删除osd节点
本文主要记录一下删除osd节点的步骤, 并对几种不同的方式进行对比
1. 删除osd的正确方式
如下我们先介绍两种移除OSD的方式,关于性能及数据迁移我们会在后面来进行分析,这里只列出相应的操作步骤:
1.1 方式1
1) 停止osd进程
# systemctl stop ceph-osd@47 # systemctl status ceph-osd@47
这一步是停止OSD的进程,让其他的OSD知道这个节点不提供服务了。
2) 将节点状态标记为out
# ceph osd out osd.47 # ceph osd tree
这一步是告诉mon,这个节点已经不能服务了,需要在其他的OSD上进行数据的恢复了。
3) 从crush中移除节点
# ceph osd crush remove osd.47
从crush中删除是告诉集群这个节点回不来了,完全从集群的分布当中剔除掉,让集群的crush进行一次重新计算,之前节点还占着这个crush的weight,会影响到当前主机的host crush weight。
4) 删除节点
# ceph osd rm osd.47
这个是从集群里面删除这个节点的记录,即从OSD map中移除中移除这个节点的记录。
5) 删除节点认证(不删除编号会占住)
# ceph auth del osd.47
这个是从认证当中去删除这个节点的信息。
如上方式移除OSD,其实会触发两次迁移,一次是在节点osd out以后,一次是在crush remove之后,两次迁移对于集群来说是不好的,其实通过调整步骤是可以避免二次迁移的。
1.2 方式2
1) 调整osd的crush weight
# ceph osd crush reweight osd.47 1.8 # ceph osd crush reweight osd.47 0.9 # ceph osd crush reweight osd.47 0
说明:这个地方如果想慢慢的调整就分几次将crush的weight减低至0,这个过程实际上是让数据不分布在这个节点上,让数据慢慢分布到其他节点上,直至最终不分布到该OSD,并且迁移完成数据。
这个地方不光调整了osd的crush weight,实际上同时调整了host的weight,这样会调整集群的整体crush分布,在osd的crush为0后,再对这个osd的任何删除相关操作都不会影响到集群的数据分布。
2) 停止osd进程
# systemctl stop ceph-osd@47 # systemctl status ceph-osd@47
停止对应osd的进程,这个是通知集群这个osd进程不在了,不提供服务了。因为本身没有权重,就不会影响到整体的分布,也就没有迁移。
3) 将节点状态标记为out
# ceph osd out osd.47
将对应OSD移出集群,这个是通知集群这个osd不再映射数据了,不提供服务了,因为本身没有权重,就不会影响到整体的分布,也就没有迁移。
4) 从crush中移除节点
# ceph osd crush remove osd.47
这个是从crush中删除,因为当前已经是0了,所以不会影响主机的权重,也就没有迁移了。
5) 删除节点
# ceph osd rm osd.47
这个是从集群里面删除这个节点的记录,即从OSD map中移除中移除这个节点的记录。
6) 删除节点认证(不删除编号会占住)
# ceph auth del osd.47
这个是从认证当中去删除这个节点的信息。
7)移除某一个host
如果某一个host的OSD全部都移除完毕,我们可能需要将host从crushmap中移除,执行如下命令:
# ceph osd crush remove oss-3-sata经过验证,第二种方式只触发了一次迁移,虽然只是一个步骤先后顺序上的调整,但是对于生产环境的集群来说,迁移的量要少一次,实际生产环境当中节点是有自动out的功能,这个可以考虑自己去控制,只是监控的密度需要加大,毕竟这是一个需要监控的集群,完全让其自己处理数据的迁移是不可能的,带来的故障只会更多。
2. 替换OSD操作的优化与分析
我们在上面介绍了删除OSD的正确方式,里面只是简单的讲了一下删除的方式怎样能减少迁移量。下面我们讲述一下ceph运维过程当中经常出现的坏盘然后换盘的步骤的优化。
这里我们操作的环境是:两台主机,每一台主机8个OSD,总共16个OSD,副本设置为2, PG数设置为800,计算下来平均每一个OSD上的PG数目为100个,下面我们将通过数据来分析不同的处理方法的差别。
开始测试前我们先把环境设置为noout,然后通过停止OSD来模拟OSD出现了异常,之后进行不同处理方法。
2.1 方式1
这里我们: 先out一个OSD,然后剔除OSD,接着增加OSD
1. 停止指定OSD进程 2. out指定OSD 3. crush remove指定OSD 4. 增加一个新的OSD
一般生产环境设置为noout,当然不设置也可以,那就交给程序去控制节点的out,默认是在进程停止后的五分钟,总之这个地方如果有out触发,不管是人为触发,还是自动触发数据流是一定的,我们这里为了便于测试,使用的是人为触发,上面提到的预制环境就是设置的noout。
1) 获取原始pg分布
开始测试之前,我们首先获取最原始的PG分布:
# ceph pg dump pgs|awk '{print $1,$15}'|grep -v pg > pg1.txt上面获取当前的PG分布,保存到文件pg1.txt,这个PG分布记录的是PG所在的OSD。这里记录下来,方便后面进行比较,从而得出需要迁移的数据。
2) 停止指定的OSD进程
# systemctl stop ceph-osd@15
停止进程并不会触发迁移,只会引起PG状态的变化,比如原来主PG在停止的OSD上,那么停止掉OSD以后,原来的副本的那个PG就会升级为主PG了。
3) out掉一个OSD
# ceph osd out 15
在触发out以前,当前的PG状态应该有active+undersized+degraded,触发out以后,所有的PG的状态应该会慢慢变成active+clean,等待集群正常以后,再次查询当前的PG分布状态。
# ceph pg dump pgs | awk '{print $1,$15}' | grep -v pg > pg2.txt保存当前的PG分布为pg2.txt。
比较out前后的PG变化情况,下面是比较具体的变化情况,只列出变化的部分:
# diff -y -W 100 pg1.txt pg2.txt --suppress-common-lines
这里我们关心的是变动的数目,只统计变动的PG数目:
# diff -y -W 100 pg1.txt pg2.txt --suppress-common-lines | wc -l 102
第一次out以后,有102个PG的变动,记住这个数字,后面的统计会用到。
4) 从crush里面删除OSD
# ceph osd crush remove osd.15
crush删除以后同样会触发迁移,等待PG的均衡,也就是全部变成active+clean状态。
通过以下的命令来获取当前PG分布的状态:
# ceph pg dump pgs | awk '{print $1,$15}' | grep -v pg > pg3.txt现在来比较crush remove前后的PG变动:
# diff -y -W 100 pg2.txt pg3.txt --suppress-common-lines | wc -l 137
5) 重新添加OSD
如下我们重新添加OSD:
# ceph-deploy osd prepare lab8107:/dev/sdi # ceph-deploy osd activate lab8107:/dev/sdi1
加完以后,统计当前的新的PG状态:
# ceph pg dump pgs | awk '{print $1,$15}' | grep -v pg > pg4.txt比较前后的变化:
# diff -y -W 100 pg3.txt pg4.txt --suppress-common-lines | wc -l 167
到这里整个替换流程完毕,统计上面PG总的变动:
102 + 137 + 167 = 406
也就是说按这个方法的变动PG为406个,因为是只有双主机,里面可能存在某些放大问题,这里不做深入讨论,因为我们三组测试环境都是一样的情况,只做横向比较,原理相通,这里是用数据来分析出差别。
2.2 方式2
这里我们: 先crush reweight 0, 然后out,然后再增加OSD
1) 获取原始pg分布
开始测试之前,我们首先获取最原始的PG分布:
# ceph pg dump pgs | awk '{print $1,$15}' | grep -v pg > 2pg1.txt上面获取当前的PG分布,保存到文件2pg1.txt,这个PG分布记录的是PG所在的OSD。这里记录下来,方便后面进行比较,从而得出需要迁移的数据。
2) crush reweight 指定的OSD
我们使用如下的命令将osd.16的crush weight降低到0:
# ceph osd crush reweight osd.16 0 reweighted item id 16 name 'osd.16' to 0 in crush map
等待平衡了以后,记录当前的PG分布状态:
# ceph pg dump pgs|awk '{print $1,$15}'|grep -v pg > 2pg2.txt
dumped pgs in format plain比较前后的PG的变动情况:
# diff -y -W 100 2pg1.txt 2pg2.txt --suppress-common-lines|wc -l 166
3) crush remove指定OSD
# ceph osd crush remove osd.16 removed item id 16 name 'osd.16' from crush map
这个地方因为上面crush weight已经是0了,所以删除也不会引起PG变动。然后直接 ‘ceph osd rm osd.16’ 同样没有PG变动。
4) 增加新的OSD
# ceph-deploy osd prepare lab8107:/dev/sdi # ceph-deploy osd activate lab8107:/dev/sdi1
等待平衡以后获取当前的PG分布:
# ceph pg dump pgs | awk '{print $1,$15}' | grep -v pg > 2pg3.txt现在来比较前后的变化情况:
# diff -y -W 100 2pg2.txt 2pg3.txt --suppress-common-lines | wc -l 159
到这里整个替换流程完毕,统计上面PG总的变动:
166 + 159 = 325
2.3 方式3
这里我们: 先做norebalance,然后做crush remove,接着再做添加OSD操作
1) 获取原始pg分布
开始测试之前,我们首先获取最原始的PG分布:
# ceph pg dump pgs | awk '{print $1,$15}' | grep -v pg > 3pg1.txt
dumped pgs in format plain上面获取当前的PG分布,保存到文件3pg1.txt,这个PG分布记录的是PG所在的OSD。这里记录下来,方便后面进行比较,从而得出需要迁移的数据。
2) 给集群做多种标记,防止迁移
设置为 norebalance,nobackfill,norecover,后面是有地方会解除这些设置的:
# ceph osd set norebalance set norebalance # ceph osd set nobackfill set nobackfill # ceph osd set norecover set norecover
3) crush reweight指定OSD
# ceph osd crush reweight osd.15 0 reweighted item id 15 name 'osd.15' to 0 in crush map
这个地方因为已经做了上面的标记,所以只会出现状态变化,而没有真正的迁移,我们也先统计一下:
# ceph pg dump pgs | awk '{print $1,$15}' | grep -v pg > 3pg2.txt
# diff -y -W 100 3pg1.txt 3pg2.txt --suppress-common-lines | wc -l
158注意这里只是计算了,并没有真正的数据变动,可以通过监控两台主机的网络流量来判断。所以这里的变动并不用计算到需要迁移的PG数据当中。
4) crush remove指定的OSD
# ceph osd crush remove osd.15
5) 删除指定的OSD
删除以后同样是没有PG的变动:
# ceph osd rm osd.15
这里有个小地方需要注意一下,不做 ‘ceph auth del osd.15’,把15的编号留着,这样号判断前后PG的变化情况,不然相同的编号,就无法判断是不是做了迁移了。
6) 增加新的OSD
# ceph-deploy osd prepare lab8107:/dev/sdi # ceph-deploy osd activate lab8107:/dev/sdi1
我的环境下,新增的OSD编号为16了。
7) 解除各种标记
# ceph osd unset norebalance unset norebalance # ceph osd unset nobackfill unset nobackfill # ceph osd unset norecover unset norecover
设置完了后数据才真正开始变动了,可以通过观察网卡流量看到,来看下最终PG变化:
# ceph pg dump pgs | awk '{print $1,$15}' | grep -v pg > 3pg3.txt
dumped pgs in format plain
# diff -y -W 100 3pg1.txt 3pg3.txt --suppress-common-lines | wc -l
195这里我们只需要跟最开始的PG分布状况进行比较就可以了,因为中间的状态实际上都没有做数据的迁移,所以不需要统计进去,可以看到这个地方变动了195个PG。因此总的PG迁移量为195。
2.4 数据汇总
现在通过表格来对比下三种方法的迁移量(括号内为迁移PG数目):
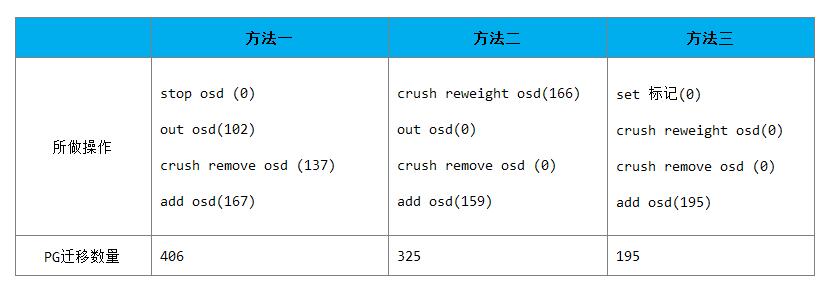
可以很清楚的看到三种不同的方法,最终触发的迁移量是不同的,处理的好的话,能减少差不多一半的数据迁移量,这个对于生产环境来说还是很重要的。关于这个建议先在测试环境上进行测试,然后再操作,上面的操作只要不对磁盘进行格式化,操作都是可逆的。也就是可以比较放心的做,记住所做的操作,每一步做完都去检查PG的状态是否是正常的。
3. 一次换盘实操
在生产环境中,我们遇到osd.47硬盘损坏的情况,这时需要换盘。
1) 保存该损坏osd的fsid以及ID
如果在硬盘没有损坏的情况下,我们可以通过在 ‘/var/lib/ceph/osd/ceph-47’ 目录下的fsid文件和whoami文件中找到其对应的值。然而,当前我们硬盘已经损坏,所以要想通过此方法来找出已经不可能了。这时我们可以通过如下命令来获得:
# ceph osd dump >> cluster_osddump.txt
接着查看导出的cluster_osddump.txt,大体可以找到对应的fsid:
# cat cluster_osddump.txt ... osd.47 down out weight 0 primary_affinity 0 up_from 22470 up_thru 22472 down_at 22474 last_clean_interval [22360,22469) 10.17.253.170:6804/1032571 10.17.254.170:6824/16032571 10.17.254.170:6825/16032571 10.17.253.170:6824/16032571 autoout,exists c457172c-d5b0-45e8-b6b3-7355f24f4109 ...
上面c457172c-d5b0-45e8-b6b3-7355f24f4109即为对应的fsid值。而OSD.47的ID值是47.
2) 调整osd的crush weight
# ceph osd crush reweight osd.47 1.8 # ceph osd crush reweight osd.47 0.9 # ceph osd crush reweight osd.47 0
具体含义请参看前面介绍。
3) 停止osd进程
# systemctl stop ceph-osd@47 # systemctl status ceph-osd@4
4) 将节点状态标记为out
# ceph osd out osd.47
5) 删除节点
# ceph osd rm osd.47
这里注意,我们并不会将osd.47从crush map中移除,因为我们后面重新添加OSD时,会生产一个新的osd.47,那时我们就不需要再修改crush map了。
6) 删除节点认证(不删除编号会占住)
# ceph auth del osd.47
7) 产生新的OSD
# ceph osd create c457172c-d5b0-45e8-b6b3-7355f24f4109 47 # ceph-osd -i 47 --mkfs --mkkey --osd-uuid c457172c-d5b0-45e8-b6b3-7355f24f4109 # ceph auth add osd.47 osd 'allow *' mon 'allow rwx' -i /var/lib/ceph/osd/ceph-47/keyring
8) 启动OSD
# systemctl start ceph-osd@47 # systemctl status ceph-osd@47 # ps -ef | grep osd
9) 调整osd的crush weight
# ceph osd crush reweight osd.47 0.6 # ceph osd crush reweight osd.47 1.2 # ceph osd crush reweight osd.47 1.8
说明: 上面只是列出了一个整体的步骤,关于一些细节部分暂为列出。
[参看]
