kafka工作原理介绍
Kafka起初是由LinkedIn公司采用Scala语言开发的一个多分区、多副本且基于Zookeeper协调的分布式消息系统,现已捐献给Apache基金会。目前Kafka已经定位为一个分布式流式处理平台,它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用。
目前越来越多的开源分布式处理系统如Cloudera、Storm、Spark、Flink等都支持与Kafka集成。Kafka之所以受到越来越多的亲昵,与它所“扮演”的三大角色是分不开的:
-
消息系统: Kafka和传统的消息系统(也称作消息中间件)都具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。与此同时,kafka还提供了大多数消息系统难以实现的消息顺序性保障及回溯消费的功能
-
存储系统: Kafka把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效地降低了数据丢失的风险。也正是得益于kafka的消息持久化功能和多副本机制,我们可以把kafka作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置为“永久”或启用主题的日志压缩功能即可。
-
流式处理平台: Kafka不仅为每个流行的流式处理框架提供了可靠的数据来源,还提供了一个完整的流式处理类库,比如窗口、连接、变换和聚合等各类操作。
1. 基本介绍
Apache Kafka是一个分布式的流处理平台,其主要有如下三个关键特性:
-
发布与订阅数据流,类似于消息队列或企业消息系统
-
以高容错的方式存储数据流
-
处理数据流
Kafka主要应用于两大类型的应用:
-
构建实时流数据通道,使得不用系统或应用之间能够可靠地获取到数据
-
构建实时流应用程序,以对流数据进行转换或处理
为了理解kafka是如何完整这些功能,这里我们深入kafka并从底层到上层来逐渐探索kafka的一些特性。首先了解如下概念:
-
kafka以集群的方式运行在一台或多台服务器上(这些服务器可以横跨多个数据中心)
-
kafka集群以不同分类(catagories)的方式存储数据流,这里我们将分类(catagory)称作topic
-
kafka中保存的每一条记录都由3个部分所组成:key、value、timestamp
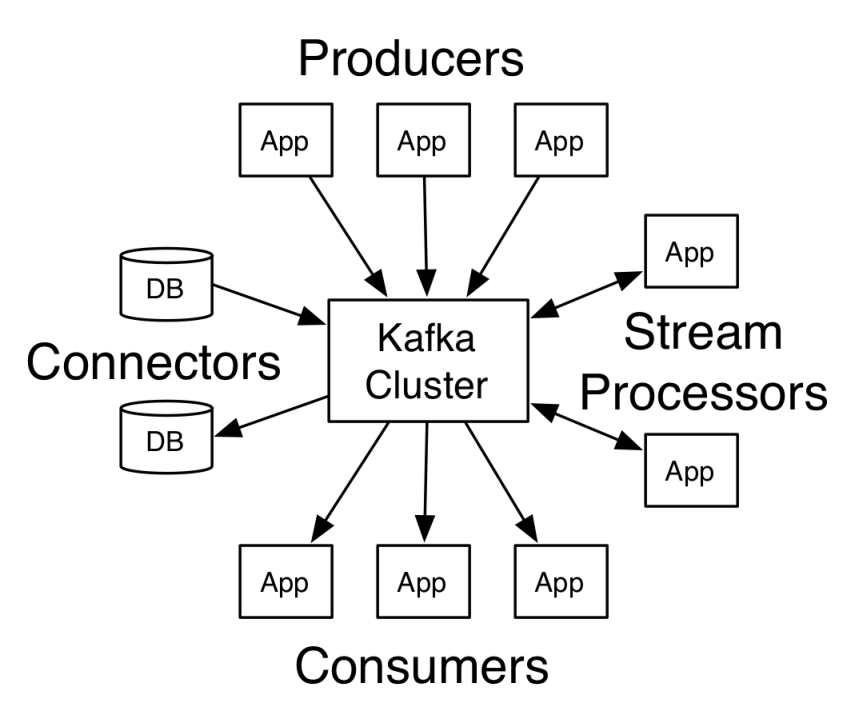
kafka有4大类型的核心API:
-
生产者(Producer)API: 应用程序可用该API来发布数据流到一个或多个kafka topic
-
消费者(Consumer)API: 应用程序可用该API来订阅一个或多个topic的数据,然后再对这些数据记录进行处理
-
流(Streams)API: 使得应用程序可以作为一个流处理器(stream processor),从一个或多个topic消费输入流,并产生一个输出流存放到一个或多个topic,从而高效的完成输入流到输出流的转变
-
Connector API: 已存在的应用程序或数据系统可用该API来构建及运行可重复使用的生产者、消费者。例如,连接到传统关系型数据库的connector,通过其来捕获表数据的修改。
如下图所示:
在kafka中,客户端与服务器之间的通信是通过简单、高效、与具体编程语言无关的TCP协议来进行的。协议具有版本号,并且保持了对旧版本的兼容,我们这里提供了多种语言实现的客户端:
-
Java
-
C/C++
-
Go
-
Python
-
Ruby
上面只列出一部分,其实对于目前大多数主流语言均有对应的客户端。
1.1 Topics与Logs
首先,我们来了解一下Kafka对数据流所提供的核心抽象——topic。
topic其实就是针对所发布数据的一种分类。在kafka中,topics可以被多方订阅,即一个topic可以有0个、1个或者多个consumers对其进行订阅。
对于每一个topic,kafka集群都维持着一个类似于如下的分区日志:
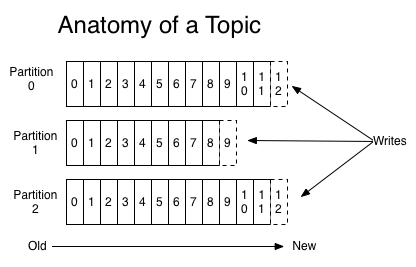
每一个partition都是一个有序、不可修改的记录序列,并且是以连续追加的方式保存到一个结构化的提交日志中。partitions中的每一条记录(record)都会被指定一个序列号,我们称之为offset,用于唯一的标识一个partition内的每一个每条记录(record)。
kafka集群会对producers所发布的记录(record)进行持久化: 可以通过配置一个保存周期,在该周期内,存储在kafka日志中的数据将不会丢失,而不论这些记录有没有被消费。例如,我们将持久化策略设置为2天,则在2天内这些记录均可被消费,到期之后则可能会被丢弃以释放相应的存储空间。kafka的性能与我们保存记录的多少没有关系,均是一个常量值,因此只要硬盘存储空间足够,我们可以对数据进行长期保存。
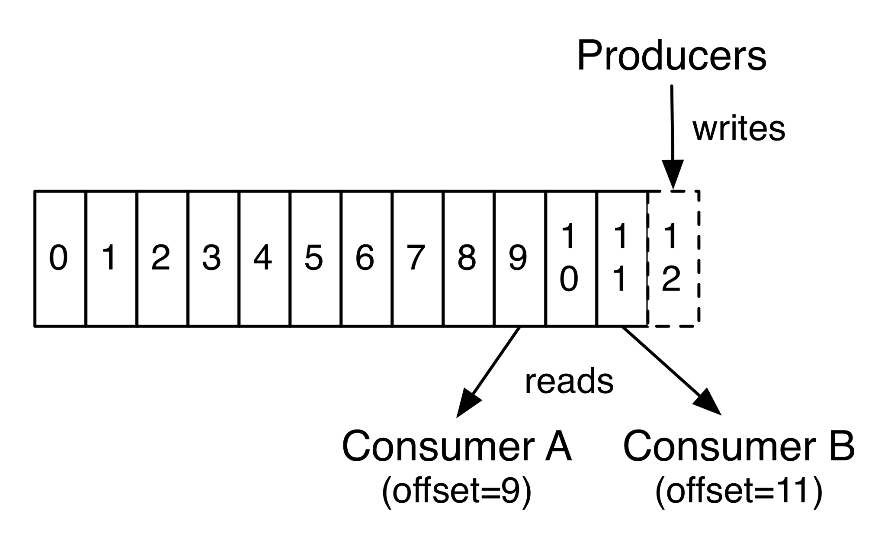 实际上,对于每一个consumer,唯一所保存的元数据就是其所消费的日志偏移(offset)。该偏移(offset)是由consumer来进行控制的:通常情况下,一个consumer在读取记录时将会线性的向前移动offset,但实际上,由于消费的偏移位置是由consumer所管理,因此其可以按任何想要的顺序来消费records。例如,一个consumer可以将offset重置到更旧的某个位置,这样其就可以对这些数据进行重新处理; 同样,一个consumer也可以将offset设置为最新,这样就可以跳过历史记录,从而只消费当前最新产生的消息。
实际上,对于每一个consumer,唯一所保存的元数据就是其所消费的日志偏移(offset)。该偏移(offset)是由consumer来进行控制的:通常情况下,一个consumer在读取记录时将会线性的向前移动offset,但实际上,由于消费的偏移位置是由consumer所管理,因此其可以按任何想要的顺序来消费records。例如,一个consumer可以将offset重置到更旧的某个位置,这样其就可以对这些数据进行重新处理; 同样,一个consumer也可以将offset设置为最新,这样就可以跳过历史记录,从而只消费当前最新产生的消息。
kafka的这些特性可以使得consumers十分轻便,可以在几乎不影响集群或其他consumers的情况下随意的加入或离开。例如,你可以使用我们所提供的命令行工具来tail任何topic的内容,而并不需要修改已被其他consumers所消费的消息偏移。
之所以在log中提供分区这一个概念有多个目的。首先,这样可使得日志以适当的大小分布于每一台单独的服务器上。每一个单独的分区必须匹配对其进行承载的服务器,一个topic可以有多个分区,因此其可以处理大量的数据。其次,partition也是作为并发处理的一个单元(unit),这一点我们后面再会详细介绍。
1.2 分布式(Distribution)
分区日志是分布在kafka集群服务器上的,每一台服务器都以共享分区的方式来处理数据及请求。每一个partition又可以设置相应的副本(replication)数,以提高系统的容错性。
每一个partition都有一台服务器充当leader,有0台或多台服务器充当followers。其中,leader服务器负责处理该partition的读写请求,而follower服务器只是被动的复制leader服务器上的数据。假如Leader失效,则其中一个follower将会自动的提升为leader。每一台服务器都作为某些分区的leader,同时也作为另外一些分区的follower,这样对于整个集群来说就可以达到基本的均衡。
这里要使数据基本均衡,还需适当安排分区数、副本数与kafka节点个数这三者之间的关系:
分区数: partitions 副本数: replicas kafka节点个数: cluster_nodes (partions * replicas) % cluster_node == 0
1.3 Geo-Replication
Kafka镜像工具MirrorMaker为集群提供了基于地理位置的副本解决方案(geo-replication)。通过使用MirrorMake,Kafka消息记录可以跨数据中心进行复制。在某些场景下,你可以使用此功能来完成数据的备份与恢复;或者通过此方式,将数据放在更靠近用户的地方;或者通过此来支持数据本地化需求。
1.4 生产者
Producers根据他们的需要将数据发布到相应的topics。数据具体要存放到topic内的哪一个partition是由Producer来进行选择的。我们可以通过简单的round-robin方式来实现基本的数据均衡,或者也可以通过某些hash函数来实现分区的选择。大多数情况下,我们使用方式2.
1.5 消费者
Consumers是通过consumer group name(消费组)来标识自己的,每一条发布到topic内的消息记录均会被消费组内的一个consumer所消费。消费者实例(consumer instances)可以是处于相同机器,也可以分布于不同机器。
假如所有的消费者都具有相同的consumer group(消费组),则消息记录将会均衡的发送给各个消费者。
假如所有的消费者都属于不同的消费组(consumer group),则每一条记录将会广播给所有消费者进程。
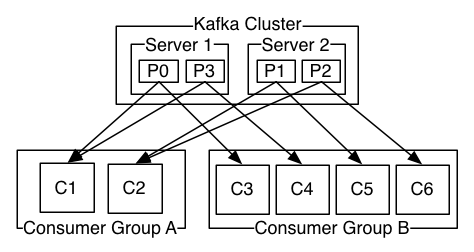
上图中,kafka有两个server节点,4个分区(P0~P3),两个消费组(consumer group)。其中,消费组A有两个consumer实例,消费组B有4个consumer实例。
更为常见的情况是,一个topic所拥有的消费组个数较少,经常是一个topic对应一个消费组。每一个消费组是由若干个consumer实例所组成,这样便于平行扩展以及提供高容错性。这其实就是普通的发布订阅,只不过这里的订阅者是一个结合,而不是单个进程。
在kafka中,消费者消费的实现方式是通过在log层面将partitions分开,以映射到不同的consumer实例,这样在任何时刻每一个consumer都独立的享有某个(些)partition。Kafka协议会动态的管理消费组中的consumer之间的关系。假如有一些新的consumer实例添加到消费组,那么它们可能就会从其他consumers那里接管一些partitions;而当某个consumer实例失效之后,其所对应的partitions又可能会被分配给剩余的consumer实例。
在一个partition内,kafka可以保证记录的有序性,而在不同partition之间是不能够保证的。因为通常我们都会采用hash(key)的方式来决定消息记录存放的partition,而每个partition内的消息记录又是有序的,这对大多数应用程序来说均能高效的满足需求。然而,假如你想获得一个全量有序的消息序列的话,你可以只采用一个topic,并且该topic只能有一个partition,但这样就意味着一个消费组只能有一个consumer进程。
1.6 多租户(multi-tenancy)
我们也可以将kafka部署为一个多租户解决方案。通过配置哪些topics可以produce数据、哪些topics可以consume数据来实现多租户的功能。另外,也可以支持限流操作。系统管理员可以定义并限制客户端请求所消耗的broker资源。
1.7 Guarantees
kafka从更高层面来说提供了如下保证:
-
producer发送到某个topic partition的消息将会按发送顺序追加到对应的日志文件。这就意味着,假如producer发送了两个消息M1、M2,M1先于M2发送,那么在对应的日志文件中,M1的offset会小于M2的offset
-
一个消费者实例所看到的消息记录顺序与该消息在日志中的顺序是一样的
-
对于一个副本数是N的topic,在不丢失任何已提交到日志中的消息记录的情况下,我们最多允许N-1个服务失效
1.8 Kafka作为消息系统
对比传统的企业消息系统,Kafka是如何理解数据流的呢?
通常,对于消息的处理有两种模型:队列模型(queuing)、发布订阅模型(publish-subscribe)。在队列模型中,若干个consumer可以从一台服务器读取消息记录,每一条消息记录会被其中一个consumer所读取;而在发布订阅模型中,消息记录会被广播给所有的consumers。两种模型各有优劣。队列模型的优点在于其允许将消息记录分给多个consumer来进行处理,这样就便于横向扩展提高系统的处理能力。然而队列模型并不支持多订阅者(multi-subscriber),因为一旦一个进程读取了消息队列中的数据,那么该消息就不能再被读了。而Publish-Subscribe允许将数据记录广播给多个进程,但通常不能进行横向扩展,因为每条消息都会被发送给每个订阅者。
在kafka中,消费组(consumer group)对这两个概念进行了抽象。类似于队列模型,在一个消费组内允许将消息记录拆分给不同的consumer进行处理;同样,也类似于publish-subscribe模型,kafka允许将消息广播给多个消费组。
kafka所采用的模型的优势在于,每一个topic同时具有两个特点:
-
支持横向扩展
-
支持multi-subscriber
此外,对比其他的传统消息系统,kafka具有强顺序性保证。
传统的队列在服务器上是按顺序保存着消息记录的,假如有多个consumer从队列中消费消息记录,则队列服务器会按记录的保存顺序将消息发送给consumer。尽管队列服务器按顺序将消息记录发送给consumer,但是由于消息记录是异步传送的,因此当到达consumers时就未必是有序的了。这就意味着有序的消息记录在并发消费的时候就丧失了顺序性。消息系统通常只允许一个消费者从队列中消费数据,但这就意味着丧失了并发处理能力。
kafka在这一点上做的比较好。通过在topic内这是partition来实现并发,kafka就能够同时提供顺序性保证并实现负载均衡。我们可以在消费组中为consumer指定partitions,这样就能确保一个partition只会被一个消费者所消费(注: 一个消费者可以同时消费多个partitions,但是一个partition只被一个consumer所消费)。通过这样,我们就确保了一个partition只被一个consumer所消费。由于我们可以设置多个分区,这样就确保了整个消费者实例之间的基本均衡。
注: 在一个消费组中,消费者的数量不能超过partitions的数目
1.8 kafka作为存储系统
任何队列消息系统都会将消息发布(publish)与消息消费(consume)分离开来,因为通常消息队列需要将处于in-flight状态的消息保存起来。kafka作为一个优秀的存储系统,这与传统的队列消息系统有什么区别呢?
写入到kafka中的数据最终会被写到硬盘,并且为了容错会复制到多个副本。kafka允许生产者在得到Leader写入完成并成功复制到Followers的确认之后,才认为数据写入成功。
kafka所记录的日志结构也便于横向扩展。不管是操作50KB大小的日志文件,还是操作50TB大小的日志文件,性能都基本持平。
由于存储消息大量占用硬盘空间,并且允许客户端控制读取位置,这样你就可以将kafka想象为某类具有特殊功能的分布式文件系统,其具有如下特点:
-
高效(high-performance)
-
低延时日志存储
-
多副本
-
良好扩展性
1.9 kafka作为流处理系统
不仅限于read、write以及存储数据流,kafka还能够对数据流进行实时处理。在kafka中,流处理器可以从input topics中不断获得输入的数据,然后进行某些处理,之后再将结果发布到output topics中。
例如,某个retail应用程序会从sales and shipments输入流中获得数据,然后将调整后的订单与价格再发布到另一个topic中。
我们可以直接使用producer与consumer APIs来做一些简单的数据处理,然而对于更复杂的转换的话,kafka提供了另一套完全集成的Streams API,这允许所构建的应用程序能够做一些更为特殊的处理,比如做多个数据流之间的聚合。
kafka所提供的流处理能力能够帮助应用程序解决相应的难题: 处理无序数据、预处理输入、进行状态计算等。
流处理API(streams API)是构建于kafka所构建的核心元语之上:其使用producer、consumer API来处理输入,使用kafka来做状态数据的存储,在流处理器实例之间使用相同的group机制来提供高容错性
[参考]
