LevelDB实现原理(1)
LevelDB是一个可持久化的KV数据库引擎,由Google传奇工程师Jeff Dean和Sanjay Ghemawat开发并开源。无论从设计还是代码上都可以用精致来形容,非常值得细细品味。本文将从整体架构、数据读写等方面介绍一下LevelDB。
1. 设计思路
做存储的同学都很清楚,对于普通机械磁盘来说顺序写的性能要比随机写大很多。比如对于15000转的SAS盘,4K写IO,顺序写在200MB/s左右,而随机写性能可能只有1MB/s左右。而LevelDB的设计思想正是利用了磁盘的这个特性。LevelDB的数据是存储在磁盘上的,采用LSM-Tree的结构实现。LSM-Tree将磁盘的随机写转化为顺序写,从而大大提高了写速度。为了做到这一点,LSM-Tree(Log-Structured Merge Tree)的思路是将索引树结构拆成一大一小两颗树,较小的一个常驻内存,较大的一个持久化到磁盘,它们共同维护一个有序的key空间。写入操作会首先操作内存中的树,随着内存中树的不断变大,会触发与磁盘中树的归并操作,而归并操作本身仅有顺序写。如下图所示:
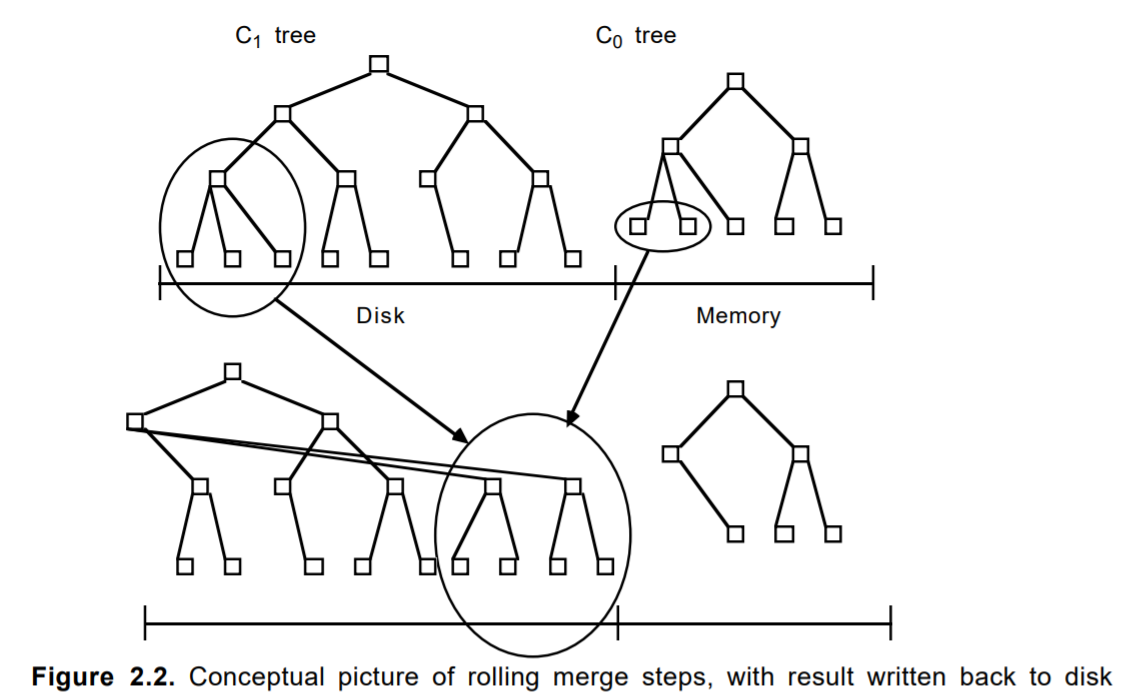
上图中,合并后的数据块会存储到磁盘空间,而这种存储方式是追加式的,也就是顺序写入磁盘。随着数据的不断写入,磁盘中的树会不断膨胀,为了避免每次参与归并操作的数据量过大,以及优化读操作的考虑,LevelDB将磁盘中的数据又拆分成多层,每一层的数据达到一定容量后会触发下一层的归并操作,每一层的数据量比上一层成倍增长。这也就是LevelDB的名称来源。
2. 主要特性
下面是LevelDB官方对其特性的描述,主要包括如下几点:
-
key和value都是任意长度的字节数组;
-
entry(即一条K-V记录)默认是按照key的字典顺序存储的,当然开发者也可以重载这个排序函数;
-
提供的基本操作接口:Put()、Delete()、Get()、Batch();
-
支持批量操作以原子操作进行;
-
可以创建数据全景的snapshot(快照),并允许在快照中查找数据;
-
可以通过前向(或后向)迭代器遍历数据(迭代器会隐含的创建一个snapshot;
-
自动使用Snappy压缩数据;
-
可移植性;
3. 整体结构
对LevelDB有一个整体的认识之后,我们分析一下它的架构。这里面有一个重要的概念(或者模块)需要理解,分别是内存数据的Memtable,分层数据存储的SST文件,版本控制的Manifest、Current文件,以及写Memtable前的WAL。这里简单介绍各个组件的作用和在整个结构中的位置。在介绍之前,我们先看一下整体架构示意图:
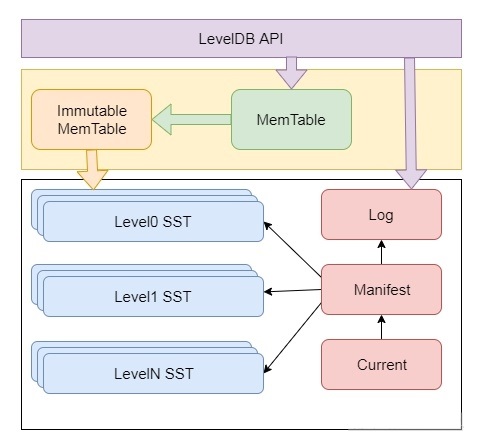
对于写数据,接口会同时写入内存表(MemTable)和日志中。当内存表达到阈值时,内存表冻结,变为Immutable MemTable,并将数据写入SST表中,其中SST表是在磁盘上的文件。下面是涉及到主要模块的简单介绍:
-
Memtable:内存数据结构,跳表实现,新的数据会首先写入这里;
-
Log文件:写Memtable前会先写Log文件,Log通过append的方式顺序写入。Log的存在使得机器宕机导致的内存数据丢失得以恢复;
-
Immutable Memtable:达到Memtable设置的容量上限后,Memtable会变为Immutable为之后向SST文件的归并做准备,顾名思义,Immutable Mumtable不再接受用户写入,同时会有新的Memtable生成;
-
SST文件:磁盘数据存储文件。分为Level-0到Level-N多层,每一层包含多个SST文件;单层SST文件总量随层次增加成倍增长;文件内数据有序;其中Level0的SST文件由Immutable直接Dump产生,其他Level的SST文件由其上一层的文件和本层文件归并产生;SST文件在归并过程中顺序写生成,生成后仅可能在之后的归并中被删除,而不会有任何的修改操作。
-
Manifest文件: Manifest文件中记录SST文件在不同Level的分布,单个SST文件的最大最小key,以及其他一些LevelDB需要的元信息。
-
Current文件: 从上面的介绍可以看出,LevelDB启动时的首要任务就是找到当前的Manifest,而Manifest可能有多个。Current文件简单的记录了当前Manifest的文件名,从而让这个过程变得非常简单。
3. 写数据流程
了解了整体流程和架构后,我们分析两个基本的流程,也就是LevelDB的写流程和读流程。我们这里首先分析一下写流程,毕竟要先有数据后才能读数据。LevelDB的写操作包括设置key-value和删除key两种。需要指出的是,这两种情况在LevelDB的处理上是一致的,删除操作其实是向LevelDB插入一条标识为删除的数据。下面我们先看一下LevelDB插入值的整体流程,如下图所示:
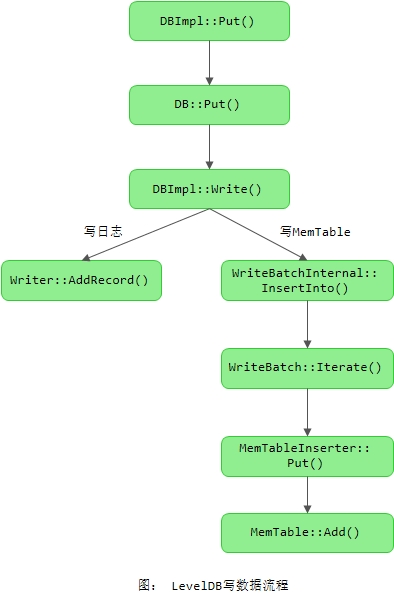
下面是最终进行数据写入的函数:
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
Writer w(&mutex_);
w.batch = updates;
w.sync = options.sync;
w.done = false;
MutexLock l(&mutex_);
writers_.push_back(&w);
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}
if (w.done) {
return w.status;
}
// May temporarily unlock and wait.
Status status = MakeRoomForWrite(updates == nullptr);
uint64_t last_sequence = versions_->LastSequence();
Writer* last_writer = &w;
if (status.ok() && updates != nullptr) { // nullptr batch is for compactions
WriteBatch* write_batch = BuildBatchGroup(&last_writer);
WriteBatchInternal::SetSequence(write_batch, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(write_batch);
// Add to log and apply to memtable. We can release the lock
// during this phase since &w is currently responsible for logging
// and protects against concurrent loggers and concurrent writes
// into mem_.
{
mutex_.Unlock();
status = log_->AddRecord(WriteBatchInternal::Contents(write_batch));
bool sync_error = false;
if (status.ok() && options.sync) {
status = logfile_->Sync();
if (!status.ok()) {
sync_error = true;
}
}
if (status.ok()) {
status = WriteBatchInternal::InsertInto(write_batch, mem_);
}
mutex_.Lock();
if (sync_error) {
// The state of the log file is indeterminate: the log record we
// just added may or may not show up when the DB is re-opened.
// So we force the DB into a mode where all future writes fail.
RecordBackgroundError(status);
}
}
if (write_batch == tmp_batch_) tmp_batch_->Clear();
versions_->SetLastSequence(last_sequence);
}
while (true) {
Writer* ready = writers_.front();
writers_.pop_front();
if (ready != &w) {
ready->status = status;
ready->done = true;
ready->cv.Signal();
}
if (ready == last_writer) break;
}
// Notify new head of write queue
if (!writers_.empty()) {
writers_.front()->cv.Signal();
}
return status;
}上面我们看到,LevelDB写入数据时都是先写log文件,服务宕机内存丢失,重启时可以从log文件恢复。
3.1 LevelDB日志写入
通过上面我们看到,在进行数据写入时会调用log_->AddRecord()进行写日志操作。下面我们来看一下具体实现:
1) 函数Writer::AddRecord()
Status Writer::AddRecord(const Slice& slice) {
const char* ptr = slice.data();
size_t left = slice.size();
// Fragment the record if necessary and emit it. Note that if slice
// is empty, we still want to iterate once to emit a single
// zero-length record
Status s;
bool begin = true;
do {
const int leftover = kBlockSize - block_offset_;
assert(leftover >= 0);
if (leftover < kHeaderSize) {
// Switch to a new block
if (leftover > 0) {
// Fill the trailer (literal below relies on kHeaderSize being 7)
static_assert(kHeaderSize == 7, "");
dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover));
}
block_offset_ = 0;
}
// Invariant: we never leave < kHeaderSize bytes in a block.
assert(kBlockSize - block_offset_ - kHeaderSize >= 0);
const size_t avail = kBlockSize - block_offset_ - kHeaderSize;
const size_t fragment_length = (left < avail) ? left : avail;
RecordType type;
const bool end = (left == fragment_length);
if (begin && end) {
type = kFullType;
} else if (begin) {
type = kFirstType;
} else if (end) {
type = kLastType;
} else {
type = kMiddleType;
}
s = EmitPhysicalRecord(type, ptr, fragment_length);
ptr += fragment_length;
left -= fragment_length;
begin = false;
} while (s.ok() && left > 0);
return s;
}
Status Writer::EmitPhysicalRecord(RecordType t, const char* ptr,
size_t length) {
assert(length <= 0xffff); // Must fit in two bytes
assert(block_offset_ + kHeaderSize + length <= kBlockSize);
// Format the header
char buf[kHeaderSize];
buf[4] = static_cast<char>(length & 0xff);
buf[5] = static_cast<char>(length >> 8);
buf[6] = static_cast<char>(t);
// Compute the crc of the record type and the payload.
uint32_t crc = crc32c::Extend(type_crc_[t], ptr, length);
crc = crc32c::Mask(crc); // Adjust for storage
EncodeFixed32(buf, crc);
// Write the header and the payload
Status s = dest_->Append(Slice(buf, kHeaderSize));
if (s.ok()) {
s = dest_->Append(Slice(ptr, length));
if (s.ok()) {
s = dest_->Flush();
}
}
block_offset_ += kHeaderSize + length;
return s;
}LevelDB的日志写入也比较简单,就是将打包好的Slice(即下图中的Record Body部分)逐一写入到Block中。一个Block的大小为32KB(即32768字节),如果一个block写不下,那么就需要将数据写入到多个block中。
注:这里有一点需要注意的是,由于一个Record Header占用7个字节,如果一个Block剩余的字节数小于7,那么将放不下一个Record Header,此时会直接使用0去填充该Block的剩余字节空间。也即,一个Record的Header是不能跨Block的。
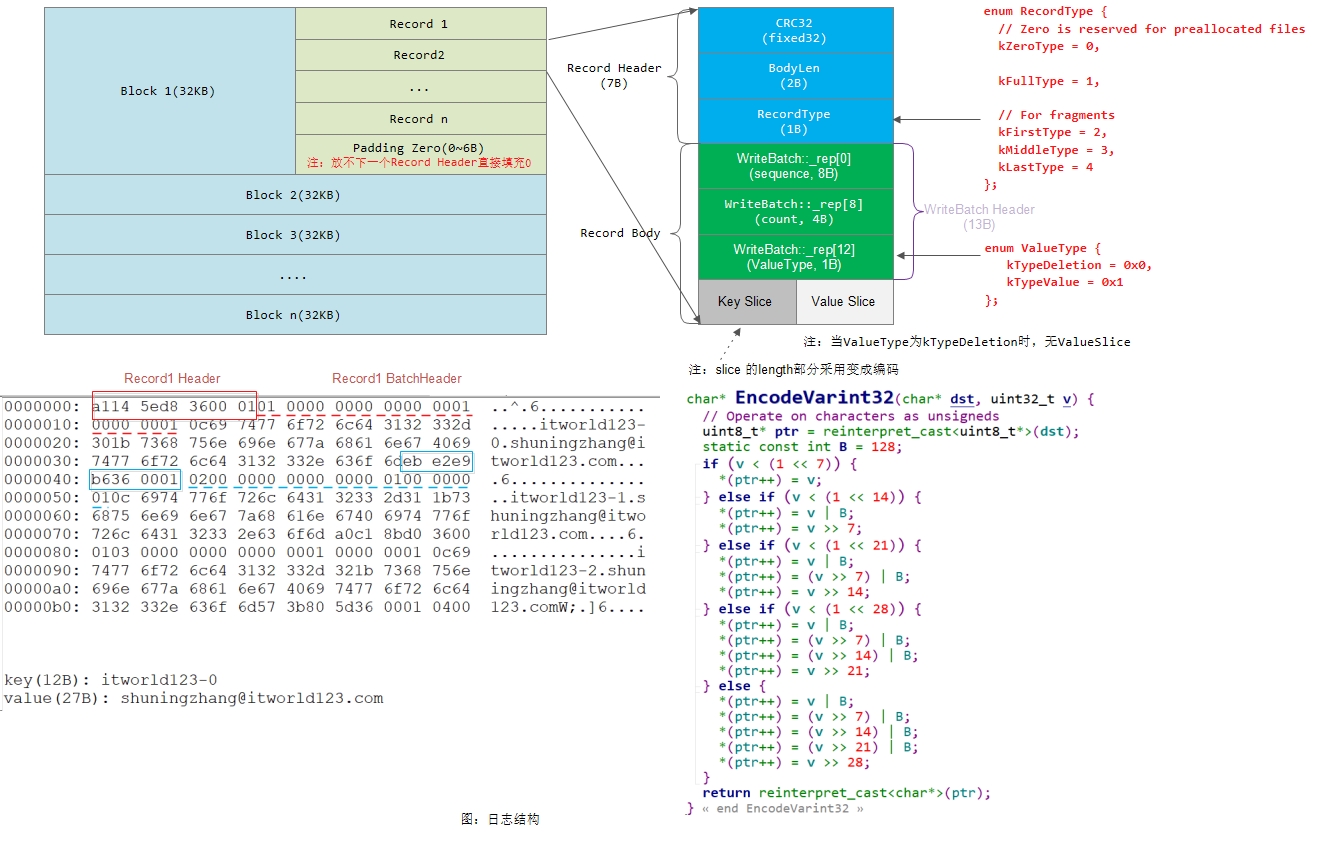
LevelDB通过mmap的方式来访问log文件。
注:每一次打开LevelDB数据库时都会创建一个新的日志。
3.2 写MemTable
LevelDB写数据时会调用如下函数来写MemTable:
Status WriteBatchInternal::InsertInto(const WriteBatch* b, MemTable* memtable) {
MemTableInserter inserter;
inserter.sequence_ = WriteBatchInternal::Sequence(b);
inserter.mem_ = memtable;
return b->Iterate(&inserter);
}
Status WriteBatch::Iterate(Handler* handler) const {
Slice input(rep_);
if (input.size() < kHeader) {
return Status::Corruption("malformed WriteBatch (too small)");
}
input.remove_prefix(kHeader);
Slice key, value;
int found = 0;
while (!input.empty()) {
found++;
char tag = input[0];
input.remove_prefix(1);
switch (tag) {
case kTypeValue:
if (GetLengthPrefixedSlice(&input, &key) &&
GetLengthPrefixedSlice(&input, &value)) {
handler->Put(key, value);
} else {
return Status::Corruption("bad WriteBatch Put");
}
break;
case kTypeDeletion:
if (GetLengthPrefixedSlice(&input, &key)) {
handler->Delete(key);
} else {
return Status::Corruption("bad WriteBatch Delete");
}
break;
default:
return Status::Corruption("unknown WriteBatch tag");
}
}
if (found != WriteBatchInternal::Count(this)) {
return Status::Corruption("WriteBatch has wrong count");
} else {
return Status::OK();
}
}最终我们看到,对于写key-value时是调用MemTableInserter::Put()来完成的,下面我们来看该函数的实现:
namespace {
class MemTableInserter : public WriteBatch::Handler {
public:
SequenceNumber sequence_;
MemTable* mem_;
void Put(const Slice& key, const Slice& value) override {
mem_->Add(sequence_, kTypeValue, key, value);
sequence_++;
}
void Delete(const Slice& key) override {
mem_->Add(sequence_, kTypeDeletion, key, Slice());
sequence_++;
}
};
} // namespace
void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key,
const Slice& value) {
// Format of an entry is concatenation of:
// key_size : varint32 of internal_key.size()
// key bytes : char[internal_key.size()]
// value_size : varint32 of value.size()
// value bytes : char[value.size()]
size_t key_size = key.size();
size_t val_size = value.size();
size_t internal_key_size = key_size + 8;
const size_t encoded_len = VarintLength(internal_key_size) +
internal_key_size + VarintLength(val_size) +
val_size;
char* buf = arena_.Allocate(encoded_len);
char* p = EncodeVarint32(buf, internal_key_size);
std::memcpy(p, key.data(), key_size);
p += key_size;
EncodeFixed64(p, (s << 8) | type);
p += 8;
p = EncodeVarint32(p, val_size);
std::memcpy(p, value.data(), val_size);
assert(p + val_size == buf + encoded_len);
table_.Insert(buf);
}从上面我们看到,在将数据插入到skiplist之前,会先对key-value进行编码:
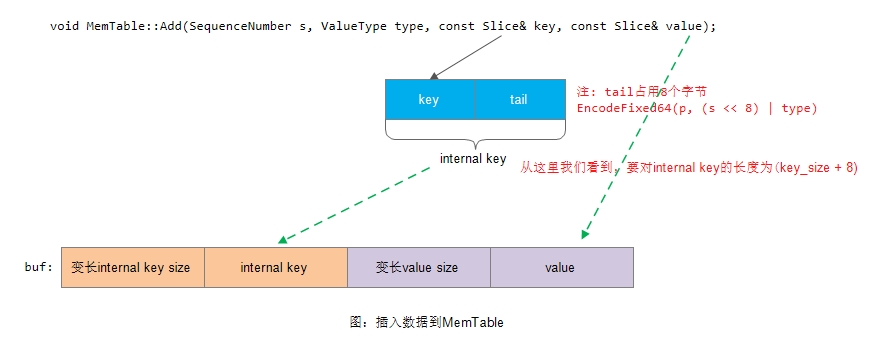
这里需要注意的是,如果要删除leveldb中的某个key时,不能直接从MemTable中删除。这是因为该key有可能已经持久化到了sst中。因此这里不管是添加key-value还是删除key,都是先直接将数据插入到MemTable,然后经过再经过ImmTable,最后固化到Level-0这一流程的。
3.3 写流程的进一步分析
在执行LevelDB数据写入操作时,还有一些细节我们可以介绍一下。如下图所示:
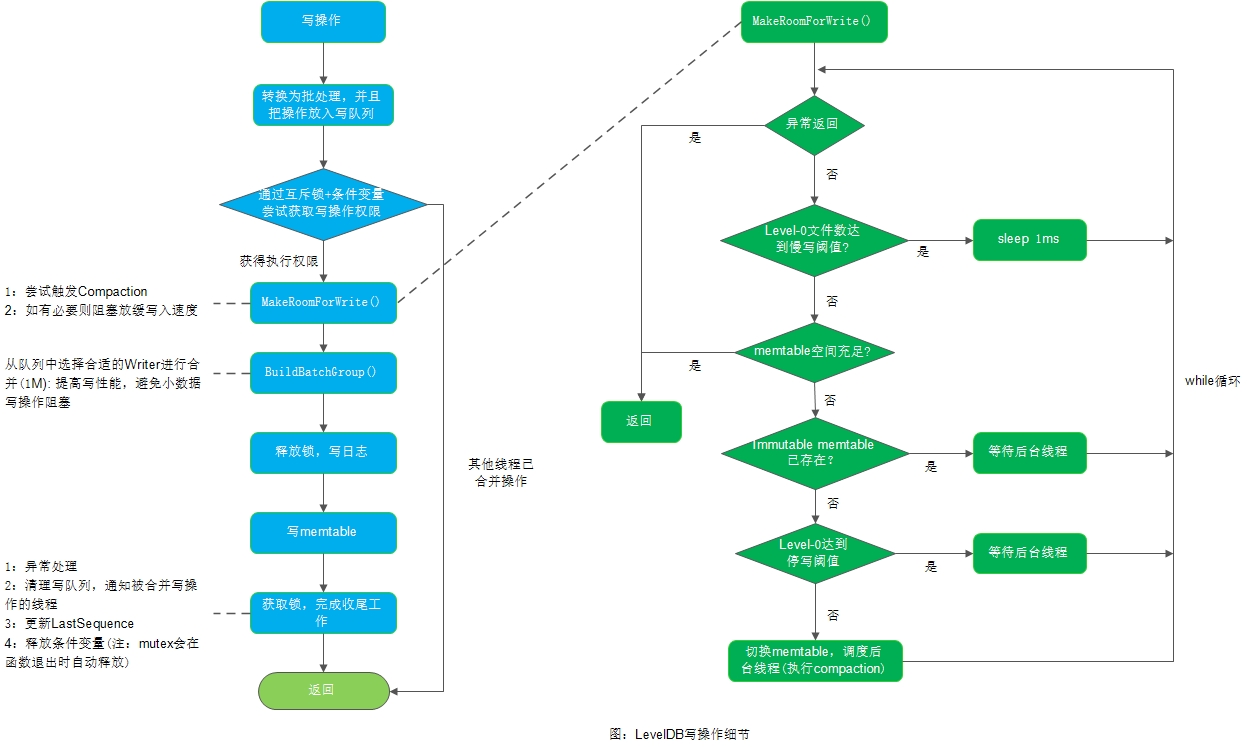
上面的写操作实现具有如下亮点:
-
构造了一个写队列(合并写),提高写性能。同时也避免小数据量的写请求被长时间阻塞
-
由于写队列存在,写日志和memtable这种耗时操作不需要加锁,释放锁去做其他资源同步。
注:关于LevelDB的compaction我们后面会专门进行介绍
4. 读数据流程
读流程要比写流程简单一些,核心代码如下所示:
Status DBImpl::Get(const ReadOptions& options, const Slice& key,
std::string* value) {
Status s;
MutexLock l(&mutex_);
SequenceNumber snapshot;
if (options.snapshot != nullptr) {
snapshot =
static_cast<const SnapshotImpl*>(options.snapshot)->sequence_number();
} else {
snapshot = versions_->LastSequence();
}
MemTable* mem = mem_;
MemTable* imm = imm_;
Version* current = versions_->current();
mem->Ref();
if (imm != nullptr) imm->Ref();
current->Ref();
bool have_stat_update = false;
Version::GetStats stats;
// Unlock while reading from files and memtables
{
mutex_.Unlock();
// First look in the memtable, then in the immutable memtable (if any).
LookupKey lkey(key, snapshot);
if (mem->Get(lkey, value, &s)) {
// Done
} else if (imm != nullptr && imm->Get(lkey, value, &s)) {
// Done
} else {
s = current->Get(options, lkey, value, &stats);
have_stat_update = true;
}
mutex_.Lock();
}
if (have_stat_update && current->UpdateStats(stats)) {
MaybeScheduleCompaction();
}
mem->Unref();
if (imm != nullptr) imm->Unref();
current->Unref();
return s;
}首先生成内部查询所用的key,该key是由用户请求的userkey拼接上sequence生成的。其中sequence可以用户提供或使用当前最新的sequence,LevelDB可以保证仅查询在这个sequence之前的写入。然后用生成的key,依次尝试从MemTable、ImmTable以及SST文件中读取,直到找到。
-
从
SST文件中查找需要依次在每一层中读取,得益于Manifest中记录的每个文件的key区间,我们可以很方便的知道某个key是否在文件中。Level-0的文件由于直接由Immutabledump产生,不可避免的会相互重叠,所以需要对每个文件依次查找。对于其他层次,由于归并过程保证了其相互不重叠且有序,二分查找的方式提供了更好的查询效率。 -
可以看出同一个Key出现在上层的操作会屏蔽下层的。也因此删除Key时只需要在Memtable压入一条标记为删除的条目即可。被其屏蔽的所有条目会在之后的归并过程中清除。
Tips: 从上面我们看到,在对LevelDB执行Get操作时有可能会通过MaybeScheduleCompaction()触发compaction动作
[参看]
