering_events(
const list<PG*> &pgs,
ThreadPool::TPHandle &handle
)
{
...
for (list<PG*>::const_iterator i = pgs.begin();i != pgs.end();++i) {
...
PG *pg = *i;
pg->lock_suspend_timeout(handle);
curmap = service.get_osdmap();
if (pg->deleting) {
pg->unlock();
continue;
}
if (!advance_pg(curmap->get_epoch(), pg, handle, &rctx, &split_pgs)) {
// we need to requeue the PG explicitly since we didn't actually
// handle an event
peering_wq.queue(pg);
} else {
assert(!pg->peering_queue.empty());
PG::CephPeeringEvtRef evt = pg->peering_queue.front();
pg->peering_queue.pop_front();
pg->handle_peering_event(evt, &rctx);
}
}
....
}1.2.1 OSD::advance_pg()函数
bool OSD::advance_pg(
epoch_t osd_epoch, PG *pg,
ThreadPool::TPHandle &handle,
PG::RecoveryCtx *rctx,
set<boost::intrusive_ptr<PG> > *new_pgs)
{
...
for (;next_epoch <= osd_epoch && next_epoch <= max;++next_epoch) {
...
nextmap->pg_to_up_acting_osds(
pg->info.pgid.pgid,
&newup, &up_primary,
&newacting, &acting_primary);
pg->handle_advance_map(
nextmap, lastmap, newup, up_primary,
newacting, acting_primary, rctx);
...
}
pg->handle_activate_map(rctx);
...
}在advance_pg()函数中,PG对每一个epoch的osdmap进行处理: 首先调用pg_to_up_acting_osds()来计算PG11.4所对应的up set和acting set;然后调用handle_advance_map()来触发peering; 之后会调用handle_activate_map()来触发peering完成后的一些其他工作。
1.2.2 PG::handle_advance_map()函数
void PG::handle_advance_map(
OSDMapRef osdmap, OSDMapRef lastmap,
vector<int>& newup, int up_primary,
vector<int>& newacting, int acting_primary,
RecoveryCtx *rctx)
{
dout(10) << "handle_advance_map "
<< newup << "/" << newacting
<< " -- " << up_primary << "/" << acting_primary
<< dendl;
...
AdvMap evt(
osdmap, lastmap, newup, up_primary,
newacting, acting_primary);
recovery_state.handle_event(evt, rctx);
...
}这里PG11.4对应的up set为[3], acting set也为[3],up_primary为3,acting_primary也为3。之后生成一个AdvMap事件,投递到recovery_state中,最终出发新的Peering过程。
1.3 peering状态机运转
1.3.1 ReplicaActive状态对AdvMap事件的处理
由于PG 11.4最开始的的up set为[0,3], acting set为[0,3],因此在active + clean状态时,该PG在OSD3上是一个replica,其所属的状态也应该是ReplicaActive状态。下面我们来看一下,当处于ReplicaActive状态时,下时收到AdvMap事件的处理:在ReplicaActive状态下没有对AdvMap事件的直接的处理函数,因此会调用其父状态Started状态的处理函数:
boost::statechart::result PG::RecoveryState::Started::react(const AdvMap& advmap)
{
dout(10) << "Started advmap" << dendl;
PG *pg = context< RecoveryMachine >().pg;
pg->check_full_transition(advmap.lastmap, advmap.osdmap);
if (pg->should_restart_peering(
advmap.up_primary,
advmap.acting_primary,
advmap.newup,
advmap.newacting,
advmap.lastmap,
advmap.osdmap)) {
dout(10) << "should_restart_peering, transitioning to Reset" << dendl;
post_event(advmap);
return transit< Reset >();
}
pg->remove_down_peer_info(advmap.osdmap);
return discard_event();
}在对应的react()函数中调用should_restart_peering()来检查是否需要重新启动peering操作。下面我们来看一下该函数的实现:
bool PG::should_restart_peering(
int newupprimary,
int newactingprimary,
const vector<int>& newup,
const vector<int>& newacting,
OSDMapRef lastmap,
OSDMapRef osdmap)
{
if (pg_interval_t::is_new_interval(
primary.osd,
newactingprimary,
acting,
newacting,
up_primary.osd,
newupprimary,
up,
newup,
osdmap,
lastmap,
info.pgid.pgid)) {
dout(20) << "new interval newup " << newup
<< " newacting " << newacting << dendl;
return true;
} else {
return false;
}
}
bool pg_interval_t::is_new_interval(
int old_acting_primary,
int new_acting_primary,
const vector<int> &old_acting,
const vector<int> &new_acting,
int old_up_primary,
int new_up_primary,
const vector<int> &old_up,
const vector<int> &new_up,
OSDMapRef osdmap,
OSDMapRef lastmap,
pg_t pgid) {
...
}
bool pg_interval_t::is_new_interval(
int old_acting_primary,
int new_acting_primary,
const vector<int> &old_acting,
const vector<int> &new_acting,
int old_up_primary,
int new_up_primary,
const vector<int> &old_up,
const vector<int> &new_up,
int old_size,
int new_size,
int old_min_size,
int new_min_size,
unsigned old_pg_num,
unsigned new_pg_num,
bool old_sort_bitwise,
bool new_sort_bitwise,
pg_t pgid) {
return old_acting_primary != new_acting_primary ||
new_acting != old_acting ||
old_up_primary != new_up_primary ||
new_up != old_up ||
old_min_size != new_min_size ||
old_size != new_size ||
pgid.is_split(old_pg_num, new_pg_num, 0) ||
old_sort_bitwise != new_sort_bitwise;
}这里old_acting_primary为0, new_acting_primary为3; old_acting为[0,3],new_acting为[3]; old_up_primary为0,new_up_primary为3; old_up为[0,3],new_up为[3]。参看代码,满足如何任何一个条件即可判断为new_interval:
-
PG的acting primary发生了改变;
-
PG的acting set发生了改变;
-
PG的up primary发生了改变;
-
PG的up set发生了改变;
-
PG的min_size发生了改变(通常是调整了rule规则);
-
PG的副本size值发生了改变;
-
PG进行了分裂
-
PG的sort bitwise发生了改变
注:关于sort bitwise,请参看sort bitwise是什么意思,下面是一个对sort bitwise作用的一个大体描述
After upgrading, users should set the ‘sortbitwise’ flag to enable the new internal object sort order: ceph osd set sortbitwise
This flag is important for the new object enumeration API and for new backends like BlueStore
因此,这里上面should_restart_peering()返回值肯定为true,因此将AdvMap事件继续投递,进入Reset状态。由于原来PG 11.4处于RepNotRecovering状态,因此这里转入Reset状态,会首先退出子状态,打印出如下语句:
3491:2020-09-11 14:05:19.134905 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] exit Started/ReplicaActive/RepNotRecovering 6737.966817 4 0.000070
3493:2020-09-11 14:05:19.134920 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] exit Started/ReplicaActive 6737.966836 0 0.000000
3495:2020-09-11 14:05:19.134936 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2220/2221/2221) [0,3] r=1 lpr=2221 pi=2215-2220/2 luod=0'0 crt=201'1 lcod 0'0 active] exit Started 6739.036070 0 0.0000001.3.2 Reset状态对AdvMap事件的处理
在上面ReplicaActive接收到AdvMap事件,从而引发进入到Reset状态后:
PG::RecoveryState::Reset::Reset(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Reset")
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
pg->flushes_in_progress = 0;
pg->set_last_peering_reset();
}在Reset状态的构造函数中,会调用set_last_peering_reset()清空上一次的peering信息。之后再调用Reset::react()来处理post_event()投递进来的AdvMap事件:
boost::statechart::result PG::RecoveryState::Reset::react(const AdvMap& advmap)
{
PG *pg = context< RecoveryMachine >().pg;
dout(10) << "Reset advmap" << dendl;
// make sure we have past_intervals filled in. hopefully this will happen
// _before_ we are active.
pg->generate_past_intervals();
pg->check_full_transition(advmap.lastmap, advmap.osdmap);
if (pg->should_restart_peering(
advmap.up_primary,
advmap.acting_primary,
advmap.newup,
advmap.newacting,
advmap.lastmap,
advmap.osdmap)) {
dout(10) << "should restart peering, calling start_peering_interval again"
<< dendl;
pg->start_peering_interval(
advmap.lastmap,
advmap.newup, advmap.up_primary,
advmap.newacting, advmap.acting_primary,
context< RecoveryMachine >().get_cur_transaction());
}
pg->remove_down_peer_info(advmap.osdmap);
return discard_event();
}1) generate_past_intervals()函数
在Reset::react(const AdvMap&)函数中,首先调用generate_past_interval():
void PG::generate_past_intervals(){
....
if (!_calc_past_interval_range(&cur_epoch, &end_epoch,
osd->get_superblock().oldest_map)) {
if (info.history.same_interval_since == 0) {
info.history.same_interval_since = end_epoch;
dirty_info = true;
}
return;
}
...
}
bool PG::_calc_past_interval_range(epoch_t *start, epoch_t *end, epoch_t oldest_map)
{
...
// Do we already have the intervals we want?
map<epoch_t,pg_interval_t>::const_iterator pif = past_intervals.begin();
if (pif != past_intervals.end()) {
if (pif->first <= info.history.last_epoch_clean) {
dout(10) << __func__ << ": already have past intervals back to "
<< info.history.last_epoch_clean << dendl;
return false;
}
*end = past_intervals.begin()->first;
}
...
}函数_calc_past_interval_range()用于计算一个past_interval的范围。所谓一个past_interval,是指一个连续的epoch段[epoch_start, epoch_end],在该epoch段内:
-
PG的acting primary保持不变;
-
PG的acting set保持不变;
-
PG的up primary保持不变;
-
PG的up set保持不变;
-
PG的min_size保持不变;
-
PG的副本size值保持不变;
-
PG没有进行分裂;
-
PG的sort bitwise保持不变;
函数_calc_past_interval_range()如果返回true,表示成功计算到一个past_interval;如果返回false,则表示该interval已经计算过,不必再计算,或者不是一个有效的past_interval。
查询_calc_past_interval_range(),发现只有在如下几个地方会被调用到:
-
Reset::react(AdvMap)函数中generate_past_intervals()
-
GetInfo::GetInfo(my_context)构造函数中调用generate_past_intervals()
-
OSD::build_past_intervals_parallel()函数中(注: 本函数由OSD::load_pgs()在启动时所调用)
从上面三种情况得知,past_interval只会在OSD启动时、或者触发Peering操作时被调用。这里我们结合osd3_watch_pg_11.4.txt日志,来看一下这里的执行过程:
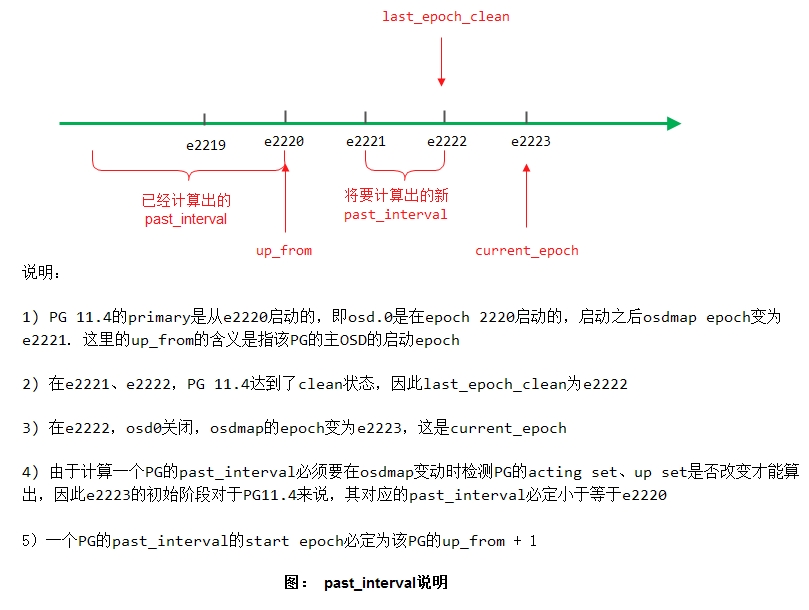
由此,我们在这里计算past_interval返回false:
_calc_past_interval_range: already have past intervals back to 2222
2) start_peering_interval()函数
void PG::start_peering_interval(
const OSDMapRef lastmap,
const vector<int>& newup, int new_up_primary,
const vector<int>& newacting, int new_acting_primary,
ObjectStore::Transaction *t)
{
...
set_last_peering_reset();
...
init_primary_up_acting(
newup,
newacting,
new_up_primary,
new_acting_primary);
....
if(!lastmap){
}else{
...
pg_interval_t::check_new_interval(....);
dout(10) << __func__ << ": check_new_interval output: "
<< debug.str() << dendl;
if (new_interval) {
dout(10) << " noting past " << past_intervals.rbegin()->second << dendl;
dirty_info = true;
dirty_big_info = true;
info.history.same_interval_since = osdmap->get_epoch();
}
}
...
dout(10) << " up " << oldup << " -> " << up
<< ", acting " << oldacting << " -> " << acting
<< ", acting_primary " << old_acting_primary << " -> " << new_acting_primary
<< ", up_primary " << old_up_primary << " -> " << new_up_primary
<< ", role " << oldrole << " -> " << role
<< ", features acting " << acting_features
<< " upacting " << upacting_features
<< dendl;
// deactivate.
state_clear(PG_STATE_ACTIVE);
state_clear(PG_STATE_PEERED);
state_clear(PG_STATE_DOWN);
state_clear(PG_STATE_RECOVERY_WAIT);
state_clear(PG_STATE_RECOVERING);
peer_purged.clear();
actingbackfill.clear();
snap_trim_queued = false;
scrub_queued = false;
// reset primary state?
if (was_old_primary || is_primary()) {
osd->remove_want_pg_temp(info.pgid.pgid);
}
clear_primary_state();
// pg->on_*
on_change(t);
assert(!deleting);
// should we tell the primary we are here?
send_notify = !is_primary();
if (role != oldrole || was_old_primary != is_primary()) {
// did primary change?
if (was_old_primary != is_primary()) {
state_clear(PG_STATE_CLEAN);
clear_publish_stats();
// take replay queue waiters
list<OpRequestRef> ls;
for (map<eversion_t,OpRequestRef>::iterator it = replay_queue.begin();it != replay_queue.end();++it)
ls.push_back(it->second);
replay_queue.clear();
requeue_ops(ls);
}
on_role_change();
// take active waiters
requeue_ops(waiting_for_peered);
} else {
....
}
cancel_recovery();
....
}在收到osdmap,从而触发peering操作之前,调用start_peering_interval()函数,完成相关状态的重新设置。
-
set_last_peering_reset()用于清空上一次的peering数据;
-
init_primary_up_acting()用于设置当前新的acting set以及up set
-
check_new_interval(): 用于检查是否是一个新的interval。如果是新interval,则计算出该新的past_interval:
generate_past_intervals interval(2221-2222 up 0,3 acting 0,3): not rw, up_thru 2221 up_from 2220 last_epoch_clean 2222
在该interval[2221,2222]下,up set为[0,3],acting set为[0,3],并且up_thru为2221。而当前在epoch 2223下,up set变为[3],acting set为[3],因此对于该PG来说,OSD3的角色由1变为0,即由replica变为primary。
- 清除PG的相关状态。关于PG的状态是由一个
unsigned类型的整数来表示的
/*
* pg states
*/
#define PG_STATE_CREATING (1<<0) // creating
#define PG_STATE_ACTIVE (1<<1) // i am active. (primary: replicas too)
#define PG_STATE_CLEAN (1<<2) // peers are complete, clean of stray replicas.
#define PG_STATE_DOWN (1<<4) // a needed replica is down, PG offline
#define PG_STATE_REPLAY (1<<5) // crashed, waiting for replay
//#define PG_STATE_STRAY (1<<6) // i must notify the primary i exist.
#define PG_STATE_SPLITTING (1<<7) // i am splitting
#define PG_STATE_SCRUBBING (1<<8) // scrubbing
#define PG_STATE_SCRUBQ (1<<9) // queued for scrub
#define PG_STATE_DEGRADED (1<<10) // pg contains objects with reduced redundancy
#define PG_STATE_INCONSISTENT (1<<11) // pg replicas are inconsistent (but shouldn't be)
#define PG_STATE_PEERING (1<<12) // pg is (re)peering
#define PG_STATE_REPAIR (1<<13) // pg should repair on next scrub
#define PG_STATE_RECOVERING (1<<14) // pg is recovering/migrating objects
#define PG_STATE_BACKFILL_WAIT (1<<15) // [active] reserving backfill
#define PG_STATE_INCOMPLETE (1<<16) // incomplete content, peering failed.
#define PG_STATE_STALE (1<<17) // our state for this pg is stale, unknown.
#define PG_STATE_REMAPPED (1<<18) // pg is explicitly remapped to different OSDs than CRUSH
#define PG_STATE_DEEP_SCRUB (1<<19) // deep scrub: check CRC32 on files
#define PG_STATE_BACKFILL (1<<20) // [active] backfilling pg content
#define PG_STATE_BACKFILL_TOOFULL (1<<21) // backfill can't proceed: too full
#define PG_STATE_RECOVERY_WAIT (1<<22) // waiting for recovery reservations
#define PG_STATE_UNDERSIZED (1<<23) // pg acting < pool size
#define PG_STATE_ACTIVATING (1<<24) // pg is peered but not yet active
#define PG_STATE_PEERED (1<<25) // peered, cannot go active, can recover
#define PG_STATE_SNAPTRIM (1<<26) // trimming snaps
#define PG_STATE_SNAPTRIM_WAIT (1<<27) // queued to trim snaps这里将active状态清除了,因此变为inactive状态。
-
clear_primary_state(): 用于清空peering状态
-
PG 11.4所在OSD3从replica变为primary,因此这里还要处理大量因角色变化而产生的操作;
-
cancel_recovery(): 取消PG当前正在进行中的recovery动作;
到此为止,由OSD::advance_pg()函数中pg->handle_advance_map()所触发的AdvMap事件就已经处理完成。
1.3.3 进入Started状态
在完成上面的Reset状态的操作之后,接着在OSD::advance_pg()函数中通过pg->handle_activate_map()函数,从而引发进入Started状态。如下是这一过程的一个日志片段:
3554:2020-09-11 14:05:19.135354 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] handle_activate_map
3556:2020-09-11 14:05:19.135365 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] update_heartbeat_peers 0,2,3 -> 3
3559:2020-09-11 14:05:19.135379 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] take_waiters
3561:2020-09-11 14:05:19.135390 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] exit Reset 0.000439 1 0.000486
3563:2020-09-11 14:05:19.135404 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] enter Started
3565:2020-09-11 14:05:19.135414 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] enter Start
3566:2020-09-11 14:05:19.135425 7fba3d124700 1 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] state<Start>: transitioning to Primary
3569:2020-09-11 14:05:19.135439 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] exit Start 0.000024 0 0.000000
3571:2020-09-11 14:05:19.135454 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] enter Started/Primary
3574:2020-09-11 14:05:19.135465 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 inactive] enter Started/Primary/Peering
3575:2020-09-11 14:05:19.135478 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] enter Started/Primary/Peering/GetInfo
3578:2020-09-11 14:05:19.135490 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] _calc_past_interval_range: already have past intervals back to 2222
3579:2020-09-11 14:05:19.135505 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior interval(2221-2222 up [0,3](0) acting [0,3](0) maybe_went_rw)
3581:2020-09-11 14:05:19.135519 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior prior osd.0 is down
3583:2020-09-11 14:05:19.135531 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior interval(2220-2220 up [0,3](0) acting [3,2](3))
3585:2020-09-11 14:05:19.135545 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior final: probe 3 down 0 blocked_by {}
3587:2020-09-11 14:05:19.135556 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] up_thru 2221 < same_since 2223, must notify monitor
3589:2020-09-11 14:05:19.135569 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] publish_stats_to_osd 2223:1330
3591:2020-09-11 14:05:19.135583 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] exit Started/Primary/Peering/GetInfo 0.000104 0 0.000000
3593:2020-09-11 14:05:19.135595 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] enter Started/Primary/Peering/GetLog
3596:2020-09-11 14:05:19.135609 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] calc_acting osd.3 11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223)
3599:2020-09-11 14:05:19.135632 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] calc_acting newest update on osd.3 with 11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223)
3601:calc_acting primary is osd.3 with 11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223)
3603:2020-09-11 14:05:19.135659 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] actingbackfill is 3
3605:2020-09-11 14:05:19.135668 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] choose_acting want [3] (== acting) backfill_targets
3607:2020-09-11 14:05:19.135684 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] state<Started/Primary/Peering/GetLog>: leaving GetLog
3609:2020-09-11 14:05:19.135698 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] exit Started/Primary/Peering/GetLog 0.000102 0 0.000000
3611:2020-09-11 14:05:19.135712 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] publish_stats_to_osd 2223: no change since 2020-09-11 14:05:19.135569
3613:2020-09-11 14:05:19.135732 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] enter Started/Primary/Peering/GetMissing
3614:2020-09-11 14:05:19.135743 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] state<Started/Primary/Peering/GetMissing>: still need up_thru update before going active
3616:2020-09-11 14:05:19.135755 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] exit Started/Primary/Peering/GetMissing 0.000023 0 0.000000
3618:2020-09-11 14:05:19.135768 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] publish_stats_to_osd 2223: no change since 2020-09-11 14:05:19.135569
3620:2020-09-11 14:05:19.135782 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] enter Started/Primary/Peering/WaitUpThru
3622:2020-09-11 14:05:19.135793 7fba3d124700 20 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] handle_activate_map: Not dirtying info: last_persisted is 2222 while current is 22231) handle_activate_map()函数
void PG::handle_activate_map(RecoveryCtx *rctx)
{
dout(10) << "handle_activate_map " << dendl;
ActMap evt;
recovery_state.handle_event(evt, rctx);
if (osdmap_ref->get_epoch() - last_persisted_osdmap_ref->get_epoch() > cct->_conf->osd_pg_epoch_persisted_max_stale) {
dout(20) << __func__ << ": Dirtying info: last_persisted is "
<< last_persisted_osdmap_ref->get_epoch()
<< " while current is " << osdmap_ref->get_epoch() << dendl;
dirty_info = true;
} else {
dout(20) << __func__ << ": Not dirtying info: last_persisted is "
<< last_persisted_osdmap_ref->get_epoch()
<< " while current is " << osdmap_ref->get_epoch() << dendl;
}
if (osdmap_ref->check_new_blacklist_entries()) check_blacklisted_watchers();
}这里handle_activate_map()函数构造了一个ActMap事件,并调用recovery_state.handle_event()来进行处理。
2) Reset::react(const ActMap &)函数
到此为止,我们其实还没有退出上一个步骤的Reset阶段,因此这个对于ActMap事件的处理,是通过如下函数来进行的:
boost::statechart::result PG::RecoveryState::Reset::react(const ActMap&)
{
PG *pg = context< RecoveryMachine >().pg;
if (pg->should_send_notify() && pg->get_primary().osd >= 0) {
context< RecoveryMachine >().send_notify(
pg->get_primary(),
pg_notify_t(
pg->get_primary().shard, pg->pg_whoami.shard,
pg->get_osdmap()->get_epoch(),
pg->get_osdmap()->get_epoch(),
pg->info),
pg->past_intervals);
}
pg->update_heartbeat_peers();
pg->take_waiters();
return transit< Started >();
}通常在osdmap发送变动,从而引发PG的acting set、up set发生变动,对于一个PG的副本OSD通常会发送一个通知消息到PG的Primary OSD。这里由于osd3已经是PG11.4的primary OSD,因此这里不需要发送通知消息。
注: 关于send_notify变量的设置,是在Initial::react(const Load&)函数中。
PG的Primary OSD会与Replica OSDs保持心跳,并且这个心跳是由Primary OSD来主动发出并维护的。这里调用pg->update_heartbeat_peers()来更新心跳信息。
最后,通过transit< Started >()直接进入Started状态
3) Started::Started()函数
PG::RecoveryState::Started::Started(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started")
{
context< RecoveryMachine >().log_enter(state_name);
}进入Started状态,首先调用相应的构造函数。
1.3.4 进入Started/Start状态
Started的默认初始状态是Start状态。这里我们来看Started/Start状态的构造函数:
PG::RecoveryState::Start::Start(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Start")
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
if (pg->is_primary()) {
dout(1) << "transitioning to Primary" << dendl;
post_event(MakePrimary());
} else { //is_stray
dout(1) << "transitioning to Stray" << dendl;
post_event(MakeStray());
}
}进入Start状态后,根据PG所在OSD是否为Primary OSD,从而决定是进入Started/Primary状态,还是Started/Stray状态。这里对于PG 11.4而言,在当前epoch 2223时osd3是Primary OSD,因此进入的是Primary状态。
1.3.5 进入Started/Primary状态
如下是Primary状态的构造函数:
PG::RecoveryState::Primary::Primary(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary")
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
assert(pg->want_acting.empty());
// set CREATING bit until we have peered for the first time.
if (pg->info.history.last_epoch_started == 0) {
pg->state_set(PG_STATE_CREATING);
// use the history timestamp, which ultimately comes from the
// monitor in the create case.
utime_t t = pg->info.history.last_scrub_stamp;
pg->info.stats.last_fresh = t;
pg->info.stats.last_active = t;
pg->info.stats.last_change = t;
pg->info.stats.last_peered = t;
pg->info.stats.last_clean = t;
pg->info.stats.last_unstale = t;
pg->info.stats.last_undegraded = t;
pg->info.stats.last_fullsized = t;
pg->info.stats.last_scrub_stamp = t;
pg->info.stats.last_deep_scrub_stamp = t;
pg->info.stats.last_clean_scrub_stamp = t;
}
}这里代码较为简单,不做介绍。
1.3.6 进入Started/Primary/Peering状态
Primary的默认初始子状态为Peering状态,因此这里直接进入Peering状态:
PG::RecoveryState::Peering::Peering(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Peering"),
history_les_bound(false)
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
assert(!pg->is_peered());
assert(!pg->is_peering());
assert(pg->is_primary());
pg->state_set(PG_STATE_PEERING);
}进入Peering状态后,就将PG的状态通过pg->state_set()设置为了PEERING了。
1.3.7 进入Started/Primary/Peering/GetInfo状态
Peering的默认初始子状态为GetInfo状态,因此这里直接进入GetInfo状态:
/*--------GetInfo---------*/
PG::RecoveryState::GetInfo::GetInfo(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Peering/GetInfo")
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
pg->generate_past_intervals();
unique_ptr<PriorSet> &prior_set = context< Peering >().prior_set;
assert(pg->blocked_by.empty());
if (!prior_set.get())
pg->build_prior(prior_set);
pg->reset_min_peer_features();
get_infos();
if (peer_info_requested.empty() && !prior_set->pg_down) {
post_event(GotInfo());
}
}进入GetInfo状态后,首先调用generate_past_intervals()计算past_intervals。这里我们在前面Reset阶段就已经计算出了新的past_interval为[2221,2222]。
1) build_prior()函数
void PG::build_prior(std::unique_ptr<PriorSet> &prior_set)
{
if (1) {
// sanity check
for (map<pg_shard_t,pg_info_t>::iterator it = peer_info.begin();it != peer_info.end();++it) {
assert(info.history.last_epoch_started >= it->second.history.last_epoch_started);
}
}
prior_set.reset(
new PriorSet(
pool.info.ec_pool(),
get_pgbackend()->get_is_recoverable_predicate(),
*get_osdmap(),
past_intervals,
up,
acting,
info,
this));
PriorSet &prior(*prior_set.get());
if (prior.pg_down) {
state_set(PG_STATE_DOWN);
}
if (get_osdmap()->get_up_thru(osd->whoami) < info.history.same_interval_since) {
dout(10) << "up_thru " << get_osdmap()->get_up_thru(osd->whoami)
<< " < same_since " << info.history.same_interval_since
<< ", must notify monitor" << dendl;
need_up_thru = true;
} else {
dout(10) << "up_thru " << get_osdmap()->get_up_thru(osd->whoami)
<< " >= same_since " << info.history.same_interval_since
<< ", all is well" << dendl;
need_up_thru = false;
}
set_probe_targets(prior_set->probe);
}关于PriorSet,我们这里不做介绍,后面我们会再开辟专门的章节来进行说明(参见up_thru)。这里我们给出针对PG 11.4所构建的PriorSet的结果:
3579:2020-09-11 14:05:19.135505 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior interval(2221-2222 up [0,3](0) acting [0,3](0) maybe_went_rw)
3581:2020-09-11 14:05:19.135519 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior prior osd.0 is down
3583:2020-09-11 14:05:19.135531 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior interval(2220-2220 up [0,3](0) acting [3,2](3))
3585:2020-09-11 14:05:19.135545 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior final: probe 3 down 0 blocked_by {}当前osdmap的epoch为e2223,对于osd3来说其上一次申请的up_thru为e2221,而当前的same_interval_since为e2223,因此这里need_up_thru需要设置为true。
2) GetInfo::get_infos()
void PG::RecoveryState::GetInfo::get_infos()
{
PG *pg = context< RecoveryMachine >().pg;
unique_ptr<PriorSet> &prior_set = context< Peering >().prior_set;
pg->blocked_by.clear();
for (set<pg_shard_t>::const_iterator it = prior_set->probe.begin();it != prior_set->probe.end();++it) {
pg_shard_t peer = *it;
if (peer == pg->pg_whoami) {
continue;
}
if (pg->peer_info.count(peer)) {
dout(10) << " have osd." << peer << " info " << pg->peer_info[peer] << dendl;
continue;
}
if (peer_info_requested.count(peer)) {
dout(10) << " already requested info from osd." << peer << dendl;
pg->blocked_by.insert(peer.osd);
} else if (!pg->get_osdmap()->is_up(peer.osd)) {
dout(10) << " not querying info from down osd." << peer << dendl;
} else {
dout(10) << " querying info from osd." << peer << dendl;
context< RecoveryMachine >().send_query(
peer, pg_query_t(pg_query_t::INFO,
it->shard, pg->pg_whoami.shard,
pg->info.history,
pg->get_osdmap()->get_epoch()));
peer_info_requested.insert(peer);
pg->blocked_by.insert(peer.osd);
}
}
pg->publish_stats_to_osd();
}
//位于src/osd/pg.h的RecoveryMachine中
void send_query(pg_shard_t to, const pg_query_t &query) {
assert(state->rctx);
assert(state->rctx->query_map);
(*state->rctx->query_map)[to.osd][spg_t(pg->info.pgid.pgid, to.shard)] = query;
}这里由上面构造的PriorSet为:
3585:2020-09-11 14:05:19.135545 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] PriorSet: build_prior final: probe 3 down 0 blocked_by {}GetInfo()是由PG的主OSD向从OSD发送pg_query_t::INFO消息以获取从OSD的pg_into_t信息。这里对于PG11.4而言,因为目前其prior_set->probe为[3],因此这里这里在for循环中第一个continue就已经退出了。但在这里我们还是讲述一下GetInfo究竟是要获取哪些info信息,下面我们先来看一下pg_query_t结构体的定义:
/**
* pg_query_t - used to ask a peer for information about a pg.
*
* note: if version=0, type=LOG, then we just provide our full log.
*/
struct pg_query_t {
enum {
INFO = 0,
LOG = 1,
MISSING = 4,
FULLLOG = 5,
};
__s32 type;
eversion_t since;
pg_history_t history;
epoch_t epoch_sent;
shard_id_t to;
shard_id_t from;
};如下则是pg_info_t结构体的定义(src/osd/osd_types.h):
/**
* pg_info_t - summary of PG statistics.
*
* some notes:
* - last_complete implies we have all objects that existed as of that
* stamp, OR a newer object, OR have already applied a later delete.
* - if last_complete >= log.bottom, then we know pg contents thru log.head.
* otherwise, we have no idea what the pg is supposed to contain.
*/
struct pg_info_t {
spg_t pgid;
eversion_t last_update; ///< last object version applied to store.
eversion_t last_complete; ///< last version pg was complete through.
epoch_t last_epoch_started; ///< last epoch at which this pg started on this osd
version_t last_user_version; ///< last user object version applied to store
eversion_t log_tail; ///< oldest log entry.
hobject_t last_backfill; ///< objects >= this and < last_complete may be missing
bool last_backfill_bitwise; ///< true if last_backfill reflects a bitwise (vs nibblewise) sort
interval_set<snapid_t> purged_snaps;
pg_stat_t stats;
pg_history_t history;
pg_hit_set_history_t hit_set;
};上面send_query()函数将要查询的pg_query_t::INFO放入RecoveryMachine的state中,然后会由OSD::process_peering_events()中的dispatch_context()来将消息发送出去:
void OSD::process_peering_events(
const list<PG*> &pgs,
ThreadPool::TPHandle &handle
)
{
...
dispatch_context(rctx, 0, curmap, &handle);
...
}
void OSD::dispatch_context(PG::RecoveryCtx &ctx, PG *pg, OSDMapRef curmap,
ThreadPool::TPHandle *handle)
{
if (service.get_osdmap()->is_up(whoami) && is_active()) {
do_notifies(*ctx.notify_list, curmap);
do_queries(*ctx.query_map, curmap);
do_infos(*ctx.info_map, curmap);
}
}
/** do_queries
* send out pending queries for info | summaries
*/
void OSD::do_queries(map<int, map<spg_t,pg_query_t> >& query_map,
OSDMapRef curmap)
{
for (map<int, map<spg_t,pg_query_t> >::iterator pit = query_map.begin();pit != query_map.end();++pit) {
if (!curmap->is_up(pit->first)) {
dout(20) << __func__ << " skipping down osd." << pit->first << dendl;
continue;
}
int who = pit->first;
ConnectionRef con = service.get_con_osd_cluster(who, curmap->get_epoch());
if (!con) {
dout(20) << __func__ << " skipping osd." << who
<< " (NULL con)" << dendl;
continue;
}
service.share_map_peer(who, con.get(), curmap);
dout(7) << __func__ << " querying osd." << who
<< " on " << pit->second.size() << " PGs" << dendl;
MOSDPGQuery *m = new MOSDPGQuery(curmap->get_epoch(), pit->second);
con->send_message(m);
}
}接着在从OSD接收到MSG_OSD_PG_QUERY消息后:
void OSD::dispatch_op(OpRequestRef op)
{
switch (op->get_req()->get_type()) {
case MSG_OSD_PG_CREATE:
handle_pg_create(op);
break;
case MSG_OSD_PG_NOTIFY:
handle_pg_notify(op);
break;
case MSG_OSD_PG_QUERY:
handle_pg_query(op);
break;
...
}
}
/** PGQuery
* from primary to replica | stray
* NOTE: called with opqueue active.
*/
void OSD::handle_pg_query(OpRequestRef op)
{
....
map< int, vector<pair<pg_notify_t, pg_interval_map_t> > > notify_list;
for (map<spg_t,pg_query_t>::iterator it = m->pg_list.begin();it != m->pg_list.end();++it) {
...
//处理在pg_map中找到了的PG的query请求
{
RWLock::RLocker l(pg_map_lock);
if (pg_map.count(pgid)) {
PG *pg = 0;
pg = _lookup_lock_pg_with_map_lock_held(pgid);
pg->queue_query(
it->second.epoch_sent, it->second.epoch_sent,
pg_shard_t(from, it->second.from), it->second);
pg->unlock();
continue;
}
}
//处理在PG_map中未找到的PG的query请求
}
do_notifies(notify_list, osdmap);
}
void PG::queue_query(epoch_t msg_epoch,
epoch_t query_epoch,
pg_shard_t from, const pg_query_t& q)
{
dout(10) << "handle_query " << q << " from replica " << from << dendl;
queue_peering_event(
CephPeeringEvtRef(std::make_shared<CephPeeringEvt>(msg_epoch, query_epoch,
MQuery(from, q, query_epoch))));
}
void OSD::process_peering_events(
const list<PG*> &pgs,
ThreadPool::TPHandle &handle
)
{
...
PG::CephPeeringEvtRef evt = pg->peering_queue.front();
pg->peering_queue.pop_front();
pg->handle_peering_event(evt, &rctx);
...
}
void PG::handle_peering_event(CephPeeringEvtRef evt, RecoveryCtx *rctx)
{
dout(10) << "handle_peering_event: " << evt->get_desc() << dendl;
if (!have_same_or_newer_map(evt->get_epoch_sent())) {
dout(10) << "deferring event " << evt->get_desc() << dendl;
peering_waiters.push_back(evt);
return;
}
if (old_peering_evt(evt))
return;
recovery_state.handle_event(evt, rctx);
}
boost::statechart::result PG::RecoveryState::Stray::react(const MQuery& query)
{
PG *pg = context< RecoveryMachine >().pg;
if (query.query.type == pg_query_t::INFO) {
pair<pg_shard_t, pg_info_t> notify_info;
pg->update_history_from_master(query.query.history);
pg->fulfill_info(query.from, query.query, notify_info);
context< RecoveryMachine >().send_notify(
notify_info.first,
pg_notify_t(
notify_info.first.shard, pg->pg_whoami.shard,
query.query_epoch,
pg->get_osdmap()->get_epoch(),
notify_info.second),
pg->past_intervals);
}
...
}
/** do_notifies
* Send an MOSDPGNotify to a primary, with a list of PGs that I have
* content for, and they are primary for.
*/
void OSD::do_notifies(
map<int,vector<pair<pg_notify_t,pg_interval_map_t> > >& notify_list,
OSDMapRef curmap)
{
for (map<int,vector<pair<pg_notify_t,pg_interval_map_t> > >::iterator it =notify_list.begin();it != notify_list.end();++it) {
if (!curmap->is_up(it->first)) {
dout(20) << __func__ << " skipping down osd." << it->first << dendl;
continue;
}
ConnectionRef con = service.get_con_osd_cluster(it->first, curmap->get_epoch());
if (!con) {
dout(20) << __func__ << " skipping osd." << it->first<< " (NULL con)" << dendl;
continue;
}
service.share_map_peer(it->first, con.get(), curmap);
dout(7) << __func__ << " osd " << it->first << " on " << it->second.size() << " PGs" << dendl;
MOSDPGNotify *m = new MOSDPGNotify(curmap->get_epoch(),it->second);
con->send_message(m);
}
}从上面我们可以看到查询pg_query_t::INFO时返回的是一个pg_notify_t类型的包装,其封装了pg_info_t数据结构。
注: 从上面OSD::handle_pg_query()的注释可看出,handle_pg_query()用于Primary OSD向replica/stray发送查询信息
之后,PG主OSD接收到pg_query_t::INFO的响应信息(MSG_OSD_PG_NOTIFY):
void OSD::dispatch_op(OpRequestRef op)
{
switch (op->get_req()->get_type()) {
case MSG_OSD_PG_CREATE:
handle_pg_create(op);
break;
case MSG_OSD_PG_NOTIFY:
handle_pg_notify(op);
break;
case MSG_OSD_PG_QUERY:
handle_pg_query(op);
break;
...
}
}
/** PGNotify
* from non-primary to primary
* includes pg_info_t.
* NOTE: called with opqueue active.
*/
void OSD::handle_pg_notify(OpRequestRef op)
{
for (vector<pair<pg_notify_t, pg_interval_map_t> >::iterator it = m->get_pg_list().begin();it != m->get_pg_list().end();++it) {
if (it->first.info.pgid.preferred() >= 0) {
dout(20) << "ignoring localized pg " << it->first.info.pgid << dendl;
continue;
}
handle_pg_peering_evt(
spg_t(it->first.info.pgid.pgid, it->first.to),
it->first.info.history, it->second,
it->first.query_epoch,
PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
it->first.epoch_sent, it->first.query_epoch,
PG::MNotifyRec(pg_shard_t(from, it->first.from), it->first,
op->get_req()->get_connection()->get_features())))
);
}
}
/*
* look up a pg. if we have it, great. if not, consider creating it IF the pg mapping
* hasn't changed since the given epoch and we are the primary.
*/
void OSD::handle_pg_peering_evt(
spg_t pgid,
const pg_history_t& orig_history,
pg_interval_map_t& pi,
epoch_t epoch,
PG::CephPeeringEvtRef evt)
{
}
boost::statechart::result PG::RecoveryState::GetInfo::react(const MNotifyRec& infoevt)
{
}上面获取到PG info之后交由GetInfo::react(const MNotifyRec&)进行处理。到此为止,GetInfo()流程执行完毕。
1.3.8 进入Started/Primary/Peering/GetLog状态
对于我们当前PG11.4而言,由于其不存在副本OSD了,因此其并没有走完整个GetInfo(),而是直接在GetInfo()构造函数中构造了一个GotInfo()事件,就直接进入GetLog()状态:
PG::RecoveryState::GetInfo::GetInfo(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Peering/GetInfo")
{
...
if (peer_info_requested.empty() && !prior_set->pg_down) {
post_event(GotInfo());
}
}
PG::RecoveryState::GetLog::GetLog(my_context ctx)
: my_base(ctx),
NamedState(
context< RecoveryMachine >().pg->cct, "Started/Primary/Peering/GetLog"),
msg(0)
{
...
}因为Peering完成之后,我们是想通过接受一个Activate事件,从而进入Active状态(注: 进入Active状态,就意味着我们可以重新进行数据的读写操作了),因此这里我们搜索Activate关键字,看在哪些情况下会产生该事件:
-
Primary状态下产生Activate事件的情形
-
在Started/Primary/Peering/GetMissing构造函数中,如果满足相应的条件会产生Activate事件
-
在Started/Primary/Peering/GetMissing状态下,接收到MLogRec事件后在其对应的react()函数中会触发产生Activate事件
-
在Started/Primary/Peering/WaitUpThru状态下,接收到ActMap事件后在其对应的react()函数中会触发产生Activate事件
-
-
Stray状态下产生Activate事件的情形
-
在Started/Stray状态下,接收到MLogRec事件后在其对应的react()函数中会触发产生Activate事件,从而触发进入ReplicaActive状态
-
在Started/Stray状态下,接收到MInfoRec事件后在其对应的react()函数中会触发产生Activate事件,从而触发进入ReplicaActive状态
-
这里我们先不理会在Stray状态下产生Activate事件,从而进入ReplicaActive状态的情形,我们主要关注在Peering状态下接收到Activate事件,从而进入Active状态的情形。因此在当前GetLog()状态下,结合状态转换图,我们主要需要了解如何先进入GetMissing状态以及WaitUpThru状态。
注:GetMissing、WaitUpThru状态接收到Activate事件,都是会调用其父状态Peering对Activate事件的处理。在Peering中,接收到Activate事件,是会直接进入到Active状态的。
如下我们再来看GetLog构造函数:
PG::RecoveryState::GetLog::GetLog(my_context ctx)
: my_base(ctx),
NamedState(
context< RecoveryMachine >().pg->cct, "Started/Primary/Peering/GetLog"),
msg(0)
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
// adjust acting?
if (!pg->choose_acting(auth_log_shard, false,&context< Peering >().history_les_bound)) {
if (!pg->want_acting.empty()) {
post_event(NeedActingChange());
} else {
post_event(IsIncomplete());
}
return;
}
// am i the best?
if (auth_log_shard == pg->pg_whoami) {
post_event(GotLog());
return;
}
const pg_info_t& best = pg->peer_info[auth_log_shard];
// am i broken?
if (pg->info.last_update < best.log_tail) {
dout(10) << " not contiguous with osd." << auth_log_shard << ", down" << dendl;
post_event(IsIncomplete());
return;
}
// how much log to request?
eversion_t request_log_from = pg->info.last_update;
assert(!pg->actingbackfill.empty());
for (set<pg_shard_t>::iterator p = pg->actingbackfill.begin();p != pg->actingbackfill.end();++p) {
if (*p == pg->pg_whoami) continue;
pg_info_t& ri = pg->peer_info[*p];
if (ri.last_update >= best.log_tail && ri.last_update < request_log_from)
request_log_from = ri.last_update;
}
// how much?
dout(10) << " requesting log from osd." << auth_log_shard << dendl;
context<RecoveryMachine>().send_query(
auth_log_shard,
pg_query_t(
pg_query_t::LOG,
auth_log_shard.shard, pg->pg_whoami.shard,
request_log_from, pg->info.history,
pg->get_osdmap()->get_epoch()));
assert(pg->blocked_by.empty());
pg->blocked_by.insert(auth_log_shard.osd);
pg->publish_stats_to_osd();
}这里结合osd3_watch_pg11.4.txt日志类分析一下:
1) 调用函数pg->choose_acting()来选择出拥有权威日志的OSD,并计算出acting_backfill和backfill_targets两个OSD列表。选择出来的权威OSD通过auth_log_shard参数返回;
2) 如果选择失败,并且want_acting不为空,就抛出NeedActingChange事件,状态机转移到Primary/WaitActingChange状态,等待申请临时PG返回结果;如果want_acting为空,就抛出IsIncomplete事件,PG的状态机转移到Primary/Peering/Incomplete状态,表明失败,PG就处于InComplete状态。
3) 如果auth_log_shard等于pg->pg_whoami,也就是选出的拥有权威日志的OSD为当前主OSD,直接抛出GotLog()完成GetLog过程;
4) 如果pg->info.last_update小于best.log_tail,也就是本OSD的日志和权威日志不重叠,那么本OSD无法恢复,抛出IsInComplete事件。经过函数choose_acting()的选择后,主OSD必须是可恢复的。如果主OSD不可恢复,必须申请临时PG,选择拥有权威日志的OSD为临时主OSD;
5)如果自己不是权威日志的OSD,则需要去拥有权威日志的OSD上去拉取权威日志,并与本地合并。发送pg_query_t::LOG请求的过程与pg_query_t::INFO的过程是一样的:
/** PGQuery
* from primary to replica | stray
* NOTE: called with opqueue active.
*/
void OSD::handle_pg_query(OpRequestRef op)
{
....
map< int, vector<pair<pg_notify_t, pg_interval_map_t> > > notify_list;
for (map<spg_t,pg_query_t>::iterator it = m->pg_list.begin();it != m->pg_list.end();++it) {
...
//处理在pg_map中找到了的PG的query请求
{
RWLock::RLocker l(pg_map_lock);
if (pg_map.count(pgid)) {
PG *pg = 0;
pg = _lookup_lock_pg_with_map_lock_held(pgid);
pg->queue_query(
it->second.epoch_sent, it->second.epoch_sent,
pg_shard_t(from, it->second.from), it->second);
pg->unlock();
continue;
}
}
//处理在PG_map中未找到的PG的query请求
}
do_notifies(notify_list, osdmap);
}
void PG::queue_query(epoch_t msg_epoch,
epoch_t query_epoch,
pg_shard_t from, const pg_query_t& q)
{
dout(10) << "handle_query " << q << " from replica " << from << dendl;
queue_peering_event(
CephPeeringEvtRef(std::make_shared<CephPeeringEvt>(msg_epoch, query_epoch,
MQuery(from, q, query_epoch))));
}
void OSD::process_peering_events(
const list<PG*> &pgs,
ThreadPool::TPHandle &handle
)
{
...
PG::CephPeeringEvtRef evt = pg->peering_queue.front();
pg->peering_queue.pop_front();
pg->handle_peering_event(evt, &rctx);
...
}
void PG::handle_peering_event(CephPeeringEvtRef evt, RecoveryCtx *rctx)
{
dout(10) << "handle_peering_event: " << evt->get_desc() << dendl;
if (!have_same_or_newer_map(evt->get_epoch_sent())) {
dout(10) << "deferring event " << evt->get_desc() << dendl;
peering_waiters.push_back(evt);
return;
}
if (old_peering_evt(evt))
return;
recovery_state.handle_event(evt, rctx);
}
boost::statechart::result PG::RecoveryState::Stray::react(const MQuery& query)
{
...
pg->fulfill_log(query.from, query.query, query.query_epoch);
...
}
void PG::fulfill_log(
pg_shard_t from, const pg_query_t &query, epoch_t query_epoch)
{
...
MOSDPGLog *mlog = new MOSDPGLog(
from.shard, pg_whoami.shard,
get_osdmap()->get_epoch(),
info, query_epoch);
mlog->missing = pg_log.get_missing();
// primary -> other, when building master log
if (query.type == pg_query_t::LOG) {
dout(10) << " sending info+missing+log since " << query.since << dendl;
if (query.since != eversion_t() && query.since < pg_log.get_tail()) {
osd->clog->error() << info.pgid << " got broken pg_query_t::LOG since " << query.since<< " when my log.tail is " << pg_log.get_tail() << ", sending full log instead\n";
mlog->log = pg_log.get_log(); // primary should not have requested this!!
} else
mlog->log.copy_after(pg_log.get_log(), query.since);
}
else if (query.type == pg_query_t::FULLLOG) {
dout(10) << " sending info+missing+full log" << dendl;
mlog->log = pg_log.get_log();
}
dout(10) << " sending " << mlog->log << " " << mlog->missing << dendl;
ConnectionRef con = osd->get_con_osd_cluster(
from.osd, get_osdmap()->get_epoch());
if (con) {
osd->share_map_peer(from.osd, con.get(), get_osdmap());
osd->send_message_osd_cluster(mlog, con.get());
} else {
mlog->put();
}
}接下来我们再来看看其中的几个函数的实现:
1.3.8.1 PG::choose_acting()
函数choose_acting()用来计算PG的acting_backfill和backfill_targets两个OSD列表。acting_backfill保存了当前PG的acting列表,包括需要进行Backfill操作的OSD列表;backfill_targets列表保存了需要进行Backfill的OSD列表。
bool PG::choose_acting(pg_shard_t &auth_log_shard_id,
bool restrict_to_up_acting,
bool *history_les_bound)
{
...
map<pg_shard_t, pg_info_t>::const_iterator auth_log_shard =
find_best_info(all_info, restrict_to_up_acting, history_les_bound);
if (auth_log_shard == all_info.end()) {
if (up != acting) {
dout(10) << "choose_acting no suitable info found (incomplete backfills?)," << " reverting to up" << dendl;
want_acting = up;
vector<int> empty;
osd->queue_want_pg_temp(info.pgid.pgid, empty);
} else {
dout(10) << "choose_acting failed" << dendl;
assert(want_acting.empty());
}
return false;
}
....
}1) 首先调用函数PG::find_best_info()来选举出一个拥有权威日志的OSD,保存在变量auth_log_shard里;
2) 如果没有选举出拥有权威日志的OSD,则进入如下流程:
a) 如果up不等于acting,申请临时PG,返回false值;
b) 否则确保want_acting列表为空,返回false值;
注: 在osdmap发生变化时,OSD::advance_pg()中会计算acting以及up,最终调用到OSDMap::_pg_to_up_acting_osds()来进行计算;
3) 计算是否是compat_mode模式,检查是,如果所有的OSD都支持纠删码,就设置compat_mode值为true;
4) 根据PG的不同类型,调用不同的函数。对应ReplicatedPG调用函数calc_replicated_acting()来计算PG需要的列表
//want_backfill为该PG需要进行Backfill的pg_shard
//want_acting_backfill: 包括进行acting和Backfill的pg_shard
set<pg_shard_t> want_backfill, want_acting_backfill;
//主OSD
vector<int> want;
//在compat_mode模式下,和want_acting_backfill相同
pg_shard_t want_primary;5) 下面是对PG做一些检查:
a) 计算num_want_acting数量,检查如果小于min_size,进行如下操作:
-
如果对于EC,清空want_acting,返回false;
-
对于ReplicatedPG,如果该PG不允许小于min_size的恢复,清空want_acting,返回false值;
b) 调用IsPGRecoverablePredicate来判断PG现有的OSD列表是否可以恢复,如果不能恢复,清空want_acting,返回false值
6) 检查如果want不等于acting,设置want_acting为want:
a) 如果want_acting等于up,申请empty为pg_temp的OSD列表;
b) 否则申请want为pg_temp的OSD列表;
7) 最后设置PG的actingbackfill为want_acting_backfill,设置backfill_targets为want_backfill,并检查backfill_targets里的pg_shard应该不在stray_set里面;
8) 最终返回true;
注: PG的acting set的设置主要会是在如下几个地方
1) OSD::load_pgs()函数中进行初始化时设置acting set
2) OSD::advance_pg()函数中,通过调用pg->handle_advance_map()产生AdvMap事件,从而引发PG进入Reset,在Reset的react(AdvMap)函数中start_peering_interval(),然后接着调用init_primary_up_acting()触发
3) OSD::handle_pg_peering_evt()函数中恢复一个正在删除的PG(do we need to resurrect a deleting pg?)
4) PG分裂
关于PG中的acting set、up set、want等我们可以这样理解: acting set是根据osdmap pg_temp的存在情况来确定的,反应的是当前阶段所希望达成的状态; want是当前实际能够工作的一个排列;up set初始是根据osdmap算出来的一个排列,但是假如当前acting不能满足需求的情况下,就会将up set设置为want。
下面举例说明需要申请pg_temp的场景:
1) 当前PG1.0,其acting列表和up列表都为[0,1,2],PG处于clean状态;
2) 此时,OSD0崩溃,导致该PG经过CRUSH算法重新获得acting和up列表都为[3, 1, 2];
3) 选择出拥有权威日志的OSD为1,经过PG::calc_replicated_acting()算法,want列表为[1, 3, 2],acting_backfill为[1,3,2],want_backfill为[3]。特别注意want列表第一个为主OSD,如果up_primary无法恢复,就选择权威日志的OSD为主OSD;
4) want[1,3,2]不等于acting[3,1,2],并且不等于up[3,1,2],需要向monitor申请pg_temp为want;
5) 申请成功pg_temp以后,acting为[3,1,2],up为[1,3,2],osd1作为临时的主OSD,处理读写请求。当PG恢复到clean状态时,pg_temp取消,acting和up都恢复为[3,1,2]。
1.3.8.2 PG::find_best_info()
函数find_best_info()用于选取一个拥有权威日志的OSD。根据last_epoch_clean到目前为止,各个past_interval期间参与该PG的所有目前还处于up状态的OSD上的pg_info_t信息,来选取一个拥有权威日志的OSD,选择的优先顺序如下:
1) 具有最新的last_update的OSD;
2) 如果条件1相同,选择日志更长的OSD;
3) 如果1,2条件相同,选择当前的主OSD;
/**
* find_best_info
*
* Returns an iterator to the best info in infos sorted by:
* 1) Prefer newer last_update
* 2) Prefer longer tail if it brings another info into contiguity
* 3) Prefer current primary
*/
map<pg_shard_t, pg_info_t>::const_iterator PG::find_best_info(
const map<pg_shard_t, pg_info_t> &infos,
bool restrict_to_up_acting,
bool *history_les_bound) const
{
assert(history_les_bound);
/* See doc/dev/osd_internals/last_epoch_started.rst before attempting
* to make changes to this process. Also, make sure to update it
* when you find bugs! */
*
eversion_t min_last_update_acceptable = eversion_t::max();
epoch_t max_last_epoch_started_found = 0;
for (map<pg_shard_t, pg_info_t>::const_iterator i = infos.begin();i != infos.end();++i) {
if (!cct->_conf->osd_find_best_info_ignore_history_les && max_last_epoch_started_found < i->second.history.last_epoch_started) {
*history_les_bound = true;
max_last_epoch_started_found = i->second.history.last_epoch_started;
}
if (!i->second.is_incomplete() && max_last_epoch_started_found < i->second.last_epoch_started) {
max_last_epoch_started_found = i->second.last_epoch_started;
}
}
for (map<pg_shard_t, pg_info_t>::const_iterator i = infos.begin(); i != infos.end(); ++i) {
if (max_last_epoch_started_found <= i->second.last_epoch_started) {
if (min_last_update_acceptable > i->second.last_update)
min_last_update_acceptable = i->second.last_update;
}
}
if (min_last_update_acceptable == eversion_t::max())
return infos.end();
map<pg_shard_t, pg_info_t>::const_iterator best = infos.end();
// find osd with newest last_update (oldest for ec_pool).
// if there are multiples, prefer
// - a longer tail, if it brings another peer into log contiguity
// - the current primary
for (map<pg_shard_t, pg_info_t>::const_iterator p = infos.begin();p != infos.end();++p) {
if (restrict_to_up_acting && !is_up(p->first) && !is_acting(p->first))
continue;
// Only consider peers with last_update >= min_last_update_acceptable
if (p->second.last_update < min_last_update_acceptable)
continue;
// disqualify anyone with a too old last_epoch_started
if (p->second.last_epoch_started < max_last_epoch_started_found)
continue;
// Disquality anyone who is incomplete (not fully backfilled)
if (p->second.is_incomplete())
continue;
if (best == infos.end()) {
best = p;
continue;
}
// Prefer newer last_update
if (pool.info.require_rollback()) {
if (p->second.last_update > best->second.last_update)
continue;
if (p->second.last_update < best->second.last_update) {
best = p;
continue;
}
} else {
if (p->second.last_update < best->second.last_update)
continue;
if (p->second.last_update > best->second.last_update) {
best = p;
continue;
}
}
// Prefer longer tail
if (p->second.log_tail > best->second.log_tail) {
continue;
} else if (p->second.log_tail < best->second.log_tail) {
best = p;
continue;
}
// prefer current primary (usually the caller), all things being equal
if (p->first == pg_whoami) {
dout(10) << "calc_acting prefer osd." << p->first << " because it is current primary" << dendl;
best = p;
continue;
}
}
return best;
}1) 首先在所有OSD中计算max_last_epoch_started,然后在拥有最大的last_epoch_started的OSD中计算min_last_update_acceptable的值;
2) 如果min_last_update_acceptable为eversion_t::max(),返回infos.end(),选取失败;
3) 根据以下条件选择一个OSD:
a) 首先过滤掉last_update小于min_last_update_acceptable,或者last_epoch_started小于max_last_epoch_started_found,或者incomplete的OSD;
b) 如果PG类型是EC,选择最小的last_update;如果PG类型是副本,选择最大的last_update的OSD;
c) 如果上述条件相同,选择log_tail最小的,也就是日志最长的OSD;
d) 如果上述条件都相同,选择当前的主OSD;
综上的选择过程可知,拥有权威日志的OSD特征如下:必须是非incomplete的OSD;必须有最大的last_epoch_started;last_update有可能是最大,但至少是min_last_update_acceptable,有可能是日志最长的OSD,有可能是主OSD。
1.3.8.3 PG::calc_replicated_acting
本函数用于计算本PG相关的OSD列表:
/**
* calculate the desired acting set.
*
* Choose an appropriate acting set. Prefer up[0], unless it is
* incomplete, or another osd has a longer tail that allows us to
* bring other up nodes up to date.
*/
void PG::calc_replicated_acting(
map<pg_shard_t, pg_info_t>::const_iterator auth_log_shard,
unsigned size,
const vector<int> &acting,
pg_shard_t acting_primary,
const vector<int> &up,
pg_shard_t up_primary,
const map<pg_shard_t, pg_info_t> &all_info,
bool compat_mode,
bool restrict_to_up_acting,
vector<int> *want,
set<pg_shard_t> *backfill,
set<pg_shard_t> *acting_backfill,
pg_shard_t *want_primary,
ostream &ss)
{
...
pg_shard_t auth_log_shard_id = auth_log_shard->first;
// select primary
map<pg_shard_t,pg_info_t>::const_iterator primary;
if (up.size() && !all_info.find(up_primary)->second.is_incomplete() &&
all_info.find(up_primary)->second.last_update >= auth_log_shard->second.log_tail) {
ss << "up_primary: " << up_primary << ") selected as primary" << std::endl;
primary = all_info.find(up_primary); // prefer up[0], all thing being equal
} else {
assert(!auth_log_shard->second.is_incomplete());
ss << "up[0] needs backfill, osd." << auth_log_shard_id << " selected as primary instead" << std::endl;
primary = auth_log_shard;
}
...
// select replicas that have log contiguity with primary.
// prefer up, then acting, then any peer_info osds
for (vector<int>::const_iterator i = up.begin();i != up.end();++i) {
...
}
// This no longer has backfill OSDs, but they are covered above.
for (vector<int>::const_iterator i = acting.begin();i != acting.end(); ++i) {
...
}
for (map<pg_shard_t,pg_info_t>::const_iterator i = all_info.begin();i != all_info.end();++i) {
...
}
}-
want_primary: 主OSD,如果它不是up_primary,就需要申请pg_temp;
-
backfill: 需要进行Backfill操作的OSD;
-
acting_backfill: 所有进行acting和Backfill的OSD的集合;
-
want和acting_backfill的OSD相同,前者类型是pg_shard_t,后者是int类型;
具体处理过程如下:
1) 首先选择want_primary:
a) 如果up_primary处于非incomplete状态,并且last_update大于等于权威日志的log_tail,说明up_primary的日志和权威日志有重叠,可通过日志记录恢复,优先选择up_primary为主OSD;
b) 否则选择auth_log_shard,也就是拥有权威日志的OSD为主OSD;
c) 把主OSD加入到want和acting_backfill列表中;
2) 函数的输入参数size为要选择的副本数,依次从up、acting、all_info里选择size个副本OSD:
a) 如果该OSD上的PG处于incomplete的状态,或者cur_info.last_update小于主OSD和auth_log_shard的最小值,则该PG副本无法通过日志修复,只能通过Backfill操作来进行修复。把该OSD分别加入backfill和acting_backfill集合中;
b) 否则就可以根据PG日志来恢复,只加入acting_backfill集合和want列表中,不用加入到Backfill列表中;
1.3.8.3 GetLog阶段日志分析
下面我们就结合PG 11.4在这一阶段的日志来进行分析:
3593:2020-09-11 14:05:19.135595 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] enter Started/Primary/Peering/GetLog
3596:2020-09-11 14:05:19.135609 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] calc_acting osd.3 11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223)
3599:2020-09-11 14:05:19.135632 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] calc_acting newest update on osd.3 with 11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223)
3601:calc_acting primary is osd.3 with 11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223)
3603:2020-09-11 14:05:19.135659 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] actingbackfill is 3
3605:2020-09-11 14:05:19.135668 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] choose_acting want [3] (== acting) backfill_targets
3607:2020-09-11 14:05:19.135684 7fba3d124700 10 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] state<Started/Primary/Peering/GetLog>: leaving GetLog
3609:2020-09-11 14:05:19.135698 7fba3d124700 5 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] exit Started/Primary/Peering/GetLog 0.000102 0 0.000000
3611:2020-09-11 14:05:19.135712 7fba3d124700 15 osd.3 pg_epoch: 2223 pg[11.4( v 201'1 (0'0,201'1] local-les=2222 n=1 ec=132 les/c/f 2222/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 peering] publish_stats_to_osd 2223: no change since 2020-09-11 14:05:19.135569在上面3593行开始进入GetLog阶段,之后在PG::choose_acting()中打印出获取到的所有pg_info信息(此时只有osd.3上具有PG 11.4的信息了),对于PG 11.4的主OSD3来说Peering尚未完成,因此其pg_info.last_epoch_started为e2222(当前osdmap的epoch为e2223),pg_info.history.last_epoch_started的值也为e2222。
注: 上面les是last_epoch_started的缩写, c是last_epoch_clean的缩写, f是last_epoch_marked_full的缩写
在PG::calc_replicated_acting()函数中计算出来的actingbackfill值为[3],want值也为[3]。此外,由于acting的值也为[3](注: 在osdmap发生变化时已经计算过了),因此want等于acting,不必申请pg_temp。
1.3.9 收到缺失的权威日志
如果主OSD不是拥有权威日志的OSD,就需要去拥有权威日志的OSD上拉取权威日志。当收到权威日志后的处理流程如下:
void OSD::dispatch_op(OpRequestRef op)
{
switch (op->get_req()->get_type()) {
...
case MSG_OSD_PG_LOG:
handle_pg_log(op);
break;
...
}
}
void OSD::handle_pg_log(OpRequestRef op)
{
MOSDPGLog *m = (MOSDPGLog*) op->get_req();
assert(m->get_type() == MSG_OSD_PG_LOG);
dout(7) << "handle_pg_log " << *m << " from " << m->get_source() << dendl;
if (!require_osd_peer(op->get_req()))
return;
int from = m->get_source().num();
if (!require_same_or_newer_map(op, m->get_epoch(), false))
return;
if (m->info.pgid.preferred() >= 0) {
dout(10) << "ignoring localized pg " << m->info.pgid << dendl;
return;
}
op->mark_started();
handle_pg_peering_evt(
spg_t(m->info.pgid.pgid, m->to),
m->info.history, m->past_intervals, m->get_epoch(),
PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
m->get_epoch(), m->get_query_epoch(),
PG::MLogRec(pg_shard_t(from, m->from), m)))
);
}
boost::statechart::result PG::RecoveryState::GetLog::react(const MLogRec& logevt)
{
assert(!msg);
if (logevt.from != auth_log_shard) {
dout(10) << "GetLog: discarding log from "<< "non-auth_log_shard osd." << logevt.from << dendl;
return discard_event();
}
dout(10) << "GetLog: received master log from osd"<< logevt.from << dendl;
msg = logevt.msg;
post_event(GotLog());
return discard_event();
}上面将logevt.msg赋值给msg(注:msg的类型为MLogRec)并抛出GotLog()事件。本函数就用于处理该事件。它首先确认是从auth_log_shard端发送的消息,然后抛出GotLog()事件:
boost::statechart::result PG::RecoveryState::GetLog::react(const GotLog&)
{
dout(10) << "leaving GetLog" << dendl;
PG *pg = context< RecoveryMachine >().pg;
if (msg) {
dout(10) << "processing master log" << dendl;
pg->proc_master_log(*context<RecoveryMachine>().get_cur_transaction(),
msg->info, msg->log, msg->missing,
auth_log_shard);
}
pg->start_flush(
context< RecoveryMachine >().get_cur_transaction(),
context< RecoveryMachine >().get_on_applied_context_list(),
context< RecoveryMachine >().get_on_safe_context_list());
return transit< GetMissing >();
}本函数捕获GotLog()事件,处理过程如下:
1) 如果msg不为空,就调用函数PG::proc_master_log()合并自己缺失的权威日志,并更新自己的pg_info相关的信息。从此,作为主OSD,也是拥有权威日志的OSD。
void PG::proc_master_log(
ObjectStore::Transaction& t, pg_info_t &oinfo,
pg_log_t &olog, pg_missing_t& omissing, pg_shard_t from)
{
dout(10) << "proc_master_log for osd." << from << ": "<< olog << " " << omissing << dendl;
assert(!is_peered() && is_primary());
// merge log into our own log to build master log. no need to
// make any adjustments to their missing map; we are taking their
// log to be authoritative (i.e., their entries are by definitely
// non-divergent).
merge_log(t, oinfo, olog, from);
peer_info[from] = oinfo;
dout(10) << " peer osd." << from << " now " << oinfo << " " << omissing << dendl;
might_have_unfound.insert(from);
// See doc/dev/osd_internals/last_epoch_started
if (oinfo.last_epoch_started > info.last_epoch_started) {
info.last_epoch_started = oinfo.last_epoch_started;
dirty_info = true;
}
if (info.history.merge(oinfo.history))
dirty_info = true;
assert(cct->_conf->osd_find_best_info_ignore_history_les ||
info.last_epoch_started >= info.history.last_epoch_started);
peer_missing[from].swap(omissing);
}
2) 调用函数pg->start_flush()添加一个空操作;
3) 状态转移到GetMissing状态;
经过GetLog阶段的处理后,该PG的主OSD已经获取了权威日志,以及pg_info的权威信息。
1.3.10 Started/Primary/Peering/GetMissing状态
在GetLog()状态中,如果Primary获取到了权威日志,在抛出的GotLog事件中调用PG::proc_master_log()处理了权威日志后,就会直接转换进入到GetMissing状态。
GetMissing的处理过程为: 首先,拉取各个从OSD上的有效日志。其次,用主OSD上的权威日志与各个从OSD上的日志进行对比,从而计算出各个从OSD上不一致的对象并保存在对应的pg_missing_t结构中,作为后续数据修复的依据。
主OSD的不一致的对象信息,已经在调用PG::proc_master_log()合并权威日志的过程中计算出来,所以这里只计算从OSD上不一致对象。
1.3.10.1 拉取从副本上的日志
在GetMissing()的构造函数里,通过对比主OSD上的权威pg_info信息,来获取从OSD上的日志信息:
PG::RecoveryState::GetMissing::GetMissing(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Peering/GetMissing")
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
assert(!pg->actingbackfill.empty());
for (set<pg_shard_t>::iterator i = pg->actingbackfill.begin();i != pg->actingbackfill.end();++i) {
if (*i == pg->get_primary()) continue;
const pg_info_t& pi = pg->peer_info[*i];
if (pi.is_empty())
continue; // no pg data, nothing divergent
if (pi.last_update < pg->pg_log.get_tail()) {
dout(10) << " osd." << *i << " is not contiguous, will restart backfill" << dendl;
pg->peer_missing[*i];
continue;
}
if (pi.last_backfill == hobject_t()) {
dout(10) << " osd." << *i << " will fully backfill; can infer empty missing set" << dendl;
pg->peer_missing[*i];
continue;
}
if (pi.last_update == pi.last_complete && // peer has no missing
pi.last_update == pg->info.last_update) { // peer is up to date
// replica has no missing and identical log as us. no need to
// pull anything.
// FIXME: we can do better here. if last_update==last_complete we
// can infer the rest!
dout(10) << " osd." << *i << " has no missing, identical log" << dendl;
pg->peer_missing[*i];
continue;
}
// We pull the log from the peer's last_epoch_started to ensure we
// get enough log to detect divergent updates.
eversion_t since(pi.last_epoch_started, 0);
assert(pi.last_update >= pg->info.log_tail); // or else choose_acting() did a bad thing
if (pi.log_tail <= since) {
dout(10) << " requesting log+missing since " << since << " from osd." << *i << dendl;
context< RecoveryMachine >().send_query(
*i,
pg_query_t(
pg_query_t::LOG,
i->shard, pg->pg_whoami.shard,
since, pg->info.history,
pg->get_osdmap()->get_epoch()));
} else {
dout(10) << " requesting fulllog+missing from osd." << *i<< " (want since " << since << " < log.tail " << pi.log_tail << ")"<< dendl;
context< RecoveryMachine >().send_query(
*i, pg_query_t(
pg_query_t::FULLLOG,
i->shard, pg->pg_whoami.shard,
pg->info.history, pg->get_osdmap()->get_epoch()));
}
peer_missing_requested.insert(*i);
pg->blocked_by.insert(i->osd);
}
if (peer_missing_requested.empty()) {
if (pg->need_up_thru) {
dout(10) << " still need up_thru update before going active" << dendl;
post_event(NeedUpThru());
return;
}
// all good!
post_event(Activate(pg->get_osdmap()->get_epoch()));
} else {
pg->publish_stats_to_osd();
}
}上述代码具体处理过程为遍历pg->actingbackfill的OSD列表,然后做如下的处理:
1) 不需要获取PG日志的情况:
a) pi.is_empty()为true,没有任何信息,需要Backfill过程来修复,不需要获取日志;
b) pi.last_update小于pg->pg_log.get_tail(),该OSD的pg_info记录中,last_update小于权威日志的尾部,该OSD的日志和权威日志不重叠,该OSD操作已经远远落后于权威OSD,已经无法根据日志来修复,需要继续Backfill的过程;
c) pi.last_backfill为hobject_t(),说明在past_interval期间,该OSD标记需要Backfill操作,实际并没开始Backfill的工作,需要继续Backfill过程;
d) pi.last_update等于pi.last_complete,说明该PG没有丢失的对象,已经完成Recovery操作阶段,并且pi.last_update等于pg->info.last_update,说明日志和权威日志的最后更新一致,说明该PG数据完整,不需要恢复。
2) 获取日志的情况:当pi.last_update大于等于pg->info.log_tail,说明该OSD的日志记录和权威日志记录重叠,可以通过日志来修复。变量since是从last_epoch_started开始的版本值:
a) 如果该PG的日志记录pi.log_tail小于等于版本值since,那就发送消息pg_query_t::LOG,从since开始获取日志记录;
b) 如果该PG的日志记录pi.log_tail大于版本值since,就发送消息pg_query_t::FULLLOG来获取该OSD的全部日志记录。
3) 最后检查如果peer_missing_requested为空,说明所有获取日志的请求返回并处理完成。如果需要pg->need_up_thru,抛出post_event(NeedUpThru());否则,直接调用post_event(Activate(pg->get_osdmap()->get_epoch()))进入Activate状态。
下面举例说明获取日志的两种情况:

当前last_epoch_started的值为10, since是last_epoch_started后的首个日志版本值。当前需要恢复的有效日志是经过since操作之后的日志,之前的日志已经没有了。
对应OSD0,其日志log_tail大于since,全部拷贝osd0上的日志;对应osd1,其日志log_tail小于since,只拷贝从since开始的日志记录。
1.3.10.2 收到从副本上的日志记录处理
当一个PG的主OSD收到从OSD返回的获取日志ACK应答后,就把该消息封装成MLogRec事件。状态GetMissing接收到该事件后,在下列事件函数里处理该事件:
boost::statechart::result PG::RecoveryState::GetMissing::react(const MLogRec& logevt)
{
PG *pg = context< RecoveryMachine >().pg;
peer_missing_requested.erase(logevt.from);
pg->proc_replica_log(*context<RecoveryMachine>().get_cur_transaction(),
logevt.msg->info, logevt.msg->log, logevt.msg->missing, logevt.from);
if (peer_missing_requested.empty()) {
if (pg->need_up_thru) {
dout(10) << " still need up_thru update before going active" << dendl;
post_event(NeedUpThru());
} else {
dout(10) << "Got last missing, don't need missing " << "posting CheckRepops" << dendl;
post_event(Activate(pg->get_osdmap()->get_epoch()));
}
}
return discard_event();
}具体处理过程如下:
1) 调用PG::proc_replica_log()处理日志。通过日志的对比,获取该OSD上处于missing状态的对象列表;
2) 如果peering_missing_requested为空,即所有的获取日志请求返回并处理。如果需要pg->need_up_thru,抛出NeedUpThru()事件;否则,直接调用函数post_event(Activate(pg->get_osdmap()->get_epoch()))进入Activate状态。
函数PG::proc_replica_log()处理各个从OSD上发过来的日志。它通过比较该OSD的日志和本地权威日志,来计算OSD上处于missing状态的对象列表。具体处理过程调用pg_log.proc_replica_log()来处理日志,输出为omissing,也就是OSD缺失的对象。
1.4 Started/Primary/Peering/WaitUpThru状态
在前面Started/Primary/Peering/GetInfo状态时,我们通过调用PG::build_prior()已经判断出PG 11.4的need_up_thru值为true,因此会进入WaitUpThru状态:
PG::RecoveryState::WaitUpThru::WaitUpThru(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Peering/WaitUpThru")
{
context< RecoveryMachine >().log_enter(state_name);
}之后获取到相应的UpThru之后,就会通过如下退出WaitUpThru状态:
boost::statechart::result PG::RecoveryState::WaitUpThru::react(const ActMap& am)
{
PG *pg = context< RecoveryMachine >().pg;
if (!pg->need_up_thru) {
post_event(Activate(pg->get_osdmap()->get_epoch()));
}
return forward_event();
}1.5 Active操作
由上可知,如果GetMissing()处理成功,就产生Activate()事件,该事件对于Primary OSD来说会跳转到Active状态:
struct Peering : boost::statechart::state< Peering, Primary, GetInfo >, NamedState {
std::unique_ptr< PriorSet > prior_set;
bool history_les_bound; //< need osd_find_best_info_ignore_history_les
explicit Peering(my_context ctx);
void exit();
typedef boost::mpl::list <
boost::statechart::custom_reaction< QueryState >,
boost::statechart::transition< Activate, Active >,
boost::statechart::custom_reaction< AdvMap >
> reactions;
>
boost::statechart::result react(const QueryState& q);
boost::statechart::result react(const AdvMap &advmap);
};其实到了本阶段为止,可以说peering主要工作已经完成,主OSD已经进入了Active状态。但还需要后续的处理,激活各个副本,如下所示:
PG::RecoveryState::Active::Active(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Active"),
remote_shards_to_reserve_recovery(
unique_osd_shard_set(
context< RecoveryMachine >().pg->pg_whoami,
context< RecoveryMachine >().pg->actingbackfill)),
remote_shards_to_reserve_backfill(
unique_osd_shard_set(
context< RecoveryMachine >().pg->pg_whoami,
context< RecoveryMachine >().pg->backfill_targets)),
all_replicas_activated(false)
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
assert(!pg->backfill_reserving);
assert(!pg->backfill_reserved);
assert(pg->is_primary());
dout(10) << "In Active, about to call activate" << dendl;
pg->start_flush(
context< RecoveryMachine >().get_cur_transaction(),
context< RecoveryMachine >().get_on_applied_context_list(),
context< RecoveryMachine >().get_on_safe_context_list());
pg->activate(*context< RecoveryMachine >().get_cur_transaction(),
pg->get_osdmap()->get_epoch(),
*context< RecoveryMachine >().get_on_safe_context_list(),
*context< RecoveryMachine >().get_query_map(),
context< RecoveryMachine >().get_info_map(),
context< RecoveryMachine >().get_recovery_ctx());
// everyone has to commit/ack before we are truly active
pg->blocked_by.clear();
for (set<pg_shard_t>::iterator p = pg->actingbackfill.begin();p != pg->actingbackfill.end();++p) {
if (p->shard != pg->pg_whoami.shard) {
pg->blocked_by.insert(p->shard);
}
}
pg->publish_stats_to_osd();
dout(10) << "Activate Finished" << dendl;
}状态Active的构造函数里处理过程如下:
1) 在构造函数里初始化了remote_shards_to_reserve_recovery和remote_shards_to_reserve_backfill,需要Recovery操作和Backfill操作的OSD;
2) 调用函数pg->start_flush()来完成相关数据的flush工作;
3) 调用函数pg->activate()完成最后的激活工作。
此时,由于PG 11.4当前的映射为[3],因此显示的状态为active+undersized+degraded。
注: 进入Active状态后,默认进入其初始子状态Started/Primary/Active/Activating
1.5.1 MissingLoc
在讲解pg->activate()之前,我们先介绍一下其中使用到的MissingLoc。类MIssingLoc用来记录处于missing状态对象的位置,也就是缺失对象的正确版本分别在哪些OSD上。恢复时就去这些OSD上去拉取正确对象的对象数据:
class MissingLoc {
//缺失的对象 ---> item(现在版本,缺失的版本)
map<hobject_t, pg_missing_t::item, hobject_t::BitwiseComparator> needs_recovery_map;
//缺失的对象 ---> 所在的OSD集合
map<hobject_t, set<pg_shard_t>, hobject_t::BitwiseComparator > missing_loc;
//所有缺失对象所在的OSD集合
set<pg_shard_t> missing_loc_sources;
PG *pg;
set<pg_shard_t> empty_set;
};下面介绍一些MissingLoc处理函数,作用是添加相应的missing对象列表。其对应两个函数:add_active_missing()函数和add_source_info()函数。
- add_active_missing()函数: 用于把一个副本中的所有缺失对象添加到MissingLoc的needs_recovery_map结构里
void add_active_missing(const pg_missing_t &missing) {
...
}- add_source_info()函数: 用于计算每个缺失对象是否在本OSD上
/// Adds info about a possible recovery source
bool add_source_info(
pg_shard_t source, ///< [in] source
const pg_info_t &oinfo, ///< [in] info
const pg_missing_t &omissing, ///< [in] (optional) missing
bool sort_bitwise, ///< [in] local sort bitwise (vs nibblewise)
ThreadPool::TPHandle* handle ///< [in] ThreadPool handle
); 具体实现如下:
遍历needs_recovery_map里的所有对象,对每个对象做如下处理:
1) 如果oinfo.last_update < need(所缺失的对象版本),就跳过;
2) 如果该PG正常的last_backfill指针小于MAX值,说明还处于Backfill阶段,但是sort_bitwise不正确,跳过;
3) 如果该对象大于last_backfill,显然该对象不存在,跳过;
4) 如果该对象大于last_complete,说明该对象或者是上次Peering之后缺失的对象,还没有来得及修复;或者是新创建的对象。检查如果missing记录已存在,就是上次缺失的对象,直接跳过;否则就是新创建的对象,存在该OSD中;
5)经过上述检查后,确认该对象在本OSD上,在missing_loc添加该对象的location为本OSD。
1.5.2 activate操作
PG::activate()函数是主OSD进入Active状态后执行的第一步操作:
void PG::activate(ObjectStore::Transaction& t,
epoch_t activation_epoch,
list<Context*>& tfin,
map<int, map<spg_t,pg_query_t> >& query_map,
map<int,
vector<
pair<pg_notify_t,
pg_interval_map_t> > > *activator_map,
RecoveryCtx *ctx)
{
}该函数完成以下功能:
-
更新一些pg_info的参数信息
-
给replica发消息,激活副本PG;
-
计算MissingLoc,也就是缺失对象分布在哪些OSD上,用于后续的恢复;
具体的处理过程如下:
1) 如果需要客户回答,就把PG添加到replay_queue队列里;
2) 更新info.last_epoch_started变量,info.last_epoch_started指的是本OSD在完成目前Peering进程后的更新,而info.history.last_epoch_started是PG的所有OSD都确认完成Peering的更新。
3) 更新一些相关的字段;
4) 注册C_PG_ActivateCommitted()回调函数,该函数最终完成activate的工作;
5) 初始化snap_trimq快照相关的变量;
6) 设置info.last_complete指针:
-
如果missing.num_missing()等于0,表明处于clean状态。直接更新info.last_complete等于info.last_update,并调用pg_log.reset_recovery_pointers()调整log的complete_to指针;
-
否则,如果有需要恢复的对象,就调用函数pg_log.activate_not_complete(info),设置info.last_complete为缺失的第一个对象的前一个版本。
7) 以下都是主OSD的操作,给每个从OSD发送MOSDPGLog类型的消息,激活该PG的从OSD上的副本。分别对应三种不同处理:
void PG::activate(ObjectStore::Transaction& t,
epoch_t activation_epoch,
list<Context*>& tfin,
map<int, map<spg_t,pg_query_t> >& query_map,
map<int,
vector<
pair<pg_notify_t,
pg_interval_map_t> > > *activator_map,
RecoveryCtx *ctx)
{
...
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
...
if (pi.last_update == info.last_update && !force_restart_backfill){
...
}else if (pg_log.get_tail() > pi.last_update || pi.last_backfill == hobject_t() ||
force_restart_backfill || (backfill_targets.count(*i) && pi.last_backfill.is_max())) {
...
}else{
}
}
}-
如果pi.last_update等于info.last_update,这种情况下,该OSD本身就是clean的,不需要给该OSD发送其他信息。添加到activator_map只发送pg_info来激活从OSD。其最终的执行在PeeringWQ的线程执行完状态机的事件处理后,在函数OSD::dispatch_context()里调用OSD::do_info()函数实现;
-
需要Backfill操作的OSD,发送pg_info,以及osd_min_pg_log_entries数量的PG日志;
-
需要Recovery操作的OSD,发送pg_info,以及从缺失的日志;
8) 设置MissingLoc,也就是统计缺失的对象,以及缺失的对象所在的OSD,核心就是调用MissingLoc的add_source_info()函数,见MissingLoc的相关分析;
9) 如果需要恢复,把该PG加入到osd->queue_for_recovery(this)的恢复队列中;
10) 如果PG当前acting set的size小于该PG所在pool设置的副本size,也就是当前的OSD不够,就标记PG的状态为PG_STATE_DEGRADED和PG_STATE_UNDERSIZED ,最后标记PG为PG_STATE_ACTIVATING状态;
1.5.3 收到从OSD的MOSDPGLog的应答
当收到从OSD发送的对MOSDPGLog的ACK消息后,触发MInfoRec事件,下面这个函数处理该事件:
boost::statechart::result PG::RecoveryState::Active::react(const MInfoRec& infoevt)
{
PG *pg = context< RecoveryMachine >().pg;
assert(pg->is_primary());
assert(!pg->actingbackfill.empty());
// don't update history (yet) if we are active and primary; the replica
// may be telling us they have activated (and committed) but we can't
// share that until _everyone_ does the same.
if (pg->is_actingbackfill(infoevt.from)) {
dout(10) << " peer osd." << infoevt.from << " activated and committed" << dendl;
pg->peer_activated.insert(infoevt.from);
pg->blocked_by.erase(infoevt.from.shard);
pg->publish_stats_to_osd();
if (pg->peer_activated.size() == pg->actingbackfill.size()) {
pg->all_activated_and_committed();
}
}
return discard_event();
}处理过程比较简单:检查该请求的源OSD在本PG的actingbackfill列表中,以及在等待列表中删除该OSD。最后检查,当收集到所有从OSD发送的ACK,就调用函数all_activated_and_committed():
/*
* update info.history.last_epoch_started ONLY after we and all
* replicas have activated AND committed the activate transaction
* (i.e. the peering results are stable on disk).
*/
void PG::all_activated_and_committed()
{
dout(10) << "all_activated_and_committed" << dendl;
assert(is_primary());
assert(peer_activated.size() == actingbackfill.size());
assert(!actingbackfill.empty());
assert(blocked_by.empty());
queue_peering_event(
CephPeeringEvtRef(
std::make_shared<CephPeeringEvt>(
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
AllReplicasActivated())));
}该函数产生一个AllReplicasActivated()事件。
对应主OSD在事务的回调函数C_PG_ActivateCommitted()里实现,最终调用PG::_activate_committed()加入peer_activated集合里:
void PG::_activate_committed(epoch_t epoch, epoch_t activation_epoch);注: Replica收到主OSD发送的MOSDPGLog消息,会进入ReplicaAcitve状态,然后也会调用PG::activate()函数,从而也会调用到PG::_activate_committed()函数,在该函数里向主OSD发出ACK响应。
1.5.4 AllReplicasActivated
如下函数用于处理AllReplicasActivated事件:
boost::statechart::result PG::RecoveryState::Active::react(const AllReplicasActivated &evt)
{
PG *pg = context< RecoveryMachine >().pg;
all_replicas_activated = true;
pg->state_clear(PG_STATE_ACTIVATING);
pg->state_clear(PG_STATE_CREATING);
if (pg->acting.size() >= pg->pool.info.min_size) {
pg->state_set(PG_STATE_ACTIVE);
} else {
pg->state_set(PG_STATE_PEERED);
}
// info.last_epoch_started is set during activate()
pg->info.history.last_epoch_started = pg->info.last_epoch_started;
pg->dirty_info = true;
pg->share_pg_info();
pg->publish_stats_to_osd();
pg->check_local();
// waiters
if (pg->flushes_in_progress == 0) {
pg->requeue_ops(pg->waiting_for_peered);
}
pg->on_activate();
return discard_event();
}当所有的replica处于activated状态时,进行如下处理:
1) 取消PG_STATE_ACTIVATING和PG_STATE_CREATING状态,如果该PG上acting状态的OSD数量大于等于pool的min_size,那么设置该PG为PG_STATE_ACTIVE状态,否则设置为PG_STATE_PEERED状态;
2) 调用pg->share_pg_info()函数向actingbackfill列表中的Replicas发送最新的pg_info_t信息;
3) 调用ReplicatedPG::check_local()检查本地的stray objects是否被删除;
4) 如果有读写请求在等待peering操作完成,则把该请求添加到处理队列pg->requeue_ops(pg->waiting_for_peered);
5) 调用函数ReplicatedPG::on_activate(),如果需要Recovery操作,触发DoRecovery事件;如果需要Backfill操作,触发RequestBackfill事件;否则,触发AllReplicasRecovered事件。
6) 初始化Cache Tier需要的hit_set对象;
7) 初始化Cache Tier需要的agent对象;
注: 在ReplicatedPG::do_request()函数中,如果发现当前PG没有peering成功,那么将会将相应的请求保存到waiting_for_peered队列中。详细请参看OSD的读写流程。
在本例子PG 11.4中,我们不需要进行Recovery操作,也不需要进行Backfill操作,因此触发AllReplicasRecovered事件进入Recovered状态:
9724:2020-09-11 14:05:19.902727 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] needs_recovery is recovered
9727:2020-09-11 14:05:19.902736 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] needs_backfill does not need backfill
9730:2020-09-11 14:05:19.902745 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] activate all replicas clean, no recovery
9734:2020-09-11 14:05:19.902757 7fba3d124700 15 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] publish_stats_to_osd 2224: no change since 2020-09-11 14:05:19.902708
9736:2020-09-11 14:05:19.902765 7fba3d124700 20 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] hit_set_clear
9738:2020-09-11 14:05:19.902772 7fba3d124700 20 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] agent_stop
9747:2020-09-11 14:05:19.902799 7fba3d124700 30 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] lock
9750:2020-09-11 14:05:19.902808 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] handle_peering_event: epoch_sent: 2224 epoch_requested: 2224 FlushedEvt
9753:2020-09-11 14:05:19.902817 7fba3d124700 15 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] requeue_ops
10071:2020-09-11 14:05:19.904183 7fba3d124700 30 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] lock
10072:2020-09-11 14:05:19.904190 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] handle_peering_event: epoch_sent: 2224 epoch_requested: 2224 AllReplicasRecovered
10073:2020-09-11 14:05:19.904198 7fba3d124700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] exit Started/Primary/Active/Activating 0.036851 4 0.000283
10076:2020-09-11 14:05:19.904207 7fba3d124700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] enter Started/Primary/Active/Recovered
10078:2020-09-11 14:05:19.904216 7fba3d124700 10 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] needs_recovery is recovered
10080:2020-09-11 14:05:19.904225 7fba3d124700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] exit Started/Primary/Active/Recovered 0.000018 0 0.000000
10082:2020-09-11 14:05:19.904234 7fba3d124700 5 osd.3 pg_epoch: 2224 pg[11.4( v 201'1 (0'0,201'1] local-les=2224 n=1 ec=132 les/c/f 2224/2222/0 2223/2223/2223) [3] r=0 lpr=2223 pi=2215-2222/3 crt=201'1 lcod 0'0 mlcod 0'0 active+undersized+degraded] enter Started/Primary/Active/Clean参看如下代码:
PG::RecoveryState::Recovered::Recovered(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Active/Recovered")
{
pg_shard_t auth_log_shard;
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
pg->osd->local_reserver.cancel_reservation(pg->info.pgid);
assert(!pg->needs_recovery());
// if we finished backfill, all acting are active; recheck if
// DEGRADED | UNDERSIZED is appropriate.
assert(!pg->actingbackfill.empty());
if (pg->get_osdmap()->get_pg_size(pg->info.pgid.pgid) <=
pg->actingbackfill.size()) {
pg->state_clear(PG_STATE_DEGRADED);
pg->publish_stats_to_osd();
}
// adjust acting set? (e.g. because backfill completed...)
bool history_les_bound = false;
if (pg->acting != pg->up && !pg->choose_acting(auth_log_shard,
true, &history_les_bound))
assert(pg->want_acting.size());
if (context< Active >().all_replicas_activated)
post_event(GoClean());
}进入Started/Primary/Active/Recovered状态后,调用OSDMap::get_pg_size()来计算PG的副本个数:
unsigned get_pg_size(pg_t pg) const {
map<int64_t,pg_pool_t>::const_iterator p = pools.find(pg.pool());
assert(p != pools.end());
return p->second.get_size();
}从上面可以看到其实是计算该PG所在pool的副本数。在这里PG 11.4所在的pool的副本数为2,而当前pg->actingbackfill.size()为1,因此仍处于DEGRADED状态。
最后判断all_replicas_activated变量,如果所有副本均已激活,那么进入Clean状态。
1.6 副本端的状态转移
当创建PG后,根据不同的角色,如果是主OSD,PG对应的状态机就进入Primary状态; 如果不是主OSD,就进入Stray状态。
1.6.1 Stray状态
Stray状态有两种情况:
情况1: 只接收到PGINFO的处理
boost::statechart::result PG::RecoveryState::Stray::react(const MInfoRec& infoevt)
{
PG *pg = context< RecoveryMachine >().pg;
dout(10) << "got info from osd." << infoevt.from << " " << infoevt.info << dendl;
if (pg->info.last_update > infoevt.info.last_update) {
// rewind divergent log entries
ObjectStore::Transaction* t = context<RecoveryMachine>().get_cur_transaction();
pg->rewind_divergent_log(*t, infoevt.info.last_update);
pg->info.stats = infoevt.info.stats;
pg->info.hit_set = infoevt.info.hit_set;
}
assert(infoevt.info.last_update == pg->info.last_update);
assert(pg->pg_log.get_head() == pg->info.last_update);
post_event(Activate(infoevt.info.last_epoch_started));
return transit<ReplicaActive>();
}从PG接收到主PG发送的MInfoRec事件,也就是接收到主OSD发送的pg_info信息。其判断如果当前pg->info.last_update大于infoevt.info.last_update,说明当前的日志有divergent的日志,调用函数PG::rewind_divergent_log()清理日志即可。最后抛出Activate(infoevt.info.last_epoch_started)事件,进入ReplicaActive状态。
情况2: 接收到MOSDPGLog消息
boost::statechart::result PG::RecoveryState::Stray::react(const MLogRec& logevt)
{
PG *pg = context< RecoveryMachine >().pg;
MOSDPGLog *msg = logevt.msg.get();
dout(10) << "got info+log from osd." << logevt.from << " " << msg->info << " " << msg->log << dendl;
ObjectStore::Transaction* t = context<RecoveryMachine>().get_cur_transaction();
if (msg->info.last_backfill == hobject_t()) {
// restart backfill
pg->unreg_next_scrub();
pg->info = msg->info;
pg->reg_next_scrub();
pg->dirty_info = true;
pg->dirty_big_info = true; // maybe.
PGLogEntryHandler rollbacker;
pg->pg_log.claim_log_and_clear_rollback_info(msg->log, &rollbacker);
rollbacker.apply(pg, t);
pg->pg_log.reset_backfill();
} else {
pg->merge_log(*t, msg->info, msg->log, logevt.from);
}
assert(pg->pg_log.get_head() == pg->info.last_update);
post_event(Activate(logevt.msg->info.last_epoch_started));
return transit<ReplicaActive>();
}当从PG接收到MLogRec事件,就对应着接收到主PG发送的MOSDPGLog消息,其通知PG处于activate状态,具体处理过程如下:
1) 如果msg->info.last_backfill为hobject_t(),需要Backfill操作的OSD;
2) 否则就是需要Recovery操作的OSD,调用merge_log()把主OSD发送过来的日志合并
抛出Activate(logevt.msg->info.last_eopch_started)事件,使副本转移到ReplicaActive状态
1.6.2 ReplicaActive状态
ReplicaActive状态如下:
boost::statechart::result PG::RecoveryState::ReplicaActive::react(
const Activate& actevt) {
dout(10) << "In ReplicaActive, about to call activate" << dendl;
PG *pg = context< RecoveryMachine >().pg;
map<int, map<spg_t, pg_query_t> > query_map;
pg->activate(*context< RecoveryMachine >().get_cur_transaction(),
actevt.activation_epoch,
*context< RecoveryMachine >().get_on_safe_context_list(),
query_map, NULL, NULL);
dout(10) << "Activate Finished" << dendl;
return discard_event();
}当处于ReplicaActive状态,接收到Activate事件,就调用PG::activate()函数。在函数PG::_activate_committed()中给主PG发送应答信息,告诉主OSD自己处于activate状态,设置PG为activate状态。
4. 状态机异常处理
在上面的流程介绍中,只介绍了正常状态机的转换流程。Ceph之所以用状态机来实现PG的状态转移,就是可以实现任何异常情况下的处理。下面介绍当OSD失效时,导致相关的PG重新Peering的机制。
当一个OSD失效,Monitor会通过heartbeat检测到,导致osdmap发生了变化,Monitor会把最新的osdmap推送给OSD,导致OSD上受影响PG重新进行Peering操作。
具体流程如下:
1) 在函数OSD::handle_osd_map()处理osdmap的变化,该函数调用consume_map(),对每一个PG调用pg->queue_null(),把PG加入到peering_wq中;
2) peering_wq的处理函数process_peering_events()调用OSD::advance_pg()函数,在该函数里调用PG::handle_advance_map()给PG的状态机RecoveryMachine发送AdvMap事件:
boost::statechart::result PG::RecoveryState::Started::react(const AdvMap& advmap);当处于Started状态,接收到AdvMap事件,调用函数pg->should_restart_peering()检查,如果是new_interval,就跳转到Reset状态,重新开始一次Peering过程。
