kafka进阶_2
本章我们主要会介绍如下方面的内容:
-
kafka常用操作
-
kafka日志数据
-
kafka分区数的选择
-
kafka controller是什么?
1. kafka常用操作
如下我们列出一些kafka在实际生产系统中的基本用法。
1.1 基本操作
在本节我们列出操作kafka集群的一些常用操作,其中涉及到的所有工具(tools)都可以在kafka的bin/目录下找到,我们可以通过直接运行相应的命令(不要携带任何参数)来获得相应的详细信息。
添加topic
我们可以选择通过手动创建topic,或者在publish消息时对于不存在的topic让其自动创建。如果topics是自动创建的,我们也可以通过bin/kafka-topics.sh来调优默认的topic配置参数。
使用如下的命令来添加topic:
# bin/kafka-topics.sh --bootstrap-server broker_host:port --create --topic my_topic_name \
--partitions 20 --replication-factor 3 --config x=y
副本复制因子用于控制写入的消息会被复制多少份。假如我们将replication factor设置为3,则在最多2副本失效的情况下,仍能对数据进行正常访问。我们建议将replication factor设置为2或者3,这样当相应的服务器出现异常时,不会中断消费数据。
分区总数用于控制一个topic的消息数据会被shard到多少个logs当中。分区数的多少会产生多方面的影响。首先,每一个分区必须匹配一台服务器。因此假如我们有20个分区的话,则最多需要20台服务器来处理(这里不计算replicas);其次,分区数也会影响到consumer的最大并发能力。
每一个分区的日志文件都有其自己的目录。目录的名字是topicName-partitionID(例如,当前topic的名称是mytopic,partitionID为0,那么对一个的目录名称就是mytopic-0)。由于folder的名称长度不能超过255个字符,因此这也限制了topic name的长度。我们假设分区总数不会操作100000,那么topic name的长度不能长于255-6=249个字符。
通过命令行选项添加的参数配置会覆盖相应的默认值。针对每一个topic有哪些参数配置,可以参考这里.
修改topics
我们可以使用bin/kafka-topics.sh来修改topic的参数配置或者partition个数。例如,通过如下命令添加partition个数:
# bin/kafka-topics.sh --bootstrap-server broker_host:port --alter --topic my_topic_name \
--partitions 40
partitions的一个使用场景就是对数据进行分区,添加分区数并不会改变已有数据的分区,因此这可能会影响到一些依赖于分区的consumer。因为通常使用hash(key)%number_of_partitions算法来决定数据存放到哪个分区,但是kafka并不会尝试对已存在的数据重新做分区映射。
1) 添加configs
使用如下的命令来添加config:
# bin/kafka-configs.sh --bootstrap-server broker_host:port --entity-type topics --entity-name my_topic_name --alter --add-config x=y
2) 移除config
使用如下的命令来移除一个config:
# bin/kafka-configs.sh --bootstrap-server broker_host:port --entity-type topics --entity-name my_topic_name --alter --delete-config x
3) 删除topic
可以通过下面的命令来移除一个topic:
# bin/kafka-topics.sh --bootstrap-server broker_host:port --delete --topic my_topic_name
当前kafka并不支持减少topic的分区数。对于修改topic的副本复制因子,请参看这里
优雅的关闭
kafka集群会自动的侦测任何broker的关闭或者是失效,然后为相应的分区重新选举出新的leader。这在broker因故障失效,或者人为的主动关闭(如进行系统维护),或者配置修改均会触发相应的Leader选举动作。对于后面的一些场景(系统维护、配置修改),kafka支持一种更加优雅的机制来进行关闭,而不是直接将其kill掉。当kafka是被优雅的关闭时,其主要是做了如下两方面的优化:
-
主动的将日志数据同步到硬盘,以避免在进行重启时需要进行日志恢复(校验日志文件尾部的若干消息的checksum),从而可以提高系统的启动速度
-
在broker关闭之前,会迁移Leader是该broker的分区。这可以加快后续相应分区Leader的选举的速度,并降低相应分区处于不可用状态的时间。
无论broker是被优雅的关闭,还是直接kill,都会触发日志的同步。但是受控的Leadership迁移需要如下特殊设置:
controlled.shutdown.enable=true
值得注意的是,受控的关闭只在该broker有replicas(即副本数大于等于1,并且至少要有一个副本处于alive状态)的情况下才有效。
平衡leadership
无论什么时候一个broker关闭或者崩溃,如果某些partitions的leadership在该broker上,那么将会进行leadship转移。这就意味着在默认情况下,当broker重启,该broker只会成为相应分区的follower,从而不会在该broker上进行任何的读写操作。
为了避免这样导致的不平衡,kafka有一个首选副本的概念。假如某一个分区的副本列表是1、5、9,则node1会更被倾向于成为leader,因为node1排在整个副本列表的首位。你可以运行如下命令,尝试让kafka集群恢复leadership到原来的broker上:
# bin/kafka-preferred-replica-election.sh --zookeeper zk_host:port/chroot
由于每次运行此命名可能会十分繁琐,因此我们可以通过如下配置来让kafka自动的来完成:
auto.leader.rebalance.enable=true
跨rack平衡replicas
kafka的rack感知特性(rack awareness feature)分区的副本放到不同的rack上。此扩展保证了kafka能够应对因rack故障导致的broker失效问题,从而降低了数据丢失的风险。
你可以通过broker的配置参数指定broker是属于哪一个特定的rack:
broker.rack=my-rack-id
当创建、修改topic,或者replicas redistributed时,此rack参数的限制就会起作用,确保副本之间尽量分布到不同的rack上面。
kafka中为broker分配replicas的算法会确保每个broker的leader都会是一个常量,而不管broker的跨rack情况如何。这从整体上保证了集群的平衡。
然而,假如rack之间brokers数量是不相等的,则副本的指定将会是不平衡的。那些brokers数量更少的rack会有更多的replicas,这就意味着会在这些brokers上面存储更多的数据。因此,我们最好保证每个rack上都有相等的broker数量。
集群之间镜像(mirror)数据
为区分单个kafka集群broker节点之间的数据复制,这里我们将集群之间复制(replicate)数据的过程称为mirroring。kafka提供了一个相应的工具来在集群之间进行数据镜像,该工具会从source cluster消费数据,然后发布到destination cluster。这种数据镜像(mirror)的常见使用场景是:在其他的数据中保存一个副本。
我们可以运行多个镜像(mirror)进程来增加吞吐率和容错性(假如一个进程失效,则其他的进程将会接管相应的负载)。
kafka-mirror-maker.sh会从source cluster相应的topic中读取数据,然后将其写到destination cluster相同名称的topic中。实际上mirror maker相当于把consumer以及producer相应功能组合到了一起。
source及destination cluster是两个完全独立的entry: 两个集群可以有不同的partitions数量,offsets也会不同。 由于这样的原因,镜像(mirror)一个cluster其实并不能作为一个很好的容错机制,我们还是建议采用使用单个集群内的副本复制。mirror maker进程会使用相同的message key来映射分区,因此消息之间的整体排列还是不会被打乱。
如下我们给出一个示例展示如何mirror一个topic:
# bin/kafka-mirror-maker.sh
--consumer.config consumer.properties
--producer.config producer.properties --whitelist my-topic
上面我们注意到使用了--whitelist选项来指定topic列表,该选项允许使用任何java风格的正则表达式。因此你可以使用--whitelist 'A|B'来mirror topic A以及topic B。或者你也可以使用--whitelist '*'来mirror所有的topic。请使用单引号('')把正则表达式括起来,以免shell将其解释为文件路径。此外,为了使用方便我们允许使用,'来代替|用于指定多个topic。之后再配合使用auto.create.topics.enable=true,使得在Mirror数据时自动的进行topic数据创建.
检查consumer的消费偏移
有时候我们需要查看consumer的消费偏移信息。kafka提供了相应的工具来查看一个consumer group中所有consumers的消费信息。如下我们展示了如何查看查看my-group这个消费组中消费者的消费偏移:
# bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID my-topic 0 2 4 2 consumer-1-029af89c-873c-4751-a720-cefd41a669d6 /127.0.0.1 consumer-1 my-topic 1 2 3 1 consumer-1-029af89c-873c-4751-a720-cefd41a669d6 /127.0.0.1 consumer-1 my-topic 2 2 3 1 consumer-2-42c1abd4-e3b2-425d-a8bb-e1ea49b29bb2 /127.0.0.1 consumer-2
这里我们简单介绍一下如下几项:
-
CURRENT-OFFSET: consumer在一个分区的当前消费偏移
-
LOG-END-OFFSET: 一个分区的日志结束的偏移量
-
LAG: consumer消费消息时落后的偏移量(可以理解为未消费的记录条数)
如果想控制当前offset,需要注意的是这里面的消息消费过后可能超出了kafka日志留存策略,所以你只能控制到近期仍保留的日志偏移。可以执行如下命令:
# bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group your_consumer_group_name --topic your_topic_name --execute --reset-offsets --to-offset 80 # bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group your_consumper_group_name
管理consumer group
通过使用consumer group命令行工具,我们可以list、describe或者delete消费组。consumer group可以手工删除,或者是根据日志留存策略在过期后被自动删除。如果我们要手动删除,那就必须要保证该group当前已经没有活跃的成员(active members)了。通过如下命令,我们可以列出所有topic的消费组:
# bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list test-consumer-group
如果要查看消费偏移,我们可以describe消费组:
# bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID topic3 0 241019 395308 154289 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2 topic2 1 520678 803288 282610 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2 topic3 1 241018 398817 157799 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2 topic1 0 854144 855809 1665 consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1 topic2 0 460537 803290 342753 consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1 topic3 2 243655 398812 155157 consumer4-117fe4d3-c6c1-4178-8ee9-eb4a3954bee0 /127.0.0.1 consumer4
此外,针对describe还有其他一些额外的选项,可用于获得一个consumer group更为详细的信息:
1) --members选项
本选项用于获取一个consumer group中所有的active members。例如:
# bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group --members CONSUMER-ID HOST CLIENT-ID #PARTITIONS consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1 2 consumer4-117fe4d3-c6c1-4178-8ee9-eb4a3954bee0 /127.0.0.1 consumer4 1 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2 3 consumer3-ecea43e4-1f01-479f-8349-f9130b75d8ee /127.0.0.1 consumer3 0
上面显示consumer1当前正在消费两个分区,consumer4正在消费1个分区。
2) --members --verbose选项
在--members选项的基础上,本选项用于列出consumer正在消费哪些分区,例如:
# bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group --members --verbose CONSUMER-ID HOST CLIENT-ID #PARTITIONS ASSIGNMENT consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1 2 topic1(0), topic2(0) consumer4-117fe4d3-c6c1-4178-8ee9-eb4a3954bee0 /127.0.0.1 consumer4 1 topic3(2) consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2 3 topic2(1), topic3(0,1) consumer3-ecea43e4-1f01-479f-8349-f9130b75d8ee /127.0.0.1 consumer3 0 -
3) --offsets选项
这是默认的describe选项,提供的输出与--describe相同。
4) --state选项
本选项会提供一些有用的group级别的信息。例如:
# bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group --state COORDINATOR (ID) ASSIGNMENT-STRATEGY STATE #MEMBERS localhost:9092 (0) range Stable 4
5) --delete选项
要手动的删除一个或多个consumer group(s),我们可以使用--delete选项。例如:
# bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --group my-group --group my-other-group
Deletion of requested consumer groups ('my-group', 'my-other-group') was successful.
此外,如果想要重置一个consumer group的offsets,我们可以使用--reset-offsets选项。本选项只支持一次重置一个consumer group,在重置offsets时还需要指定作用域: --all-topics或--topic。另外,还需要确保在重置是consumer处于Inactive状态。
执行offsets重置时,有3个执行选项:
-
(default): 显示哪些offsets会被重置
-
--execute: 用于执行--reset-offsets进程 -
--export: 将结果导出为CSV格式
–reset-offsets可以通过如下方式来指定要重置到哪个位置:
--to-datetime <String: datetime>: 将offsets重置指定的日期。日期格式为'YYYY-MM-DDTHH:mm:SS.sss'
--to-earliest : 重置offsets到earliest
--to-latest: 重置offsets到latest
--shift-by <Long: number-of-offsets>: 将offsets重置为当前值+'n',这里'n'可以可以是正数也可以是负数
--from-file : 将offsets重置到CSV文件中指定的位置
--to-current: 将offsets重置到当前位置
--to-offset: 将offsets重置到一个指定的偏移值需要注意的是,如果要重置的offsets已经超出了当前可用的offset,那么就只会被重置为当前可用offset的结尾处。例如,假如offset end是10,我们使用offset shift请求来设置偏移到15,那么最后offset仍只能被重置为10。
如下我们给出一个示例,将一个consumer group的offsets重置为latest:
# bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --reset-offsets --group consumergroup1 --topic topic1 --to-latest TOPIC PARTITION NEW-OFFSET topic1 0 0
假如你使用的是较老版本的kafka,那么consumer的消费偏移信息可能存放在zookeeper中,此时你可以传递--zookeeper参数而不是--bootstrap-server参数:
# bin/kafka-consumer-groups.sh --zookeeper localhost:2181 --list
2. kafka日志数据
3. 如何确定kafka分区数
3.1 kafka分区数是不是越多越好?
分区多的优点
kafka使用分区将topic的消息打散到多个分区分布保存在不同的broker上,实现了producer和consumer消息处理的高吞吐量。kafka的producer和consumer都可以多线程地并行操作,而每个线程处理的是一个分区的数据。因此分区实际上是调优kafka并行度的最小单元。对于producer而言,它实际上是用多个线程并发地向不同分区所在的broker发起socket连接同时给这些分区发送消息; 而consumer,同一个消费组内所有consumer线程都被指定topic的某一个分区进行进行消费。
所以说,如果一个topic分区越多,理论上整个集群所能达到的吞吐量就越大。
分区不是越多越好
分区是否越多越好呢?显然也不是,每个分区都有自己的开销:
1) 客户端/服务器端内存开销
kafka 0.8.2之后,在客户端producer有个参数batch.size,默认是16KB。它会为每个分区缓存消息,一旦满了就打包将消息批量发送出去。看上去这是个能够提升性能的设计。不过很显然,因为这个参数是分区级别的,如果分区数越多,这部分缓存所需的内存占用也会更多。假设你有10000个分区,按照默认设置,这部分缓存需要占用约157MB的内存。而consumer端呢?我们抛开获取数据所需的内存不说,只说线程的开销。如果还是假设10000个分区,同时consumer线程数要匹配分区数(注: 大部分情况下,这是最佳的消费吞吐量配置)的话,那么consumer client就需要创建10000个线程,也需要大约10000个socket去获取分区数据。这里面线程切换的开销本身就已经不容小觑了。
服务端的开销也不小,如果阅读kafka源码的话可以发现,服务端的很多组件都在内存中维护了分区级别的缓存,比如controller,FetcherManager等,因此分区数越多,这种缓存的成本就越大。
2) 文件句柄的开销
每个分区在底层文件系统都有属于自己的一个目录。该目录下通常会有两个文件:base_offset.log和base_offset.index。kafka的controller和ReplicaManager会为每个broker都保存这两个句柄。很明显,如果分区数越多,所需要保持打开状态的文件句柄数也就越多,最终可能会突破你的ulimit -n的限制。
3) 降低高可用性
kafka通过副本(replica)机制来保证高可用。具体做法就是为每个分区保存若干个副本(replica_factor指定副本数)。每个副本保存在不同的broker上,其中的一个副本充当leader,负责处理producer和consumer的读写请求; 其他副本充当follower角色,由kafka controller负责保证与leader的同步。如果leader所在的broker挂掉了,controller会检测到然后在zookeeper的帮助下重新选出新的leader———这中间会有短暂的不可用时间窗口,虽然大部分情况下可能只是几毫秒级别。但如果你有10000个分区,10个broker,也就是说每个broker上有1000个分区。此时这个broker挂掉了,那么zookeeper和controller需要立即对这1000个分区进行Leader选举。比起很少的分区Leader选举而言,这必然要花更长的时间,并且通常不是线性累加的。如果这个broker同时还是controller,情况就更糟了。
如何确定分区数量
可以遵循一定的步骤来尝试确定分区数: 创建一个只有一个分区的topic,然后测试这个topic的producer吞吐量和consumer吞吐量。假设它们的值分别是Tp和Tc,单位可以是MB/s。然后假设总的目标吞吐量是Tt,那么分区数是: p = Tt/max(Tp, Tc)。
说明:Tp表示producer的吞吐量。测试producer通常是很容易的,因为它的逻辑非常简单,就是直接发送消息到kafka就好了。Tc表示consumer的吞吐量,测试Tc通常与应用的关系更大,因为Tc的值取决于你拿到消息之后执行什么操作,因此Tc的测试也要更麻烦些。
3.2 消息被发送到哪个分区?
一条消息要被发送到哪个partition,通常是按如下方式来进行处理的:
1) 按照key值分配
默认情况下,kafka根据传递消息的key来进行分区的分配,即hash(key)%numPartitions:
def partition(key: Any, numPartitions: Int): Int = {
Utils.abs(key.hashCode) % numPartitions
}这保证了相同key的消息一定会被路由到相同的分区。
2) key为null时,从缓存中取分区ID或者随机取一个
如果你没有指定key,那么kafka是如何确定这条消息去往哪个分区的呢?
if(key == null) {
val id = sendPartitionPerTopicCache.get(topic) // 先看看Kafka有没有缓存的现成的分区Id
id match {
case Some(partitionId) => // 如果有的话直接使用这个分区Id就好了
partitionId
case None => // 如果没有的话,
val availablePartitions = topicPartitionList.filter(_.leaderBrokerIdOpt.isDefined) //找出所有可用分区的leader所在的broker
if (availablePartitions.isEmpty)
throw new LeaderNotAvailableException("No leader for any partition in topic " + topic)
val index = Utils.abs(Random.nextInt) % availablePartitions.size // 从中随机挑一个
val partitionId = availablePartitions(index).partitionId
sendPartitionPerTopicCache.put(topic, partitionId) // 更新缓存以备下一次直接使用
partitionId
}
}不指定key时,kafka几乎就是随机找一个分区发送无key的消息,然后把这个分区号加入到缓存中以备后面直接使用。当然了,kafka本身也会清空该缓存(默认每10分钟或者每次请求topic元数据时)。
3.3 consumer个数与分区数
topic下的一个分区只能被同一个consumer group下的一个consumer线程来消费,但反之并不成立,即一个consumer线程可以消费多个分区的数据,比如kafka提供的ConsoleConsumer,默认就只是一个线程来消费所有分区的数据。
即分区数决定了同组消费者个数的上限
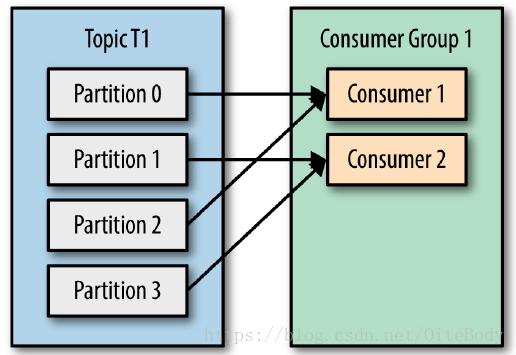
所以,如果你的分区数是N,那么最好线程数也保持为N,这样通常能够达到最大的吞吐量。超过N的配置只是浪费系统资源,因为多出的线程不会被分配到任何分区。
Consumer消费partition的分配策略
kafka提供了两种分配策略: range和round robin,由参数partition.assignment.strategy指定,默认是range策略。
当以下事件发生时,kafka将会进行一次分区分配:
-
同一个Consumer Group内新增消费者
-
消费者离开当前所属的Consumer Group,包括shutdown 或 crash
-
订阅的主题新增分区
将分区的所有权从一个消费者移动到另一个消费者,称为重新平衡(rebalance)。如何rebalance就涉及到本文提到的分区分配策略。
下文我们将详细介绍kafka内置的两种分区分配策略。本文假设我们有个名为T1的topic,其中包含了10个分区,然后我们有两个消费者(C1,C2)来消费这10个分区里面的数据,而且C1的num.streams=1, C2的num.streams=2。
1) Range strategy
range策略是对每个topic而言的,首先对同一个topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。在我们的例子里面,排完序的分区将会使0,1,2,3,4,5,6,7,8,9; 消费者线程排完序将会是C1-0,C2-0,C2-1。然后将partitions的个数除以消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,前面几个消费者线程将会多消费一个分区。在我们的例子里面,我们有10个分区,3个消费者线程,10/3=3,而且除不尽,那么消费者线程C1-0将会多消费一个分区,随意最后分区分配的结果看起来是这样的:
-
C1-0将消费0,1,2,3分区
-
C2-0将消费4,5,6分区
-
C2-1将消费7,8,9分区
假如我们有11个分区,那么最后分区分配的结果看起来是这样的:
-
C1-0将消费0,1,2,3分区
-
C2-0将消费4,5,6,7分区
-
C2-1将消费8,9,10分区
假如我们有两个topic(名称分别为T1和T2),分别有10个分区,那么最后分区分配的结果看起来是这样的:
-
C1-0将消费T1这个topic的0,1,2,3分区; C1-0将消费T2这个topic的0,1,2,3分区
-
C2-0将消费T1这个topic的4,5,6分区; C2-0将消费T2这个topic的4,5,6分区
-
C2-1将消费T1这个topic的7,8,9分区; C2-1将消费T2这个topic的7,8,9分区
可以看出,C1-0这个消费者线程比其他消费者线程多消费了2个分区,这就是range strategy的一个很明显的弊端。
2) RoundRobin strategy
使用roundrobin策略有两个前提条件必须满足:
-
同一个consumer group里面的所有消费者的num.streams必须相等;
-
每个消费者订阅的topic必须相同
所以这里假设前面提到的两个消费者的num.streams=2。Roundrobin策略的工作原理:将所有topic的分区组成TopicAndPartion列表,然后对TopicAndPartition列表按照hashCode进行排序,参看如下代码:
val allTopicPartitions = ctx.partitionsForTopic.flatMap { case(topic, partitions) =>
info("Consumer %s rebalancing the following partitions for topic %s: %s"
.format(ctx.consumerId, topic, partitions))
partitions.map(partition => {
TopicAndPartition(topic, partition)
})
}.toSeq.sortWith((topicPartition1, topicPartition2) => {
/*
* Randomize the order by taking the hashcode to reduce the likelihood of all partitions of a given topic ending
* up on one consumer (if it has a high enough stream count).
*/
topicPartition1.toString.hashCode < topicPartition2.toString.hashCode
})最后按照round-robin风格将分区分别分配给不同的消费者线程。
在这个例子里面,假如按照hashCode排完序的topic-partitions组依次为:T1-5、T1-3、T1-0、T1-8、T1-2、T1-1、T1-4、T1-7、T1-6、T1-9,我们的消费者线程排序为C1-0、C1-1、C2-0、C2-1,最后分区分配的结果为:
-
C1-0将消费T1-5、T1-2、T1-6分区;
-
C1-1将消费T1-3、T1-1、T1-9分区;
-
C2-0将消费T1-0、T1-4分区
-
C2-1将消费T1-8、T1-7分区
多个topic的分区分配和单个topic类似。遗憾的是,目前我们还不能自定义分区分配策略,只能通过partition.assignment.strategy参数选择range或round-robin。
4. kafka controller
本节描述一下kafka controller的实现原理,并对其源代码的实现进行讲解。
4.1 controller运行原理
在kafka集群中,controller是多个broker中的一个(也只有一个controller)。它除了实现了正常的broker功能外,还负责选举分区(partition)的Leader。第一个启动的broker会成为一个controller,它会在zookeeper创建一个临时节点(ephemeral): /controller。其他后启动的broker也尝试去创建这样一个临时节点,但会报错,此时这些broker会在该zookeeper的/controller节点上创建一个监控(watch),这样当该节点状态发生变化(比如: 被删除)时,这些broker就会得到通知。此时,这些broker就可以在得到通知时,继续创建该节点。保证该集群一直都有一个controller节点。
当controller所在的broker节点宕机或断开和zookeeper的连接,它在zookeeper上创建的临时节点就会被自动删除。其他在该节点上都安装了监控的broker节点都会得到通知,此时,这些broker都会尝试去创建这样一个临时的/controller节点,但它们当中只有一个broker(最先创建的那个)能够创建成功,其他的broker会报错:node already exists,接收到该错误的broker节点会再次在该临时节点上安装一个watch来监控该节点状态的变化。每次当一个broker被选举时,将会赋予一个更大的数字(通过zookeeper的条件递增实现),这样其他节点就知道controller目前的数字。
当一个broker宕机而不在当前kafka集群中时,controller将会得到通知(通过监控zookeeper的路径实现),若有些topic的主分区恰好在该broker上,此时controller将重新选择这些主分区。controller将会检查所有没有leader的分区,并决定新的leader是谁(简单的方法是: 选择该分区的下一个副本分区),并给所有的broker发送请求。
每个分区的新的Leader知道,它将接收来自客户端的生产者和消费者的请求。同时follower也知道,应该从这个新的leader开始复制消息。当一个新的broker节点加入集群时,controller将会检查,在该broker上是否存在分区副本。若存在,controller通知新的和存在的broker这个变化,该broker开始从leader处复制消息。
总的来说,kafka会通过在zookeeper上创建临时节点的方式来选举一个controller,当kafka集群中有节点加入或退出时,该controller将会得到通知。Controller还负责在多个分区中选择主分区,负责当有节点加入集群时进行副本的复制。Controller通过递增数字(epoch number)来防止脑裂(split brain)问题。
脑裂是指: 多个节点都选自己为controller
4.2 实现分析
Controller是通过事件处理机制来实现的。把broker的节点的变化、分区的变化,都封装成事件,事件发生时把事件放入到事件队列中。此时,阻塞在事件队列的处理者即可开始处理这些事件。这些事件类,都必须实现同一个接口。
启动
类KafkaServer中的startup()函数中启动Controller,代码如下:
def startup() {
...
/* start kafka controller */
kafkaController = new KafkaController(config, zkClient, time, metrics, brokerInfo, tokenManager, threadNamePrefix)
// 启动kafka server的控制模块
kafkaController.startup()
...
}初始化工作
kafka服务节点启动时,Controller模块就会启动。但当Controller启动时,并不会假设自己是controller,而是先注册会话超时的监听者(listener),然后开始controller的leader选举过程。
启动时,会把Startup事件控制实体,放入到事件队列中。在eventManager线程启动时,会在队列取出ControllerEvent类型的事件,并进行处理。此时取出的当然是刚刚放入的Startup事件,所以,开始执行Startup类的process函数。代码实现如下:
def startup() = {
... ...
eventManager.put(Startup)
eventManager.start()
}- Startup事件控制实体
在Controller模块启动时,该事件就被放入到事件队列中,所以最开始处理该事件。执行的处理函数是下面定义的process()。代码实现如下:
case object Startup extends ControllerEvent {
def state = ControllerState.ControllerChange
override def process(): Unit = {
zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)
elect()
}
}Startup事件处理
private def elect(): Unit = {
val timestamp = time.milliseconds
activeControllerId = zkClient.getControllerId.getOrElse(-1)
// 这里要判断一下controller是否已经选出来了,若是选出来了,就不需要再继续选举
if (activeControllerId != -1) {
debug(s"Broker $activeControllerId has been elected as the controller, so stopping the election process.")
return
}
// 若controller还没有选出来,则进行选举
try {
// 若成功的选举成controller,继续进行后面的注册,否则抛出异常
zkClient.checkedEphemeralCreate(ControllerZNode.path, ControllerZNode.encode(config.brokerId, timestamp))
info(s"${config.brokerId} successfully elected as the controller")
// 自己被选举成controller,进入onControllerFailover函数
activeControllerId = config.brokerId
onControllerFailover()
} catch {
case _: NodeExistsException =>
// If someone else has written the path, then
activeControllerId = zkClient.getControllerId.getOrElse(-1)
... ...
}
}被选举成controller之后
当broker被选举成为controller之后,继续执行后面的代码,此时进入onControllerFailover()函数。该函数主要完成以下几件事:
-
注册constroller epoch(controller id)变化的监听器
-
增加controller的id
-
初始化controller的context,该context保存了每个topic的信息,和所有分区的leader信息
-
开启controller的channel管理模块
-
开启副本状态机
-
开启分区状态机
-
当该broker发生任何异常,会重新选择controller,这样其他的broker节点也有可能成为controller
[参考]
