RAMCloud介绍
本文我们会先对RAMCloud做一个简单的介绍,之后会探讨一下其使用场景。
1. RAMCloud介绍
RAMCloud是一种新的适用于大规模数据中心应用的高速存储。其通过在一个数据中心当中部署大量服务器,来为应用程序提供大规模、低延迟的持久化数据存储。RAMCloud具有如下特征:
-
低延迟(Low Latency): RAMCloud会将数据一直保存在内存中,这就使得应用程序能够在最小5us的时间内通过数据中心网络读取到RAMCloud对象。此外,写数据最短也可以在15us内完成。与memcached等系统不同的是,使用RAMCloud的应用程序不再需要处理cache miss或等待disk/flash的访问(注: 所有数据都在内存)。因此,RAMCloud存储会比其他存储快10~1000倍。
-
大规模(Large Scale): RAMCloud会将成千上万的DRAM服务器组织起来以形成一个集群,从而能够达到支持1PB甚至更多的容量。
-
持久化(Durability): RAMCloud会将所有的数据复制到如硬盘、Flash等备份存储器当中,这样就使得即使在服务器崩溃或是电源断电的情况下都不会丢失数据。RAMCloud的其中一个独特之处就在于其能够在服务器崩溃之后非常快的完成数据恢复(只需要1~2s),从而达到非常高的可用性。RAMCloud整合了DRAM的高速以及备份数据的持久化两个方面。假如你曾经使用过memcached,可能就体验过管理一个二级(secondly)持久化存储系统会面临的巨大挑战,并且还要维持缓存与硬盘数据的一致性。使用RAMCloud的之后,我们就不再需要关心这样一个二级(secondly)永久存储的问题。
-
强大的数据模型(Powerful data model): RAMCloud的基本数据模型就是一个key-value存储,但是我们又对其进行了额外的扩展,使其还具有如下依稀特性
a. 具有多表结构,每一个表都有其自己的key-space b. 能够支持跨表的更新事务(transaction) c. 支持二级索引 d. 强一致性: 与其他的NoSQL存储系统不同,RAMCloud的所有更新操作都是consitent、immediately visible、durable的
- 易部署(Easy Demployment): RAMCloud软件包能够运行在普通的Intel-Linux系统上,并且是开放源代码的
从实际使用者的角度来说,RAMCloud提供为应用程序了一种新的方式来操作大规模数据。使用RAMCloud能够将成千上万的数据组织起来,并实时的响应客户端的请求。与传统的数据库不同,RAMCloud能够支持大规模的应用程序请求,并且能够保证数据的一致性。我们相信RAMCloud,或者类似的系统,在未来云计算的环境下将会变成结构化数据的主要存储系统,应用于如Amazon AWS、Microsoft Azure上。我们构建的RAMCloud并不是一个研究性的原型,而是一个具有生产质量的软件系统,能够满足实际应用程序的需求。
站在研究角度来说,RAMCloud其实也是一个很有意义的项目。RAMCloud最重要的两个特征是latency和scale。第一个目标是为处于同一数据中心的应用程序提供最低延迟的数据访问。实验中我们获取到的读最低延迟为5us,写最低延迟为15us,并且在未来仍有望读写性能。另外,系统必须要支持大规模的数据存储,因为单机肯定是提供不了如此大规模内存的。RAMCloud目前已经支持多达10000台存储服务器,整个系统必须要能够跨机器来自动的管理所有信息,这样才可以使得客户端不必再关心分布式相关的问题。RAMCloud在latency与scale两方面的特性,创造了很多有趣的研究课题,例如: 在不牺牲读写延迟性的情况下,如何保证数据的持久性; 如何充分利用系统的大规模分布式部署来在系统崩溃后快速的恢复数据; 如何在内存中管理所存储的数据; 如何提供一些更高层级的特性比如二级索引以及多对象的事务操作。
2. 是否使用RAMCloud
2.1 使用RAMCloud的原因
如下是一些你可能想使用RAMCloud的原因:
-
RAMCloud主要的强大之处(claim to fame)在于其实现了一个能够快速访问的key-value存储系统。假如在数据中心中拥有高速的网络,你可以在最低5us内访问RAMCloud集群中的任意对象(small object)
-
RAMCloud具有良好的扩展性,其可以扩展到成百上千台服务器。例如,我们有1000个64GB内存大小的节点,则整个RAMCloud集群就可以提供64TB的数据存储总容量;如果有4000个256GB内存大小的节点,则整个RAMCloud集群就可以提供1PB的数据存储中容量
-
RAMCloud能够将数据保存到disk或者flash,并且在进行数据保存时几乎不会影响到系统的性能。这样,你可以在最少15us内就完成小对象(small object)的写操作,并且不用担心在系统崩溃或者断电后数据丢失的问题。也有一些其他的存储系统可以在内存中保存数据,但是通常它们都不能像RAMCloud那样提供持久化以及高可用性
-
RAMCloud特别适合于在一个请求(request)当中需要访问成百上千条相互独立的数据,并且需要能够实时的进行响应。假如你的应用程序仍然使用传统的关系型数据库(如MySQL)的话,你可能会发现将不能够大规模的扩展以满足业务需求(例如,不能够实时的返回数据,不能够大规模的扩展),此时RAMCloud可能就能够很好的满足这样的需求。假如你正在考虑将数据sharding到多个不同的MySQL实例的话,RAMCloud也许是一个更好的选择
-
RAMCloud特别适合于那种需要多个请求的应用场景,其中每一个请求可能都需要依赖于前一个请求(即这些请求都不能够并发的进行处理)
2.2 RAMCloud与memcached
近年来,许多组织都开始使用memcached来降低传统数据库的压力,以提高整个系统水平扩展性。通过这种方法,将memcache作为缓存来存储数据库的查询结果,这样可以较大的提高整个系统的访问速度。然而,尽管此种方法可以较快的提高系统性能,但与RAMCloud比较起来其仍有如下4个缺点:
-
为了保证数据的持久性与可用性,任何对数据的修改操作都必须再写入到数据库,而这通常是低速的。RAMCloud的写效率比传统数据库快10~1000倍
-
应用程序开发人员必须手动的管理数据库与memcached中数据的一致性。假如数据库中的数据发生了改变,则memcached中的数据也必须要进行刷新以保证数据的一致性,而这通常是一个复杂并容易出错的操作,应用程序经常会使用到一些位于memcached中的
陈旧的数据。而如果使用RAMCloud,开发人员就可以不同担心这一方面的数据不一致性问题 -
数据库对比memcached来说,即使具有很高的缓存命中率,数据库的速度、性能都会低很多。相反,RAMCloud会将所有数据一直保存在内存中,因此就不会存在cache命中这样的问题。假如采用memcached的话,即使有1%的数据不能在缓存中成功命中,相比RAMCloud来说性能都会有10倍的下降。不幸的是,对于大多数大规模请求访问的应用程序来说, 其不能命中的概率远大于1%.
-
RAMCloud已经被优化到能提供极低的延迟,并且能够充分利用高速网络来提供最少5us延迟的读操作。相反,Facebook报告的典型的memcached的延迟通常有几百毫秒
2.3 不使用RAMCloud的原因
并不是对每一个应用程序来说,RAMCloud都是最好的存储系统。这里有一些场景就不太适合使用RAMCloud:
-
假如你的应用程序并不需要进行密集的数据访问,则可能并不需要将数据保存在内存中;你可以直接使用基于硬盘的文件系统
-
假如你的应用程序是面向于批量读取整个数据集的话,则低延迟可能就不是主要关注的目标。在这些场景下,应用程序的性能会收到整个存储系统的影响。其他的存储系统对这种全量的数据访问可能做了更好的优化,例如在这种情况下Spark就比RAMCloud具有更好的性能。对于一些分析性的应用程序来说,RAMCloud会更适合它们。
-
为了获得最高的性能,你可能需要高速网络
1) 高效的交换机(低于1us的交换延迟)。对于大多数10Gbs交换机均能满足此要求 2) 网络控制器(NIC)必须要支持kernel bypass
3. RAMCloud整体架构
3.1 RAMCloud架构
RAMCloud特征:
-
通用的存储系统
-
所有数据都在内存(没有缓存失效)
-
持久性和可用性
-
可扩展性(10000+ servers,32-64GB DRAM/server, 100+ TB)
-
低延迟(5-10us远程访问)
-
高吞吐(1M ops/sec/server)
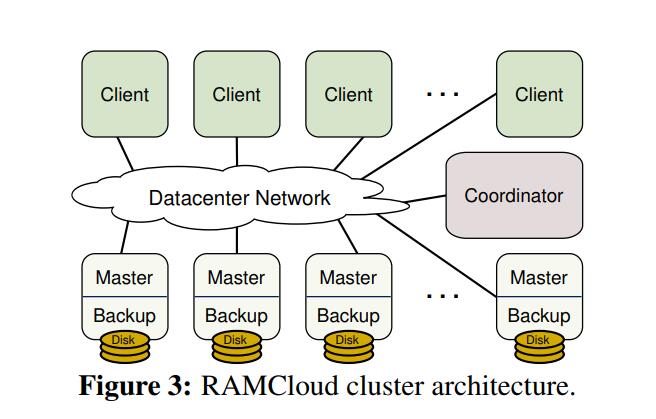
每个storage server都包含两个部分: Master和Backup。Master管理了存储在memory中的object,Backup使用本地的机械硬盘或者固态硬盘保存了其他server的数据备份。Coordinator管理了Master和Backup配置信息,比如集群各个server之间的关系和各个备份的分配。但是Coordinator并不涉及数据的读写操作,因此也不会成为cluster的bottleneck或者降低系统的scalability。
RAMCloud提供了一个简单的key-value的数据模型,数据(称为object)都是连续存储的。每个object都被长度不一的唯一的key标记。多个object被保存到table中,这个table有可能跨越多个server。object只能够以整体的方式进行读写,它为小object做了专门的优化,这也非常适合超大规模的web并发请求。
每个Master都有自己的日志,这些日志被分成8M的块,称为segment。每个segment都会冗余到其他server的backup,典型的配置都是冗余2-3块。在client写操作的时候,冗余会发送到其他节点,这些节点在把冗余写到memory的buffer后就会返回,而不是保存到本地磁盘后才返回,这样保证了client的高速写入。这些buffer在某些时间点会flush到本地存储。
[参看]
