OSD启动流程
本章我们简单介绍一下OSD启动的几个主要的流程。
1. 集群信息相关初始化
在启动OSD之前,首先需要创建相应的ObjectStore对象(src/ceph_osd.cc):
ObjectStore *store = ObjectStore::create(g_ceph_context,
store_type,
g_conf->osd_data,
g_conf->osd_journal,
g_conf->osd_os_flags);对于Jewel版本,默认使用的是filestore。
之后调用OSD::peek_meta()来获取superblock相关的信息:
int OSD::peek_meta(ObjectStore *store, std::string& magic,
uuid_d& cluster_fsid, uuid_d& osd_fsid, int& whoami)
{
string val;
int r = store->read_meta("magic", &val);
if (r < 0)
return r;
magic = val;
r = store->read_meta("whoami", &val);
if (r < 0)
return r;
whoami = atoi(val.c_str());
r = store->read_meta("ceph_fsid", &val);
if (r < 0)
return r;
r = cluster_fsid.parse(val.c_str());
if (!r)
return -EINVAL;
r = store->read_meta("fsid", &val);
if (r < 0) {
osd_fsid = uuid_d();
} else {
r = osd_fsid.parse(val.c_str());
if (!r)
return -EINVAL;
}
return 0;
}我们来看一下OSD根目录下的meta文件如下:
# ls ceph_fsid current fsid keyring magic ready store_version superblock type whoami
之后会创建相应的Messenger进行通信:
Messenger *ms_public = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "client",
getpid());
Messenger *ms_cluster = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "cluster",
getpid(), CEPH_FEATURES_ALL);
Messenger *ms_hbclient = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "hbclient",
getpid());
Messenger *ms_hb_back_server = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "hb_back_server",
getpid());
Messenger *ms_hb_front_server = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "hb_front_server",
getpid());
Messenger *ms_objecter = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "ms_objecter",
getpid());之后会创建MonClient来与Monitor进行通信。Monitor是基于Paxos协议实现的一个典型的分布式系统,在其上会保存cluster_map、OSD_map、PG_map、Monitor_map以及MDS_map等相关信息。
MonClient mc(g_ceph_context);
if (mc.build_initial_monmap() < 0)
return -1;在build_initial_monmap()函数中会读取所有的monitor的地址信息。
2. OSD的启动
在src/ceph_osd.cc文件中,通过如下代码段完成OSD的启动:
osd = new OSD(g_ceph_context,
store,
whoami,
ms_cluster,
ms_public,
ms_hbclient,
ms_hb_front_server,
ms_hb_back_server,
ms_objecter,
&mc,
g_conf->osd_data,
g_conf->osd_journal);
int err = osd->pre_init();
if (err < 0) {
derr << TEXT_RED << " ** ERROR: osd pre_init failed: " << cpp_strerror(-err)
<< TEXT_NORMAL << dendl;
return 1;
}
ms_public->start();
ms_hbclient->start();
ms_hb_front_server->start();
ms_hb_back_server->start();
ms_cluster->start();
ms_objecter->start();
// start osd
err = osd->init();上面首先创建一个OSD对象,然后调用pre_init()以及init()完成OSD的初始化。
2.1 OSD::pre_init()
OSD::pre_init()函数实现如下:
int OSD::pre_init()
{
Mutex::Locker lock(osd_lock);
if (is_stopping())
return 0;
if (store->test_mount_in_use()) {
derr << "OSD::pre_init: object store '" << dev_path << "' is "
<< "currently in use. (Is ceph-osd already running?)" << dendl;
return -EBUSY;
}
cct->_conf->add_observer(this);
return 0;
}pre_init()函数实现较为简单,主要检测当前ObjectStore是否被占用,以及对conf添加observer。
2.2 OSD::init()
OSD::init()是完成OSD初始化的主函数:
int OSD::init(){
...
store->mount();
...
read_superblock();
...
// make sure snap mapper object exists
if (!store->exists(coll_t::meta(), OSD::make_snapmapper_oid())) {
dout(10) << "init creating/touching snapmapper object" << dendl;
ObjectStore::Transaction t;
t.touch(coll_t::meta(), OSD::make_snapmapper_oid());
r = store->apply_transaction(service.meta_osr.get(), std::move(t));
if (r < 0)
goto out;
}
...
osdmap = get_map(superblock.current_epoch);
...
clear_temp_objects();
...
load_pgs();
...
monc->set_want_keys(CEPH_ENTITY_TYPE_MON | CEPH_ENTITY_TYPE_OSD);
r = monc->init();
if (r < 0)
goto out;
...
service.init();
service.publish_map(osdmap);
service.publish_superblock(superblock);
...
consume_map();
peering_wq.drain();
...
// subscribe to any pg creations
monc->sub_want("osd_pg_creates", last_pg_create_epoch, 0);
...
monc->renew_subs();
start_boot();
...
}如下我们会对其中一些较为关键的步骤进行详细说明。
2.2.1 store->mount()函数
store->mount()实际调用的是FileStore::mount()函数:
int FileStore::mount(){
}mount()函数主要完成相关数据的检查,读取/var/lib/ceph/osd/ceph-0/current/commit_op_seq中相关的提交信息,以及完成相关backend线程的启动。
另外需要注意的一点是,在mount()的时候会对临时collection进行处理:
void FileStore::init_temp_collections(){
}2.2.2 read_superblock()
本函数用于读取superblock相关信息:
#define OSD_SUPERBLOCK_GOBJECT ghobject_t(hobject_t(sobject_t(object_t("osd_superblock"), 0)))
int OSD::read_superblock()
{
bufferlist bl;
int r = store->read(coll_t::meta(), OSD_SUPERBLOCK_GOBJECT, 0, 0, bl);
if (r < 0)
return r;
bufferlist::iterator p = bl.begin();
::decode(superblock, p);
dout(10) << "read_superblock " << superblock << dendl;
return 0;
}经分析其最终会读取到meta目录下的superblock文件::
# pwd /var/lib/ceph/osd/ceph-0/current/meta # ls DIR_2 DIR_5 DIR_7 DIR_8 osd\usuperblock__0_23C2FCDE__none snapmapper__0_A468EC03__none
读取出来的OSDSuperblock结构如下:
class OSDSuperblock {
public:
uuid_d cluster_fsid, osd_fsid;
int32_t whoami; // my role in this fs.
epoch_t current_epoch; // most recent epoch
epoch_t oldest_map, newest_map; // oldest/newest maps we have.
double weight;
CompatSet compat_features;
// last interval over which i mounted and was then active
epoch_t mounted; // last epoch i mounted
epoch_t clean_thru; // epoch i was active and clean thru
OSDSuperblock() :
whoami(-1),
current_epoch(0), oldest_map(0), newest_map(0), weight(0),
mounted(0), clean_thru(0) {
}
};注: 在每一次OSD map发生变动时都会对superblock进行修改,请参看OSD::handle_osd_map(),后面在适当的章节我们会仔细分析一下此函数的实现。
2.2.3 检查snap mapper对象是否存在
// make sure snap mapper object exists
if (!store->exists(coll_t::meta(), OSD::make_snapmapper_oid())) {
dout(10) << "init creating/touching snapmapper object" << dendl;
ObjectStore::Transaction t;
t.touch(coll_t::meta(), OSD::make_snapmapper_oid());
r = store->apply_transaction(service.meta_osr.get(), std::move(t));
if (r < 0)
goto out;
}这里实际是检查meta目录下的snap mapper文件是否存在:
# pwd /var/lib/ceph/osd/ceph-0/current/meta # ls DIR_2 DIR_5 DIR_7 DIR_8 osd\usuperblock__0_23C2FCDE__none snapmapper__0_A468EC03__none
2.2.4 get_map()
通过如下代码片段来获取当前的osd map信息:
// load up "current" osdmap
assert_warn(!osdmap);
if (osdmap) {
derr << "OSD::init: unable to read current osdmap" << dendl;
r = -EINVAL;
goto out;
}
osdmap = get_map(superblock.current_epoch);
check_osdmap_features(store);因为OSD的恢复严重依赖于osd map信息,因此这里要加载superblock.current_epoch时的OSD Map信息。下面简单来看一下相关实现:
// osd map cache (past osd maps)
OSDMapRef get_map(epoch_t e) {
return service.get_map(e);
}
OSDMapRef get_map(epoch_t e) {
OSDMapRef ret(try_get_map(e));
assert(ret);
return ret;
}
OSDMapRef OSDService::try_get_map(epoch_t epoch)
{
Mutex::Locker l(map_cache_lock);
OSDMapRef retval = map_cache.lookup(epoch);
if (retval) {
dout(30) << "get_map " << epoch << " -cached" << dendl;
return retval;
}
OSDMap *map = new OSDMap;
if (epoch > 0) {
dout(20) << "get_map " << epoch << " - loading and decoding " << map << dendl;
bufferlist bl;
if (!_get_map_bl(epoch, bl)) {
delete map;
return OSDMapRef();
}
map->decode(bl);
} else {
dout(20) << "get_map " << epoch << " - return initial " << map << dendl;
}
return _add_map(map);
}
bool OSDService::_get_map_bl(epoch_t e, bufferlist& bl)
{
bool found = map_bl_cache.lookup(e, &bl);
if (found)
return true;
found = store->read(coll_t::meta(),
OSD::get_osdmap_pobject_name(e), 0, 0, bl) >= 0;
if (found)
_add_map_bl(e, bl);
return found;
}
static ghobject_t get_osdmap_pobject_name(epoch_t epoch) {
char foo[20];
snprintf(foo, sizeof(foo), "osdmap.%d", epoch);
return ghobject_t(hobject_t(sobject_t(object_t(foo), 0)));
}从这里我们可以看到其实际是从map_cache中读取,如果读取不到就调用_get_map_bl()从OSD的meta目录下来获取。但是我们查看meta目录:
# pwd /var/lib/ceph/osd/ceph-0/current/meta # ls DIR_2 DIR_5 DIR_7 DIR_8 osd\usuperblock__0_23C2FCDE__none snapmapper__0_A468EC03__none # cd DIR_8 # ls DIR_0 DIR_1 DIR_2 DIR_3 DIR_4 DIR_5 DIR_6 DIR_7 DIR_8 DIR_9 DIR_A DIR_B DIR_C DIR_D DIR_E DIR_F # cd DIR_0 # ls osdmap.8595__0_0A3F2D08__none osdmap.8658__0_0A3ED408__none osdmap.8720__0_0A3E9F08__none osdmap.8793__0_0A3E4608__none osdmap.8856__0_0A3E0908__none osdmap.8919__0_0A3E3008__none osdmap.8977__0_0A3DEC08__none osdmap.9031__0_0A3D6008__none osdmap.8614__0_0A3F3708__none osdmap.8672__0_0A3EE308__none osdmap.8735__0_0A3EAA08__none osdmap.8812__0_0A3E6808__none osdmap.8870__0_0A3E0408__none osdmap.8933__0_0A3DCF08__none osdmap.8991__0_0A3DFB08__none osdmap.9046__0_0A3D7F08__none osdmap.8629__0_0A3EC208__none osdmap.8687__0_0A3EFE08__none osdmap.8764__0_0A3EBC08__none osdmap.8827__0_0A3E6708__none osdmap.8885__0_0A3E1308__none osdmap.8948__0_0A3DDA08__none osdmap.9002__0_0A3D5E08__none osdmap.9060__0_0A3D0A08__none osdmap.8643__0_0A3ED908__none osdmap.8706__0_0A3E8008__none osdmap.8779__0_0A3E4B08__none osdmap.8841__0_0A3E7208__none osdmap.8904__0_0A3E2508__none osdmap.8962__0_0A3DD108__none osdmap.9017__0_0A3D5508__none osdmap.9075__0_0A3D0108__none # cd ../DIR_2 # ls osdmap.8586__0_0A3F2A28__none osdmap.8678__0_0A3EE728__none osdmap.8755__0_0A3EA528__none osdmap.8832__0_0A3E7B28__none osdmap.8924__0_0A3E3428__none osdmap.8997__0_0A3DFF28__none osdmap.9066__0_0A3D0E28__none osdmap.8605__0_0A3F3C28__none osdmap.8692__0_0A3EF228__none osdmap.8784__0_0A3E4F28__none osdmap.8847__0_0A3E7628__none osdmap.8939__0_0A3DC328__none osdmap.9008__0_0A3D5228__none osdmap.9080__0_0A3D0528__none osdmap.8634__0_0A3EC628__none osdmap.8711__0_0A3E8428__none osdmap.8799__0_0A3E5A28__none osdmap.8861__0_0A3E0D28__none osdmap.8953__0_0A3DDE28__none osdmap.9022__0_0A3D6928__none osdmap.9095__0_0A3D1028__none osdmap.8649__0_0A3EDD28__none osdmap.8726__0_0A3E9328__none osdmap.8803__0_0A3E5128__none osdmap.8876__0_0A3E1828__none osdmap.8968__0_0A3DD528__none osdmap.9037__0_0A3D6428__none osdmap.8663__0_0A3EE828__none osdmap.8740__0_0A3EAE28__none osdmap.8818__0_0A3E6C28__none osdmap.8890__0_0A3E1728__none osdmap.8982__0_0A3DE028__none osdmap.9051__0_0A3D7328__none
从上面我们可以看到,在OSD上也保留了相应的OSD map信息。
注:对于ghobject_t对象,通过LFNIndex可以映射为多级目录。这也就是我们上面看到的meta目录下的多个DIR目录
2.2.5 clear_temp_objects()
void OSD::clear_temp_objects()
{
vector<coll_t> ls;
store->list_collections(ls);
for (vector<coll_t>::iterator p = ls.begin(); p != ls.end(); ++p) {
...
}
}上面通过list_collections()函数可以获取出如下一些文件:
# ls /var/lib/ceph/osd/ceph-0/current/ ... 23.a1_head 24.14d_TEMP 24.272_head 24.3b7_TEMP 24.d5_head 26.7f_TEMP 36.127_head 36.1c1_TEMP 36.ef_head 39.1b3_TEMP 39.8e_head 42.c_TEMP 23.a1_TEMP 24.14_head 24.272_TEMP 24.3bb_head 24.d5_TEMP 26.82_head 36.127_TEMP 36.1c2_head 36.ef_TEMP 39.1b9_head 39.8e_TEMP commit_op_seq 23.a3_head 24.14_TEMP 24.282_head 24.3bb_TEMP 24.d7_head 26.82_TEMP 36.128_head 36.1c2_TEMP 36.f1_head 39.1b9_TEMP 39.9a_head meta 23.a3_TEMP 24.163_head 24.282_TEMP 24.3bc_head 24.d7_TEMP 26.8f_head 36.128_TEMP 36.1c3_head 36.f1_TEMP 39.1c9_head 39.9a_TEMP nosnap 23.a9_head 24.163_TEMP 24.291_head 24.3bc_TEMP 24.dd_head 26.8f_TEMP 36.140_head 36.1c3_TEMP 36.fa_head 39.1c9_TEMP 39.a5_head omap 23.a9_TEMP 24.16b_head 24.291_TEMP 24.3c0_head 24.dd_TEMP 26.92_head 36.140_TEMP 36.1c8_head 36.fa_TEMP 39.1d1_head 39.a5_TEMP ...
查看FileStore::list_collections(ls)的实现:
int FileStore::list_collections(vector<coll_t>& ls)
{
return list_collections(ls, false);
}
int FileStore::list_collections(vector<coll_t>& ls, bool include_temp){
...
while ((r = ::readdir_r(dir, (struct dirent *)&buf, &de)) == 0) {
...
coll_t cid;
if (!cid.parse(de->d_name)) {
derr << "ignoging invalid collection '" << de->d_name << "'" << dendl;
continue;
}
if (!cid.is_temp() || include_temp)
ls.push_back(cid);
}
...
}
bool coll_t::parse(const std::string& s)
{
if (s == "meta") {
type = TYPE_META;
pgid = spg_t();
removal_seq = 0;
calc_str();
assert(s == _str);
return true;
}
if (s.find("_head") == s.length() - 5 &&
pgid.parse(s.substr(0, s.length() - 5))) {
type = TYPE_PG;
removal_seq = 0;
calc_str();
assert(s == _str);
return true;
}
if (s.find("_TEMP") == s.length() - 5 &&
pgid.parse(s.substr(0, s.length() - 5))) {
type = TYPE_PG_TEMP;
removal_seq = 0;
calc_str();
assert(s == _str);
return true;
}
return false;
}
bool is_temp() const {
return type == TYPE_PG_TEMP;
}从这里我们可以看到,这里的clear_temp_objects()所清理的主要是head中的临时pool中的对象,并不包括TEMP中的对象,这一点需要注意。
2.2.6 load_pgs()
本函数是一个十分关键的函数,用于从本地ObjectStore加载PG:
void OSD::load_pgs(){
...
vector<coll_t> ls;
int r = store->list_collections(ls);
if (r < 0) {
derr << "failed to list pgs: " << cpp_strerror(-r) << dendl;
}
for (vector<coll_t>::iterator it = ls.begin();it != ls.end(); ++it) {
...
}
...
}下面我们会对其进行一个较为详细的分析:
1) 获取所有PG
通过调用函数store->list_collections()来获取本OSD所管理的所有PG:
int FileStore::list_collections(vector<coll_t>& ls)
{
return list_collections(ls, false);
}此处获取的PG信息并不包括meta以及temp。
2) 遍历处理每一个PG
void OSD::load_pgs(){
...
for (vector<coll_t>::iterator it = ls.begin();it != ls.end();++it) {
spg_t pgid;
if (it->is_temp(&pgid) || (it->is_pg(&pgid) && PG::_has_removal_flag(store, pgid))) {
dout(10) << "load_pgs " << *it << " clearing temp" << dendl;
recursive_remove_collection(store, pgid, *it);
continue;
}
if (!it->is_pg(&pgid)) {
dout(10) << "load_pgs ignoring unrecognized " << *it << dendl;
continue;
}
if (pgid.preferred() >= 0) {
dout(10) << __func__ << ": skipping localized PG " << pgid << dendl;
// FIXME: delete it too, eventually
continue;
}
dout(10) << "pgid " << pgid << " coll " << coll_t(pgid) << dendl;
bufferlist bl;
epoch_t map_epoch = 0;
int r = PG::peek_map_epoch(store, pgid, &map_epoch, &bl);
if (r < 0) {
derr << __func__ << " unable to peek at " << pgid << " metadata, skipping"<< dendl;
continue;
}
PG *pg = NULL;
if (map_epoch > 0) {
OSDMapRef pgosdmap = service.try_get_map(map_epoch);
if (!pgosdmap) {
if (!osdmap->have_pg_pool(pgid.pool())) {
derr << __func__ << ": could not find map for epoch " << map_epoch
<< " on pg " << pgid << ", but the pool is not present in the "
<< "current map, so this is probably a result of bug 10617. "
<< "Skipping the pg for now, you can use ceph-objectstore-tool "
<< "to clean it up later." << dendl;
continue;
} else {
derr << __func__ << ": have pgid " << pgid << " at epoch "
<< map_epoch << ", but missing map. Crashing."
<< dendl;
assert(0 == "Missing map in load_pgs");
}
}
pg = _open_lock_pg(pgosdmap, pgid);
} else {
pg = _open_lock_pg(osdmap, pgid);
}
// there can be no waiters here, so we don't call wake_pg_waiters
pg->ch = store->open_collection(pg->coll);
// read pg state, log
pg->read_state(store, bl);
if (pg->must_upgrade()) {
if (!pg->can_upgrade()) {
derr << "PG needs upgrade, but on-disk data is too old; upgrade to"
<< " an older version first." << dendl;
assert(0 == "PG too old to upgrade");
}
if (!has_upgraded) {
derr << "PGs are upgrading" << dendl;
has_upgraded = true;
}
dout(10) << "PG " << pg->info.pgid
<< " must upgrade..." << dendl;
pg->upgrade(store);
}
service.init_splits_between(pg->info.pgid, pg->get_osdmap(), osdmap);
// generate state for PG's current mapping
int primary, up_primary;
vector<int> acting, up;
pg->get_osdmap()->pg_to_up_acting_osds(
pgid.pgid, &up, &up_primary, &acting, &primary);
pg->init_primary_up_acting(
up,
acting,
up_primary,
primary);
int role = OSDMap::calc_pg_role(whoami, pg->acting);
pg->set_role(role);
pg->reg_next_scrub();
PG::RecoveryCtx rctx(0, 0, 0, 0, 0, 0);
pg->handle_loaded(&rctx);
dout(10) << "load_pgs loaded " << *pg << " " << pg->pg_log.get_log() << dendl;
pg->unlock();
}
...
}针对每一个PG按如下方式进行处理:
-
对temp类型、非TYPE_PG类型以及preferred类型的PG不做处理;
-
读取PG的epoch信息
int PG::peek_map_epoch(ObjectStore *store,
spg_t pgid,
epoch_t *pepoch,
bufferlist *bl){
}- 获取该PG所对应epoch的OSDMap信息,并以该OSDMap在内存中创建PG对象
PG *OSD::_open_lock_pg(
OSDMapRef createmap,
spg_t pgid, bool no_lockdep_check)
{
assert(osd_lock.is_locked());
PG* pg = _make_pg(createmap, pgid);
{
RWLock::WLocker l(pg_map_lock);
pg->lock(no_lockdep_check);
pg_map[pgid] = pg;
pg->get("PGMap"); // because it's in pg_map
service.pg_add_epoch(pg->info.pgid, createmap->get_epoch());
}
return pg;
}- 打开该PG所对应的collection句柄
pg->ch = store->open_collection(pg->coll);- 读取pg state、pg log等信息
void PG::read_state(ObjectStore *store, bufferlist &bl)
{
int r = read_info(store, pg_id, coll, bl, info, past_intervals,
info_struct_v);
assert(r >= 0);
if (g_conf->osd_hack_prune_past_intervals) {
_simplify_past_intervals(past_intervals);
}
ostringstream oss;
pg_log.read_log(store,
coll,
info_struct_v < 8 ? coll_t::meta() : coll,
ghobject_t(info_struct_v < 8 ? OSD::make_pg_log_oid(pg_id) : pgmeta_oid),
info, oss, cct->_conf->osd_ignore_stale_divergent_priors);
if (oss.tellp())
osd->clog->error() << oss.rdbuf();
// log any weirdness
log_weirdness();
}这里我们直接看info_struct_v为v8版本即可。因为针对Jewel 10.2.10版本,程序在检测到PG版本小于v8版本时,会首先将低版本的PG信息读取出来,然后升级为v8版本再写入,因此这里我们直接看v8版本的pglog读取即可。
- 更新PG版本到v8版本
if (pg->must_upgrade()) {
if (!pg->can_upgrade()) {
derr << "PG needs upgrade, but on-disk data is too old; upgrade to"
<< " an older version first." << dendl;
assert(0 == "PG too old to upgrade");
}
if (!has_upgraded) {
derr << "PGs are upgrading" << dendl;
has_upgraded = true;
}
dout(10) << "PG " << pg->info.pgid << " must upgrade..." << dendl;
pg->upgrade(store);
}上面代码会自动完成从v7升级到v8版本。
- 检查PG是否需要分裂,如果需要则完成分裂操作
service.init_splits_between(pg->info.pgid, pg->get_osdmap(), osdmap);这里我们跳过,不进行分析。
- pg_to_up_acting_osds()
/**
* map a pg to its acting set as well as its up set. You must use
* the acting set for data mapping purposes, but some users will
* also find the up set useful for things like deciding what to
* set as pg_temp.
* Each of these pointers must be non-NULL.
*/
void pg_to_up_acting_osds(pg_t pg, vector<int> *up, int *up_primary,
vector<int> *acting, int *acting_primary) const {
_pg_to_up_acting_osds(pg, up, up_primary, acting, acting_primary);
}
void pg_to_up_acting_osds(pg_t pg, vector<int>& up, vector<int>& acting) const {
int up_primary, acting_primary;
pg_to_up_acting_osds(pg, &up, &up_primary, &acting, &acting_primary);
}本函数用于实现获取PG对应的acting set及up set。具体的实现细节,我们来看一下_pg_to_up_acting_osds():
void OSDMap::_pg_to_up_acting_osds(const pg_t& pg, vector<int> *up, int *up_primary,
vector<int> *acting, int *acting_primary) const
{
const pg_pool_t *pool = get_pg_pool(pg.pool());
if (!pool) {
if (up)
up->clear();
if (up_primary)
*up_primary = -1;
if (acting)
acting->clear();
if (acting_primary)
*acting_primary = -1;
return;
}
vector<int> raw;
vector<int> _up;
vector<int> _acting;
int _up_primary;
int _acting_primary;
ps_t pps;
_pg_to_osds(*pool, pg, &raw, &_up_primary, &pps);
_raw_to_up_osds(*pool, raw, &_up, &_up_primary);
_apply_primary_affinity(pps, *pool, &_up, &_up_primary);
_get_temp_osds(*pool, pg, &_acting, &_acting_primary);
if (_acting.empty()) {
_acting = _up;
if (_acting_primary == -1) {
_acting_primary = _up_primary;
}
}
if (up)
up->swap(_up);
if (up_primary)
*up_primary = _up_primary;
if (acting)
acting->swap(_acting);
if (acting_primary)
*acting_primary = _acting_primary;
}其中函数_pg_to_osds()仅仅是利用crush算法计算出的一个PG所映射的OSD,我们称之为raw set。
# ceph osd --help | grep lost
osd lost <int[0-]> {--yes-i-really-mean- mark osd as permanently lost. THIS
it} DESTROYS DATA IF NO MORE REPLICAS
EXIST, BE CAREFUL
在计算raw set时我们要去掉CEPH_OSD_EXISTS为0的OSD。一般情况下并不会出现某一个OSD不存在的情况,但是上面为我们提供了一种将某个OSD标记为永久丢失的方法。
接着要获取出该PG对应的up set,需要继续计算:_raw_to_up_osds()用于剔除掉raw set中处于down状态的OSD;_apply_primary_affinity()用于选择亲和性较高的OSD作为up primary OSD。我们这里在实际环境中没有设置primary affinity,因此这里我们可以忽略亲和性计算这一步。
# ceph osd --help | grep primary-affinity
osd primary-affinity <osdname (id|osd. adjust osd primary-affinity from 0.0 <=
id)> <float[0.0-1.0]> <weight> <= 1.0之后,再调用_get_temp_osds()来获取出acting set,我们来看相应的实现:
void OSDMap::_get_temp_osds(const pg_pool_t& pool, pg_t pg,
vector<int> *temp_pg, int *temp_primary) const
{
pg = pool.raw_pg_to_pg(pg);
map<pg_t,vector<int32_t> >::const_iterator p = pg_temp->find(pg);
temp_pg->clear();
if (p != pg_temp->end()) {
for (unsigned i=0; i<p->second.size(); i++) {
if (!exists(p->second[i]) || is_down(p->second[i])) {
if (pool.can_shift_osds()) {
continue;
} else {
temp_pg->push_back(CRUSH_ITEM_NONE);
}
} else {
temp_pg->push_back(p->second[i]);
}
}
}
map<pg_t,int32_t>::const_iterator pp = primary_temp->find(pg);
*temp_primary = -1;
if (pp != primary_temp->end()) {
*temp_primary = pp->second;
} else if (!temp_pg->empty()) { // apply pg_temp's primary
for (unsigned i = 0; i < temp_pg->size(); ++i) {
if ((*temp_pg)[i] != CRUSH_ITEM_NONE) {
*temp_primary = (*temp_pg)[i];
break;
}
}
}
}可以看到,在有pg temp的情况下,acting set与up set可能会不一样。这里有一点我们需要注意的到pg_temp和primary_temp都是OSDMap中的一个成员变量,因此可以推断这些temp信息肯定是经过Monitor协调出来的(因为OSDMap这些信息是符合Paxos严格一致性的)。
-
init_primary_up_acting(): 在上面我们已经求出了up set以及acting set,这里我们需要将其转换成pg_shard_t格式来进行保存,本质上没有特别的变化。
-
calc_pg_role()计算当前PG的角色
int OSDMap::calc_pg_rank(int osd, const vector<int>& acting, int nrep)
{
if (!nrep)
nrep = acting.size();
for (int i=0; i<nrep; i++)
if (acting[i] == osd)
return i;
return -1;
}
int OSDMap::calc_pg_role(int osd, const vector<int>& acting, int nrep)
{
if (!nrep)
nrep = acting.size();
return calc_pg_rank(osd, acting, nrep);
}这里如果role的值为-1,代表的是replica。
-
reg_next_scrub(): PG的scrub操作是由replica来注册的,对于primary PG直接返回;
-
创建PG::RecoveryCtx,并向PG所对应的状态机投递第一个事件:Load
void PG::handle_loaded(RecoveryCtx *rctx)
{
dout(10) << "handle_loaded" << dendl;
Load evt;
recovery_state.handle_event(evt, rctx);
}对于recovery_state对象,其所对应的状态机machine的初始状态为Initial。因此这里当Initial收到Load事件时,其会直接进入Reset状态:
boost::statechart::result PG::RecoveryState::Initial::react(const Load& l)
{
PG *pg = context< RecoveryMachine >().pg;
// do we tell someone we're here?
pg->send_notify = (!pg->is_primary());
return transit< Reset >();
}上面我们还注意到对于replica PG,还会将send_notify置为true。
-
清理该PG老的infos信息: 这里主要是针对进行过升级的PG,我们要清理原来老版的infos信息
-
build_past_intervals_parallel(): 本函数的实现很复杂,其主要目的就是从pglog中获取epoch信息,然后再用这些epoch获取到相应的OSDMap,从而计算出后续该PG进行恢复时所需要的相关信息(这里主要是pg->info.history.same_interval_since信息)。我们后面会对恢复相关步骤再进行详细讲解
2.2.7 MonClient初始化
因为OSD后续的运行都需要读写最新的Map信息,因此这里需要调用init来先初始化MonClient:
int OSD::init()
{
...
monc->set_want_keys(CEPH_ENTITY_TYPE_MON | CEPH_ENTITY_TYPE_OSD);
r = monc->init();
if (r < 0)
goto out;
...
}这里我们看到monc会订阅Monitor的OSDMap、MonMap相关信息。
2.2.8 将当前的OSDMap等信息保存到OSDService中
int OSD::init(){
...
service.init();
service.publish_map(osdmap);
service.publish_superblock(superblock);
service.max_oldest_map = superblock.oldest_map;
...
}后续OSDMap等的更新操作都是由OSDService来负责,因此这里需要进行service的初始化。因为后续很多操作都与OSDMap的变化相关,其实OSDService的实现相对还是很复杂的。OSDService也是作为驱动OSD后续运行的一个动力存在。详细的分析,我们会在后面再介绍。
2.2.9 consume_map()
int OSD::init(){
...
dout(10) << "ensuring pgs have consumed prior maps" << dendl;
consume_map();
peering_wq.drain();
...
}这里consume_map()也是作为OSD启动时的一个十分重要的函数,下面我们来看看其具体实现:
- 扫描pg_map,找出其中的待移除pg以及待分裂pg,并进行处理
void OSD::consume_map()
{
...
int num_pg_primary = 0, num_pg_replica = 0, num_pg_stray = 0;
list<PGRef> to_remove;
// scan pg's
{
RWLock::RLocker l(pg_map_lock);
for (ceph::unordered_map<spg_t,PG*>::iterator it = pg_map.begin(); it != pg_map.end(); ++it) {
PG *pg = it->second;
pg->lock();
if (pg->is_primary())
num_pg_primary++;
else if (pg->is_replica())
num_pg_replica++;
else
num_pg_stray++;
if (!osdmap->have_pg_pool(pg->info.pgid.pool())) {
//pool is deleted!
to_remove.push_back(PGRef(pg));
} else {
service.init_splits_between(it->first, service.get_osdmap(), osdmap);
}
pg->unlock();
}
}
for (list<PGRef>::iterator i = to_remove.begin(); i != to_remove.end(); to_remove.erase(i++)) {
RWLock::WLocker locker(pg_map_lock);
(*i)->lock();
_remove_pg(&**i);
(*i)->unlock();
}
to_remove.clear();
...
}这里首先遍历pg_map列表,会有三种类型的PG:primay、replica、stray(注:此种情况一般出现在PG发生重新映射的情况,比如OSD处于out之后,经过一段时间该OSD又重新回到集群),之后找出待移除的PG以及待分裂的PG。
对于待分裂的PG,调用函数init_splits_between()函数进行处理;对于待移除的PG,调用_remove_pg()来删除该PG。
- 等待service的OSDMap更新到当前指定epoch的OSDMap
void OSD::consume_map()
{
service.pre_publish_map(osdmap);
service.await_reserved_maps();
service.publish_map(osdmap);
}将当前osdmap设置为service的预发布(pre-publish)版本,接着调用await_reserved_maps()等待OSD中各元素都同步到该osdmap版本,之后再将该osdmap正式发布(注: 在初始启动时,service初始的osdmap版本与这里pre_publish_map()的版本应该是一样的,因此这里await_reserved_maps()应该马上就会返回)。
这里进行osdmap版本的同步是十分重要的,可以确保该OSD上的PG都达到一个指定的状态才开始进行工作,从而保证系统步调的一致性。
- 处理因等待osdmap同步而阻塞的sessions
void OSD::consume_map()
{
dispatch_sessions_waiting_on_map();
// remove any PGs which we no longer host from the session waiting_for_pg lists
set<spg_t> pgs_to_check;
get_pgs_with_waiting_sessions(&pgs_to_check);
for (set<spg_t>::iterator p = pgs_to_check.begin();p != pgs_to_check.end();++p) {
if (!(osdmap->is_acting_osd_shard(p->pgid, whoami, p->shard))) {
set<Session*> concerned_sessions;
get_sessions_possibly_interested_in_pg(*p, &concerned_sessions);
for (set<Session*>::iterator i = concerned_sessions.begin(); i != concerned_sessions.end(); ++i) {
{
Mutex::Locker l((*i)->session_dispatch_lock);
session_notify_pg_cleared(*i, osdmap, *p);
}
(*i)->put();
}
}
}
}由于上面await_reserved_maps()已经同步了osdmap,因此这里先调用dispatch_sessions_waiting_on_map()来解除被阻塞的sessions。由于前面session被阻塞,因此我们可以通过get_pgs_with_waiting_sessions()来获取阻塞在哪些PG上,在这里session阻塞被解除后,我们也可以将这些PG移出session的waiting_for_pg队列。
- 发送NullEvt,触发PG的peering操作
void OSD::consume_map()
{
...
// scan pg's
{
RWLock::RLocker l(pg_map_lock);
for (ceph::unordered_map<spg_t,PG*>::iterator it = pg_map.begin(); it != pg_map.end(); ++it) {
PG *pg = it->second;
pg->lock();
pg->queue_null(osdmap->get_epoch(), osdmap->get_epoch());
pg->unlock();
}
logger->set(l_osd_pg, pg_map.size());
}
...
}在OSD初始启动过程中,这是一个十分重要的步骤,可以推动PG从Reset状态进入Started状态。下面我们来看queue_null()函数的实现:
void OSDService::queue_for_peering(PG *pg)
{
peering_wq.queue(pg);
}
void PG::queue_peering_event(CephPeeringEvtRef evt)
{
if (old_peering_evt(evt))
return;
peering_queue.push_back(evt);
osd->queue_for_peering(this);
}
void PG::queue_null(epoch_t msg_epoch,
epoch_t query_epoch)
{
dout(10) << "null" << dendl;
queue_peering_event(
CephPeeringEvtRef(std::make_shared<CephPeeringEvt>(msg_epoch, query_epoch,
NullEvt())));
}下面我们给出一个OSD::peering_wq的整体架构图:

上面首先将一个NullEvt放入进去pg对应的peering_queue,之后再将该PG放入OSDSerivce中的peering_wq(也即OSD中的peering_wq)。peering_wq所绑定的线程池中的线程就会取出peering_wq中的PG来进行处理,调用OSD::process_peering_events()。下面我们简单分析一下该函数:
void OSD::process_peering_events(
const list<PG*> &pgs,
ThreadPool::TPHandle &handle
)
{
...
for (list<PG*>::const_iterator i = pgs.begin(); i != pgs.end(); ++i) {
...
if (!advance_pg(curmap->get_epoch(), pg, handle, &rctx, &split_pgs)) {
// we need to requeue the PG explicitly since we didn't actually
// handle an event
peering_wq.queue(pg);
} else {
assert(!pg->peering_queue.empty());
PG::CephPeeringEvtRef evt = pg->peering_queue.front();
pg->peering_queue.pop_front();
pg->handle_peering_event(evt, &rctx);
}
...
}
...
}通过上面的代码,我们看到对PG peering的处理主要是通过advance_pg()和handle_peering_event()来进行的。那么这两种不同的处理方式是如何选择的呢?其实这是跟PG当前所处的osdmap的版本相关的: 这里假设pg当前所对应的osdmap的epoch为pg_osdmap_epoch, OSD当前所对应的osdmap的epoch为osd_osdmap_epoch。这里就存在两种不同的情况: 如果pg_osdmap_epoch小于osd_osdmap_epoch,那么该PG就可以直接通过获取本地OSD的osdmap信息,完成前期的osdmap的追赶;如果pg_osdmap_epoch等于osd_osdmap_epoch,说明pg已经和osd同步,此时就可以开始调用handle_peering_event()来处理投递进来的其他事件了。
注:在OSD启动时,第一次调用consume_map()时的状态机状态为Reset,此时回调process_peering_events()函数,从而引发调用advance_pg()。Reset阶段可以接受QueryState、AdvMap、ActMap、FlushedEvt、IntervalFlush等事件,我们在PG状态机转换图中可能有些没有画出,在阅读时请注意对比来看。
2.2.10 drain工作队列
int OSD::init()
{
...
peering_wq.drain();
...
}由于上面consume_map()是异步调用,通过事件的方式触发完成PG的初始化,因此这里要使用peering_wq.drain()来等待相关的事件完成。此时,其实就已经进入peering流程,可以接收peering事件了。
2.2.11 订阅PG创建事件
int OSD::init()
{
...
// subscribe to any pg creations
monc->sub_want("osd_pg_creates", last_pg_create_epoch, 0);
...
}通过上面peering_wq.drain()已经基本完成了OSD的初始化,可以处理peering事件了。因此这里订阅PG创建消息,用于处理后续的PG创建请求。
2.2.12 重新更新订阅
int OSD::init()
{
...
monc->renew_subs();
...
}这里重新更新相关的订阅情况。暂不太清楚为何要更新。
2.2.13 完成OSD初始化的最后阶段
int OSD::init()
{
...
start_boot();
...
}
void OSD::start_boot()
{
if (!_is_healthy()) {
// if we are not healthy, do not mark ourselves up (yet)
dout(1) << "not healthy; waiting to boot" << dendl;
if (!is_waiting_for_healthy())
start_waiting_for_healthy();
// send pings sooner rather than later
heartbeat_kick();
return;
}
dout(1) << "We are healthy, booting" << dendl;
set_state(STATE_PREBOOT);
dout(10) << "start_boot - have maps " << superblock.oldest_map << ".." << superblock.newest_map << dendl;
C_OSD_GetVersion *c = new C_OSD_GetVersion(this);
monc->get_version("osdmap", &c->newest, &c->oldest, c);
}这里如果启动时异常,等待恢复到健康状态;如果启动正常,那么通过monc来获取最新的osdmap信息。
3. OSD启动时PG osdmap的追赶
这里我们接着上一节,在OSD::advance_pg()中会实现PG osdmap的追赶,我们来看相应的实现:
bool OSD::advance_pg(
epoch_t osd_epoch, PG *pg,
ThreadPool::TPHandle &handle,
PG::RecoveryCtx *rctx,
set<boost::intrusive_ptr<PG> > *new_pgs)
{
assert(pg->is_locked());
epoch_t next_epoch = pg->get_osdmap()->get_epoch() + 1;
OSDMapRef lastmap = pg->get_osdmap();
if (lastmap->get_epoch() == osd_epoch)
return true;
assert(lastmap->get_epoch() < osd_epoch);
epoch_t min_epoch = service.get_min_pg_epoch();
epoch_t max;
if (min_epoch) {
max = min_epoch + g_conf->osd_map_max_advance;
} else {
max = next_epoch + g_conf->osd_map_max_advance;
}
for (;
next_epoch <= osd_epoch && next_epoch <= max;
++next_epoch) {
OSDMapRef nextmap = service.try_get_map(next_epoch);
if (!nextmap) {
dout(20) << __func__ << " missing map " << next_epoch << dendl;
// make sure max is bumped up so that we can get past any
// gap in maps
max = MAX(max, next_epoch + g_conf->osd_map_max_advance);
continue;
}
vector<int> newup, newacting;
int up_primary, acting_primary;
nextmap->pg_to_up_acting_osds(
pg->info.pgid.pgid,
&newup, &up_primary,
&newacting, &acting_primary);
pg->handle_advance_map(
nextmap, lastmap, newup, up_primary,
newacting, acting_primary, rctx);
// Check for split!
set<spg_t> children;
spg_t parent(pg->info.pgid);
if (parent.is_split(
lastmap->get_pg_num(pg->pool.id),
nextmap->get_pg_num(pg->pool.id),
&children)) {
service.mark_split_in_progress(pg->info.pgid, children);
split_pgs(
pg, children, new_pgs, lastmap, nextmap,
rctx);
}
lastmap = nextmap;
handle.reset_tp_timeout();
}
service.pg_update_epoch(pg->info.pgid, lastmap->get_epoch());
pg->handle_activate_map(rctx);
if (next_epoch <= osd_epoch) {
dout(10) << __func__ << " advanced to max " << max
<< " past min epoch " << min_epoch
<< " ... will requeue " << *pg << dendl;
return false;
}
return true;
}
// src/include/types.h
typedef __u32 epoch_t;在上面for循环中实现pg osdmap的追赶,如下图所示:
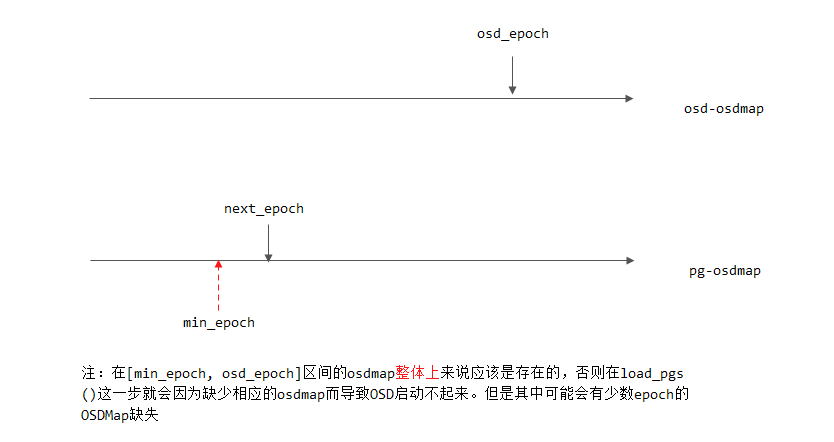
在这一追赶过程中,PG根据相应epoch的osdmap,计算出该epoch下pg的up set以及acting set,然后调用PG::handle_advance_map()来进行处理。
void PG::handle_advance_map(
OSDMapRef osdmap, OSDMapRef lastmap,
vector<int>& newup, int up_primary,
vector<int>& newacting, int acting_primary,
RecoveryCtx *rctx)
{
assert(lastmap->get_epoch() == osdmap_ref->get_epoch());
assert(lastmap == osdmap_ref);
dout(10) << "handle_advance_map "
<< newup << "/" << newacting
<< " -- " << up_primary << "/" << acting_primary
<< dendl;
update_osdmap_ref(osdmap);
pool.update(osdmap);
if (cct->_conf->osd_debug_verify_cached_snaps) {
interval_set<snapid_t> actual_removed_snaps;
const pg_pool_t *pi = osdmap->get_pg_pool(info.pgid.pool());
assert(pi);
pi->build_removed_snaps(actual_removed_snaps);
if (!(actual_removed_snaps == pool.cached_removed_snaps)) {
derr << __func__ << ": mismatch between the actual removed snaps "
<< actual_removed_snaps << " and pool.cached_removed_snaps "
<< " pool.cached_removed_snaps " << pool.cached_removed_snaps
<< dendl;
}
assert(actual_removed_snaps == pool.cached_removed_snaps);
}
AdvMap evt(
osdmap, lastmap, newup, up_primary,
newacting, acting_primary);
recovery_state.handle_event(evt, rctx);
if (pool.info.last_change == osdmap_ref->get_epoch())
on_pool_change();
}
boost::statechart::result PG::RecoveryState::Reset::react(const AdvMap& advmap)
{
PG *pg = context< RecoveryMachine >().pg;
dout(10) << "Reset advmap" << dendl;
// make sure we have past_intervals filled in. hopefully this will happen
// _before_ we are active.
pg->generate_past_intervals();
pg->check_full_transition(advmap.lastmap, advmap.osdmap);
if (pg->should_restart_peering(
advmap.up_primary,
advmap.acting_primary,
advmap.newup,
advmap.newacting,
advmap.lastmap,
advmap.osdmap)) {
dout(10) << "should restart peering, calling start_peering_interval again"
<< dendl;
pg->start_peering_interval(
advmap.lastmap,
advmap.newup, advmap.up_primary,
advmap.newacting, advmap.acting_primary,
context< RecoveryMachine >().get_cur_transaction());
}
pg->remove_down_peer_info(advmap.osdmap);
return discard_event();
}在完成PG osdmap的追赶后,OSD::advance_pg()函数会返回true,之后处理该PG的第一个事件是Reset NullEvt,再接着的事件可能就是Reset AdvMap,之后可能就是Reset ActMap从而进入Started状态。
关于在PG::RecoveryState::react()中对AdvMap事件的处理,其中计算past_interval的过程,我们后面会再进行详细的介绍。
4. OSD中几个线程参数的设置
通过如下命令查看OSD中其中一些有关线程数的设置:
# ceph daemon osd.0 config show | grep threads
"xio_portal_threads": "2",
"async_compressor_threads": "2",
"ms_async_op_threads": "3",
"ms_async_max_op_threads": "5",
"osd_op_threads": "2",
"osd_disk_threads": "1",
"osd_recovery_threads": "1",
"osd_op_num_threads_per_shard": "2",
"bluestore_wal_threads": "4",
"filestore_op_threads": "5",
"filestore_ondisk_finisher_threads": "1",
"filestore_apply_finisher_threads": "1",
"rbd_op_threads": "1",
"rgw_enable_quota_threads": "true",
"rgw_enable_gc_threads": "true",
"rgw_num_async_rados_threads": "32",
"internal_safe_to_start_threads": "true",下面我们对其中一些配置进行简要说明:
-
osd_op_threads: 处理peering等请求时的线程数,用于回调OSD::process_peering_events()
-
filestore_op_threads: 用于filestore层进行IO操作的线程数;
-
osd_disk_threads: 处理snap trim,replica trim及scrub等的线程数
[参看]
