ceph的数据读写(2)
本章介绍ceph的服务端OSD(书中简称OSD模块或者OSD)的实现。其对应的源代码在src/osd目录下。OSD模块是Ceph服务进程的核心实现,它实现了服务端的核心功能。本章先介绍OSD模块静态类图相关数据结构,再着重介绍服务端数据的写入和读取流程。
1. 读写操作的序列图
写操作的序列图如下图6-2所示:
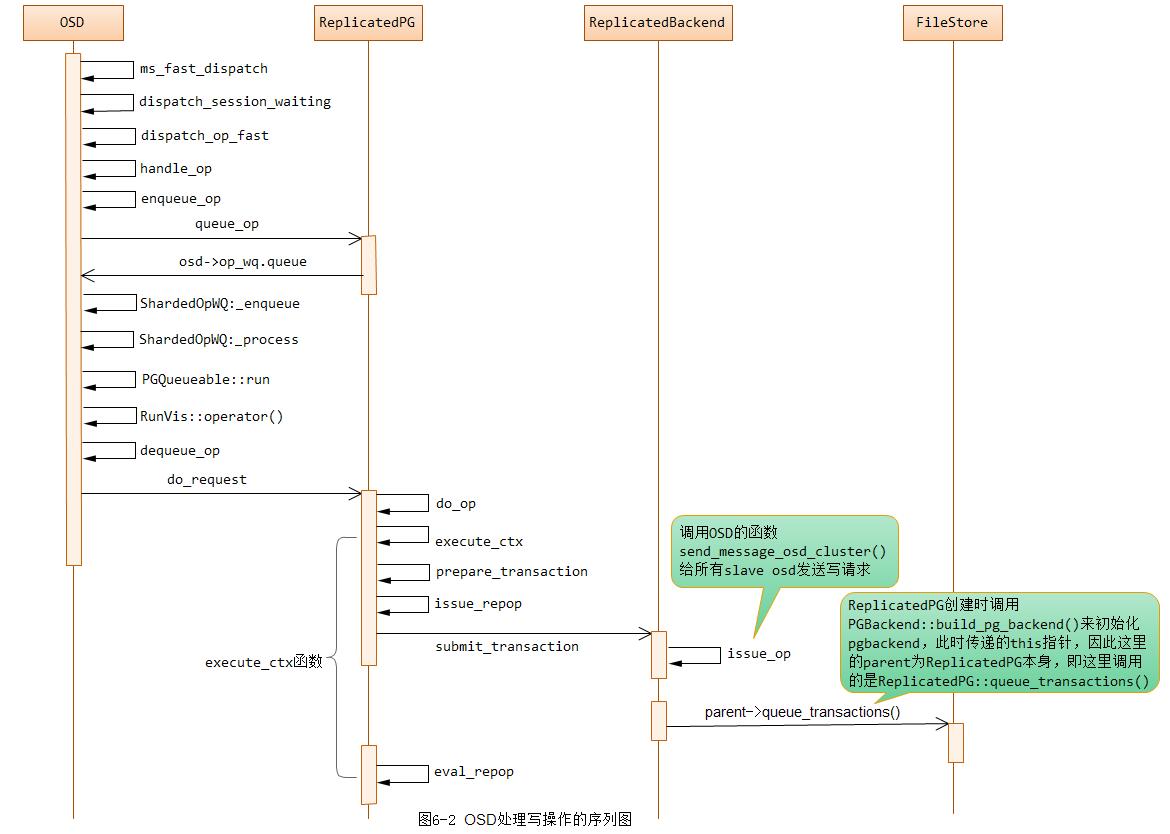
写操作分为三个阶段:
-
阶段1:从函数ms_fast_dispatch()到函数op_wq.queue函数为止,其处理过程都在网络模块的回调函数中处理,主要检查当前OSD的状态,以及epoch是否一致;
-
阶段2: 这个阶段在工作队列op_wq中的线程池里处理,在类ReplicatedPG里,其完成对PG的状态、对象的状态的检查,并把请求封装成事务。
-
阶段3: 本阶段也是在工作队列op_wq中的线程池里处理,主要功能都在类ReplicatedBackend中实现。核心工作就是把封装好的事务通过网络分发到从副本上,最后调用本地FileStore的函数完成本地对象的数据写入。
通过上面,其实我们可以这样理解OSD、ReplicatedPG以及ReplicatedBackend三者之间的关系: OSD是PG操作的主入口,而ReplicatedPG对应于一个特定的PG,其调用ReplicatedBackend来完成Object读写消息的发送及事件的处理。
注: OSD进程的主入口为src/ceph_osd.cc。这里从RadosClient发送过来的对象读写消息都为CEPH_MSG_OSD_OP
从上面我们可以看到,PG写操作的核心逻辑为:
void ReplicatedPG::do_op()
{
execute_ctx();
}
void ReplicatedPG::execute_ctx()
{
prepare_transaction();
issue_repop();
submit_transaction();
eval_repop();
}2. 读写流程代码分析
在介绍了上述的数据结构和基本的流程之后,下面将从服务端接收到消息开始,分三个阶段具体分析读写的过程。
2.1 阶段1: 接收请求
读写请求都是从OSD::ms_fast_dispatch()开始,它是接收读写消息message的入口。下面从这里开始读写操作的分析。本阶段所有的函数是被网络模块的接收线程调用,所以理论上应该尽可能的简单,处理完成后交给后面的OSD模块的op_wq工作队列来处理。
1. ms_fast_dispatch
void OSD::ms_fast_dispatch(Message *m)
{
if (service.is_stopping()) {
m->put();
return;
}
OpRequestRef op = op_tracker.create_request<OpRequest, Message*>(m);
{
#ifdef WITH_LTTNG
osd_reqid_t reqid = op->get_reqid();
#endif
tracepoint(osd, ms_fast_dispatch, reqid.name._type,
reqid.name._num, reqid.tid, reqid.inc);
}
OSDMapRef nextmap = service.get_nextmap_reserved();
Session *session = static_cast<Session*>(m->get_connection()->get_priv());
if (session) {
{
Mutex::Locker l(session->session_dispatch_lock);
update_waiting_for_pg(session, nextmap);
session->waiting_on_map.push_back(op);
dispatch_session_waiting(session, nextmap);
}
session->put();
}
service.release_map(nextmap);
}; 函数ms_fast_dispatch()为OSD注册了网络模块的回调函数,其被网络的接收线程调用,具体实现过程如下:
1) 首先检查service,如果已经停止了,就直接返回;
2) 调用函数op_tracker.create_request()把Message消息转换成OpRequest类型,数据结构OpRequest包装了Message,并添加了一些其他信息。
3) 获取nextmap(也就是最新的osdmap)和session,类Session保存了一个Connection的相关信息。
4) 调用函数update_waiting_for_pg来更新session里保存的OSDMap信息;
5) 把请求加入waiting_on_map的列表里;
6) 调用函数dispatch_session_waiting()处理,它循环调用函数dispatch_op_fast处理请求;
7) 如果session->waiting_on_map不为空,说明该session里还有等待osdmap的请求,把该session加入到session_waiting_for_map队列里(该队列表示正在等待最新OSDMap的session,当成功获取到最新的OSDMap,那么OSD的相关线程会将该session里的消息马上发送出去)。
2. dispatch_op_fast
bool OSD::dispatch_op_fast(OpRequestRef& op, OSDMapRef& osdmap);该函数检查OSD目前的epoch是否最新:
1) 检查变量is_stopping,如果为true,说明当前OSD正处于停止过程中,返回true,这样就会直接删除掉该请求。
2) 调用函数op_required_epoch(op),从OpRequest中获取msg带的epoch,进行比较,如果该值大于OSD最新的epoch,则调用函数osdmap_subscribe()订阅新的OSDMap更新,返回false值,表明不应该把此请求从session->waiting_on_map里移除。
3) 否则,根据消息类型,调用相应的消息处理函数。本章只关注处理函数handle_op相关的流程。
3. handle_op
void OSD::handle_op(OpRequestRef& op, OSDMapRef& osdmap);该函数处理OSD相关的操作,其处理流程如下:
1) 首先调用op_is_discardable,检查该op是否可以丢弃;
2) 构建share_map结构体,获取client_session,从client_session获取last_sent_epoch,调用函数service.should_share_map()来设置share_map.should_send标志,该函数用于检查是否需要通知对方更新epoch值。这里和dispatch_op_fast的处理区别是:上次是更新自己,这里是通知对方更新。需要注意的是,client和OSD的epoch不一致,并不影响读写,只要epoch的变化不影响本次读写PG的OSD list变化。
3) 从消息里获取_pgid,再从_pgid里获取pool
// calc actual pgid
pg_t _pgid = m->get_pg();
int64_t pool = _pgid.pool();4) 调用函数osdmap->raw_pg_to_pg,最终调用pg_pool_t::raw_pg_to_pg()函数,对PG做了调整
//参看: src/osd/OSDMap.h
pg_t OSDMap::raw_pg_to_pg(pg_t pg) const {
map<int64_t,pg_pool_t>::const_iterator p = pools.find(pg.pool());
assert(p != pools.end());
return p->second.raw_pg_to_pg(pg);
}
/*
* map a raw pg (with full precision ps) into an actual pg, for storage
* 参看: src/osd/Osd_types.cc
*/
pg_t pg_pool_t::raw_pg_to_pg(pg_t pg) const
{
pg.set_ps(ceph_stable_mod(pg.ps(), pg_num, pg_num_mask));
return pg;
}至于为什么要调用raw_pg_to_pg(),上面代码的注释也比较详细。
5) 调用osdmap->get_primary_shard()函数,获取该PG的主OSD
6) 调用函数get_pg_or_queue_for_pg(),通过pgid获取PG类的指针。如果获取成功,就调用函数enqueue_op处理请求;
7) 如果PG类的指针没有获取成功,做一些错误检查:
a) send_map为空,client需要重试;
b) 客户端的osdmap里没有当前的pool;
c) 当前OSD的osdmap没有该pool,或者当前OSD不是该PG的主OSD
总结,这个函数主要检查了消息的源端epoch是否需要share,最主要的是获取读写请求相关的PG类后,下面就进入PG类的处理。
4. queue_op
void PG::queue_op(OpRequestRef& op)
{
Mutex::Locker l(map_lock);
if (!waiting_for_map.empty()) {
// preserve ordering
waiting_for_map.push_back(op);
op->mark_delayed("waiting_for_map not empty");
return;
}
if (op_must_wait_for_map(get_osdmap_with_maplock()->get_epoch(), op)) {
waiting_for_map.push_back(op);
op->mark_delayed("op must wait for map");
return;
}
op->mark_queued_for_pg();
osd->op_wq.queue(make_pair(PGRef(this), op));
{
// after queue() to include any locking costs
#ifdef WITH_LTTNG
osd_reqid_t reqid = op->get_reqid();
#endif
tracepoint(pg, queue_op, reqid.name._type,
reqid.name._num, reqid.tid, reqid.inc, op->rmw_flags);
}
}该函数实现如下:
1) 加map_lock锁,该锁保护waiting_for_map列表,判断waiting_for_map列表不为空,就把当前Op加入该列表,直接返回。waiting_for_map列表不为空,说明有操作在等待osdmap的更新,说明当前osdmap不信任,不能继续当前的处理。
2) 函数op_must_wait_for_map()判断当前的epoch是否大于Op的epoch,如果是,则必须加入waiting_for_map等待,等待更新PG当前的epoch值。
提示: 这里的osdmap的epoch的判断,是一个PG层的epoch的判断。和前面的判断不在一个层次,这里是需要等待的。
3) 最终,把请求加入OSD的op_wq处理队列里
总结,这个函数做在PG类里,做PG层面的相关检查,如果ok,就加入OSD的op_wq工作队列里继续处理。
2.2 阶段2: OSD的op_wq处理
op_wq是一个ShardedWQ类型的工作队列。以下操作都是在op_wq对应的线程池里调用做相应的处理。这里着重分析读写流程。
1. dequeue_op
/*
* NOTE: dequeue called in worker thread, with pg lock
*/
void OSD::dequeue_op(
PGRef pg, OpRequestRef op,
ThreadPool::TPHandle &handle);1) 检查如果op->send_map_update为true,也就是如果需要更新osdmap,就调用函数service.share_map()更新源端的osdmap信息。在函数OSD::handle_op()里,只在op->send_map_update里设置了是否需要share_map标记,这里才真正去发消息实现share操作。
2) 检查如果pg正在删除,就把本请求丢弃,直接返回;
3) 调用函数pg->do_request(op, handle)处理请求。
总之,本函数主要实现了使请求源端更新osdmap的操作,接下来在PG里调用do_request()来处理。
2. do_request()
本函数进入ReplicatedPG类来处理:
void ReplicatedPG::do_request(OpRequestRef& op, ThreadPool::TPHandle &handle);处理过程如下:
1) 调用函数can_discard_request()检查op是否可以直接丢弃掉;
2) 检查变量flushes_in_progress,如果还有flush操作,把op加入waiting_for_peered队列里,直接返回;
3) 如果PG还没有peered,调用函数can_handle_while_inactive()检查pgbackend能否处理该请求,如果可以,就调用pgbackend->handle_message()处理;否则加入waiting_for_peered队列,等待PG完成peering后再处理;
注意: PG处于inactive状态,pgbackend只能处理MSG_OSD_PG_PULL类型的消息。这种情况可能是: 本OSD可能已经不在该PG的acting osd列表中,但是可能在上一阶段该PG的OSD列表中,所以PG可能含有有效的对象数据,这些对象数据可以被该PG当前的主OSD拉取以修复当前PG的数据。
4) 此时PG处于peered并且flushes_in_progress未0的状态下,检查pgbackend能否处理该请求。pgbackend可以处理数据恢复过程中的PULL和PUSH请求,以及主副本发的从副本的更新相关SUBOP类型的请求。
5) 如果是CEPH_MSG_OSD_OP,检查该PG的状态,如果处于非active状态或者处于replay状态,则把请求添加到waiting_for_active等待队列;
6) 检查如果该pool是cache pool,而该操作没有带CEPH_FEATURE_OSD_CACHEPOOL标志,返回EOPNOTSUPP错误码;
7) 根据消息的类型,调用相应的处理函数来处理;
本函数开始进入ReplicatedPG层面来处理,主要检查当前PG的状态是否正常,是否可以处理请求。
3. do_op()
函数do_op()比较复杂,处理读写请求的状态检查和一些上下文的准备工作。其中大量的关于快照的处理,本章在遇到快照处理时只简单介绍一下。
void ReplicatedPG::do_op(OpRequestRef& op);具体处理过程如下:
1) 调用函数m->finish_decode(),把消息带的数据从bufferlist中解析出相关的字段;
2) 调用osd->osd->init_op_flags()初始化op->rmw_flags,函数init_op_flags()根据flag来设置rmw_flags标志;
3) 如果是读操作:
a) 如果消息里带有CEPH_OSD_FLAG_BALANCE_READS(平衡读)或者CEPH_OSD_FLAG_LOCALIZE_READS(本地读)标志,表明主副本都允许读。检查本OSD必须是该PG的primary或者replica之一;
b) 如果没有上述标志,读操作只能读取主副本,本OSD必须是该PG的主OSD
4) 调用函数op_has_sufficient_caps()检查是否有相关的操作权限
5) 如果里面含有includes_pg_op操作,调用pg_op_must_wait()检查该操作是否需要等待。如果需要等待,加入waiting_for_all_missing队列;如果不需要等待,调用do_pg_op()处理PG相关的操作。这里的PG操作,都是CEPH_OSD_OP_PGLS等类似的PG相关的操作,需要确保该PG上没有需要修复的对象,否则ls列出的对象就不准确。
6) 构建要访问对象的head对象(head对象和快照对象的概念可查看后面介绍快照的章节)
hobject_t head(m->get_oid(), m->get_object_locator().key,
CEPH_NOSNAP, m->get_pg().ps(),
info.pgid.pool(), m->get_object_locator().nspace);7) 检查对象的名字是否超长
// object name too long?
if (m->get_oid().name.size() > g_conf->osd_max_object_name_len) {
dout(4) << "do_op name is longer than "
<< g_conf->osd_max_object_name_len
<< " bytes" << dendl;
osd->reply_op_error(op, -ENAMETOOLONG);
return;
}
if (m->get_object_locator().key.size() > g_conf->osd_max_object_name_len) {
dout(4) << "do_op locator is longer than "
<< g_conf->osd_max_object_name_len
<< " bytes" << dendl;
osd->reply_op_error(op, -ENAMETOOLONG);
return;
}
if (m->get_object_locator().nspace.size() > g_conf->osd_max_object_namespace_len) {
dout(4) << "do_op namespace is longer than "
<< g_conf->osd_max_object_namespace_len
<< " bytes" << dendl;
osd->reply_op_error(op, -ENAMETOOLONG);
return;
}
if (int r = osd->store->validate_hobject_key(head)) {
dout(4) << "do_op object " << head << " invalid for backing store: "
<< r << dendl;
osd->reply_op_error(op, r);
return;
}8) 检查操作的客户端是否在黑名单(blacklist)中
9) 检查磁盘空间是否满
op->may_write();10) 检查如果是写操作,并且是snap,返回EINVAL,快照不允许写操作。如果写操作带的数据大于osd_max_write_size(如果设置了),直接返回OSD_WRITETOOBIG错误。
// invalid?
if (m->get_snapid() != CEPH_NOSNAP) {
osd->reply_op_error(op, -EINVAL);
return;
}
// too big?
if (cct->_conf->osd_max_write_size && m->get_data_len() > cct->_conf->osd_max_write_size << 20) {
// journal can't hold commit!
derr << "do_op msg data len " << m->get_data_len()
<< " > osd_max_write_size " << (cct->_conf->osd_max_write_size << 20)
<< " on " << *m << dendl;
osd->reply_op_error(op, -OSD_WRITETOOBIG);
return;
}可以看到,以上完成基本的与操作相关的参数检查。
11) 如果是顺序写,调用函数scrubber.write_blocked_by_scrub()检查:如果head对象正在进行scrub操作,就加入waiting_for_active队列,等待scrub操作完成后继续本次请求的处理。
if (write_ordered && scrubber.write_blocked_by_scrub(head, get_sort_bitwise())) {
dout(20) << __func__ << ": waiting for scrub" << dendl;
waiting_for_active.push_back(op);
op->mark_delayed("waiting for scrub");
return;
}12) 检查head对象是否处于缺失状态(missing)需要恢复,调用函数wait_for_unreadable_object()把当前请求加入相应的队列里等待恢复完成
// missing object?
if (is_unreadable_object(head)) {
wait_for_unreadable_object(head, op);
return;
}13) 如果是顺序写,检查head对象是否is_degraded_or_backfilling_object(),也就是正在恢复状态,需要调用wait_for_degraded_object()加入相应的队列等待
// degraded object?
if (write_ordered && is_degraded_or_backfilling_object(head)) {
wait_for_degraded_object(head, op);
return;
}14) 检查head对象的特殊情况
a) 检查队列objects_blocked_on_degraded_snap里如果保存有head对象,就需要等待。该队列里保存的head对象在rollback到某个版本的快照时,该版本的snap对象处于缺失状态,必须等待该snap对象恢复,从而完成rollback操作。因此,该队列的head对象目前处于缺失状态。
b) 队列objects_blocked_on_snap_promotion里的对象标识head对象rollback到某个版本的快照时,该版本的快照对象在Cache pool层没有,需要到Data pool层获取。
如果head对象在上述的两个队列中,head对象都不能执行写操作,需要等待获取快照对象,完成rollback后才能写入。
可知,以上11~14步骤是构建并检查head对象的状态是否正常。
15) 如果是顺序写,检查该对象是否在objects_blocked_on_cache_full队列中,该队列中的对象因Cache pool层空间满而阻塞写操作
if (write_ordered && objects_blocked_on_cache_full.count(head)) {
block_write_on_full_cache(head, op);
return;
}注意:当head对象被删除时,系统自动创建一个snapdir对象用来保存快照相关的信息。head对象和snapdir对象只能有一个存在,其都可以用来保存快照相关的信息。
16) 检查该对象的snapdir对象(如果存在)是否处于missing状态
17) 检查snapdir对象是否可读,如果不能读,就调用函数wait_for_unreadable_object()等待;
18) 如果是顺序写操作,调用函数is_degraded_or_backfilling_object()检查snapdir对象是否缺失;
19) 检查如果是CEPH_SNAPDIR类型的操作,则只能是读操作。snapdir对象只能读取;
20) 检查是否是客户端replay操作
21) 构建对象oid,这才是实际要操作的对象,可能是snap对象也可能是head对象
hobject_t oid(m->get_oid(),
m->get_object_locator().key,
m->get_snapid(),
m->get_pg().ps(),
m->get_object_locator().get_pool(),
m->get_object_locator().nspace);22) 调用函数检查maybe_await_blocked_snapset是否被block,检查该对象缓存的ObjectContext如果设置为blocked状态,该object有可能正在flush,或者copy(由于Cache Tier),暂时不能写,需要等待
// io blocked on obc?
if (!m->has_flag(CEPH_OSD_FLAG_FLUSH) &&
maybe_await_blocked_snapset(oid, op)) {
return;
}23) 调用函数find_object_context()获取object_context,如果获取成功,需要检查oid的状态
int r = find_object_context(
oid, &obc, can_create,
m->has_flag(CEPH_OSD_FLAG_MAP_SNAP_CLONE),
&missing_oid);24) 如果hit_set不为空,就需要设置hit_set。hit_set和agent_state都是Cache tier的机制,hit_set记录了cachepool中对象是否命中,暂时不深入分析;
25) 如果agent_state不为空,就调用函数agent_choose_mode()设置agent的状态,调用函数maybe_handle_cache来处理,如果可以处理,就返回
if (agent_state) {
if (agent_choose_mode(false, op))
return;
}
if (maybe_handle_cache(op,
write_ordered,
obc,
r,
missing_oid,
false,
in_hit_set))
return;26) 获取object_locator,验证是否和msg里的相同
// make sure locator is consistent
object_locator_t oloc(obc->obs.oi.soid);
if (m->get_object_locator() != oloc) {
dout(10) << " provided locator " << m->get_object_locator()
<< " != object's " << obc->obs.oi.soid << dendl;
osd->clog->warn() << "bad locator " << m->get_object_locator()
<< " on object " << oloc
<< " op " << *m << "\n";
}27) 检查该对象是否被阻塞
// io blocked on obc?
if (obc->is_blocked() && !m->has_flag(CEPH_OSD_FLAG_FLUSH)) {
wait_for_blocked_object(obc->obs.oi.soid, op);
return;
}28) 获取src_obc,也就是src_oid对应的ObjectContext: 同样的方法,对src_oid做各种状态检查,然后调用find_object_context()函数获取ObjectContext。
29) 如果是操作对象snapdir,相关的操作就需要所有的clone对象,获取clone对象的ObjectContext。对每个clone对象,调用get_object_context()构建ObjectContext,并把它加入到src_objs中。
30) 创建opContext
OpContext *ctx = new OpContext(op, m->get_reqid(), m->ops, obc, this);31) 调用execute_ctx(ctx);
总之,do_op()主要检查相关对象的(head对象、snapdir对齐、src对象等)状态是否正常,并获取ObjectContext、OpContext相关的上下文信息。
4. get_object_context()
本函数获取一个对象的ObjectContext信息:
ObjectContextRef ReplicatedPG::get_object_context(const hobject_t& soid, //soid要获取的对象
bool can_create, //是否允许创建新的ObjectContext
map<string, bufferlist> *attrs); //attrs对象的属性关键是从属性OI_ATTR中获取object_info_t信息。具体过程如下:
1) 首先从LRU缓存object_contexts中获取该对象的ObjectContext,如果获取成功,就直接返回结果;
2) 如果从LRU cache没有查找到:
a) 如果参数attrs值不为空,就从attrs里获取OI_ATTR的属性值;
b) 否则,调用函数pgbackend->objects_get_attr()获取该对象的OI_ATTR属性值。如果获取失败,并且不允许创建,就直接返回ObjectContextRef()的空值。
3) 如果成功获取OI_ATTR属性值,就从该属性值中decode后获取object_info_t的值;
4) 调用get_snapset_context获取SnapSetContext
5) 调用相关函数设置obc相关的参数,并返回obc
5. get_snapset_context()
本函数获取对象的snapset_context结构,其过程和函数get_object_context()类似。具体实现如下:
SnapSetContext *ReplicatedPG::get_snapset_context(
const hobject_t& oid,
bool can_create,
map<string, bufferlist> *attrs,
bool oid_existed);1) 首先从LRU缓存snapset_contexts获取该对象的snapset_context,如果成功,直接返回结果;
2) 如果不存在,并且can_create,就调用pgbackend->objects_get_attr()函数获取SS_ATTR属性。只有head对象或者snapdir对象保存有SS_ATTR属性,如果head对象不存在,就获取snapdir对象的SS_ATTR属性值,根据获得的值,decode后获得SnapsetContext结构;
6. find_object_context()
本函数查找对象的object_context,这里需要理解snapshot相关的知识。根据snap_seq正确与否获取相应的clone对象,然后获取相应的object_context:
/*
* If we return an error, and set *pmissing, then promoting that
* object may help.
*
* If we return -EAGAIN, we will always set *pmissing to the missing
* object to wait for.
*
* If we return an error but do not set *pmissing, then we know the
* object does not exist.
*/
int ReplicatedPG::find_object_context(const hobject_t& oid, //要查找的对象
ObjectContextRef *pobc, //输出对象的ObjectContext
bool can_create, //是否需要创建
bool map_snapid_to_clone, //映射snapid到clone对象
hobject_t *pmissing); //如果对象不存在,返回缺失的对象参数map_snapid_to_clone指该snap是否可以直接对应一个clone对象,也就是snap对象的snap_id在SnapSet的clones列表中。
1) 如果是head对象,就调用函数get_object_context()获取head对象的ObjectContext,如果失败,设置head对象为pmissing对象,返回-ENOENT;如果获取成功,返回0;
2) 如果是snapdir对象,先获取head对象的ObjectContext,如果失败,继续获取snapdir对象的ObjectContext,如果失败,返回-ENOENT;如果成功,返回0;
3) 如果非map_snapid_to_clone并且该snap已经标记删除了,就直接返回-ENOENT,pmissing为空,意味着该对象确实不存在。
// we want a snap
if (!map_snapid_to_clone && pool.info.is_removed_snap(oid.snap)) {
dout(10) << __func__ << " snap " << oid.snap << " is removed" << dendl;
return -ENOENT;
}4) 调用函数get_snapset_context()来获取SnapSetContext,如果不存在,设置pmissing为head对象,返回-ENOENT。
SnapSetContext *ssc = get_snapset_context(oid, can_create);
if (!ssc || !(ssc->exists || can_create)) {
dout(20) << __func__ << " " << oid << " no snapset" << dendl;
if (pmissing)
*pmissing = head; // start by getting the head
if (ssc)
put_snapset_context(ssc);
return -ENOENT;
}5) 如果是map_snapid_to_clone:
a) 如果oid.snap大于ssc->snapset.seq,说明该snap是最新做的快照,osd端还没有完成相关的信息更新,直接返回head对象object_context,如果head对象存在,就返回0,否则返回-ENOENT。
b) 否则,直接检查SnapSet的clones列表,如果没有,就直接返回-ENOENT.
c) 如果找到,检查对象如果处于missing, pmissing就设置为该clone对象,返回-EAGAIN。如果没有,就获取该clone对象的object_context。
6) 如果不是map_snapid_to_clone,就不能从snap_id直接获取clone对象,需要根据snaps和clones列表,计算snap_id对应的clone对象:
a) 如果oid.snap > ssc->snapset.seq,获取head对象的ObjectContext;
b) 计算oid.snap首次大于ssc->snapset.clones列表中的clone对象,就是oid对应的clone对象;
c) 检查该clone对象如果missing,设置pmissing为该clone对象,返回-EAGAIN。
d) 获取该clone对象的ObjectContext;
e) 最后检查该clone对象如果是在first到last之间,这是合理情况,返回0;否则,就是异常情况,返回-ENOENT。
本函数是获取实际对象的ObjectContext,如果不是head对象,就需要获取快照对象实际对应的clone对象的ObjectContext。
7. execute_ctx()
在do_op()函数里,做了大量的对象状态的检查和上下文相关信息的获取,本函数执行相关的操作:
void ReplicatedPG::execute_ctx(OpContext *ctx);处理过程如下:
1) 首先在OpContext中创建一个新的事务,该事务为pgbackend定义的事务
// this method must be idempotent since we may call it several times
// before we finally apply the resulting transaction.
ctx->op_t.reset(pgbackend->get_transaction());2) 如果是写操作,更新ctx->snapc值。ctx->snapc值保存了该操作的客户端附带的快照相关信息:
a) 如果是给整个pool的快照操作,就设置ctx->snapc等于pool.snapc的值;
b) 如果是用户特定快照(目前只有rbd实现),ctx->snapc值就设置为消息带的相关信息:
// client specified snapc
ctx->snapc.seq = m->get_snap_seq();
ctx->snapc.snaps = m->get_snaps();c) 如果设置了CEPH_OSD_FLAG_ORDERSNAP标志,客户端的snap_seq比服务端的小,就直接返回-EOLDSNAPC错误码。
3) 如果是read操作,该对象的ObjectContext加ondisk_read_lock锁;对于源对象,无论读写操作,都需要加ondisk_read_lock锁。
if (op->may_read()) {
dout(10) << " taking ondisk_read_lock" << dendl;
obc->ondisk_read_lock();
}提示: 所谓源对象,就是一个操作中带两个对象,比如copy操作,源对象会有读操作。
4) 调用函数prepare_transaction()把相关的操作封装到ctx->op_t的事务中。如果是读操作,对于replicate类型,该函数直接调用pgbackend->objects_read_sync同步读取数据;如果是EC,就把请求加入pending_async_reads完成异步读取操作
int result = prepare_transaction(ctx);5) 解除操作3)中加的相关锁;
6) 如果是读操作,并且ctx->pending_async_reads为空,说明是同步读取,调用complete_read_ctx完成读取操作,给客户端返回应答消息。如果是异步读取,就调用函数ctx->start_async_reads()完成异步读取。读操作到这里就结束,后续都是写操作的流程。
// read or error?
if (ctx->op_t->empty() || result < 0) {
// finish side-effects
if (result == 0)
do_osd_op_effects(ctx, m->get_connection());
if (ctx->pending_async_reads.empty()) {
complete_read_ctx(result, ctx);
} else {
in_progress_async_reads.push_back(make_pair(op, ctx));
ctx->start_async_reads(this);
}
return;
}7) 调用calc_trim_to(),计算需要trim的pg log的版本
// trim log?
calc_trim_to();8) 调用函数issue_repop()向各个副本发送同步操作请求;
9) 调用函数eval_repop(),检查发向各个副本的同步操作是否已经reply成功,做相应的操作。
从上可以看出,execute_ctx()操作把相关的操作打包成事务,并没有真正的对对象的数据做修改。
8. calc_trim_to()
本函数用于计算是否应该将旧的pg log日志进行trim操作:
void ReplicatedPG::calc_trim_to()
{
size_t target = cct->_conf->osd_min_pg_log_entries;
if (is_degraded() ||
state_test(PG_STATE_RECOVERING |
PG_STATE_RECOVERY_WAIT |
PG_STATE_BACKFILL |
PG_STATE_BACKFILL_WAIT |
PG_STATE_BACKFILL_TOOFULL)) {
target = cct->_conf->osd_max_pg_log_entries;
}
if (min_last_complete_ondisk != eversion_t() &&
min_last_complete_ondisk != pg_trim_to &&
pg_log.get_log().approx_size() > target) {
size_t num_to_trim = pg_log.get_log().approx_size() - target;
if (num_to_trim < cct->_conf->osd_pg_log_trim_min) {
return;
}
list<pg_log_entry_t>::const_iterator it = pg_log.get_log().log.begin();
eversion_t new_trim_to;
for (size_t i = 0; i < num_to_trim; ++i) {
new_trim_to = it->version;
++it;
if (new_trim_to > min_last_complete_ondisk) {
new_trim_to = min_last_complete_ondisk;
dout(10) << "calc_trim_to trimming to min_last_complete_ondisk" << dendl;
break;
}
}
dout(10) << "calc_trim_to " << pg_trim_to << " -> " << new_trim_to << dendl;
pg_trim_to = new_trim_to;
assert(pg_trim_to <= pg_log.get_head());
assert(pg_trim_to <= min_last_complete_ondisk);
}
}处理过程如下:
1) 首先计算target值: target值为最少保留的日志条数,默认设置为配置项cct->_conf->osd_min_pg_log_entries的值。如果pg处于degraded,或者正在修复的状态,target值为cct->_conf->osd_max_pg_log_entries(默认10000条)
2) 变量min_last_complete_ondisk为本PG在本OSD上完成的最后一条日志记录的版本。如果它不为空,且不等于pg_trim_to,当前pg log的size大于target值,就计算需要trim掉的日志条数:
a) num_to_trim为日志总数目减去target,如果它小于日志一次trim的最小值cct->_conf->osd_pg_log_trim_min,就返回;
b) 否则,从日志头开始计算最新的pg_trim_to版本。
9. prepare_transaction()
本函数用于把相关的更新操作打包为事务,包括比较复杂的部分为对象的snapshot的处理:
int ReplicatedPG::prepare_transaction(OpContext *ctx);处理过程如下:
1) 首先调用调用函数ctx->snapc.is_valid()来验证SnapSet的有效性;
2) 调用函数do_osd_ops()打包请求到ctx->op_t的transaction中
int ReplicatedPG::prepare_transaction(OpContext *ctx){
....
// prepare the actual mutation
int result = do_osd_ops(ctx, ctx->ops);
if (result < 0)
return result;
...
}
int ReplicatedPG::do_osd_ops(OpContext *ctx, vector<OSDOp>& ops)
{
...
PGBackend::PGTransaction* t = ctx->op_t.get();
for (vector<OSDOp>::iterator p = ops.begin(); p != ops.end(); ++p, ctx->current_osd_subop_num++) {
...
switch(op.op){
...
case CEPH_OSD_OP_WRITE:
}
}
}do_osd_ops()函数CEPH_OSD_OP_WRITE实现对写请求的封装。这里我们看到是将要写入的对象数据封装到了ctx->opt_t这样一个Transaction中了。
3) 如果事务为空,或者没有修改操作,就直接返回result
// read-op? done?
if (ctx->op_t->empty() && !ctx->modify) {
unstable_stats.add(ctx->delta_stats);
return result;
}4) 检查磁盘空间是否满
// check for full
if ((ctx->delta_stats.num_bytes > 0 ||
ctx->delta_stats.num_objects > 0) && // FIXME: keys?
(pool.info.has_flag(pg_pool_t::FLAG_FULL) ||
get_osdmap()->test_flag(CEPH_OSDMAP_FULL))) {
MOSDOp *m = static_cast<MOSDOp*>(ctx->op->get_req());
if (ctx->reqid.name.is_mds() || // FIXME: ignore MDS for now
m->has_flag(CEPH_OSD_FLAG_FULL_FORCE)) {
dout(20) << __func__ << " full, but proceeding due to FULL_FORCE or MDS"<< dendl;
} else if (m->has_flag(CEPH_OSD_FLAG_FULL_TRY)) {
// they tried, they failed.
dout(20) << __func__ << " full, replying to FULL_TRY op" << dendl;
return pool.info.has_flag(pg_pool_t::FLAG_FULL) ? -EDQUOT : -ENOSPC;
} else {
// drop request
dout(20) << __func__ << " full, dropping request (bad client)" << dendl;
return -EAGAIN;
}
}5) 如果该对象是head对象,就有相关快照对象COW机制的操作,需要调用函数make_writable()来完成,在关于快照的介绍中会详细介绍到。
// clone, if necessary
if (soid.snap == CEPH_NOSNAP)
make_writeable(ctx);6) 调用函数finish_ctx来完成后续处理,该函数主要完成了快照相关的处理。如果head对象存在,就删除snapdir对象;如果不存在,就创建snapdir对象,用来保存快照相关的信息。此外,这里很重要的一个步骤是涉及到PGLog的处理:
int ReplicatedPG::prepare_transaction(OpContext *ctx)
{
finish_ctx(ctx,
ctx->new_obs.exists ? pg_log_entry_t::MODIFY :
pg_log_entry_t::DELETE);
}
void ReplicatedPG::finish_ctx(OpContext *ctx, int log_op_type, bool maintain_ssc,
bool scrub_ok){
...
// append to log
ctx->log.push_back(pg_log_entry_t(log_op_type, soid, ctx->at_version,
ctx->obs->oi.version,
ctx->user_at_version, ctx->reqid,
ctx->mtime));
if (soid.snap < CEPH_NOSNAP) {
switch (log_op_type) {
case pg_log_entry_t::MODIFY:
case pg_log_entry_t::PROMOTE:
case pg_log_entry_t::CLEAN:
dout(20) << __func__ << " encoding snaps " << ctx->new_obs.oi.snaps << dendl;
::encode(ctx->new_obs.oi.snaps, ctx->log.back().snaps);
break;
default:
break;
}
}
...
}
//src/osd/osd_types.h
struct pg_log_entry_t {
enum {
MODIFY = 1, // some unspecified modification (but not *all* modifications)
CLONE = 2, // cloned object from head
DELETE = 3, // deleted object
BACKLOG = 4, // event invented by generate_backlog [deprecated]
LOST_REVERT = 5, // lost new version, revert to an older version.
LOST_DELETE = 6, // lost new version, revert to no object (deleted).
LOST_MARK = 7, // lost new version, now EIO
PROMOTE = 8, // promoted object from another tier
CLEAN = 9, // mark an object clean
};
// describes state for a locally-rollbackable entry
ObjectModDesc mod_desc;
bufferlist snaps; // only for clone entries
hobject_t soid;
osd_reqid_t reqid; // caller+tid to uniquely identify request
vector<pair<osd_reqid_t, version_t> > extra_reqids;
eversion_t version, prior_version, reverting_to;
version_t user_version; // the user version for this entry
utime_t mtime; // this is the _user_ mtime, mind you
__s32 op;
bool invalid_hash; // only when decoding sobject_t based entries
bool invalid_pool; // only when decoding pool-less hobject based entries
pg_log_entry_t()
: user_version(0), op(0),
invalid_hash(false), invalid_pool(false) {}
pg_log_entry_t(int _op, const hobject_t& _soid,
const eversion_t& v, const eversion_t& pv,
version_t uv,
const osd_reqid_t& rid, const utime_t& mt)
: soid(_soid), reqid(rid), version(v), prior_version(pv), user_version(uv),
mtime(mt), op(_op), invalid_hash(false), invalid_pool(false)
{}
};PGLog在ceph的数据一致性方面非常重要。从上面可以看到,对于每一次的数据写操作,均会构造一个pg_log_entry_t对象将其放入ctx->log中。后续在ReplicatedBackend::submit_transaction()中,实际上会向ctx->log这一vector中的日志打包放入ctx->opt_t中的。注意: 这里PGLog与实际的对象数据是存在于同一个transaction中的。
10. issue_repop()
void ReplicatedPG::issue_repop(RepGather *repop, OpContext *ctx)
{
const hobject_t& soid = ctx->obs->oi.soid;
dout(7) << "issue_repop rep_tid " << repop->rep_tid
<< " o " << soid
<< dendl;
repop->v = ctx->at_version;
if (ctx->at_version > eversion_t()) {
for (set<pg_shard_t>::iterator i = actingbackfill.begin();
i != actingbackfill.end();
++i) {
if (*i == get_primary()) continue;
pg_info_t &pinfo = peer_info[*i];
// keep peer_info up to date
if (pinfo.last_complete == pinfo.last_update)
pinfo.last_complete = ctx->at_version;
pinfo.last_update = ctx->at_version;
}
}
ctx->obc->ondisk_write_lock();
if (ctx->clone_obc)
ctx->clone_obc->ondisk_write_lock();
bool unlock_snapset_obc = false;
if (ctx->snapset_obc && ctx->snapset_obc->obs.oi.soid !=
ctx->obc->obs.oi.soid) {
ctx->snapset_obc->ondisk_write_lock();
unlock_snapset_obc = true;
}
ctx->apply_pending_attrs();
if (pool.info.require_rollback()) {
for (vector<pg_log_entry_t>::iterator i = ctx->log.begin();
i != ctx->log.end();
++i) {
assert(i->mod_desc.can_rollback());
assert(!i->mod_desc.empty());
}
}
Context *on_all_commit = new C_OSD_RepopCommit(this, repop);
Context *on_all_applied = new C_OSD_RepopApplied(this, repop);
Context *onapplied_sync = new C_OSD_OndiskWriteUnlock(
ctx->obc,
ctx->clone_obc,
unlock_snapset_obc ? ctx->snapset_obc : ObjectContextRef());
pgbackend->submit_transaction(
soid,
ctx->at_version,
std::move(ctx->op_t),
pg_trim_to,
min_last_complete_ondisk,
ctx->log,
ctx->updated_hset_history,
onapplied_sync,
on_all_applied,
on_all_commit,
repop->rep_tid,
ctx->reqid,
ctx->op);
}本函数的处理过程如下:
1) 首先更新actingbackfill的osd对应的peer_info的相关信息:如果pinfo.last_update和pinfo.last_complete二者相等,说明该peer的状态处于clean状态,就同时更新二者,否则只更新pinfo.last_update值。(注:通过pinfo.last_update、pinfo.last_complete来反应当前PG的状态信息)
2) 对该对象的ObjectContext的ondisk_write_lock加写锁,如果有clone对象,对该clone对象的ObjectContext的ondisk_write_lock加写锁。如果snapset_obc不为空,也就是可能创建或者删除snapdir对象,对该ObjectContext的ondisk_write_lock加锁。
3) 如果pool是可以rollback的(也就是ErasureCode模式),检查pg log也应该支持rollback操作;
4) 分别设置三个回调Context,调用函数pgbackend->submit_transaction()来完成事务向从OSD的发送;
本函数调用pgbackend的submit_transaction()函数向从osd开始发送操作日志。
2.3 阶段3: PGBackend的处理
PGBackend为PG的更新操作增加了一层与PG类型相关的实现。对于Replicate类型的PG由类ReplicatedBackend实现。其核心处理过程是把封装好的事务分发到该PG对应的其他从OSD上;对于ErasureCode类型的PG由类ECBackend实现,其核心处理过程为主chunk向各个分片chunk分发数据的过程。下面着重介绍Replicate的处理方式。
ReplicatedBackend::submit_transaction()函数最终调用网络接口,把更新请求发送给从OSD:
void ReplicatedBackend::submit_transaction(
const hobject_t &soid,
const eversion_t &at_version,
PGTransactionUPtr &&_t,
const eversion_t &trim_to,
const eversion_t &trim_rollback_to,
const vector<pg_log_entry_t> &log_entries,
boost::optional<pg_hit_set_history_t> &hset_history,
Context *on_local_applied_sync,
Context *on_all_acked,
Context *on_all_commit,
ceph_tid_t tid,
osd_reqid_t reqid,
OpRequestRef orig_op)
{
std::unique_ptr<RPGTransaction> t(
static_cast<RPGTransaction*>(_t.release()));
assert(t);
ObjectStore::Transaction op_t = t->get_transaction();
assert(t->get_temp_added().size() <= 1);
assert(t->get_temp_cleared().size() <= 1);
assert(!in_progress_ops.count(tid));
InProgressOp &op = in_progress_ops.insert(
make_pair(
tid,
InProgressOp(
tid, on_all_commit, on_all_acked,
orig_op, at_version)
)
).first->second;
op.waiting_for_applied.insert(
parent->get_actingbackfill_shards().begin(),
parent->get_actingbackfill_shards().end());
op.waiting_for_commit.insert(
parent->get_actingbackfill_shards().begin(),
parent->get_actingbackfill_shards().end());
issue_op(
soid,
at_version,
tid,
reqid,
trim_to,
trim_rollback_to,
t->get_temp_added().empty() ? hobject_t() : *(t->get_temp_added().begin()),
t->get_temp_cleared().empty() ?
hobject_t() : *(t->get_temp_cleared().begin()),
log_entries,
hset_history,
&op,
op_t);
if (!(t->get_temp_added().empty())) {
add_temp_objs(t->get_temp_added());
}
clear_temp_objs(t->get_temp_cleared());
parent->log_operation(
log_entries,
hset_history,
trim_to,
trim_rollback_to,
true,
op_t);
op_t.register_on_applied_sync(on_local_applied_sync);
op_t.register_on_applied(
parent->bless_context(
new C_OSD_OnOpApplied(this, &op)));
op_t.register_on_commit(
parent->bless_context(
new C_OSD_OnOpCommit(this, &op)));
vector<ObjectStore::Transaction> tls;
tls.push_back(std::move(op_t));
parent->queue_transactions(tls, op.op);
}其处理过程如下:
1) 首先构建InProgressOp请求记录;
2) 调用函数ReplicatedBackend::issue_op把请求发送出去: 对于该PG中的每一个从OSD,
a) 调用函数generate_subop()生成MSG_OSD_REPOP类型的请求;
b) 调用函数get_parent()->send_message_osd_cluster()把消息发送出去;
3) 最后调用parent->queue_transactions()函数来完成自己,也就是该PG的主OSD上本地对象的数据修改。这里我们可以看到主OSD的OnCommit的结果可以通过回调C_OSD_OnOpCommit()来获得,而其又会回调ReplicatedBackend::op_commit();相似的,OnApply的结果可以通过回调C_OSD_OnOpApplied()来获得,而其又会回调ReplicatedBackend::op_applied()。在op_commit()以及on_applied()两个函数里会回调ReplicatedBackend::InProgressOp结构体中注册的Context,关于这一点我们会在本章最后一节进行分析。
2.4 从副本的处理
当PG的从副本OSD接收到MSG_OSD_REPOP类型的操作,也就是主副本发来的同步写的操作时,处理流程和上述流程都一样。在函数sub_op_modify()里,对本地存储应用相应的事务,完成本地对象的数据写入:
void ReplicatedBackend::sub_op_modify(OpRequestRef op)
{
MOSDRepOp *m = static_cast<MOSDRepOp *>(op->get_req());
m->finish_decode();
int msg_type = m->get_type();
assert(MSG_OSD_REPOP == msg_type);
const hobject_t& soid = m->poid;
dout(10) << "sub_op_modify trans"
<< " " << soid
<< " v " << m->version
<< (m->logbl.length() ? " (transaction)" : " (parallel exec")
<< " " << m->logbl.length()
<< dendl;
// sanity checks
assert(m->map_epoch >= get_info().history.same_interval_since);
// we better not be missing this.
assert(!parent->get_log().get_missing().is_missing(soid));
int ackerosd = m->get_source().num();
op->mark_started();
RepModifyRef rm(std::make_shared<RepModify>());
rm->op = op;
rm->ackerosd = ackerosd;
rm->last_complete = get_info().last_complete;
rm->epoch_started = get_osdmap()->get_epoch();
assert(m->logbl.length());
// shipped transaction and log entries
vector<pg_log_entry_t> log;
bufferlist::iterator p = m->get_data().begin();
::decode(rm->opt, p);
if (m->new_temp_oid != hobject_t()) {
dout(20) << __func__ << " start tracking temp " << m->new_temp_oid << dendl;
add_temp_obj(m->new_temp_oid);
}
if (m->discard_temp_oid != hobject_t()) {
dout(20) << __func__ << " stop tracking temp " << m->discard_temp_oid << dendl;
if (rm->opt.empty()) {
dout(10) << __func__ << ": removing object " << m->discard_temp_oid
<< " since we won't get the transaction" << dendl;
rm->localt.remove(coll, ghobject_t(m->discard_temp_oid));
}
clear_temp_obj(m->discard_temp_oid);
}
p = m->logbl.begin();
::decode(log, p);
rm->opt.set_fadvise_flag(CEPH_OSD_OP_FLAG_FADVISE_DONTNEED);
bool update_snaps = false;
if (!rm->opt.empty()) {
// If the opt is non-empty, we infer we are before
// last_backfill (according to the primary, not our
// not-quite-accurate value), and should update the
// collections now. Otherwise, we do it later on push.
update_snaps = true;
}
parent->update_stats(m->pg_stats);
parent->log_operation(
log,
m->updated_hit_set_history,
m->pg_trim_to,
m->pg_trim_rollback_to,
update_snaps,
rm->localt);
rm->opt.register_on_commit(
parent->bless_context(
new C_OSD_RepModifyCommit(this, rm)));
rm->localt.register_on_applied(
parent->bless_context(
new C_OSD_RepModifyApply(this, rm)));
vector<ObjectStore::Transaction> tls;
tls.reserve(2);
tls.push_back(std::move(rm->localt));
tls.push_back(std::move(rm->opt));
parent->queue_transactions(tls, op);
// op is cleaned up by oncommit/onapply when both are executed
}如下是从OSD接收消息并处理的流程图:
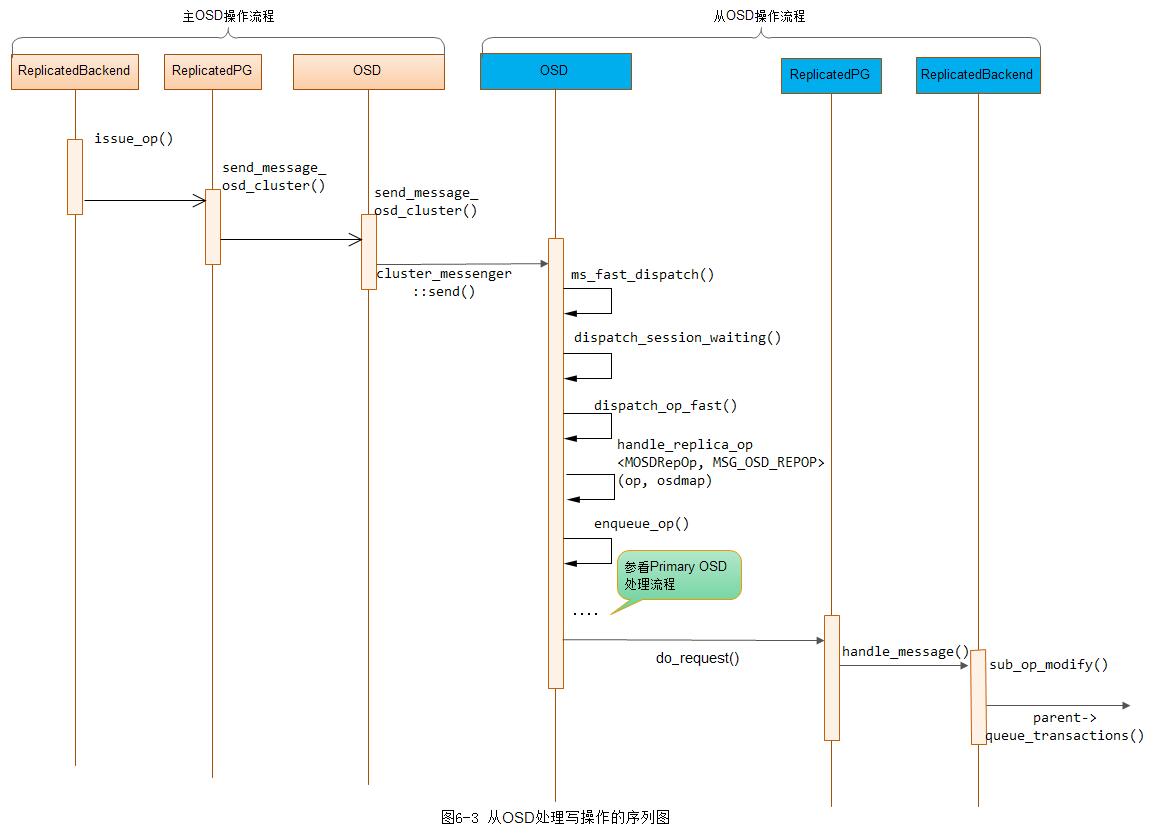
此外,通过上面的代码我们可以看到,本地数据写入的结果可以通过所注册的C_OSD_RepModifyCommit()以及C_OSD_RepModifyApply()两个回调函数获得。这里onCommit的回调函数为:
void ReplicatedBackend::sub_op_modify_commit(RepModifyRef rm)
{
rm->op->mark_commit_sent();
rm->committed = true;
// send commit.
dout(10) << "sub_op_modify_commit on op " << *rm->op->get_req()
<< ", sending commit to osd." << rm->ackerosd
<< dendl;
assert(get_osdmap()->is_up(rm->ackerosd));
get_parent()->update_last_complete_ondisk(rm->last_complete);
Message *m = rm->op->get_req();
Message *commit = NULL;
if (m->get_type() == MSG_OSD_SUBOP) {
// doesn't have CLIENT SUBOP feature ,use Subop
MOSDSubOpReply *reply = new MOSDSubOpReply(
static_cast<MOSDSubOp*>(m),
get_parent()->whoami_shard(),
0, get_osdmap()->get_epoch(), CEPH_OSD_FLAG_ONDISK);
reply->set_last_complete_ondisk(rm->last_complete);
commit = reply;
} else if (m->get_type() == MSG_OSD_REPOP) {
MOSDRepOpReply *reply = new MOSDRepOpReply(
static_cast<MOSDRepOp*>(m),
get_parent()->whoami_shard(),
0, get_osdmap()->get_epoch(), CEPH_OSD_FLAG_ONDISK);
reply->set_last_complete_ondisk(rm->last_complete);
commit = reply;
}
else {
assert(0);
}
commit->set_priority(CEPH_MSG_PRIO_HIGH); // this better match ack priority!
get_parent()->send_message_osd_cluster(
rm->ackerosd, commit, get_osdmap()->get_epoch());
log_subop_stats(get_parent()->get_logger(), rm->op, l_osd_sop_w);
}从上面可以看到,最终其会通过cluster_messenger向主OSD发送应答信息。
2.5 主副本接收到从副本的应答
当PG的主副本接收到从副本的应答消息MSG_OSD_REPOPREPLY时,处理流程和上述类似,不同之处在于,在函数ReplicatedPG::do_request()里调用了函数ReplicatedBackend::handle_message(),在该函数里调用了ReplicatedBackend::sub_op_modify_reply()函数处理该请求。
注:从OSD向主OSD发送MSG_OSD_REPOPREPLY应答消息,主OSD收到应答消息后,又会经历一次OSD::ms_fast_dispatch()到ReplicatedPG::do_request()这一大段流程,可以参看“图6-2 OSD处理写操作的序列图”
sub_op_modify_reply函数的处理过程如下:
void ReplicatedBackend::sub_op_modify_reply(OpRequestRef op);1) 首先在in_progress_ops中查找到该请求;
2) 如果是ondisk的ACK,也就是事务已经应答,就在ip_op.waiting_for_commit删除该OSD。该事务已经应答,那么必定已经提交了,那么从ip_op.waiting_for_applied删除该OSD;
3) 如果只是事务提交到日志中的ACK,就从ip_op.waiting_for_applied删除
注: 这里特别说明的是,从副本需要给主副本发送两次ACK,一次是事务提交到日志中,并没有应用到实际的对象数据中;一次是完成应用操作返回的ACK。
4) 最后检查,如果ip_op.waiting_for_applied为空,也就是所有从OSD的请求都返回来了,并且ip_op.on_applied(其为一个Context)不为NULL,就调用该Context的complete函数。同样,检查ip_op.waiting_for_commit为空,并且ip_op.on_commit(其为一个Context)不为NULL,就调用该Context的complte函数。
下面看一下,in_progress_ops注册的回调函数。其回调函数是在ReplicatedPG::issue_repop()函数调用里注册的:
void ReplicatedPG::issue_repop(RepGather *repop, OpContext *ctx)
{
....
Context *on_all_commit = new C_OSD_RepopCommit(this, repop);
Context *on_all_applied = new C_OSD_RepopApplied(this, repop);
Context *onapplied_sync = new C_OSD_OndiskWriteUnlock(
ctx->obc,
ctx->clone_obc,
unlock_snapset_obc ? ctx->snapset_obc : ObjectContextRef());
pgbackend->submit_transaction(
soid,
ctx->at_version,
std::move(ctx->op_t),
pg_trim_to,
min_last_complete_ondisk,
ctx->log,
ctx->updated_hset_history,
onapplied_sync,
on_all_applied,
on_all_commit,
repop->rep_tid,
ctx->reqid,
ctx->op);
}回调函数都最终调用了函数ReplicatedPG::eval_repop,其最终向client发送应答消息。这里强调的是,主副本必须等待所有的处于up的OSD都返回成功的ACK应答消息,才向客户端返回请求成功的应答。
注: 只要所有处于up状态的OSD都返回了onApplied应答(事务已经写入日志)即可向client发送响应消息,不必等到OnCommit应答。
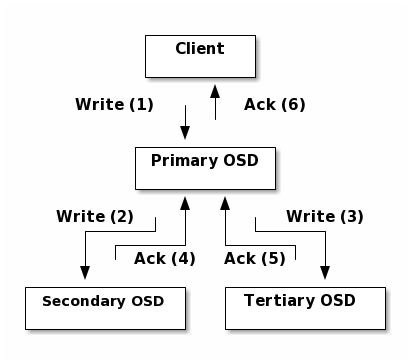
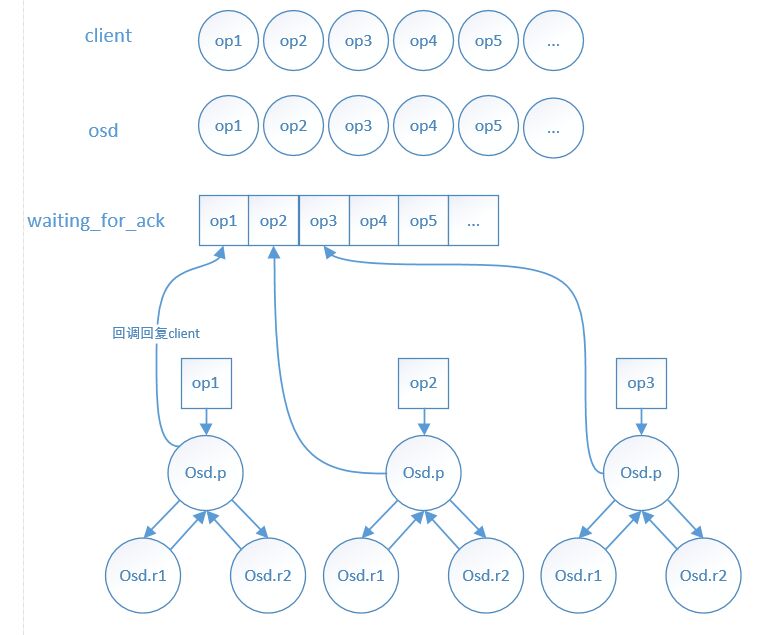
下面再贴出一张官网上面关于ceph写数据的图:
3. 总结
本章介绍了OSD读写流程核心处理过程。通过本章的介绍,可以了解读写流程的主干流程,并对一些核心概念和数据结构的处理做了介绍。当然,读写流程是ceph文件系统的核心流程,其实现细节比较复杂,还需要读者对照代码继续研究。目前在这方面的工作,许多都集中在提供ceph的读写性能。其基本的方法更多的就是优化读写流程的关键路径,通过减少锁来提供并发,同时简化一些关键流程。
[参看]
