ceph本地对象存储(3)
在本地对象中,日志是实现操作一致性的机制。在介绍Filestore之前,首先需要了解Journal的机制。本章首先介绍Journal的对外接口,通过对外提供的功能接口,可以了解日志的基本功能。然后详细介绍FileJournal的实现。
1. Journal对外接口
通过Ceph中的test_filejournal.cc的一段测试程序,执行如下命令编译:
# cd src # make ceph_test_filejournal
可以比较清楚地了解Journal的外部接口,通过这些外部接口可以了解Journal的功能,以及如何使用Journal:
FileJournal j(fsid, finisher, &sync_cond, path, directio, aio, faio);
j.create();
j.make_writeable();
vector<ObjectStore::Transaction> tls;
bufferlist bl;
bl.append("small");
int orig_len = j.prepare_entry(tls, &bl); //获得日志的原始长度
j.reserve_throttle_and_backoff(bl.length());
j.submit_entry(1, bl, orig_len, new C_SafeCond(&wait_lock, &cond, &done));
wait();
j.close();通过上述代码可以了解到,日志的基本使用方法如下所示:
1) 创建一个FileJournal类型的日志对象,其构造函数path为日志文件的路径;
2) 调用日志的create方法创建日志,并调用函数make_writable()设置为可写状态;
3) 在bufferlist中添加一段数据作为测试的日志数据,调用submit_entry提交一条日志;
4) 等待日志提交完成;
5) 关闭日志
2. FileJournal
类FileJournal以文件(包括块设备文件看做特殊文件)作为日志,实现了Journal的接口。下面先介绍FileJournal的数据结构和日志的格式,然后介绍日志的三个阶段: 日志的提交(journal submit)、日志的应用(journal apply)、日志的同步(journal sync或者commit、trim)及其具体的实现过程。
2.1 FileJournal数据结构
FileJournal数据结构如下:
1) write_item部分
//FileJournal用于在文件或块设备层面实现日志功能
class FileJournal :
public Journal,
public md_config_obs_t {
public:
struct write_item {
uint64_t seq;
bufferlist bl;
uint32_t orig_len;
TrackedOpRef tracked_op;
write_item(uint64_t s, bufferlist& b, int ol, TrackedOpRef opref) :
seq(s), orig_len(ol), tracked_op(opref) {
bl.claim(b, buffer::list::CLAIM_ALLOW_NONSHAREABLE); // potential zero-copy
}
write_item() : seq(0), orig_len(0) {}
};
Mutex writeq_lock; //writeq相关的锁
Cond writeq_cond; //writeq相关的条件变量
list<write_item> writeq; //保存write_item的队列
};结构体write_item封装了一条提交的日志,seq为提交日志的序号,bl保存了提交的日志数据,也就是提交的事务或事务的集合序列化后的数据。Journal并不关心日志数据的内容,它认为一条日志就是一段写入的数据,只负责把数据正确写入日志盘。orig_len记录日志的原始长度,由于日志字节对齐的需要,最终写入的数据长度可能会变化。
所有提交的日志,都先保存到writeq这个内部的队列中,writeq_lock和writeq_cond是writeq相应的锁和条件变量。
2) completion_item部分
struct completion_item {
uint64_t seq; //日志的序号
Context *finish; //完成后的回调函数
utime_t start; //提交时间
TrackedOpRef tracked_op;
completion_item(uint64_t o, Context *c, utime_t s,
TrackedOpRef opref)
: seq(o), finish(c), start(s), tracked_op(opref) {}
completion_item() : seq(0), finish(0), start(0) {}
};
Mutex completions_lock;
list<completion_item> completions;结构体completion_item记录准备提交的item,保存在列表completions中。由锁completions_lock保护。
3) 日志头部header_t
struct header_t{
enum {
FLAG_CRC = (1<<0),
};
uint64_t flags; //日志的一些标志
uuid_d fsid; //文件系统的id
__u32 block_size; //日志文件或设备的块大小
__u32 alignment; //对齐
int64_t max_size; //日志的最大size。日志是一段一段的,每一段日志都要有一个日志头
int64_t start; //offset of first entry
uint64_t committed_up_to; //已经提交的日志的seq,等同于journaled_seq
/*
* 本日志段的起始seq,header.start处的日志的seq >= start_seq
*
* 通常情况下,header.start处的日志的seq会等于start_seq。唯一的例外是当新创建一个日志文件时,由于
* 并不知道初始seq是什么,这种情况下就会出现header.start处的seq > start_seq
*
* 假如在打开一个日志文件后,初始读取日志失败,若start_seq > committed_up_thru的话,我们就认为
* 日志已经遭到了破坏,因为header.start处的日志的seq >= start_seq,因此肯定会有 seq > committed_up_thru
*/
uint64_t start_seq;
}header; 4) 其他字段
bool must_write_header; //是否必须写入一个header,当日志同步完成后,就设置本标准,必须要写入一个header,
//以持久化保存因日志同步而变化了的header结构
off64_t write_pos; //byte where the next entry to be written will go
off64_t read_pos; //日志读取的位置
uint64_t last_committed_seq; //最后同步完成的seq
enum {
FULL_NOTFULL = 0,
FULL_FULL = 1,
FULL_WAIT = 2,
} full_state; //日志的磁盘空间状态
deque<pair<uint64_t, off64_t> > journalq; // 跟踪记录在日志中的偏移,用于在日志删除时可以方便的知道偏移位置
//(pair的一个元素用于表示相应日志的seq值,第二个元素表示该条日志在Journal日志文件中的偏移)
uint64_t writing_seq; //当前正在写入的最大的seq
Mutex write_lock; //
bool write_stop; //写线程是否停止的标记
Mutex finisher_lock;
Cond finisher_cond;
uint64_t journaled_seq; //已提交成功的日志的最大seq
JournalThrottle throttle; //对日志进行限流2.2 日志的格式
日志的格式如下(会在FileJournal::prepare_entry()中进行打包):
entry_header_t + journal data + entry_header_t
每条日志数据的头部和尾部都添加了entry_header_t结构。此外,日志在每次同步完成的时候设置must_write_header为true时会强制插入一个日志头header_t的结构,用于持久化存储header中变化了的字段。日志的结构如下图7-1所示。
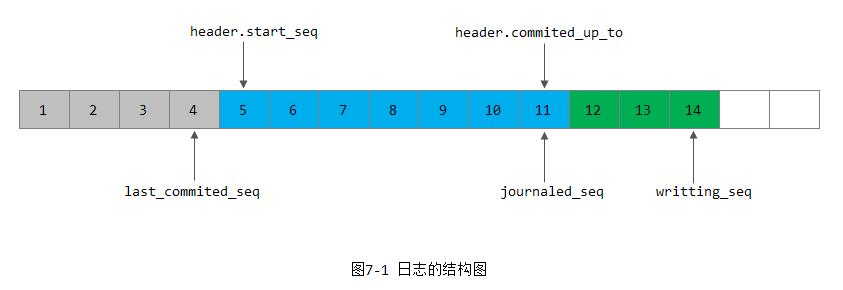
日志记录1到4为已经由日志同步时trim掉的日志(逻辑删除),last_commited_seq记录了最后一个trim的日志序号,当前值为4。日志记录5到11为已经提交成功的日志。journaled_seq记录已经提交成功的日志最大序号,当前值为11。日志记录12到14为正在提交,还没有完成的日志。writting_seq记录正在提交的最大日志序号,当前值为14。
header.start_seq记录提交成功的第一条有效日志,当前显示为5;header.committed_up_to为提交成功的最后一条日志,当前值为11。
entry_header_t结构如下所示:
struct entry_header_t {
uint64_t seq; // fs op seq #
uint32_t crc32c; // payload only. not header, pre_pad, post_pad, or footer.
uint32_t len;
uint32_t pre_pad, post_pad;
uint64_t magic1; //用于记录本条日志写到Journal日志文件的偏移位置
uint64_t magic2; //
};2.3 日志的提交
函数FileJournal::submit_entry用于提交日志:
void FileJournal::submit_entry(uint64_t seq, bufferlist& e, uint32_t orig_len, Context *oncommit, TrackedOpRef osd_op);
其处理过程如下:
1) 其分别加writeq_lock锁和completions_lock锁;
2) 然后构造completion_item和write_item两个数据结构体,并分别加入到completions队列和writeq队列中;
3) 如果wirteq队列为空,就通过writeq_cond.Signal()触发写线程。(如果writeq不为空,说明线程一直在忙碌处理请求,不会睡眠,就没必要再次触发了)。
write_thread线程是FileJournal内部的一个工作线程。该线程的会在FileJournal::make_writeable()中被启动,线程的处理函数write_thread_entry实现了不断地从writeq队列中取出write_item请求,并完成把日志数据写入磁盘的工作。
write_thread_entry()函数调用prepare_multi_write()函数,把多个write_item合并到一个bufferlist中打包写入,可以提高日志写入的性能。配置项g_conf->journal_max_write_entries为一次写入的最大日志条目数量,配置项g_conf->journal_max_write_bytes为一次合并写入的最大字节数。
prepare_multi_write()函数调用batch_pop_write()函数,从writeq里一次获取所有的write_item,对每一个write_item调用函数prepare_single_write()进行处理。
prepare_single_write()函数实现了把日志数据封装成日志格式的数据:
1) 在数据的前端和后端都添加了一个entry_header_t的数据结构;
2) journalq记录了该条日志在日志文件(或者设备)中的起始偏移量,它在日志同步时,用于逻辑删除该条日志
journalq.push_back(pair<uint64_t,off64_t>(seq, queue_pos));3) 更新writting_seq的值为当前日志的seq,并更新当前日志写入的queue_pos的值。当queue_pos达到日志的最大值时,需要从日志的头开始:
writing_seq = seq;
queue_pos += size;
if (queue_pos >= header.max_size)
queue_pos = queue_pos + get_top() - header.max_size;如下图所示:
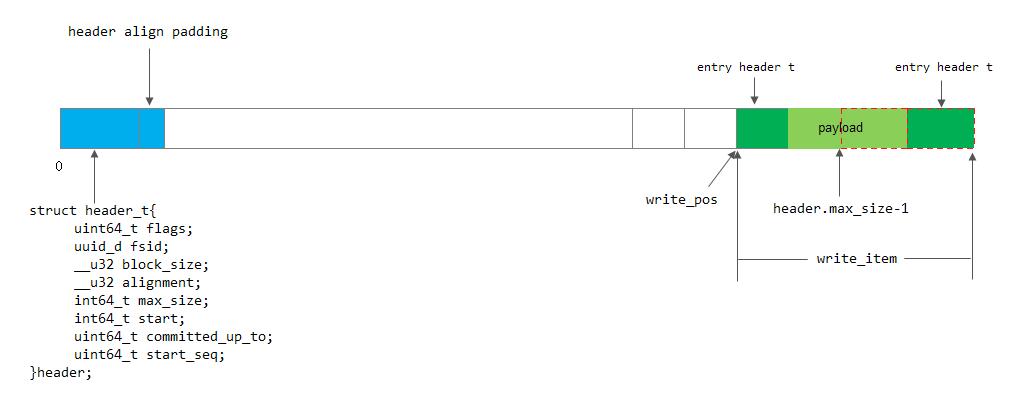
当调用函数prepare_multi_write把日志封装成需要的格式后,就需要把数据写入日志盘。目前有两种实现方式: 一种是同步写入;另一种是Linux系统提供的异步IO的方式。
同步写入
同步写入方式直接调用do_write函数实现, 该函数具体过程如下:
1) 首先判断是否需要写入日志的header头部: 日志在每隔配置选项设定的g_conf->journal_write_header_frequency日志条数后或者must_write_header设置时插入一个header头。
2) 其次计算如果日志数据超过了日志文件的最大长度,就需要把该条日志的数据分两次写入: 尾端写入一部分,然后绕到头部写入一部分。
3) 如果不是directIO,就需要调用函数fsync把日志数据刷到磁盘上
4) 加finisher_lock,更新journaled_seq(journaled_seq用于记录已提交成功的日志的最大seq)
5) 如果日志为不满的状态,并且plug_journal_completions没有设置,就调用函数queue_completions_thru()来把completion_item的callback函数加入Finisher,来实现回调告诉上层日志已经写入完成。最后删除该completion_item项
异步写入
异步IO的方式写入是日志写入的另一种方式,是使用了Linux操作系统内核自带的异步IO(aio)。Linux内核实现的aio,必须以directIO的方式写入。aio由于内核实现,数据不经过缓存直接落盘,性能要比同步的方式高很多。
异步IO相关的数据结构如下:
struct aio_info{
struct iocb iocb; //提交的异步aio控制块
bufferlist bl; //aio的数据
struct iovec *iov; //异步aio方式的数据
bool done; //是否完成的标志
uint64_t off, len; //these are for debug only
uint64_t seq; //aio的序号
};
Mutex aio_lock; //aio队列的锁
Cond aio_cond; //控制inflight的aio不能过多,否则需要等待
Cond write_finish_cond; //aio完成,触发完成线程去处理
io_context_t aio_ctx; //异步IO的上下文
list<aio_info> aio_queue; //已经提交的aio请求队列
int aio_num, aio_bytes; //正在进行的aio的数量和数据量
uint64_t aio_write_queue_ops;
uint64_t aio_write_queue_bytes;异步IO的方式写日志,调用了do_aio_write函数,基本过程和do_write相似,只是写入的方式调用了write_aio_bl函数。
函数write_aio_bl实现了调用Linux的aio的API异步写入磁盘。实现过程如下:
1) 首先把数据转换成iovec的格式;
2) 构造aio_info数据结构,该结构保存了aio的上下文信息,并把它加入aio_queue队列里;
3) 调用函数io_prep_pwritev和函数io_submit,异步提交请求:
io_prep_pwritev(&aio.iocb, fd, aio.iov, n, pos);
int r = io_submit(aio_ctx, 1, &piocb);3) 触发write_finish_thread检查异步IO是否完成
aio_lock.Lock();
write_finish_cond.Signal();
aio_lock.Unlock();函数write_finish_thread_entry()为线程write_finish_thread的执行函数,用来检查aio是否完成。其具体实现如下:
1) 调用函数io_getevents来检查是否有aio事件完成的
io_event event[16];
int r = io_getevents(aio_ctx, 1, 16, event, NULL);2) 对每个完成的事件,获取相应的aio_info结构。检查写入的数据是否是aio的数据长度,然后设置ai->done为true,标记该aio已经完成。
3) 调用函数check_aio_completion检查aio_queue队列的完成情况。由于aio的并发提交,多条日志可能并发完成,为了保证日志是按照seq的顺序完成,必须从头按顺序检查aio_queue的完成情况。
4) 更新journaled_seq的值,调用queue_completions_thru()函数完成后续工作,这和同步实现工作一样。
2.4 日志的同步
日志的同步是在日志已经成功应用完成,对应的日志数据已经确保写入磁盘对象后,就删除相应的日志,释放出日志空间的过程。
函数committed_thru用来实现日志的同步。它只是完成了日志的同步功能。日志同步时,必须确保日志应用完成,这个逻辑在Filestore里完成。
函数committed_thru具体实现如下:
1) 确保当前同步的seq必上次last_committed_seq大
2) 用seq更新last_committed_seq的值。之后会调用
queue_completions_thru(seq);
这里我们知道在日志数据写入成功时也会调用该函数,而在应用成功时也会回调,而一般是先写日志,后再对日志进行应用,那么为什么需要调用两次呢?
通过后面我们了解到,在FileStore里,根据日志条方式的不同,有3种类型的日志:
-
journal writeahead
-
journal parallel
-
不使用日志的情况(基本不用)
对于journal parallel这种并行提交的情况,有可能会出现日志应用先于日志写入成功这种情况,因此这里也调用queue_completions_thru可以尽快获得对象数据写入成功的通知。
3) 把journalq中小于等于seq的记录删除掉,这些记录已经无用了
4) 删除相应的日志。这里只是逻辑上的删除,只是修改header.start指针就可以了。当journalq为空,就删除到设置write_pos位置;如果journalq不为空,就设置为队列的第一条记录的偏移值,这是最新日志的起始地址,也就是上一条日志的结尾。
5) 设置must_write_header为true,由于header更新了,日志必须把header写入磁盘
6) 日志可能因日志空间满而阻塞写线程,此时由于释放出更多空间,就调用commit_cond.Signal()唤醒写线程
3. 总结
下面我们对Journal写日志的过程进行一下总结:
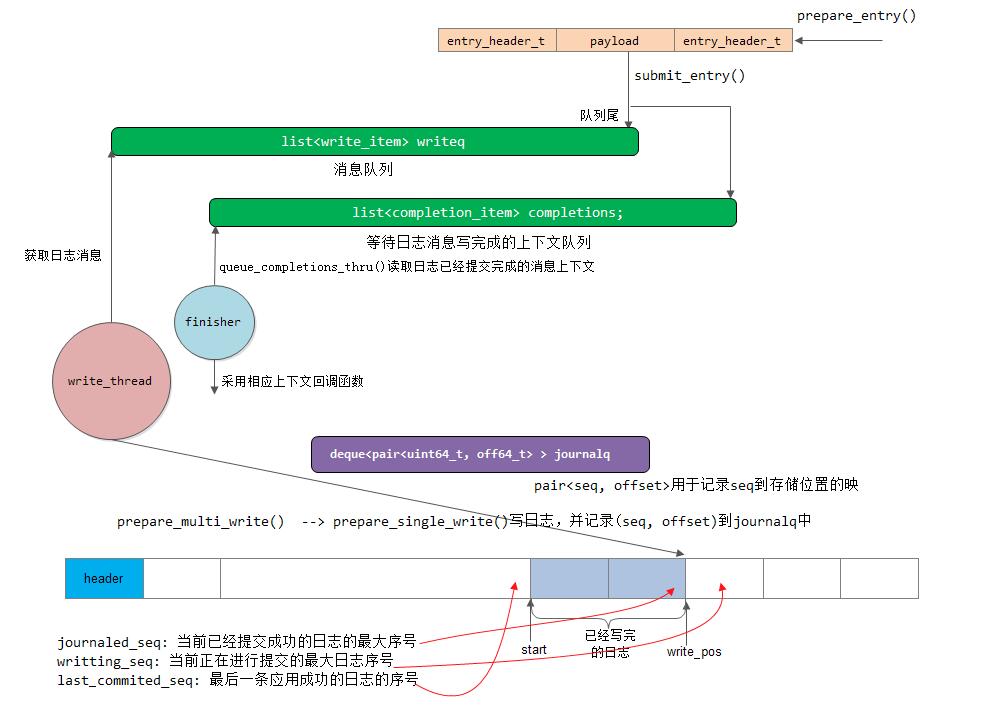
[参看]
