ceph数据recovery配置策略(转)
本文转载自ceph数据recovery配置策略,在此做个记录,防止原文丢失,并便于自己后续阅读。
1. 数据recovery流量控制
Ceph在扩容或缩容期间会有数据rebalance。如何控制在rebalance时,尽量降低对client IO的影响?
本质上,用户数据写入ceph时,会被切分成大小相等的object,这些object由PG承载,分布到不同的OSD上(每个OSD一般会对应一块硬盘)。数据的迁移会以PG为单位进行,所以当PG发生变化时,就会有数据rebalance。
后端的数据均衡IO会对client的IO造成影响从而影响到集群的业务IO,所以我们需要对数据均衡IO进行控制,主要是业务优先和恢复优先。
那么在什么时候PG会变化呢?从用户使用角度讲一般有如下几种场景:
1) osd暂时下线,然后又上线 2) osd硬件故障下线,更换硬盘重新上线
无论哪种情况,osd上线后通常会发现,自己承载的pg有数据落后了,需要进入恢复模式,从其它osd上获取新的数据达到同步。这个过程就是recovery。
recovery分为两种:
log-based recovery: 是说osd故障时间不长,需要恢复的数据可以通过pg log回放找回来。 backfill recovery: 是说无法通过pg log回放找全数据,只能通过全量回填(backfill)拷贝。
注:操作前记得查看下默认参数值,操作完后记得恢复到原先参数
- 业务优先
# ceph tell osd.* injectargs '--osd-max-backfills 1 --osd-recovery-max-active 1 --osd-recovery-max-single-start 1'
# ceph tell osd.* injectargs '--osd-recovery-sleep 1'- 恢复优先
# ceph tell osd.* injectargs '--osd-max-backfills 5 --osd-recovery-max-active 5 --osd-recovery-max-single-start 5'
# ceph tell osd.* injectargs '--osd-recovery-sleep 0'- 还原配置
# ceph tell osd.* injectargs '--osd-max-backfills 1 --osd-recovery-max-active 3 --osd-recovery-max-single-start 1'
# ceph tell osd.* injectargs '--osd-recovery-sleep 0'1.1 完全保证client带宽场景
在极端情况下,如果网络带宽及磁盘性能有限,这个时候为了不影响用户体验,不得不在业务繁重时段关闭数据重建及迁移的I/O,来完全保证client的带宽,在业务空闲时段再打开数据重建及迁移,具体操作如下:
1) 在业务繁忙时,完全关闭数据重建及迁移
# ceph osd set norebalance # ceph osd set norecover # ceph osd set nobackfill
2) 在业务空闲时,打开数据重建及迁移
# ceph osd unset norebalance # ceph osd unset norecover # ceph osd unset nobackfill
以上前两种方案操作配置均为立即生效,且重启服务或者重启节点后失效,如果想长期有效,可以在进行以上操作立即生效后,修改所有ceph集群节点的配置文件。
注:查看现有recovery配置信息,这里的133为具体osd的id号
# ceph --admin-daemon /var/run/ceph/ceph-osd.133.asok config show | grep -E "osd_max_backfills|osd_recovery_max_active|osd_recovery_max_single_start|osd_recovery_sleep"
"osd_max_backfills": "1",
"osd_recovery_max_active": "1",
"osd_recovery_max_single_start": "1",
"osd_recovery_sleep": "0.000000",
"osd_recovery_sleep_hdd": "0.100000",
"osd_recovery_sleep_hybrid": "0.025000",
"osd_recovery_sleep_ssd": "0.000000",
下面我们对上面参数简单说明:
-
osd_max_backfills : 一个osd上最多能有多少个pg同时做backfill。其中osd出去的最大backfill数量为osd_max_backfills ,osd进来的最大backfill数量也是osd_max_backfills ,所以每个osd最大的backfill数量为
osd_max_backfills * 2; -
osd_recovery_sleep: 出队列后先Sleep一段时间,拉长两个Recovery的时间间隔;
-
osd_recovery_max_active: 每个OSD上同时进行的所有PG的恢复操作(active recovery)的最大数量;
-
osd_recovery_max_single_start: OSD在某个时刻会为一个PG启动恢复操作数;
上面两个参数,网上解释大多有误导,结合代码以及官方材料分析为:
a.假设我们配置osd_recovery_max_single_start为1,osd_recovery_max_active为3,那么,这意味着OSD在某个时刻会为一个PG最多启动1个恢复操作,而且最多可以有3个恢复操作同时处于活动状态。
b.假设我们配置osd_recovery_max_single_start为2,osd_recovery_max_active为3,那么,这意味着OSD在某个时刻会为一个PG最多启动2个恢复操作,而且最多可以有3个恢复操作同时处于活动状态。例如第一个pg启动2个恢复操作,第二个pg启动1个恢复操作,第三个pg等待前两个pg 恢复操作完进行新的恢复。
1.2 recovery相关参数配置
- 默认配置:
osd_max_backfills:默认值10. 一个osd上承载了多个pg。可能很多pg都需要做第二种recovery,即backfill。 设定这个参数来指明在一个osd上最多能有多少个pg同时做backfill。
osd_recovery_max_active:默认值15. 一个osd上可以承载多个pg, 可能好几个pg都需要recovery,这个值限定该osd最多同时有多少pg做recovery。
osd_recovery_max_single_start:默认值5. 这个值限定了每个pg可以启动recovery操作的最大数。
osd_recovery_max_chunk: 默认值8388608. 设置恢复数据块的大小,以防网络阻塞
osd_recovery_op_priority: 默认值10. osd修复操作的优先级, 可小于该值
osd_recovery_sleep: 默认值0. revocery的间隔- 推荐配置
"osd_max_backfills": "1",
"osd_recovery_sleep": "0",
"osd_recovery_max_active": "3",
"osd_recovery_max_single_start": "1",如下是不同配置下对业务的影响参考:
注:级别一栏,5%是业务优先,对业务影响最小;100%恢复优先,对业务影响最大;其他介于二者之间
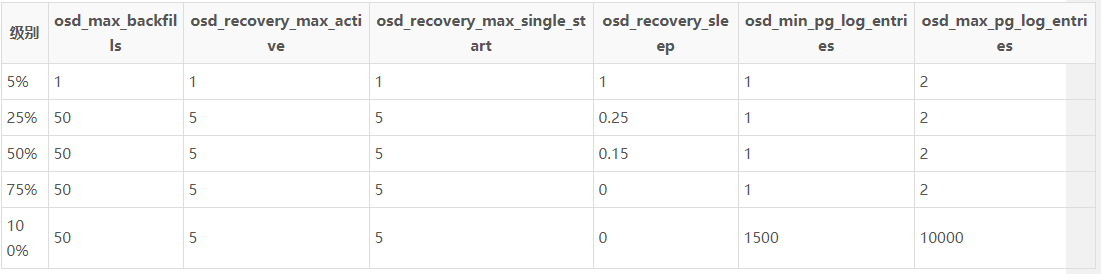
osd_min_pg_log_entries 正常情况下PGLog的记录的条数
osd_max_pg_log_entries 异常情况下pglog记录的条数,达到该限制会进行trim操作
[参看]
