Raft协议原理讲解(转)
大名鼎鼎的Paxos算法可能不少人都听说过,几乎垄断了一致性算法领域,在Raft协议诞生之前,Paxos几乎成了一致性协议的代名词。但是对于大多数人来说,Paxos算法太难以理解了,而且难以实现。因此斯坦福大学的两位教授Diego Ongaro和John Ousterhout决定设计一种更容易理解的一致性算法,最终在论文”In search of an Understandable Consensus Algorithm”中提出了Raft算法!论文原文地址:https://raft.github.io/raft.pdf
本文将尽量以简单的描述,来解开篇论文的神秘面纱。
1. 复制状态机(Replication state machine)
Raft协议可以使得一个集群的服务器组成复制状态机,在详细了解Raft算法之前,我们先来了解一下什么是复制状态机。一个分布式的复制状态机系统由多个复制单元组成,每个复制单元均是一个状态机,它的状态保存在一组状态变量中,状态机的变量只能通过外部命令来改变。简单理解的话,可以想象成是一组服务器,每个服务器是一个状态机,服务器的运行状态只能通过一行行的命令来改变。每一个状态机存储一个包含一系列指令的日志,严格按照顺序逐条执行日志中的指令,如果所有的状态机都能按照相同的日志执行指令,那么它们最终将达到相同的状态。因此,在复制状态机模型下,只要保证了操作日志的一致性,我们就能保证该分布式系统状态的一致性。
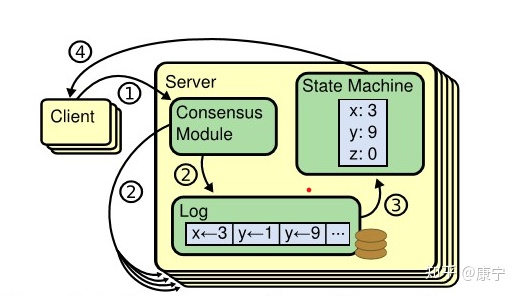
在上图中,服务器中的一致性模块(Consensus Modle)接受来自客户端的指令,并写入到自己的日志中,然后通过一致性模块和其他服务器交互,确保每一条日志都能以相同顺序写入到其他服务器的日志中,即便服务器宕机了一段时间。一旦日志命令都被正确的复制,每一台服务器就会顺序的处理命令,并向客户端返回结果。
为了让一致性协议变得简单可理解,Raft协议主要使用了两种策略。一是将复杂问题进行分解,在Raft协议中,一致性问题被分解为:leader election、log replication、safety三个简单问题;二是减少状态空间中的状态数目。下面我们详细看一下Raft协议是怎样设计的。
2. Raft一致性算法
在Raft体系中,有一个强leader,由它全权负责接收客户端的请求命令,并将命令作为日志条目复制给其他服务器,在确认安全的时候,将日志命令提交执行。当leader故障时,会选举产生一个新的leader。在强leader的帮助下,Raft将一致性问题分解为了三个子问题:
-
leader选举:当已有的leader故障时必须选出一个新的leader。
-
日志复制:leader接受来自客户端的命令,记录为日志,并复制给集群中的其他服务器,并强制其他节点的日志与leader保持一致。
-
安全safety措施:通过一些措施确保系统的安全性,如确保所有状态机按照相同顺序执行相同命令的措施。
1) 基本概念
一个Raft集群拥有多个服务器,典型值是5,这样可以容忍两台服务器出现故障。服务器可能会处于如下三种角色:leader、candidate、follower,正常运行的情况下,会有一个leader,其他全为follower,follower只会响应leader和candidate的请求,而客户端的请求则全部由leader处理,即使有客户端请求了一个follower也会将请求重定向到leader。candidate代表候选人,出现在选举leader阶段,选举成功后candidate将会成为新的leader。可能出现的状态转换关系如下图:
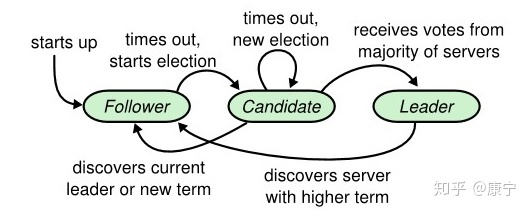
从状态转换关系图中可以看出,集群刚启动时,所有节点都是follower,之后在time out信号的驱使下,follower会转变成candidate去拉取选票,获得大多数选票后就会成为leader,这时候如果其他候选人发现了新的leader已经诞生,就会自动转变为follower;而如果另一个time out信号发出时,还没有选举出leader,将会重新开始一次新的选举。可见,time out信号是促使角色转换得关键因素,类似于操作系统中得中断信号。
在Raft协议中,将时间分成了一些任意长度的时间片,称为term,term使用连续递增的编号的进行识别,如下图所示:
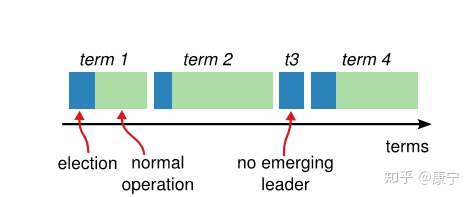
每一个term都从新的选举开始,candidate们会努力争取成为leader。一旦获胜,它就会在剩余的term时间内保持leader状态,在某些情况下(如term3)选票可能被多个candidate瓜分,形不成多数派,因此term可能直至结束都没有leader,下一个term很快就会到来重新发起选举。
term也起到了系统中逻辑时钟的作用,每一个server都存储了当前term编号,在server之间进行交流的时候就会带有该编号,如果一个server的编号小于另一个的,那么它会将自己的编号更新为较大的那一个;如果leader或者candidate发现自己的编号不是最新的了,就会自动转变为follower;如果接收到的请求的term编号小于自己的当前term将会拒绝执行。
server之间的交流是通过RPC进行的。只需要实现两种RPC就能构建一个基本的Raft集群:
-
RequestVote RPC:它由选举过程中的candidate发起,用于拉取选票
-
AppendEntries RPC:它由leader发起,用于复制日志或者发送心跳信号。
它们的定义如下图所示:

2) leader选举过程
Raft通过心跳机制发起leader选举。节点都是从follower状态开始的,如果收到了来自leader或candidate的RPC,那它就保持follower状态,避免争抢成为candidate。Leader会发送空的AppendEntries RPC作为心跳信号来确立自己的地位,如果follower一段时间(election timeout)没有收到心跳,它就会认为leader已经挂了,发起新的一轮选举。
选举发起后,一个follower会增加自己的当前term编号并转变为candidate。它会首先投自己一票,然后向其他所有节点并行发起RequestVote RPC,之后candidate状态将可能发生如下三种变化:
-
赢得选举,成为leader: 如果它在一个term内收到了大多数的选票,将会在接下的剩余term时间内称为leader,然后就可以通过发送心跳确立自己的地位。(每一个server在一个term内只能投一张选票,并且按照先到先得的原则投出)
-
其他server成为leader:在等待投票时,可能会收到其他server发出AppendEntries RPC心跳信号,说明其他leader已经产生了。这时通过比较自己的term编号和RPC过来的term编号,如果比对方大,说明leader的term过期了,就会拒绝该RPC,并继续保持候选人身份; 如果对方编号不比自己小,则承认对方的地位,转为follower.
-
选票被瓜分,选举失败: 如果没有candidate获取大多数选票, 则没有leader产生, candidate们等待超时后发起另一轮选举. 为了防止下一次选票还被瓜分,必须采取一些额外的措施, raft采用随机election timeout的机制防止选票被持续瓜分。通过将timeout随机设为一段区间上的某个值, 因此很大概率会有某个candidate率先超时然后赢得大部分选票.
3) 日志复制过程
一旦leader被选举成功,就可以对客户端提供服务了。客户端提交每一条命令都会被按顺序记录到leader的日志中,每一条命令都包含term编号和顺序索引,然后向其他节点并行发送AppendEntries RPC用以复制命令(如果命令丢失会不断重发),当复制成功也就是大多数节点成功复制后,leader就会提交命令,即执行该命令并且将执行结果返回客户端,raft保证已经提交的命令最终也会被其他节点成功执行。leader会保存有当前已经提交的最高日志编号。顺序性确保了相同日志索引处的命令是相同的,而且之前的命令也是相同的。当发送AppendEntries RPC时,会包含leader上一条刚处理过的命令,接收节点如果发现上一条命令不匹配,就会拒绝执行。
在这个过程中可能会出现一种特殊故障:如果leader崩溃了,它所记录的日志没有完全被复制,会造成日志不一致的情况,follower相比于当前的leader可能会丢失几条日志,也可能会额外多出几条日志,这种情况可能会持续几个term。如下图所示:
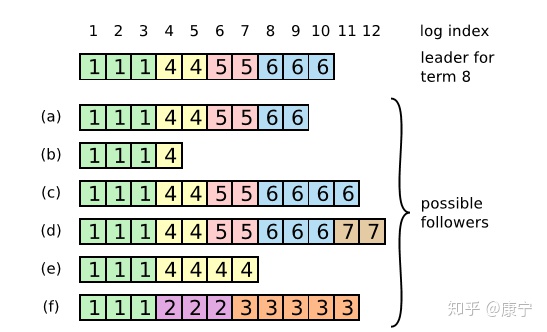
在上图中,框内的数字是term编号,a、b丢失了一些命令,c、d多出来了一些命令,e、f既有丢失也有增多,这些情况都有可能发生。比如f可能发生在这样的情况下:f节点在term2时是leader,在此期间写入了几条命令,然后在提交之前崩溃了,在之后的term3中它很快重启并再次成为leader,又写入了几条日志,在提交之前又崩溃了,等他苏醒过来时新的leader来了,就形成了上图情形。在Raft中,leader通过强制follower复制自己的日志来解决上述日志不一致的情形,那么冲突的日志将会被重写。为了让日志一致,先找到最新的一致的那条日志(如f中索引为3的日志条目),然后把follower之后的日志全部删除,leader再把自己在那之后的日志一股脑推送给follower,这样就实现了一致。而寻找该条日志,可以通过AppendEntries RPC,该RPC中包含着下一次要执行的命令索引,如果能和follower的当前索引对上,那就执行,否则拒绝,然后leader将会逐次递减索引,直到找到相同的那条日志。
然而这样也还是会有问题,比如某个follower在leader提交时宕机了,也就是少了几条命令,然后它又经过选举成了新的leader,这样它就会强制其他follower跟自己一样,使得其他节点上刚刚提交的命令被删除,导致客户端提交的一些命令被丢失了,下面一节内容将会解决这个问题。Raft通过为选举过程添加一个限制条件,解决了上面提出的问题,该限制确保leader包含之前term已经提交过的所有命令。Raft通过投票过程确保只有拥有全部已提交日志的candidate能成为leader。由于candidate为了拉选票需要通过RequestVote RPC联系其他节点,而之前提交的命令至少会存在于其中某一个节点上,因此只要candidate的日志至少和其他大部分节点的一样新就可以了, follower如果收到了不如自己新的candidate的RPC,就会将其丢弃.
还可能会出现另外一个问题, 如果命令已经被复制到了大部分节点上,但是还没来的及提交就崩溃了,这样后来的leader应该完成之前term未完成的提交. Raft通过让leader统计当前term内还未提交的命令已经被复制的数量是否半数以上, 然后进行提交.
4) 日志压缩
随着日志大小的增长,会占用更多的内存空间,处理起来也会耗费更多的时间,对系统的可用性造成影响,因此必须想办法压缩日志大小。Snapshotting是最简单的压缩方法,系统的全部状态会写入一个snapshot保存起来,然后丢弃截止到snapshot时间点之前的所有日志。Raft中的snapshot内容如下图所示:
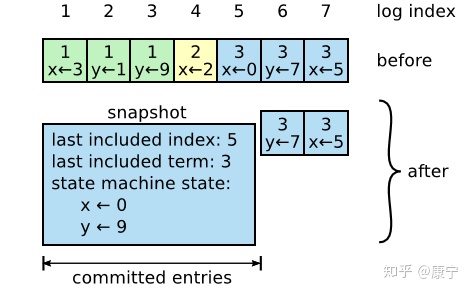
每一个server都有自己的snapshot,它只保存当前状态,如上图中的当前状态为x=0,y=9,而last included index和last included term代表snapshot之前最新的命令,用于AppendEntries的状态检查。
虽然每一个server都保存有自己的snapshot,但是当follower严重落后于leader时,leader需要把自己的snapshot发送给follower加快同步,此时用到了一个新的RPC:InstallSnapshot RPC。follower收到snapshot时,需要决定如何处理自己的日志,如果收到的snapshot包含有更新的信息,它将丢弃自己已有的日志,按snapshot更新自己的状态,如果snapshot包含的信息更少,那么它会丢弃snapshot中的内容,但是自己之后的内容会保存下来。RPC的定义如下:

[参看]:
