kafka数据迁移(转)
本文重点介绍kafka的两类常见数据迁移方式:
-
broker内部不同数据盘之间的分区数据迁移
-
不同broker之间的分区数据迁移
1. broker内部不同数据盘之间的分区数据迁移
1.1 背景介绍
最近,腾讯云的一个重要客户发现kafka broker内部的topic分区数据存储分布不均匀,导致部分磁盘100%耗尽,而部分磁盘只有40%的消耗量。
分析原因,发现存在部分topic的分区数据过于集中在某些磁盘导致,比如,以下截图显示的/data5数据盘:
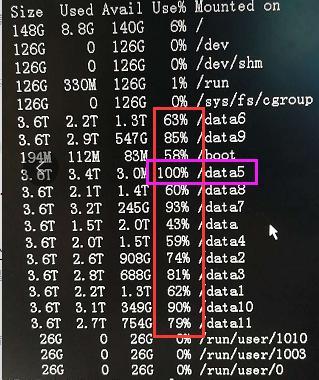
根据分布式系统的特点,很容易想到采取数据迁移的办法,对broker内部不同数据盘的分区数据进行迁移。在进行线上集群数据迁移之前,为了保证集群的数据完整和安全,必须先在测试集群进行测试。
1.2 测试broker内部不同数据盘进行分区数据迁移
1) 建立测试topic并验证生产和消费正常
我们搭建的测试集群,kafka有3个broker,hostname分别为:
-
tbds-172-16-16-11
-
tbds-172-16-16-12
-
tbds-172-16-16-16
每个broker配置了两块数据盘,缓存数据分别存储在/data/kafka-logs/和/data1/kafka-logs/。
首先建立测试topic:
# ./kafka-topics.sh --create --zookeeper tbds-172-16-16-11:2181 --replication-factor 2 --partitions 3 --topic test_topic
然后向topic生产发送500条数据,发送的时候也同时消费数据。然后查看topic的分区数据情况:
# ./kafka-consumer-groups.sh --zookeeper tbds-172-16-16-11:2181 --describe --group groupid1 GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER groupid1 test_topic 0 172 172 0 kafka-python-1.3.1_tbds-172-16-16-3/172.16.16.3 groupid1 test_topic 1 156 156 0 kafka-python-1.3.1_tbds-172-16-16-3/172.16.16.3 groupid1 test_topic 2 172 172 0 kafka-python-1.3.1_tbds-172-16-16-3/172.16.16.3
发现test_topic生产和消费数据都正常。
2) 将分区数据在磁盘间进行迁移
现在登录tbds-172-16-16-12这台broker节点,将test_topic的分区数据目录/data1/kafka-logs/test_topic-0/移动到/data/kafka-logs/目录:
# mv /data1/kafka-logs/test_topic-0 /data/kafka-logs/
查看/data/kafka-logs/目录下,分区test_topic-0的数据:
# pwd /data/kafka-logs/test_topic-0 # ll total 28 -rw-r--r-- 1 kafka hadoop 10485760 Jan 18 15:28 000000000000000000000.index -rw-r--r-- 1 kafka hadoop 21065 Jan 18 15:26 000000000000000000000.log
3) 再次对测试topic生产和消费数据
再次发送500条数据,同时消费数据,然后查看数据状况:
# ./kafka-consumer-groups.sh --zookeeper tbds-172-16-16-11:2181 --describe --group groupid1 GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER groupid1 test_topic 0 337 337 0 kafka-python-1.3.1_tbds-172-16-16-3/172.16.16.3 groupid1 test_topic 1 304 304 0 kafka-python-1.3.1_tbds-172-16-16-3/172.16.16.3 groupid1 test_topic 2 359 359 0 kafka-python-1.3.1_tbds-172-16-16-3/172.16.16.3
再次查看tbds-172-16-16-12这个broker节点的/data/kafka-logs/test_topic-0分区目录下的数据:
# pwd /data/kafka-logs/test_topic-0 # ll total 28 -rw-r--r-- 1 kafka hadoop 10485760 Jan 18 15:28 000000000000000000000.index -rw-r--r-- 1 kafka hadoop 21065 Jan 18 15:26 000000000000000000000.log
发现,从/data1/kafka-logs/移动到/data/kafka-logs/目录下的分区数据目录test_topic-0(也就是编号为0的分区)缓存数据并没有增加。
这是因为test_topic每个分区有两个replicas,因此,我们找到编号为0的另外一个分区replica数据存储在tbds-172-16-16-16这个broker节点。登陆tbds-172-16-16-16这个broker节点,打开编号为0的分区缓存数据目录,得到如下信息:
# pwd /data1/kafka-logs/test_topic-0 # ll total 48 -rw-r--r-- 1 kafka hadoop 10485760 Jan 18 15:37 000000000000000000000.index -rw-r--r-- 1 kafka hadoop 40801 Jan 18 15:38 000000000000000000000.log
上面我们看到log文件的大小发生了改变,即tbds-172-16-16-16这台broker节点的分区数据目录test_topic-0内缓存数据量是增加的,也就是缓存有再次生产发送的message数据。
由此可见,经过移动之后的tbds-172-16-16-12这台broker节点的编号为0的分区数据缓存目录内,并没有新增缓存数据。与之对应的,没有做分区数据移动操作的tbds-172-16-16-16这台broker节点的编号为0的分区缓存数据目录内新增再次发送的数据。
是不是意味着不能在broker的磁盘间移动分区数据呢?
4) 调用重启大法:重启kafka
重启kafka集群,重启完成后,发现tbds-172-16-16-12这台broker节点的编号为0的分区缓存数据目录内的数据也增加到正常水平:
# pwd /data/kafka-logs/test_topic-0 # ll total 44 -rw-r--r-- 1 kafka hadoop 10485760 Jan 18 15:44 000000000000000000000.index -rw-r--r-- 1 kafka hadoop 40801 Jan 18 15:44 000000000000000000000.log
表明重启之后,broker的不同磁盘间迁移数据已经生效。
5) 验证磁盘间迁移分区数据生效
再次向test_topic-0发送500条数据,同时消费数据,然后查看数据情况:
# ./kafka-consumer-groups.sh --zookeeper tbds-172-16-16-11:2181 --describe --group groupid1 GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER groupid1 test_topic 0 521 521 0 kafka-python-1.3.1_tbds-172-16-16-3/172.16.16.3 groupid1 test_topic 1 468 468 0 kafka-python-1.3.1_tbds-172-16-16-3/172.16.16.3 groupid1 test_topic 2 511 511 0 kafka-python-1.3.1_tbds-172-16-16-3/172.16.16.3
查看tbds-172-16-16-12这个个broker节点的test_topic-0分区数据的缓存目录:
# pwd /data/kafka-logs/test_topic-0 # ll total 72 -rw-r--r-- 1 kafka hadoop 10485760 Jan 18 15:53 000000000000000000000.index -rw-r--r-- 1 kafka hadoop 63283 Jan 18 15:53 000000000000000000000.log
查看tbds-172-16-16-16这个个broker节点的test_topic-0分区数据的缓存目录:
# pwd /data1/kafka-logs/test_topic-0 # ll total 72 -rw-r--r-- 1 kafka hadoop 10485760 Jan 18 15:53 000000000000000000000.index -rw-r--r-- 1 kafka hadoop 63283 Jan 18 15:53 000000000000000000000.log
发现两个replicas完全一样。
1.3 结论
kafka broker内部不同数据盘之间可以自由迁移分区数据目录。迁移完成后,重启kafka即可生效。
2. 不同broker之间传输分区数据
当对kafka集群进行扩容之后,由于新扩容的broker没有缓存数据,容易造成系统的数据分布不均匀。因此,需要将原来集群broker的分区数据迁移到新扩容的broker节点。
不同broker之间传输分区数据,可以使用kafka自带的kafka-reassign-partitions.sh脚本工具实现。
我们在kafka测试集群原有的3台broker基础上,扩容一台broker。
2.1 获取test_topic的分区分布情况
执行如下命令:
# ./kafka-topics.sh --zookeeper 172.16.16.11:2181 --topic test_topic --describe Topic:test_topic PartitionCount:3 ReplicationFactor:2 Configs: Topic: test_topic Partition: 0 Leader: 1002 Replicas: 1002,1001 Isr: 1002,1001 Topic: test_topic Partition: 1 Leader: 1003 Replicas: 1003,1002 Isr: 1003,1002 Topic: test_topic Partition: 2 Leader: 1001 Replicas: 1001,1003 Isr: 1001,1003
从上面我们看到,test_topic的3个分区(每个分区2个replicas)在三个broker节点上的分布情况。
2.2 获取topic重新分区的配额文件
编写分配脚本move_kafka_topic.json,内容如下:
{"topics": [{"topic": "test_topic"}], "version": 1}接着执行分配计划生成脚本:
# ./kafka-reassign-partitions.sh --zookeeper tbds-172-16-16-11:2181 --topics-to-move-json-file /tmp/move_kafka_topic.json --broker-list "1001,1002,1003,1004" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test_topic","partition":0,"replicas":[1002,1001]},{"topic":"test_topic","partition":2,"replicas":[1001,1003]},{"topic":"test_topic","partition":1,"replicas":[1003,1002]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"test_topic","partition":0,"replicas":[1001,1002]},{"topic":"test_topic","partition":2,"replicas":[1003,1004]},{"topic":"test_topic","partition":1,"replicas":[1002,1003]}]}
上面命令里的broker-list填写kafka集群4个broker的id。不同kafka集群,因为部署方式不一样,选择的broker id也不一样。我们的测试集群broker id是1001、1002、1003、1004。读者需要根据自己的kafka集群设置的broker id填写。
下面我们对上面的结果稍加整理:
Current partition replica assignment //当前分区的副本分配
{
"version": 1,
"partitions": [{
"topic": "test_topic",
"partition": 0,
"replicas": [1002, 1001]
}, {
"topic": "test_topic",
"partition": 2,
"replicas": [1001, 1003]
}, {
"topic": "test_topic",
"partition": 1,
"replicas": [1003, 1002]
}]
}
Proposed partition reassignment configuration //建议的分区配置
{
"version": 1,
"partitions": [{
"topic": "test_topic",
"partition": 0,
"replicas": [1001, 1002]
}, {
"topic": "test_topic",
"partition": 2,
"replicas": [1003, 1004]
}, {
"topic": "test_topic",
"partition": 1,
"replicas": [1002, 1003]
}]
}Proposed partition reassignment configuration后是根据命令行指定的broker list生成的分区分配计划json格式。将Proposed partition reassignment configuration的配置复制到一个文件中move_kafka_topic_result.json:
# cat ./move_kafka_topic_result.json
{"version":1,"partitions":[{"topic":"test_topic","partition":0,"replicas":[1001,1002]},{"topic":"test_topic","partition":2,"replicas":[1003,1004]},{"topic":"test_topic","partition":1,"replicas":[1002,1003]}]}2.3 对topic分区数据进行重新分布
执行重新分配命令:
# ./kafka-reassign-partitions.sh --zookeeper tbds-172-16-16-11:2181 --reassignment-json-file /tmp/move_kafka_topic_result.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test_topic","partition":0,"replicas":[1002,1001]},{"topic":"test_topic","partition":2,"replicas":[1001,1003]},{"topic":"test_topic","partition":1,"replicas":[1003,1002]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions {"version":1,"partitions":[{"topic":"test_topic","partition":0,"replicas":[1001,1002]},{"topic":"test_topic","partition":2,"replicas":[1003,1004]},{"topic":"test_topic","partition":1,"replicas":[1002,1003]}]}
从上面的返回结果来看,分区数据重新分布任务已经启动成功。
2.4 查看分区数据重新分布进度
查看分配的状态,执行如下命令:
# ./kafka-reassign-partitions.sh --zookeeper tbds-172-16-16-11:2181 --reassignment-json-file /tmp/move_kafka_topic_result.json --verify Status of partition reassignment: Reassignment of partition [test_topic,0] completed successfully Reassignment of partition [test_topic,2] completed successfully Reassignment of partition [test_topic,1] completed successfully
从上面我们看到分区数据重新分布任务已经完成。
2.5 再次获取test_topic的分区分布情况
再次查看各个分区的分布情况,执行如下命令:
# ./kafka-topics.sh --zookeeper 172.16.16.11:2181 --topic test_topic --describe Topic:test_topic PartitionCount:3 ReplicationFactor:2 Configs: Topic: test_topic Partition: 0 Leader: 1002 Replicas: 1001,1002 Isr: 1002,1001 Topic: test_topic Partition: 1 Leader: 1003 Replicas: 1002,1003 Isr: 1003,1002 Topic: test_topic Partition: 2 Leader: 1003 Replicas: 1003,1004 Isr: 1003,1004
从上面我们可以看出,test_topic的分区数据已经由原来的3个broker,重新分布到4个broker。
3. 测试结论
-
kafka broker内部不同数据盘之间可以自由迁移分区数据目录。迁移完成后,重启kafka即可生效;
-
kafka 不同broker之间可以迁移数据,使用kafka自带的kafka-reassign-partitions.sh脚本工具实现
4. 修复客户的kafka集群故障
我们采用本文测试的方法,对该客户的kafka集群进行broker节点内部不同磁盘间的数据迁移,对多个topic均进行了迁移,最终实现磁盘间数据缓存分布均匀化。
同时,我们又对客户kafka集群进行扩容,扩容之后采用本文描述的不同broker之间迁移分区数据方法,对多个topic均进行了数据迁移,保证新扩容节点也有缓存数据,原来的broker节点存储压力减小。
[参考]
