ceph中对象读写的顺序性及并发性保证(转)
分布式系统中经常需要考虑对象(或者记录、文件、数据块等)的读写顺序以及并发访问问题。通常来说,如果两个对象没有共享的资源,就可以进行并发的访问;如果有共享的部分,就需要对这部分资源进行加锁。而对于同一个对象的并发读写(尤其是并发写更新时),就需要注意顺序性以及并发访问的控制,以免数据错乱。本文主要针对ceph中对象读写的顺序及并发性保证机制进行介绍。
1. PG的概念
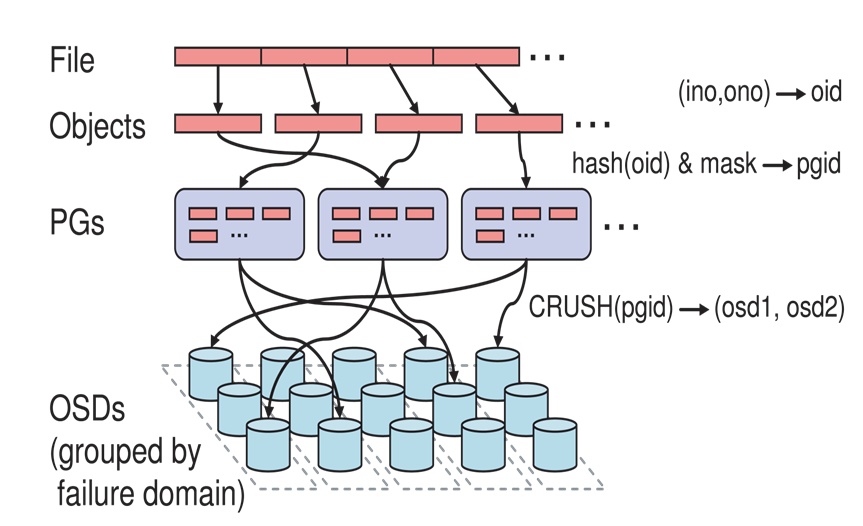
ceph中引入PG(Placement Group)的概念,这是一个逻辑上的组,通过crush算法映射到一组OSD上,每个PG里包含完整的副本关系,比如3个数据副本分布到一个PG里的3个不同的OSD上。下面引用ceph论文中的一张图就可以比较直观的理解了。将文件按照指定的对象大小分割成多个对象,每个对象根据hash映射到某个PG,然后再根据crush算法映射到后端的某几个OSD上:
2. 不同对象的并发控制
不同的对象有可能落到同一个PG里,ceph实现里,再OSD的处理线程中就会给PG加锁,一直到queue_transactions里把事务放到journal的队列里(以filestore为例)才释放PG的锁。从这里可以看出,对于同一个PG里的不同对象,是通过PG锁来进行并发的控制,好在这个过程中没有涉及到对象的IO,不会太影响效率;对于不同PG的对象,就可以直接进行并发访问。
void OSD::ShardedOpWQ::_process(uint32_t thread_index, heartbeat_handle_d *hb ) {
...
(item.first)->lock_suspend_timeout(tp_handle);
...
(item.first)->unlock();
}3. 同一个对象的并发顺序控制
从上面的介绍可以得知,同一个对象的访问也会受到PG锁的限制,但这是在OSD的处理逻辑里。对于同一个对象的访问,要考虑的情况比较复杂。从用户使用场景上来说,有两种使用方式。比如:
1) 一个client情况,客户端对同一个对象的更新处理逻辑是串行的,要等前一次写请求完成,再进行后一次的读取或者写更新;
2) 多个client对同一个对象的并发访问,这样的应用场景类似于NFS,目前的分布式系统里很少能做到,涉及到多个client同时更新带来的数据一致性问题,一般需要集群文件系统的支持;
对于多client的场景,ceph的rbd也是不能保证的,cephfs或许可以(没深入研究过,待取证)。因此,这里主要以单client访问ceph rbd块设备的场景进行阐述,看一个极端的例子:同一个client先后发送了2次对同一个对象的异步写请求。以这个例子展开进行说明。
3.1 tcp消息的顺序性保证
了解tcp的都知道,tcp使用序号来保证消息的顺序。发送方每次发送数据时,tcp就给每个数据包分配一个序列号,并且在一个特定的时间内等待接收主机对分配的这个序列号进行确认,如果发送方在一个特定时间内没有收到接收方的确认,则发送放会重传此数据包。接收方利用序号对接收的数据进行确认,以便检测对方发送的数据是否有丢失或者乱序等,接收方一旦收到已经顺序化的数据,它就将这些数据按正确的顺序重组成数据流并传递到应用层进行处理。注意: tcp的序号时用来保证同一个tcp连接上消息的顺序性。
3.2 ceph消息层的顺序性保证
ceph的消息有个seq序号,以simple消息模型为例,Pipe里有3个序号:in_seq、in_seq_acked、out_seq。
-
in_seq是对于Reader来说,已经收到的消息的序号
-
in_seq_acked表示成功处理并应答的消息序号,接收端收到发送端的消息并处理完成后将ack成功发到发送端后设置的;
-
out_seq是发送端生成的,一般新建一个连接时随机生成一个序号,然后后续的消息发送时out_seq递增赋值给消息的序号m->seq。
注: 参看Pipe::reader()与Pipe::writer()函数
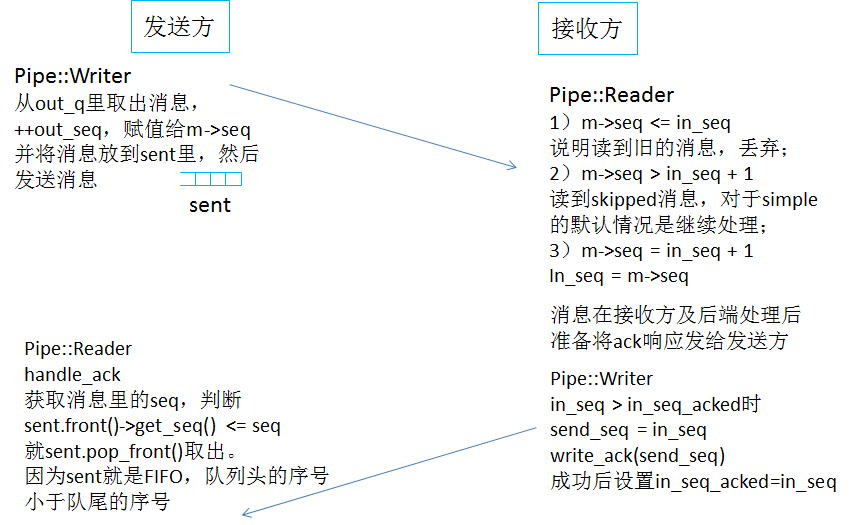
当网络异常导致tcp连接中断后,会调用Pipe::fault()进行处理,就是关闭socket,调用requeue_sent把没有收到ack的消息重新放入out_q队列头(放在头部以便于可以优先处理),而且out_seq会递减,后续会不断尝试重新建立连接。这样再重新建立连接重发的消息所带的seq还是跟之前的一样。
因为发送端连接异常调用Pipe::fault()里会关闭socket,进行tcp的连接关闭处理,在接收端继续读的时候读到0认为tcp_read失败,因此也会调用Pipe::fault()从而调用shutdown_socket去关闭socket。因此对于连接异常断开后再重新建立连接的情况,in_seq也不会接着之前的序号,仍然是取决于发送端生成的out_seq。因而可以保证消息的顺序。
3.3 pg层顺序保证及对象锁机制
从消息队列里取消息进行处理时,osd端处理op是划分为多个shard,然后每个shard可以配置多个线程,PG按照取模的方式映射到不同的shard里。另外OSD在处理PG时,从消息队列里取出的时候就对PG加了写锁的,而且是在请求下发到store后端才释放的锁,所以消息队列里过来的消息有序后,在OSD端PG这一层处理时也是有序的。
对某个对象进行写时会在对象上进行加锁操作ondisk_write_lock(),对某个对象的读请求会先在对象上进行加锁操作ondisk_read_lock()。这两个操作是互斥的,当一个对象有写操作还在进行时,尝试ondisk_read_lock()会一直等着;同样的,当一个对象正在进行读操作时,尝试ondisk_write_lock()时,也是会等。两者加锁解锁的地方如下图所示:读数据的过程中是持有锁的;写请求要等数据写到底层文件系统(文件系统缓存里)才释放锁,这样后续对这个对象的读可以直接从文件系统缓存里读到(或者数据刷到磁盘上后从磁盘上读取)。
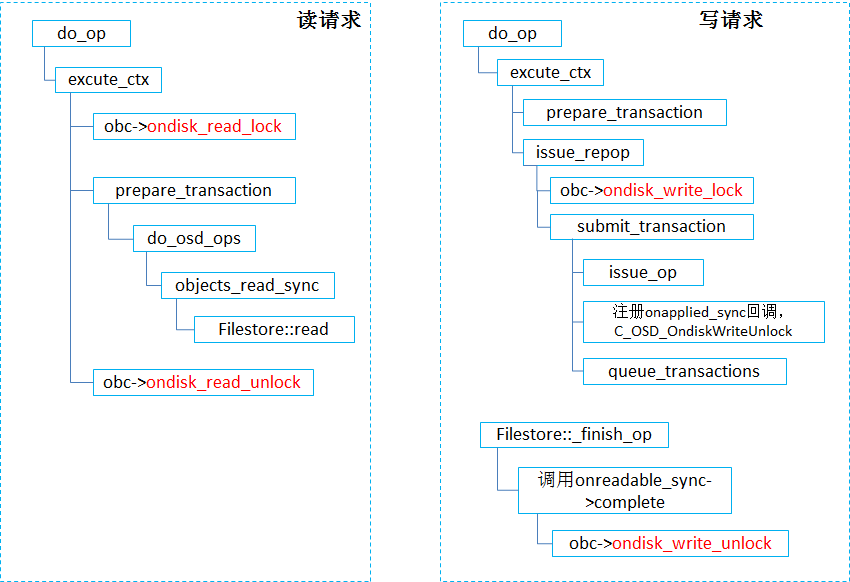
注意: 这里的两个锁操作限制的是同一个对象上的读和写的并发,对于(不同对象的)读和读、写和写的并发没有控制。对于同一个对象的两个读请求理论上来说不会出问题(实际上不会同时发生,因为先加了PG锁),可是对于同一个对象上的两个写请求会不会造成数据错乱呢?不要忘了,在进入do_op()之前就已经加了PG锁,而且是请求都下发到store层才释放的PG锁,因此同一个对象的2个写请求,是不会并发进入PG层处理的,必定是按照顺序前一个写请求经过PG层的处理后,到达store层进行处理(由另外的线程来进行),然后后一个写请求才会进入PG层处理后下发到store层。所以同一个对象上的读写请求,一定是按照顺序在PG层进行处理。那么问题来了,同一个对象的2次写请求到了store层处理的时候也是有顺序上的保证吗?
3.4 store层顺序保证
ceph的store层支持各种存储后端,以插件化的形式来管理,以filestore为例来进行说明。filestore有几种写的方式,这里以filestore journal writeahead为例。写请求到达filestore后(入口是FileStore::queue_transactions()),会生成OpSequencer(如果这个PG之前已经生成过了,就直接获取,每个PG有一个osr,类型为ObjectStore::Sequencer,osr->p就是指向OpSequencer),OpSequencer就是用来保证PG内op操作的顺序的,后面会介绍具体怎么使用。
对于封装了写请求的事务(每个op都有一个seq序号,递增的),按照顺序会先放到completions,再放到writeq里后(writeq队尾),通知write_thread去处理。在write_thread中使用aio异步将事务写到journal里,并将IO信息放到aio_queue,然后使用write_finish_cond通知write_finish_thread进行处理。在write_finish_thread里对于已经完成的IO,会根据完成的op的seq序号按序放到journal的finisher队列里(因为aio并不保证顺序,因此采用op的seq序号来保证完成后处理的顺序),如果某个op之前的op还未完成,那么这个op会等到它之前的op都完成后才一起放到finisher队列里。参看如下代码:
int FileStore::queue_transactions(Sequencer *posr, vector<Transaction>& tls,
TrackedOpRef osd_op,
ThreadPool::TPHandle *handle)
{
...
OpSequencer *osr;
assert(posr);
if (posr->p) {
osr = static_cast<OpSequencer *>(posr->p.get());
dout(5) << "queue_transactions existing " << osr << " " << *osr << dendl;
} else {
osr = new OpSequencer(next_osr_id.inc());
osr->set_cct(g_ceph_context);
osr->parent = posr;
posr->p = osr;
dout(5) << "queue_transactions new " << osr << " " << *osr << dendl;
}
...
if (journal && journal->is_writeable() && !m_filestore_journal_trailing) {
...
uint64_t op_num = submit_manager.op_submit_start();
o->op = op_num;
if (m_filestore_journal_parallel) {
dout(5) << "queue_transactions (parallel) " << o->op << " " << o->tls << dendl;
_op_journal_transactions(tbl, orig_len, o->op, ondisk, osd_op);
// queue inside submit_manager op submission lock
queue_op(osr, o);
} else if (m_filestore_journal_writeahead) {
dout(5) << "queue_transactions (writeahead) " << o->op << " " << o->tls << dendl;
osr->queue_journal(o->op);
_op_journal_transactions(tbl, orig_len, o->op,
new C_JournaledAhead(this, osr, o, ondisk),
osd_op);
} else {
assert(0);
}
submit_manager.op_submit_finish(op_num);
...
}
...
}
void FileJournal::submit_entry(uint64_t seq, bufferlist& e, uint32_t orig_len,
Context *oncommit, TrackedOpRef osd_op)
{
...
completions.push_back(
completion_item(
seq, oncommit, ceph_clock_now(g_ceph_context), osd_op));
if (writeq.empty())
writeq_cond.Signal();
writeq.push_back(write_item(seq, e, orig_len, osd_op));
}
void FileJournal::write_thread_entry()
{
...
#ifdef HAVE_LIBAIO
if (aio)
do_aio_write(bl);
else
do_write(bl);
#else
do_write(bl);
#endif
...
}在journal的finisher处理函数里,会将op按序放到OpSequencer的队列里,并且会放到FileStore::op_wq的队列中,FileStore::OpWQ线程池调用FileStore::_do_op(),先osr->apply_lock.Lock()进行加锁操作,然后会从队列中取op进行处理(调用osr->peek_queue(),并没有dequeue),然后进行写数据到Filesystem的操作完成后,在FileStore::_finish_op()里才会osr->dequeue(),并osr->apply_lock.Unlock()。即通过OpSequencer来控制同一个PG内写IO到filesystem的并发,但是对于不同PG的写IO是可以在OpWQ的线程池里并发处理的。
总的来说,FileStore里先通过op的seq来控制持久化写到journal的顺序性,然后再通过OpSequencer来保证写数据到文件系统的顺序性,并且整个处理过程中都是通过FIFO来确保出入队列的顺序。由此可见,同一个对象的2次写请求按照顺序进入到FileStore里进行处理,也是按照先后顺序处理完成的。
在BlueStore里也有OpSequencer这个机制,比如BlueStore里是通过OpSequencer来保证某个请求之前的请求还没有处理完成之前,后面的请求就不会处理。因此对于同一个对象的两个写请求会按照顺序进行处理,而且对于一个对象的读请求,如果这个对象还有未完成的写请求在处理,那么会等到写处理完成才能读取。
3.5 primary发到replica的请求顺序
有了消息层的顺序性,以及primary处理上的顺序性,再将请求发给replica的时候也是有序的(即对同一个对象的两次写),replica端收到的两次写的顺序跟primary的两次写的顺序是一样的(由同一个tcp连接上的顺序性和ceph消息层的顺序性保证),这样replica端在进行处理时,到osd以及后续store层的处理也是保序的。这样就不会出现primary跟replica上对于同一个对象的两次写会乱序导致不一致。
[参看]
