一个具有层级结构的crushmap示例
前面我们较为详细的介绍了crush算法,为了进一步理解并掌握crush算法,这里我们给出一个具有层级结构的crushmap示例。本文参考:CRUSHMAP : Example of a Hierarchical Cluster Map
1. crushmap层级结构示例
通常我们并不太容易知道如何在crushmap中组织数据,特别是当你需要将数据存储到不同类型的硬盘(例如:SATA硬盘、SAS硬盘、SSD硬盘)上时。下面我们来看如何将crushmap想象成为具有层级结构。
模型1:
假设我们将数据存储在两个数据中心。

模型2:
在我们介绍了cache pools之后,我们可以很容易的想象到添加SSD硬盘到存储集群中。如下示例中我们将SSD添加到新的主机上。添加完成后,我们需要管理两种类型的硬盘。在只需要描述cluster的物理分割时,我们可能会采用如下的层次结构:

模型3:
在上面模型2的层级结构中,我们很快就会意识到这样的配置并不能支持为特定pool区分硬盘类型。
为了区分这些硬盘并且组织crushmap,最简单的方法就是从根节点开始重新复制一份该树形结构。这样我们就会有两个根:“default”(可以被命名为hdd)和“ssd”。

另一个hdd与ssd混合的例子如下(你需要将每一个host分割开):

模型4:
上面模型3的问题是我们通过硬盘的不同类型来分割集群。这样的话我们就不能通过一个入口(entry)来选择“dc-1”和“dc-2”中任何一块硬盘。例如,我们就不能定义一个规则来将数据存储到数据中心的任何一块硬盘上。
要解决这个问题,我们可以在root层级上增加一个其他的入口点。例如,按如下方式添加一个新的entry point来允许访问所有类型的硬盘。

模型5:
假若我们需要在树中维持更多逻辑关系,我们可以添加更多的层级。例如一些逻辑层级代表磁盘类型,而其他一些则代表物理分布。这些层级可以根据我们的需要来添加。例如,这里我们添加了一个“pool”层级,或者也可以被称为“type”层级或其他(图中浅绿部分):
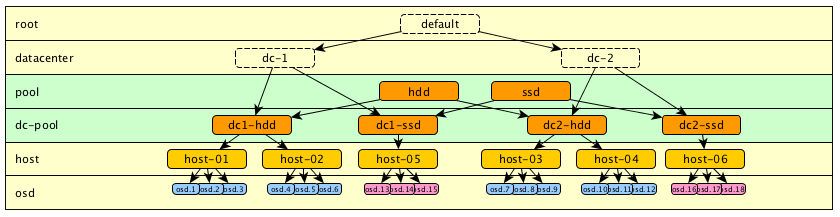
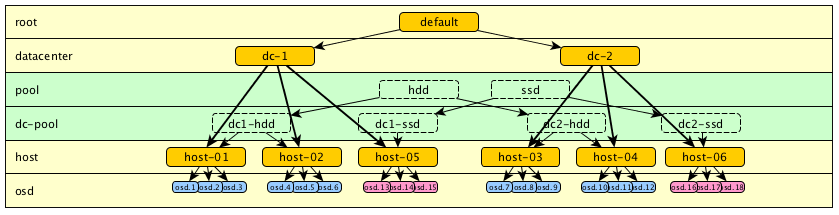
模型6:
在上面模型5中,虽然已经可以满足我们的需求了,但是因为层级太多,不便于我们阅读。特别是在当同一台宿主机上同时存在SSD和HDD时就会变得更加难以阅读。同样在这种情况下,模型5也并不能在物理数据存放层面进行逻辑区分。要解决这个问题,我们可以在HOST和OSD之间插入一个新的层级:

模型7:
上面模型6在小集群或者不需要更多层级的集群中具有较大优势。我们也可以其他一些另外的组织方式,比如将OSD分割到不同的层级,然后通过不同的规则来使用它们。例如,我们可以通过step chooseleaf firstn 5 type host-sata来选择sata硬盘,通过step chooseleaf firstn 5 type host-ssd来选择ssd硬盘。
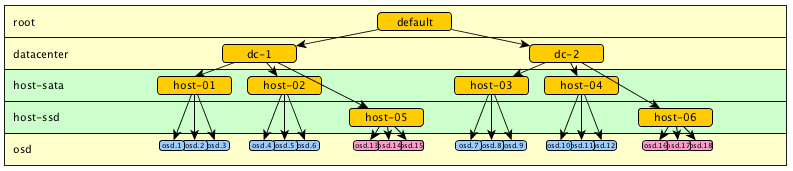
2. crushmap示例
如下我们是针对模型7的一个crushmap.
- 在每个DC中选择一个ssd的规则
- 在每个DC中选择一个sata的规则
- 在两个不同的host上选择一个sata的规则
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 0
tunable chooseleaf_vary_r 0
# devices
device 0 osd.0
device 1 osd.1
device 2 osd.2
device 3 osd.3
device 4 osd.4
device 5 osd.5
device 6 osd.6
device 7 osd.7
device 8 osd.8
device 9 osd.9
device 10 osd.10
device 11 osd.11
device 12 osd.12
device 13 osd.13
device 14 osd.14
device 15 osd.15
device 16 osd.16
device 17 osd.17
device 18 osd.18
# types
type 0 osd
type 1 host-ssd
type 2 host-sata
type 3 datacenter
type 4 root
# buckets
host-sata host-01 {
alg straw
hash 0
item osd.1 weight 1.000
item osd.2 weight 1.000
item osd.3 weight 1.000
}
host-sata host-02 {
alg straw
hash 0
item osd.4 weight 1.000
item osd.5 weight 1.000
item osd.6 weight 1.000
}
host-sata host-03 {
alg straw
hash 0
item osd.7 weight 1.000
item osd.8 weight 1.000
item osd.9 weight 1.000
}
host-sata host-04 {
alg straw
hash 0
item osd.10 weight 1.000
item osd.11 weight 1.000
item osd.12 weight 1.000
}
host-ssd host-05 {
alg straw
hash 0
item osd.13 weight 1.000
item osd.14 weight 1.000
item osd.15 weight 1.000
}
host-ssd host-06 {
alg straw
hash 0
item osd.16 weight 1.000
item osd.17 weight 1.000
item osd.18 weight 1.000
}
datacenter dc1 {
alg straw
hash 0
item host-01 weight 1.000
item host-02 weight 1.000
item host-05 weight 1.000
}
datacenter dc2 {
alg straw
hash 0
item host-03 weight 1.000
item host-04 weight 1.000
item host-06 weight 1.000
}
root default {
alg straw
hash 0
item dc1 weight 1.000
item dc2 weight 1.000
}
# rules
rule sata-rep_2dc {
ruleset 0
type replicated
min_size 2
max_size 2
step take default
step choose firstn 0 type datacenter
step chooseleaf firstn 1 type host-sata
step emit
}
rule ssd-rep_2dc {
ruleset 1
type replicated
min_size 2
max_size 2
step take default
step choose firstn 0 type datacenter
step chooseleaf firstn 1 type host-ssd
step emit
}
rule sata-all {
ruleset 2
type replicated
min_size 2
max_size 2
step take default
step chooseleaf firstn 0 type host-sata
step emit
}
# end crush map
