MySQL复制原理详解(转)
MySQL作为一个开源的数据库,有着广泛的应用。本文主要讲述了mysql复制的原理,以及异步复制、同步复制和并行复制。
1. MySQL复制的原理
MySQL有两种复制原理:基于行的复制和基于语句的复制。最早出现的是基于语句的复制,而基于行的复制方式在5.1版本中才被引入。这两种方式都是通过在主库上记录二进制日志(binlog),在备库上重放日志的方式来实现异步的数据复制。这意味着在同一时间点备库上的数据可能和主库不一致,并且无法保证主库备库之间的延迟。
1.1 基于语句的复制
基于语句的复制模式下,主库会记录那些造成数据更改的查询,当备库读取并重放这些事件时,实际上只把主库上执行过的SQL再执行一遍。
1)优点
最明显的好处是实现相当简单。理论上讲,简单地记录和执行这些语句,能够让备库保持同步。另外的好处是binlog日志里的事件更加紧凑,所以相对而言,基于语句的模式不会使用太多带宽。一条更新好几兆数据的语句在二进制日志里可能只占用几十字节。
2)缺点
有些数据更新语句,可能依赖其他因素。例如,同一条SQL在主库和备库上执行的时间可能稍微或很不同,因此在传输的binlog日志中,除了查询语句,还包括一些元数据信息,如当前的时间戳。即便如此,还存在着一些无法被正确复制的SQL。例如,使用CURRENT_USER()函数语句。 存储过程和触发器在使用基于语句的复制模式时也可能存在问题。另外一个问题是更新必须是串行的,这需要更多的锁,并且不是所有的存储引擎都支持这种复制模式。
1.2 基于行的复制
MySQL 5.1开始支持基于行的复制,这种方式将实际数据记录在二进制日志中,跟其他数据库的实现比较像。
1) 优点
最大的好处是可以正确的复制每一行,一些语句可以被更加有效地复制。由于无需重放更新主库数据的查询,使用基于行的复制模式能够更加高效地复制数据。重放一些查询的代价会很高。例如,下面有一个查询将数据从一个大表中汇总到小表:
mysql> INSERT INTO summary_table(col1,col2,sum_col3)
->SELECT col1,col2,sum(col3) from enormous_table GROUP BY col1,col2;2) 缺点
但是另外一方面,下面这条语句使用基于语句的复制方式代价会小很多:
mysql> UPDATE enormous_table SET col1 =0 ;由于这条语句做了全表更新,使用基于行的复制开销会大很多,因为每一行的数据都会被记录到二进制日志中,这使得二进制日志事件非常庞大。另外由于语句并没有在日志里记录,因此无法判断执行了哪些SQL,除了需要知道行的变化外,这在很多情况下很重要。执行基于行的过程像一个黑盒子,你无法知道服务器正在做什么。
由于没有哪一种模式对所有情况都是完善的,MySQL能够在这两种复制模式间动态切换。默认情况下使用的是基于语句的复制方式,但是如果发现语句无法被正确地复制,就切换成基于行的复制模式。还可以根据需要来设置会话级别的变量binlog_format,控制二进制日志格式。
2.异步复制过程
总体来说,复制有3个步骤:
1) 主服务器把数据更改记录到二进制日志中
2) 从服务器把主服务器的二进制日志拷贝到自己的中继日志中;
3) 从服务器重放中继日志中的事件,把更改应用到自己的数据上;
这只是一个概述,每一个步骤都很复杂。下图更清晰地描述了复制地过程:
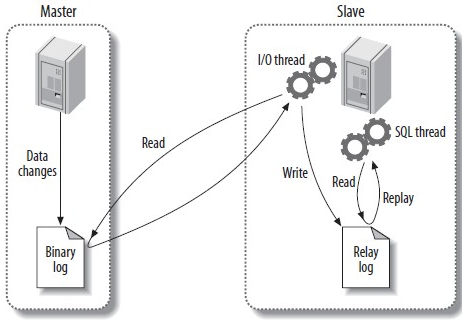
第一步:在主服务器上记录二进制日志。在每个更新数据的事务完成之前,主服务器都会将数据更改记录到二进制日志中。即使事务在执行期间是交错的,MySQL也会串行地将事务写入到二进制日志中。在把事件写入二进制日志之后,主服务器告诉存储引擎提交事务;
第二步:从服务器把主服务器的二进制日志拷贝到自己地硬盘上,进入所谓的“中继日志”中。首先,它启动一个工作线程,叫IO线程,这个IO线程开启一个普通的客户端连接,然后启动一个特殊的二进制日志转储进程(它没有响应的SQL命令)。这个转储进程从主服务器的二进制日志中读取数据,它不会对事件进行轮询。如果其跟上了主服务器,就会进入休眠状态并等待有新的事件发生时主服务器发出的信号。IO线程把数据写入从服务器的中继日志中。
第三步:SQL线程读取中继日志,并且重放其中的事件,然后更新从服务器的数据。由于这个线程能跟上IO线程,中继日志通常在操作系统的缓存中,所以中继日志的开销很低。SQL线程执行事件也可以被写入从服务器自己的二进制日志中,它对于有些场景很实用。
3. 半同步复制
一般情况下,异步复制就已经足够应付了,但由于是异步复制,备库极有可能落后于主库,特别是极端情况下,我们无法保证主备数据是严格一致的。比如,当用户发起commit命令时,master并不关心slave的执行状态,执行成功后,立即返回给用户。试想下,若一个事务提交后,master成功返回给用户后crash,这个事务的binlog还没来的及传递到slave,那么slave相对于master而言就少了一个事务,此时主备就不一致了。对于要求强一致的业务是不可接受的,半同步复制就是为了解决数据一致性而产生的。
为什么叫半同步复制?先说说同步复制,所谓同步复制就是一个事务在master和slave都执行后,才返回给用户执行成功。这里核心是说master和slave要么都执行,要么都不执行,涉及到2PC(2 Phase Commit)。而MySQL只实现了本地redo log和binlog的2PC,但并没有实现Master和Slave的2PC,所以不是严格意义上的同步复制。而MySQL半同步复制不要求slave执行,而仅仅是接收到日志后,就通知master可以返回了。这里关键点是slave接收日志后是否执行,若执行后才通知master则是同步复制;若仅仅是接收日志成功,则是半同步复制。对于MySQL而言,我们谈到的日志都是binlog,对于其他的关系型数据库可能是redo log或其他日志。
半同步复制如何实现? MySQL半同步复制的实现是建立在MySQL异步复制的基础上的,其关键点是master对于事务提交过程特殊处理。MySQL支持两种略有不同的半同步复制策略:AFTER_SYNC和AFTER_COMMIT(受 rpl_semi_sync_master_wait_point控制)。这两种策略的主要区别在于是否在存储引擎提交后等待slave的ACK。
开启半同步复制时,master在返回之前会等待slave的响应或超时。当slave超时时,半同步复制退化成异步复制。这也是MySQL半同步复制存在的一个问题。本文不讨论slave超时的情形(不讨论异步复制)。
3.1 AFTER_COMMIT模式
MySQL 5.5和5.6的半同步复制只支持AFTER_COMMIT,其基本流程如下:
-
Prepare the transaction in the storage engine(s).
-
Write the transaction to the binlog, flush the binlog to disk
-
Commit the transaction to the storage engines(s)
-
Wait for at least one slave to acknowledge the reception for the binlog events for the transaction.
如下图所示,Start和End分别表示用户发起commit命令和master返回给用户的时间点,中间部分就是整个commit过程master和slave坐的事情:
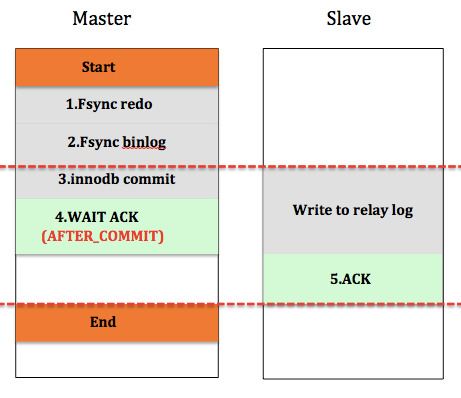
master提交时,会首先将该事务的redo log刷入磁盘,然后将事务的binlog刷入磁盘(这里其实还涉及到两阶段提交的问题,暂不展开讲),然后进入innodb commit流程,这个步骤主要是释放锁,标记事务为提交状态(其他用户可以看到该事务的更新),这个过程完成后,等待slave发送的ACK消息,等到slave的响应后,master才成功返回给用户。看到图中红色虚线部分,这段是master和slave的同步逻辑,是master-slave一致性的保证。
半同步复制是否能保证不丢数据?我们通过几种场景来简单分析下:
1) 场景1
假设master第1、2步执行成功后,binlog还没来得及传递给slave,此时master挂了,slave作为新的master提供服务,那么备库比主库少一个事务(因为主库的redo log和binlog 已经落盘),但是不影响用户,对于用户而言,这个事务没有成功返回,那么提交与否,用户都可以接受,用户一定会进行异常捕获而重试。
2)场景2
假设第3步innodb commit执行成功后,binlog还没来得及传递给slave,此时master挂了,此时与第一种情况一样,备库比主库少一个事务,但是其他用户在3执行完后,可以看到该事务的更新,而切换到备库后,却发现再次读这个更新又没了,这个就发生了“幻读”,如果其他事务依赖于这个更新,则会对业务逻辑产生影响。当然这仅仅是极端情况。
3) 场景3
客户端事务在存储引擎层提交后,在得到从库确认的过程中,主库宕机了。此时,客户端会收到事务提交失败的信息,客户端会重新提交该事务到新的主上,当宕机的主库重新启动后,以从库的身份重新加入到该主从结构中,会发现,该事务在从库中被提交了两次,一次是之前作为主的时候,一次是被新主同步过来的。
4) 场景4
客户端事务在存储引擎层提交后,在得到从库确认的过程中,主库宕机了,但是从库实际上已经收到并应用了该事务,此种情况客户端仍然会收到事务提交失败的信息,重新提交该事务到新的主上。
针对上面的场景2,AFTER_SYNC模式可以解决这一问题。
3.2 AFTER_SYNC模式
AFTER_SYNC模式是MySQL 5.7才支持的半同步复制方式,也是MySQL 5.7默认的半同步复制方式。
注: MySQL5.7.3开始支持配置半同步复制等待Slave应答的个数:rpl_semi_sync_master_wait_slave_count
其基本流程如下:
-
Prepare the transaction in the storage engine(s)
-
Write the transaction to the binlog, flush the binlog to disk
-
Wait for at least one slave to acknowledge the reception for the binlog events for the transaction.
-
Commit the transaction to the storage engine(s)
如下图所示:
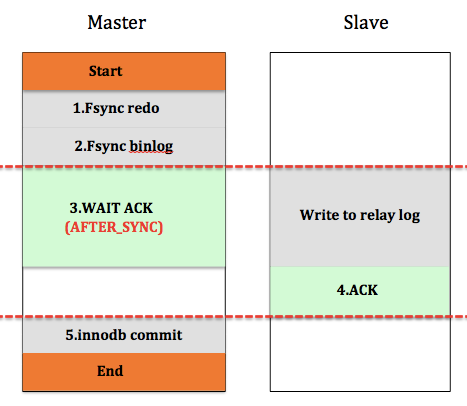
与AFTER_COMMIT相比,master在AFTER_SYNC模式下,fsync binlog后,就开始等待slave同步。那么在进行第5步innodb commit后,即其他事务能看到该事务的更新时,slave肯定已经成功接收到binlog,因此即使发生切换,slave也拥有与master同样的数据,不会发生幻读现象。但是对于AFTER_COMMIT中描述的第一种情况,结果是一样的。
3.2.1 异常情形
下面我们来分析一下AFTER_SYNC模式下的异常情形:
1) 异常情形1: master宕机后,主备切换
a) master执行事务T,在将事务T的binlog刷到硬盘之前,master发生宕机。slave升级为master。master重启后,crash recovery会对事务T进行回滚,此时主备数据一致。
b) master执行事务T,在将事务T的binlog刷到硬盘之后,收到ACK之前,master发生宕机(存在pendinglog)。slave升级为master。此时又可能有如下两种子情形:
b1) slave还没收到事务T的binlog,master重启后,crash recovery会直接提交pendinglog,主备数据不一致; b2) slave已经接收到事务T的binlog,主备数据一致;
2) 异常情形2:master宕机后,不切换主机
我们只需要考虑异常情形1中的b1)。master重启后,直接提交pendinglog,此时,主备数据不一致:
a) slave连上master,通过异步复制的方式获得事务的binlog,从而达到主备数据一致;
b) slave还没来得及复制事务T的binlog,如果master又发生宕机,磁盘损坏。主备数据不一致,事务T的数据丢失。
3.2.2 异常情形处理
从上面异常情况的简单分析我们得知,半同步需要处理master宕机后重启存在pendinglog(slave没有应答)的特殊情况。
1) 针对master宕机后,不进行主备切换的情形
在crash recovery之后,master等到slave的连接和复制,直到至少有一个slave复制了所有已提交的事务的binlog。(SHOW MASTER STATUS on master and SELECT master_pos_wait() on slave
2) 针对master宕机后,进行主备切换的情形
旧master重启后,在crash recovery时,对pendinglog进行回滚。(人工截断master的binlog未复制的部分?)
3.2.3 思考
为什么master重启之后,crash recovery的过程中,是直接commit pendinglog,而不是重试请求slave的应答呢?
我们知道MySQL的异步复制和半同步复制都是由slave触发的,slave主动去连接master同步binlog。若没有发生主备切换,机器重启后无法知道哪台机器是slave;若发生了主备切换,它已经不是master了,则不会在再有slave连上来,此时如果继续等待,则无法正常运行。
3.3 总结
MySQL半同步复制存在以下问题:
-
当Slave超时时,会退化成异步复制。
-
当Master宕机时,数据一致性无法保证,需要人工处理。
-
复制是串行的。
正因为MySQL在主备数据一致性存在着这些问题,影响了互联网业务7*24的高可用服务,因此各大公司纷纷祭出自己的“补丁”:腾讯的TDSQL、微信的PhxSQL、阿里的AliSQL、网易的InnoSQL。
MySQL官方已经在MySQL5.7推出新的复制模式——MySQL Group Replication。
4. 并行复制
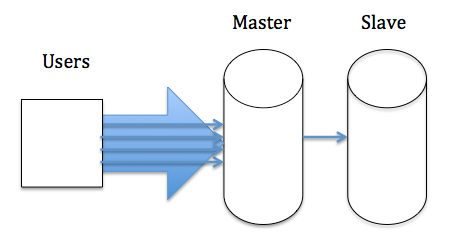
半同步复制解决了master-slave的强一致问题,那么性能问题呢?从本文的第一张图可以看到参与复制的主要有两个线程:IO线程和SQL线程,分别用于拉取和回放binlog。对于slave而言,所有拉取和解析binlog的动作都是串行的,相对于master并发处理用户请求,在高负载下,若master产生binlog的速度超过slave消费binlog的速度,就会导致slave出现延迟。如下图所示,我们可以看到users和master中间的管道远远大于master和slave之间的管道:
那么如何并行化,是并行IO线程,还是并行SQL线程?其实两方面都可以并行,但是并行SQL线程的收益更大,因为SQL线程做的事情更多(解析、执行)。并行IO线程,可以将从master拉取和写relay log分为两个线程;并行SQL线程则可以根据需要做到库级并行、表级并行、事务级并行。库级并行在MySQL官方版本5.6已经实现。如下图所示,并行复制框架实际包含了一个协调线程和若干个工作线程,协调线程负责分发和解决冲突,工作线程只负责执行。图中DB1、DB2和DB3的事务就可以并发执行,提高了复制的性能。有时候库级并发可能不够,需要做表级并发,或更细粒度的事务级并发。
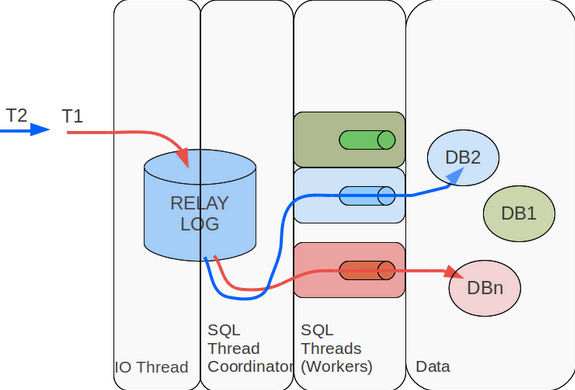
并行复制如何解决冲突?并发的世界是美好的,但不能乱并发,否则数据就乱了。master上面通过锁机制来保证并发的事务有序进行,那么并行复制呢?slave必须保证回放的顺序与master上事务执行顺序一致,因此只要做到顺序读取binlog,将不冲突的事务并发执行即可。对于库级并发而言,协调线程要保证执行同一个库的事务放在一个工作线程串行执行;对于表级并发而言,协调线程要保证同一个表的事务串行执行;对于事务级而言,则是保证操作同一行的事务串行执行。
是否粒度越细,性能越好?这个并不是一定的。相对于串行复制而言,并行复制多了一个协调线程。协调线程一个重要作用是解决冲突,粒度越细的并发,可能会有更多的冲突,最终可能也是串行执行的,但消耗了大量的冲突检测代价。
[参看]:
