系统级性能分析工具perf的介绍与使用(转)
系统级性能优化通常包括两个阶段:性能剖析(performance profiling)和代码优化。性能剖析的目标是寻找性能瓶颈,查找引发性能问题的原因及热点代码; 代码优化的目标是针对具体性能问题而优化代码或编译选项,以改善软件性能。
在性能剖析阶段,需要借助于现有的profiling工具,如perf等。在代码优化阶段往往需要借助开发者的经验,编写简洁高效的代码,甚至在汇编级别合理使用各种指令,合理安排各种指令的执行顺序。
perf是一款Linux性能分析工具。Linux性能计数器是一个新的基于内核的子系统,它提供一个性能分析框架,比如硬件(CPU、PMU(Performance Monitor Unit))功能和软件(软件计数器、tracepoint)功能。通过perf,应用程序可以利用PMU、tracepoint和内核中的计数器来进行性能统计。它不但可以分析指定应用程序的性能问题,也可以用来分析内核的性能问题,当然也可以同时分析应用程序和内核,从而全面理解应用程序中的性能瓶颈。
使用perf,既可以分析程序运行期间的硬件事件,比如instruction retired、processor clock cycles等; 也可以分析软件事件,比如page fault和进程切换。perf是一款综合性分析工具,大到系统全局性性能,小到进程线程级别,甚至到函数及汇编级别。
当前我们的操作系统环境为:
# cat /etc/redhat-release CentOS Linux release 7.3.1611 (Core) # uname -a Linux localhost.localdomain 3.10.0-514.el7.x86_64 #1 SMP Tue Nov 22 16:42:41 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
1. 背景知识
1.1 tracepoints
tracepoints是散落在内核源代码中的一些hook,它们可以在特定的代码被执行到时触发,这一特性可以被各种trace/debug工具所使用。perf将tracepoint产生的时间记录下来,生成报告,通过分析这些报告,调优人员便可以了解程序运行期间内核的各种细节,对性能症状做出准确的诊断。
这些tracepoint对应的sysfs节点在/sys/kernel/debug/tracing/events目录下。
# ls /sys/kernel/debug/tracing/events
block enable filemap header_page kmem module nfsd printk rcu scsi sunrpc udp writeback
compaction exceptions ftrace iommu libata mpx oom random regmap signal syscalls vmscan xen
context_tracking fence gpio irq mce napi pagemap ras rpm skb task vsyscall xfs
drm filelock header_event irq_vectors migrate net power raw_syscalls sched sock timer workqueue xhci-hcd1.2 硬件之cache
内存读写是很快的,但是还是无法和处理器指令执行速度相比。为了从内存中读取指令和数据,处理器需要等待,用处理器时间来衡量,这种等待非常漫长。cache是一种SRAM,读写速度非常快,能和处理器相匹配。因此,将常用的数据保存在cache中,处理器便无需等待,从而提高性能。cache的尺寸一般都很小,充分利用cache是软件调优非常重要的部分。
2. 主要关注点
基于性能分析,可以进行算法优化(空间复杂度和时间复杂度权衡)、代码优化(提高执行速度,减少内存占用)。评估程序对硬件资源的使用情况,例如各级cache的访问次数、各级cache的丢失次数、流水线停顿周期、前端总线访问次数等。评估程序对操作系统资源的使用情况,系统调用次数、上下文切换次数、任务迁移次数。
事件可以分为如下三种:
-
Hardware Event由PMU部件产生,在特定的条件下探测性能事件是否发生以及发生的次数。比如cache命中
-
Software Event是内核产生的事件,分布在各个功能模块中,统计与操作系统相关的性能事件。比如进程切换、tick数等
-
Tracepoint Event是内核中静态tracepoint所触发的事件,这些tracepoint用来判断程序运行期间内核的行为细节,比如slab分配器的分配次数等。
3. perf初探
当前我们环境可以直接通过如下命令来安装perf:
# yum install perf # perf --help usage: perf [--version] [--help] [OPTIONS] COMMAND [ARGS] The most commonly used perf commands are: annotate Read perf.data (created by perf record) and display annotated code archive Create archive with object files with build-ids found in perf.data file bench General framework for benchmark suites buildid-cache Manage build-id cache. buildid-list List the buildids in a perf.data file c2c Shared Data C2C/HITM Analyzer. config Get and set variables in a configuration file. data Data file related processing diff Read perf.data files and display the differential profile evlist List the event names in a perf.data file ftrace simple wrapper for kernel's ftrace functionality inject Filter to augment the events stream with additional information kallsyms Searches running kernel for symbols kmem Tool to trace/measure kernel memory properties kvm Tool to trace/measure kvm guest os list List all symbolic event types lock Analyze lock events mem Profile memory accesses record Run a command and record its profile into perf.data report Read perf.data (created by perf record) and display the profile sched Tool to trace/measure scheduler properties (latencies) script Read perf.data (created by perf record) and display trace output stat Run a command and gather performance counter statistics test Runs sanity tests. timechart Tool to visualize total system behavior during a workload top System profiling tool. probe Define new dynamic tracepoints trace strace inspired tool See 'perf help COMMAND' for more information on a specific command.
下面我们分成几个大的部分简单介绍一下各选项:
1) 全局性概况
-
perf list: 查看当前系统支持的所有性能事件。包括硬件性能事件、软件性能事件以及检查点。
-
perf bench: perf中内置的benchmark,目前包括两套针对调度器和内存管理子系统的benchmark。
-
perf test: 对系统进行健全性测试
-
perf stat: 执行某个命令,收集特定进程的性能概况,包括CPI、Cache丢失率等。可以对某一个程序进行全局性的性能统计
2) 全局细节
-
perf top: 类似于linux的top命令,对系统性能进行实时分析。可以实时查看当前系统进程函数占用率情况
-
perf probe: 用于自定义动态检查点
3) 特定功能分析
-
perf kmem: 针对slab子系统性能分析;
-
perf kvm: 针对kvm虚拟化分析;
-
perf lock: 分析锁性能;
-
perf mem: 分析内存slab性能;
-
perf sched: 分析内核调度器性能;
-
perf trace: 记录
系统调用轨迹;
4) 最常用功能perf record,可以系统全局,也可以具体到某个进程,更甚具体到某一进程某一事件;可宏观,也可以很微观
-
pref record: 收集采样信息,并将其记录在数据文件中。随后可通过其它工具对数据文件进行分析。
-
perf report: 读取perf record创建的数据文件,并给出热点分析结果。
-
perf diff: 对比两个数据文件的差异。能够给出每个符号(函数)在热点分析上的具体差异.
-
perf evlist: 列出数据文件perf.data中所有性能事件
-
perf annotate: 解析perf record生成的perf.data文件,显示被注释的代码。
-
perf archive: 根据数据文件记录的build-id,将所有被采样到的elf文件打包。利用此压缩包,可以再在任何机器上分析数据文件中记录的采样数据。
-
perf script: 执行perl或python写的功能扩展脚本、生成脚本框架、读取数据文件中的数据信息等
5) 可视化工具perf timechart
-
perf timechart: 针对测试期间系统行为进行可视化的工具
-
perf timechart生成output.svg文档;
3.1 perf引入的overhead
perf测试不可避免的会引入额外负荷,有三种形式:
-
counting: 内核提供计数总结,多是Hardware Event、Software Events、PMU计数等。相关命令perf stat
-
sampling: perf将事件数据缓存到一块buffer中,然后异步写入到perf.data文件中。使用perf report等工具进行离线分析
-
bpf: Kernel 4.4+新增功能,可以提供更多有效filter和输出总结
counting引入的额外负荷最小; sampling在某些情况下会引入非常大的负荷; bpf可以有效缩减负荷。针对sampling,可以通过挂载建立在RAM上的文件系统来有效降低读写IO引入的负荷:
# mkdir /tmpfs # mount -t tmpfs tmpfs /tmpfs
3.2 perf list
perf list不能完全显示所有支持的事件类型 ,需要执行sudo perf list。同时,还可以显示特定模块支持的perf事件:
-
hw/cache/pmu都是硬件相关的
-
tracepoint是基于内核的ftrace
-
sw实际上是内核计数器
1) hw/hardware显示支持的相关硬件事件
# sudo perf list hardware List of pre-defined events (to be used in -e): branch-instructions OR branches [Hardware event] branch-misses [Hardware event] bus-cycles [Hardware event] cache-misses [Hardware event] cache-references [Hardware event] cpu-cycles OR cycles [Hardware event] instructions [Hardware event] ref-cycles [Hardware event]
2) sw/software显示支持的软件事件列表
# sudo perf list sw List of pre-defined events (to be used in -e): alignment-faults [Software event] context-switches OR cs [Software event] cpu-clock [Software event] cpu-migrations OR migrations [Software event] dummy [Software event] emulation-faults [Software event] major-faults [Software event] minor-faults [Software event] page-faults OR faults [Software event] task-clock [Software event]
3) cache/hwcache显示硬件cache相关事件列表
# sudo perf list cache List of pre-defined events (to be used in -e): L1-dcache-load-misses [Hardware cache event] L1-dcache-loads [Hardware cache event] L1-dcache-stores [Hardware cache event] L1-icache-load-misses [Hardware cache event] LLC-load-misses [Hardware cache event] LLC-loads [Hardware cache event] LLC-store-misses [Hardware cache event] LLC-stores [Hardware cache event] branch-load-misses [Hardware cache event] branch-loads [Hardware cache event] dTLB-load-misses [Hardware cache event] dTLB-loads [Hardware cache event] dTLB-store-misses [Hardware cache event] dTLB-stores [Hardware cache event] iTLB-load-misses [Hardware cache event] iTLB-loads [Hardware cache event] node-load-misses [Hardware cache event] node-loads [Hardware cache event] node-store-misses [Hardware cache event] node-stores [Hardware cache event]
4) pmu显示支持的PMU事件列表
# sudo perf list pmu List of pre-defined events (to be used in -e): branch-instructions OR cpu/branch-instructions/ [Kernel PMU event] branch-misses OR cpu/branch-misses/ [Kernel PMU event] bus-cycles OR cpu/bus-cycles/ [Kernel PMU event] cache-misses OR cpu/cache-misses/ [Kernel PMU event] cache-references OR cpu/cache-references/ [Kernel PMU event] cpu-cycles OR cpu/cpu-cycles/ [Kernel PMU event] cycles-ct OR cpu/cycles-ct/ [Kernel PMU event] cycles-t OR cpu/cycles-t/ [Kernel PMU event] el-abort OR cpu/el-abort/ [Kernel PMU event] el-capacity OR cpu/el-capacity/ [Kernel PMU event] el-commit OR cpu/el-commit/ [Kernel PMU event] el-conflict OR cpu/el-conflict/ [Kernel PMU event] el-start OR cpu/el-start/ [Kernel PMU event] instructions OR cpu/instructions/ [Kernel PMU event] intel_bts// [Kernel PMU event] mem-loads OR cpu/mem-loads/ [Kernel PMU event] mem-stores OR cpu/mem-stores/ [Kernel PMU event] power/energy-cores/ [Kernel PMU event] power/energy-gpu/ [Kernel PMU event] power/energy-pkg/ [Kernel PMU event] ....
5) tracepoint显示支持的所有tracepoint列表
# sudo perf list tracepoint List of pre-defined events (to be used in -e): block:block_bio_backmerge [Tracepoint event] block:block_bio_bounce [Tracepoint event] block:block_bio_complete [Tracepoint event] block:block_bio_frontmerge [Tracepoint event] block:block_bio_queue [Tracepoint event] block:block_bio_remap [Tracepoint event] block:block_dirty_buffer [Tracepoint event] block:block_getrq [Tracepoint event] block:block_plug [Tracepoint event] block:block_rq_abort [Tracepoint event] block:block_rq_complete [Tracepoint event] block:block_rq_insert [Tracepoint event] block:block_rq_issue [Tracepoint event] block:block_rq_remap [Tracepoint event] block:block_rq_requeue [Tracepoint event] block:block_sleeprq [Tracepoint event] block:block_split [Tracepoint event] block:block_touch_buffer [Tracepoint event] block:block_unplug [Tracepoint event] compaction:mm_compaction_isolate_freepages [Tracepoint event] compaction:mm_compaction_isolate_migratepages [Tracepoint event] compaction:mm_compaction_migratepages [Tracepoint event] context_tracking:user_enter [Tracepoint event] context_tracking:user_exit [Tracepoint event] drm:drm_vblank_event [Tracepoint event] drm:drm_vblank_event_delivered [Tracepoint event] drm:drm_vblank_event_queued [Tracepoint event] exceptions:page_fault_kernel [Tracepoint event] ...
6)指定性能事件
-e <event>:u //userspace
-e <event>:k //kernel
-e <event>:h //hypervisor
-e <event>:G //guest counting(in KVM guests)
-e <event>:H //host counting(not in KVM guests)7) 使用用例
4. perf top的使用
perf top主要用于实时分析各个函数在某个性能事件上的热度,能够快速的定位热点函数,包括应用程序函数、模块函数与内核函数,甚至能够定位到热点指令。默认的性能事件为cpu cycles。
默认情况下,perf top是无法显示信息的,需要sudo perf top,或者echo -1 > /proc/sys/kernel/perf_event_paranoid(注:在Ubuntu16.04系统中,还需要echo 0 > /proc/sys/kernel/kptr_restrict)。例如:
# cat /proc/sys/kernel/perf_event_paranoid
1
# echo -1 > /proc/sys/kernel/perf_event_paranoid
# cat /proc/sys/kernel/perf_event_paranoid
-1
#
# sudo perf top
Samples: 600 of event 'cycles:ppp', Event count (approx.): 195997614
Overhead Shared Object Symbol
2.37% [kernel] [k] __schedule
2.26% beam.smp [.] process_main
2.00% [kernel] [k] __d_lookup_rcu
1.65% [kernel] [k] cpuidle_enter_state
1.61% libpthread-2.17.so [.] pthread_mutex_lock
1.47% [kernel] [k] menu_select
1.37% [kernel] [k] sys_epoll_wait
1.36% [vdso] [.] __vdso_clock_gettime
1.30% beam.smp [.] erts_thr_progress_prepare_wait
1.27% [kernel] [k] __switch_to
1.27% beam.smp [.] erts_poll_wait_kp
1.25% [kernel] [k] tick_check_oneshot_broadcast_this_cpu
1.24% [kernel] [k] unmap_page_range
1.24% [kernel] [k] task_waking_fair
1.14% [kernel] [.] irq_return
1.12% beam.smp [.] erts_deliver_time
1.08% [kernel] [k] system_call_after_swapgs
1.07% [kernel] [k] rb_insert_color
1.04% [kernel] [k] rcu_needs_cpu
1.03% [kernel] [k] hrtimer_start_range_ns
1.02% [kernel] [k] cpuidle_idle_call
1.01% beam.smp [.] 0x000000000009db8d
1.00% beam.smp [.] cmp
0.84% [kernel] [k] ep_poll
0.82% libc-2.17.so [.] clock_gettime
0.78% [kernel] [k] free_pcppages_bulk
0.77% [kernel] [k] rb_erase
0.76% [kernel] [k] update_curr
0.71% beam.smp [.] 0x000000000009dba0
0.68% [kernel] [k] timerqueue_add
...-
第一列: 符号引发的性能事件的比例,指占用CPU周期比例
-
第二列: 符号所在的DSO(Dynamic Shared Object),可以是应用程序、内核、动态链接库、模块
-
第三列: DSO的类型。
[.]表示此符号属于用户态的ELF文件,包括可执行文件和动态链接库;[k]表示此符号属于内核或模块 -
第四列: 符号名。有些函数不能解析为函数名,只能用地址表示
1) 常用交互命令
h:显示帮助,即可显示详细的帮助信息。 UP/DOWN/PGUP/PGDN/SPACE:上下和翻页。 a:annotate current symbol,注解当前符号。能够给出汇编语言的注解,给出各条指令的采样率。 d:过滤掉所有不属于此DSO的符号。非常方便查看同一类别的符号。 P:将当前信息保存到perf.hist.N中。
这里注意,在SecureCRT中可能不能够明显的看到当前的选中行,直接在Linux控制台会有相应的颜色指示当前选中项。
2) perf top常用选项
-
-e <event>: 指明要分析的性能事件 -
-p <pid>: 仅分析目标进程及其创建的线程。pid之间以逗号分割 -
-k <path>: 带符号表的内核映像所在的路径 -
-K: 不显示属于内核或模块的符号 -
-U: 不显示属于用户态程序的符号 -
-d <n>: 界面的刷新周期,默认为2s,因为perf top默认每2s从mmap的内存区域读取一次性能数据 -
-G: 得到函数的调用关系图
perf top --call-graph fractal,路径概率为相对值,加起来为100%,调用顺序为从下往上。 perf top --call-graph graph,路径概率为绝对值,加起来为该函数的热度
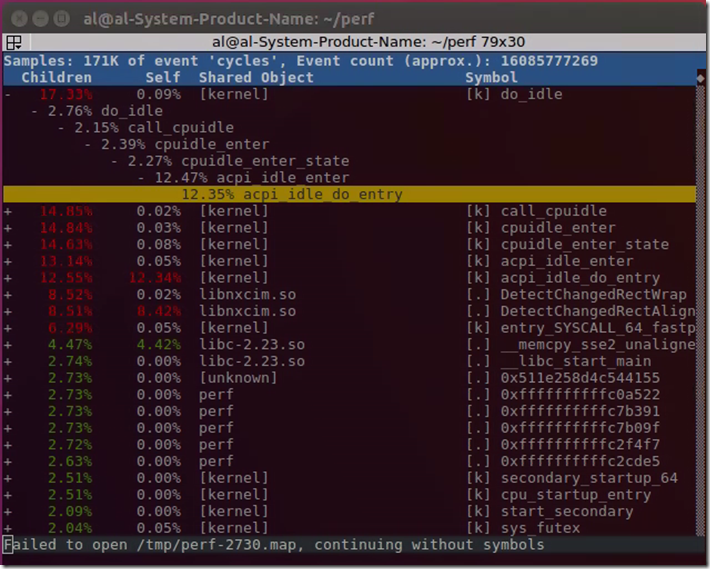
3) 使用示例
# perf top // 默认配置 # perf top -G // 得到调用关系图 # perf top -e cycles // 指定性能事件 # perf top -p 23015,32476 // 查看这两个进程的cpu cycles使用情况 # perf top -s comm,pid,symbol // 显示调用symbol的进程名和进程号 # perf top --comms nginx,top // 仅显示属于指定进程的符号 # perf top --symbols kfree // 仅显示指定的符号
4) 具体程序示例
使用perf stat(如下会介绍)的时候,往往你已经有一个调优的目标。但有些时候,你只是发现系统性能无端下降,并不清楚究竟哪个进程成为了贪吃dog。此时需要一个类似top的命令,列出所有值得怀疑的进程,从中找到需要进一步审查的家伙。perf top用于实时显示当前系统的性能统计信息。该命令主要用来观察整个系统当前的状态,比如可以通过该命令的输出来查看当前系统最耗时的内核函数或某个用户进程。
下面我们给出一个示例(perf_test1.c):
int main(int argc,char *argv[])
{
int i;
while(1)
i++;
return 0x0;
}编译运行:
# gcc -g -o perf_test1 perf_test1.c # ./perf_test1
运行这个程序后,我们再起另外一个窗口,运行perf top来看看:
# perf top Samples: 54K of event 'cycles:ppp', Event count (approx.): 37421490869 Overhead Shared Object Symbol 88.05% perf_test1 [.] main 0.37% libpython3.4m.so.1.0 [.] PyEval_EvalFrameEx 0.32% bash [.] main 0.23% beam.smp [.] erts_alloc_init 0.20% beam.smp [.] erts_foreach_sys_msg_in_q 0.19% beam.smp [.] trace_sched_ports 0.13% beam.smp [.] trace_virtual_sched
这里我们很容易便发现perf_test1是需要关注的可疑程序(注: perf top运行之后,可能需要等待一段时间,才能看到)。不过其作案手法太简单: 肆无忌惮地浪费着CPU。所以我们不用再做什么其他的事情便可疑找到问题所在。但现实生活中,影响性能的程序一般不会如此愚蠢,所以我们往往还需要使用其他的perf工具进行进一步分析。
5. perf stat的使用
perf stat用于运行指令,并分析其统计结果。虽然perf top也可以指定pid,但是必须先启动应用才能查看信息,而perf stat则可以用来直接启动程序。
perf stat能完整的统计应用整个生命周期的信息。命令格式为:
perf stat [-e <EVENT> | --event=EVENT] [-a] <command>
perf stat [-e <EVENT> | --event=EVENT] [-a] — <command> [<options>]下面来简单看一下perf stat的输出:
# perf stat //输入马上按CTRL+C
^C
Performance counter stats for 'system wide':
1098.937652 cpu-clock (msec) # 7.982 CPUs utilized
121 context-switches # 0.110 K/sec
6 cpu-migrations # 0.005 K/sec
1 page-faults # 0.001 K/sec
7,936,603 cycles # 0.007 GHz
3,202,686 instructions # 0.40 insn per cycle
650,820 branches # 0.592 M/sec
27,319 branch-misses # 4.20% of all branches
0.137685089 seconds time elapsed
上面是我们执行perf stat,然后马上按CTRL+C退出打印出来的信息。接着我们简单介绍一下各字段的含义:
-
cpu-clock: 任务真正占用的处理器时间,单位是ms。CPUs utilized = task-clock / time elapsed,CPU的占用率。
-
context-switches: 程序在运行过程中上下文切换的次数
-
cpu-migrations: 程序在运行过程中发生的处理器迁移次数。Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU迁移到另一个CPU。
注: 关于CPU迁移和上下文切换 发生上下文切换不一定会发生CPU迁移,而发生CPU迁移时肯定会发生上下文切换。发生上下文切换有可能只是把上下文 从当前CPU中换出,下一次调度器还是将进程安排在这个CPU上执行。
-
page_faults: 缺页异常的次数。当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页中断异常。另外,TLB不命中,页面访问权限不匹配等情况也会触发缺页异常。
-
cycles: 消耗的处理器周期数。如果我们执行
perf stat ls
# perf stat ls
b2 bjam boost-build.jam boost.css bootstrap.bat bootstrap.sh index.htm INSTALL libs more rst.css status
bin.v2 boost boostcpp.jam boost.png bootstrap.log doc index.html Jamroot LICENSE_1_0.txt project-config.jam stage tools
Performance counter stats for 'ls':
0.625255 task-clock (msec) # 0.736 CPUs utilized
22 context-switches # 0.035 M/sec
0 cpu-migrations # 0.000 K/sec
285 page-faults # 0.456 M/sec
2,247,015 cycles # 3.594 GHz
1,627,504 instructions # 0.72 insn per cycle
327,118 branches # 523.175 M/sec
12,593 branch-misses # 3.85% of all branches
0.000850072 seconds time elapsed
然后把输出的cpu cycles看成是一个处理器的,那么它的主频为3.594GHz。可以用cycles/task-clock算出。
-
instructions: 执行了多少条指令。IPC(insn per cycle)为平均每个cpu cycle执行了多少条指令
-
branches: 遇到的分支指令数。
-
branch-misses: 预测错误的分支指令数
1) 其他常用参数
-a, --all-cpus 显示所有CPU上的统计信息
-C, --cpu <cpu> 显示指定CPU的统计信息
-c, --scale scale/normalize counters
-D, --delay <n> ms to wait before starting measurement after program start
-d, --detailed detailed run - start a lot of events
-e, --event <event> event selector. use 'perf list' to list available events
-G, --cgroup <name> monitor event in cgroup name only
-g, --group put the counters into a counter group
-I, --interval-print <n>
print counts at regular interval in ms (>= 10)
-i, --no-inherit child tasks do not inherit counters
-n, --null null run - dont start any counters
-o, --output <file> 输出统计信息到文件
-p, --pid <pid> stat events on existing process id
-r, --repeat <n> repeat command and print average + stddev (max: 100, forever: 0)
-S, --sync call sync() before starting a run
-t, --tid <tid> stat events on existing thread id
...2) 使用示例
下面我们给出一个示例perf_test2.c。其中函数longa()是个很长的循环,比较浪费时间; 函数foo1()和foo2()将分别调用该函数10次和100次:
void longa()
{
int i,j;
for(i = 0; i < 1000000; i++)
j=i; //am I silly or crazy? I feel boring and desperate.
}
void foo1()
{
int i;
for(i = 0; i< 100; i++)
longa();
}
void foo2()
{
int i;
for(i=0 ; i < 10; i++)
longa();
}
int main(int argc, char *argv[])
{
foo1();
foo2();
return 0x0;
}然后执行下面的命令进行编译:
# gcc -g -o perf_test2 perf_test2.c
下面演示了perf stat针对程序perf_test2的输出:
# perf stat ./perf_test2
Performance counter stats for './perf_test2':
205.309101 task-clock (msec) # 0.999 CPUs utilized
0 context-switches # 0.000 K/sec
0 cpu-migrations # 0.000 K/sec
111 page-faults # 0.541 K/sec
773,240,949 cycles # 3.766 GHz
551,050,656 instructions # 0.71 insn per cycle
110,190,791 branches # 536.707 M/sec
4,305 branch-misses # 0.00% of all branches
0.205596513 seconds time elapsed
从上面可以看出,程序perf_test2是一个CPU bound型,因为task-clock-msecs接近1。
有些程序慢是因为计算量太大,其多数时间都应该在使用 CPU 进行计算,这叫做 CPU bound 型;有些程序慢是因为过多的 IO,这种时候其 CPU 利用率应该不高,这叫做 IO bound 型;对于 CPU bound 程序的调优和 IO bound 的调优是不同的。
3) perf stat更多统计项
perf stat默认情况下,只会对一些项进行统计。如果需要更多的统计项,可以通过-e选项来指定。例如:
# sudo perf stat -e task-clock,context-switches,cpu-migrations,page-faults,cycles,stalled-cycles-frontend,stalled-cycles-backend, \
instructions,branches,branch-misses,L1-dcache-loads,L1-dcache-load-misses,LLC-loads,LLC-load-misses,dTLB-loads,dTLB-load-misses ls
perf_test1 perf_test1.c perf_test2 perf_test2.c
Performance counter stats for 'ls':
0.530557 task-clock (msec) # 0.764 CPUs utilized
2 context-switches # 0.004 M/sec
0 cpu-migrations # 0.000 K/sec
280 page-faults # 0.528 M/sec
1,945,037 cycles # 3.666 GHz
<not supported> stalled-cycles-frontend
<not supported> stalled-cycles-backend
1,419,884 instructions # 0.73 insn per cycle
282,634 branches # 532.712 M/sec
11,539 branch-misses # 4.08% of all branches
<not counted> L1-dcache-loads (0.00%)
<not counted> L1-dcache-load-misses (0.00%)
<not counted> LLC-loads (0.00%)
<not counted> LLC-load-misses (0.00%)
<not counted> dTLB-loads (0.00%)
<not counted> dTLB-load-misses (0.00%)
0.000694272 seconds time elapsed
Some events weren't counted. Try disabling the NMI watchdog:
echo 0 > /proc/sys/kernel/nmi_watchdog
perf stat ...
echo 1 > /proc/sys/kernel/nmi_watchdog6. 使用perf record/report
使用perf top和perf stat之后,您可能已经大致有数了。要进一步分析,便需要一些粒度更细的信息。比如说你已经断定目标程序计算量较大,也许是因为有些代码写的不够精简。那么面对长长的代码文件,究竟哪几行代码需要进一步修改呢? 这便需要使用perf record记录单个函数级别的统计信息,并使用perf report来显示统计结果。
您的调优应该将注意力集中到百分比高的热点代码片段上,假如一段代码只占用整个程序运行时间的0.1%,即使你将其优化到仅剩一条机器指令,恐怕也只能将整体程序的性能提高0.1%。俗话说,好钢用在刀刃上,不必我多说了。下面我们用perf record来运行上述perf_test2.c程序:
# perf record -e cpu-clock ./perf_test2 // 默认导出的文件名为perf.data, 也可以使用-o选项来指定导出的文件 [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.044 MB perf.data (801 samples) ]
接着,我们用perf report来分析:
# perf report -i ./perf.data Samples: 801 of event 'cpu-clock', Event count (approx.): 200250000 Overhead Command Shared Object Symbol 100.00% perf_test2 perf_test2 [.] longa
不出所料,hot spot 是 longa() 函数。但是,代码是非常复杂难说的,perf_test2程序中的foo1()也是一个潜在的调优对象,为什么要调用100次那个无聊的longa()函数呢? 但我们在上图中无法发现foo1()和foo2(),更无法了解他们的区别了。我曾发现自己写的一个程序居然有近一半的时间花费在string类的几个方法上, string是C++标准库函数,我绝不可能写出比STL更好的代码了。因此我只有找到自己程序中过多使用string的地方。因此我很需要按照调用关系进行显示的统计信息。
使用perf record的-g选项便可以得到需要的信息:
# perf record -e cpu-clock -g ./perf_test2
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.081 MB perf.data (803 samples) ]再接着使用perf report来进行分析:
# perf report -i perf.data
Samples: 803 of event 'cpu-clock', Event count (approx.): 200750000
Children Self Command Shared Object Symbol
+ 99.88% 99.88% perf_test2 perf_test2 [.] longa
+ 99.88% 0.00% perf_test2 libc-2.17.so [.] __libc_start_main
+ 99.88% 0.00% perf_test2 perf_test2 [.] main
+ 90.91% 0.00% perf_test2 perf_test2 [.] foo1
+ 8.97% 0.00% perf_test2 perf_test2 [.] foo2
0.12% 0.12% perf_test2 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.12% 0.00% perf_test2 [kernel.kallsyms] [k] system_call_fastpath
0.12% 0.00% perf_test2 [kernel.kallsyms] [k] sys_exit_group
0.12% 0.00% perf_test2 [kernel.kallsyms] [k] do_group_exit
0.12% 0.00% perf_test2 [kernel.kallsyms] [k] do_exit
0.12% 0.00% perf_test2 [kernel.kallsyms] [k] mmput
0.12% 0.00% perf_test2 [kernel.kallsyms] [k] exit_mmap
0.12% 0.00% perf_test2 [kernel.kallsyms] [k] tlb_finish_mmu
0.12% 0.00% perf_test2 [kernel.kallsyms] [k] tlb_flush_mmu.part.61
0.12% 0.00% perf_test2 [kernel.kallsyms] [k] free_pages_and_swap_cache
0.12% 0.00% perf_test2 [kernel.kallsyms] [k] release_pages
上面通过对calling graph的分析,能很方便的看到90.91%的时间都花费在foo1()函数中,因为它调用了100次 longa() 函数,因此假如longa()是个无法优化的函数,那么程序员就应该考虑优化foo1()函数,减少对longa()函数的调用次数。
[参看]:
-
# perf record -F 99 -g -p 11121 -- sleep 60 # perf script > out.perf # /home/ivanzz101/FlameGraph/stackcollapse-perf.pl out.perf > out.folded # /home/ivanzz1001/FlameGraph/flamegraph.pl out.folded > flamegraph.svg
