redis分布式锁
本文主要讲述以下redis分布式锁相关内容,以进一步加深对相关知识的理解。
1. Redis分布式锁
在很多校项目中,我们直接使用Redis的set key方式来实现分布式锁,这种实现方式简单且大部分情况下效果良好,在特定情形下也是满足要求的。
然而,实际情况往往更加复杂,如何确保临界资源的串行执行,如何及时释放,这些都是需要额外考虑的。
先来看一下一个完备的分布式锁需要支持哪些特性:
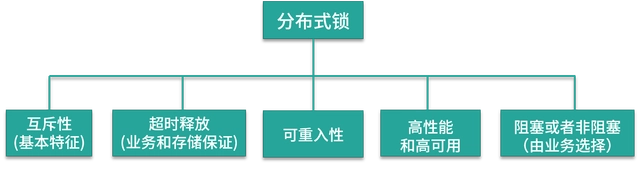
一般而言,在生产环境中可用的分布式锁需要满足以下几个要点:
-
互斥性:分布式锁必须具备互斥性,即同一时刻只能有一个线程持有锁并执行临界操作,防止数据竞争和冲突。
-
超时释放:分布式锁需要具备超时释放功能,即在一定时间内未能成功获取锁时,自动释放锁,避免不必要的线程等待和资源浪费。
-
可重入性:在分布式环境下,同一个节点上的同一个线程如果已经持有锁,则再次请求锁时应该能够成功获取,实现可重入性。
-
高性能和高可用性:分布式锁应具备高性能和高可用性,加锁和解锁的开销要尽可能小,同时要保证锁的可靠性,防止分布式锁失效。
-
支持阻塞和非阻塞性:分布式锁应该支持阻塞和非阻塞性,以满足不同场景下的需求。例如,可以在获取锁时使用阻塞操作或轮询来等待,或者通过非阻塞操作立即返回获取锁的结果。
综合上述要点,一个可用的分布式锁要同时满足以上条件,以确保系统的正确性、高性能和可扩展性。
实现一个相对完备的分布式锁,并不是锁住资源就可以了,还需要满足一些额外的特性,否则会在业务开发中出现各种各样的问题。
1.1 使用 setnx 实现分布式锁
Redis支持setnx指令,用于在key不存在的情况下将其设置为指定的value值。基于setnx指令,可以简单实现分布式锁的方案。获取锁的方法很简单,只需以锁作为key,设置一个随机值作为value。若setnx返回1,则表示当前进程成功获取锁;若返回0,则说明其他进程已获取锁,当前进程无法进入临界区。若需要阻塞当前进程,则可通过循环不断尝试setnx操作。
if(setnx(key,value)==1){
try{
//业务处理
}finally{
//释放锁
del(key)
}
}使用Java中的try-catch-finally来释放锁是一种常见的做法,可以确保在业务进程出现异常时仍能够正常释放锁。然而,与之前提到的分布式锁特性相比较,这种方式存在一个明显的问题:不支持超时释放锁。
如果某个进程在加锁后发生宕机或异常退出,无法正常执行锁的释放操作,导致其他进程无法获取该锁,从而产生死锁现象。这会对系统的可用性和响应性造成严重影响。
为了解决这个问题,通常需要引入超时释放机制。可以使用带有超时时间的锁,例如设置一个合理的过期时间,在加锁时为锁设置一个自动过期时间。当加锁的进程在超时时间内未能完成操作或异常退出时,锁会自动过期释放,从而避免死锁情况的发生。
1.2 使用 setnx 和 expire 实现
在分布式锁的实现中,依赖业务线程进行锁的释放可能存在宕机导致的死锁问题。为了解决这个问题,可以利用Redis的特性,在设置锁时设置一个过期时间,利用Redis的缓存失效策略实现锁的超时释放。
具体实现方式是,在使用setnx指令获取锁之后,再使用expire指令给锁设置一个过期时间。通过设置过期时间,当其他进程在获取锁时发现该锁已经超时过期,即使之前持有锁的进程宕机或异常退出,也能确保其他进程能够获取到该锁。
通过利用Redis的缓存失效策略,当锁的过期时间到达时,Redis会自动删除该锁,从而实现了锁的超时释放。这样可以避免死锁情况的发生,并保证分布式锁的正确性和高可用性。
if(setnx(key,value)==1){
expire(key,expireTime)
try{
//业务处理
}finally{
//释放锁
del(key)
}
}通过设置过期时间,避免了占锁到释放锁的过程发生异常而导致锁无法释放的问题,但是在 Redis 中,setnx 和 expire 这两条命令不具备原子性。如果一个线程在执行完 setnx 之后突然崩溃,导致锁没有设置过期时间,那么这个锁就会一直存在,无法被其他线程获取。
1.3 使用 set 扩展命令实现
在 Redis 2.8 版本中,扩展了 set 命令,支持 set 和 expire 指令组合的原子操作,解决了加锁过程中失败的问题。 set 扩展参数的语法如下:
redis> SET key value expireTime nx使用setnx指令结合expire指令可以解决锁超时释放的问题,但在实际业务中仍存在一些潜在问题。
一种可能性是,在加锁和释放锁之间的业务逻辑执行非常耗时,超过了锁的超时限制。这种情况下,Redis会自动删除锁,导致其他线程能够获取到该锁,从而产生对加锁资源的并发操作。
看一下下面这种情况:
1) 客户端 A 获取锁的时候设置了 key 的过期时间为 2 秒,客户端 A 在获取到锁之后,业务逻辑方法执行了 3 秒;
2) 客户端 A 获取的锁被 Redis 过期机制自动释放,客户端 B 请求锁成功,出现并发执行;
3) 客户端 A 执行完业务逻辑后,释放锁,删除对应的 key;
4) 对应锁已经被客户端 B 获取到了,客户端A释放的锁实际是客户端B持有的锁。
在第一个线程的逻辑还没执行完的时候,第二个线程也成功获得了锁,加锁的代码或者资源并没有得到严格的串行操作,同时由于叠加了删除和释放锁操作,导致了加锁的混乱。
怎么解决这个问题?首先,基于 Redis 的分布式锁一般是用于耗时比较短的瞬时性任务,业务上超时的可能性较小;其次,在获取锁时,可以设置 value 为一个随机数,在释放锁时进行读取和对比,确保释放的是当前线程持有的锁,通常是通过 Redis 结合 Lua 脚本的方案来实现;最后,需要添加完备的日志,记录上下游数据链路,当出现超时的时候,则需要检查对应的问题数据,进行人工修复。
1.4 分布式锁高可用
在上面分布式锁的实现方案中,是针对单节点 Redis 的,在实际生产环境中,为了保证高可用,避免单点故障,一般会使用 Redis 集群。 在集群环境下,分布式锁会遇到一些问题,特别是在Redis主从复制的情况下可能会出现锁的安全性问题。
主从复制是异步的,在故障转移(Failover)过程中,可能导致数据同步的延迟。这样,在发生节点故障时,如果主节点已经获取到锁但数据还未同步到从节点,那么在故障转移后的从节点可能会认为锁没有被持有,从而另一个客户端可以获取到相同的锁。
这种情况下,就会发生多个客户端同时获取到锁的情况,导致竞争和不一致的结果。
我们模拟下这个场景,按照下面的顺序执行:
1) 客户端 A 从 Master 节点获取锁;
2) Master 节点宕机,主从复制过程中,对应锁的 key 还没有同步到 Slave 节点上;
3) Slave 升级为 Master 节点,于是集群丢失了锁数据;
4) 其他客户端请求新的 Master 节点,获取到了对应同一个资源的锁;
5) 出现多个客户端同时持有同一个资源的锁,不满足锁的互斥性。
可以看到,在单实例场景中和集群环境中实现分布式锁是不同的,关于集群下如何实现分布式锁,Redis 的作者 Antirez(Salvatore Sanfilippo)提出了 Redlock 算法。
2. Redlock算法
2.1 安全和liveness保证
RedLock的设计目标仅针对如下3个属性,从我们的视角来看,这也是有效的使用分布式锁所应满足的最低要求:
-
Safety属性:互斥。在任何时刻,只有一个客户端能获取到锁
-
Liveness属性A: 不会发生死锁。即使在先前已经获取到锁的客户端崩溃或者发生了网络分区,都要要保证最终都要能成功的获取到锁
-
Liveness属性B: 容错性。只要超过半数的Redis节点起来并运行正常,客户端就能够成功的获取并释放锁
2.2 为什么基于故障转移(failover)的实现还不够(Not Enough)?
要理解我们需要在哪些方面进行改进,我们首先来看一下目前大部分的library是如何基于Redis实现分布式锁的。
使用Redis来对一个资源进行上锁,最简单的方式就是创建一个key,并在创建的时候使用Redis的Expire特性为key指定一个ttl值,这样使得在最坏的情况下能够成功的释放锁。当客户端需要释放资源的时候,删除key即可。
从表面上看,这可以良好的进行工作,但这存在一个问题:系统架构中存在单点故障。假如Redis Master崩溃之后会发生什么情形呢?我们假设该master有一个replica,那么当其出现故障的时候,原先的replica成为新的master。然而这并不是一种可行的方式,因为Redis的副本复制是异步的,这就可能会导致在同一时刻两个不同的节点均能抢到锁,从而破坏了锁的互斥性。
该模型存在如下竞态条件:
1) ClientA在master上获得锁
2) master在将key复制到replica之前崩溃
3) replica成为新的master
4) ClientB获得了相同资源的锁。这样互斥锁的安全性保障就被破坏了。
2.3 RedLock算法
RedLock算法需要有N个Redis Master,这些节点之间是相互独立的,并不存在复制关系或其他的相互协调关系。在我们如下的例子中,我们假设N为5,为了保证各自独立,分别将这些节点部署在5台主机上。
为了获取分布式锁,客户端节点做如下操作:
1) 获取当前时间(单位: ms)
2) 按顺序从N个实例中获取Redis锁,在获取锁时使用相同的key和相同的random value。在本步骤中,当设置每一个实例的锁时,客户端都会使用一个很短的超时时间(ps: 相对锁本身的TTL而言)。例如,假如锁的自动失效时间是10s,这设置锁的timeout可以为5~50ms,这可以防止由于Redis节点故障导致客户端获取锁时被卡住: 假如一个节点不可用,我们需要尽快的尝试下一个节点。
3) 客户端计算获取锁时所耗费的时间(当前时间减去第1步中所获取的时间)。当且仅当获取锁花费的时间小于锁的TTL值时,我们认为锁获取成功。、
ps: 上面计算获取锁花费的时间,前提要求是过半数的Redis节点成功获取到锁
4) 假如锁获取成功,则锁的真实有效时间为tv=t0-t1,其中t0为初始的TTL时间,t1为获取锁的耗时
5) 假如客户端获取锁失败(比如未能从过半的节点上成功获取锁,或者tv小于0),那么客户端尝试从所有节点上解锁(包括那些其认为加锁失败的节点)
3. 总结
分布式系统设计是实现复杂性和收益的平衡,考虑到集群环境下的一致性问题,同时要避免过度的设计。在实际业务场景中,我们一般是使用基于单点的 Redis 实现分布式锁就可以了,当出现数据不一致的时候,再通过人工手段去回补。
[参看]
