字符编码
本文我们简单讲述一下unicode编码(Unicode-32与UTF-8)
1. Unicode

2. UTF-8
UTF-8是对Unicode字符的一个变长编码。utf-8是由Ken Thompson和Rob Pike发明,同时这两位也是Golang的创立者,当前已经称为Unicode的标准(Unicode standard)。utf-8使用1~4个字节来编码每一个字符,其中ASCII字符使用1个字节,对于其他大部分常用的字符使用2个或3个字节,极少部分采用4个字节来编码。第一个字节高比特位为0,用于表示7位的ASCII码;第一个字节的高位为10表示字符占用2个字节:
0xxxxxx runes 0−127 (ASCII) 110xxxxx 10xxxxxx 128−2047 (values <128 unused) 1110xxxx 10xxxxxx 10xxxxxx 2048−65535 (values <2048 unused) 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 65536−0x10ffff (other values unused)
此外,还可以参考如下一段对utf8的说明:
UTF-8 represents each Unicode character using a variable number of bytes. For instance, it represents A with one byte, 65; it represents the Hebrew character Aleph, which has code 1488 in Unicode, with the two-byte sequence 215–144. UTF-8 represents all characters in the ASCII range as in ASCII, that is, with a single byte smaller than 128. It represents all other characters using sequences of bytes where the first byte is in the range [194,244] and the continuation bytes are in the range [128,191]. More specifically, the range of the starting bytes for two-byte sequences is [194,223]; for three-byte sequences, the range is [224,239]; and for four-byte sequences, it is [240,244]. None of those ranges overlap. This property ensures that the code sequence of any character never appears as part of the code sequence of any other character. In particular, a byte smaller than 128 never appears in a multibyte sequence; it always represents its corresponding ASCII character.
例如,对于国,其Unicode-16值为\u56fd,那么编码为utf-8后,其对应的字节为:
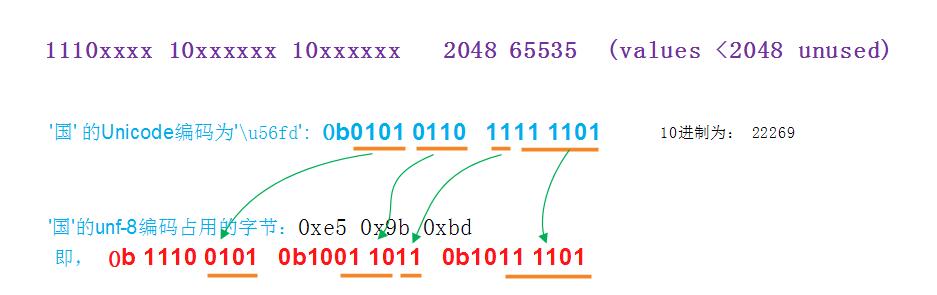
说明: unicode-16表示形式为\uhhhh,unicode-32表示形式为\Uhhhhhhhh(注意这里为大写的U) 对于如下均表示同一字符串: "世界" "\xe4\xb8\x96\xe7\x95\x8c" "\u4e16\u754c" "\U00004e16\U0000754c"
参看:
