phxpaxos源码分析: 归档机制
Paxos协议是分布式系统设计中的一个非常重要的协议,本文转载自微信后台团队公众号团队所发表一系列Paxos的文章,中间针对自己的理解略有修改或注释。在此处做一个备份,一方面为了加深对Paxos协议的理解,另一方面也方便自己的后续查找,防止文章丢失。
1. 基本概念
上一章我们讲解了PhxPaxos的状态机,各种场景下可以定制不同的状态机,每个状态机独立消费一个paxos log以驱动业务状态变更。
状态机消费完paxos log之后,paxos log是否可以删除呢?答案是不行。有如下几个原因:
-
某些paxos节点可能由于网络等原因落后于其他节点,需要学习现有的paxos log;
-
业务消费完paxos log之后,可能由于重启等原因出现数据丢失,需要通过paxos log做重放(replay)
那什么时候可以删除paxos log呢?答案是不知道。因为某个节点可能永远处于离线状态,这时候必须保留从最初到现在所有的paxos log。但另一方面,如果数据不删除将无限增长,这是无法忍受的。
PhxPaxos因此引入了Checkpoint机制,关于该机制的详细描述请参见《状态机Checkpoint详解》,这里简要说明如下:
1) 一个Checkpoint代表着一份某一时刻被固化下来的状态机数据,它通过sm.h下的StateMachine::GetCheckpointInstanceID()函数反馈它的精确时刻;
2) 每次启动replay时,只需要从GetCheckpointInstanceID()所指向的paxos log位置开始,而不是从0开始;
3) Node::SetHoldPaxosLogCount()控制需要保留多少在StateMachine::GetCheckpointInstanceID()之前的paxos log
4) 保留一定数量的paxos log的目的在于,如果其他节点数据不对齐,可以通过保留的这部分paxos log完成对齐,而不需要checkpoint数据介入;
5) 如果对齐数据已被删除,这时需要Checkpoint数据传输;
2. 代码设计
Checkpoint机制相关类图如下:
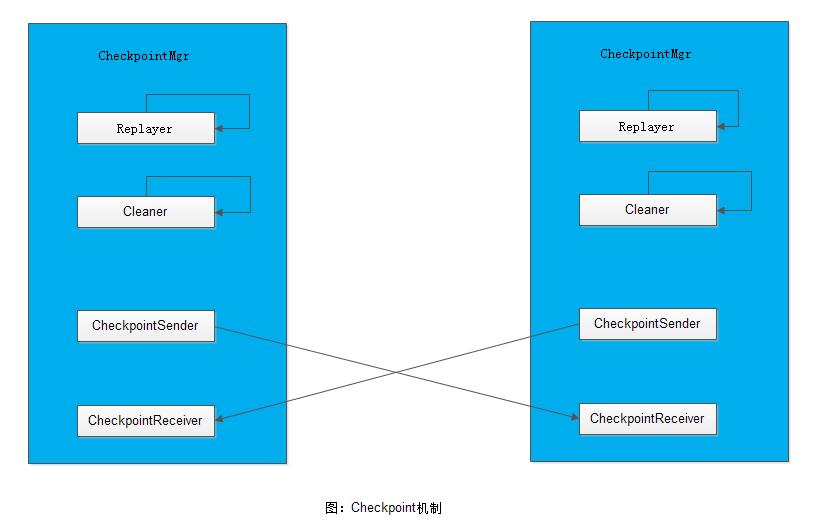
参照上一节讲的功能及类图补充说明如下:
-
Replayer: replay线程。当业务状态机已经消费指定paxos log后,交由Checkpoint重新执行。由Checkpoint relay的数据允许被删除
-
Cleaner: paxos log清理线程,根据配置的保留条数等清理paxos log
-
CheckpointSender: 归档数据发送线程。将归档数据发往其他节点,用于归档数据同步。
-
CheckpointReceiver: 归档数据接收器。接收其他节点发送过来的归档数据。通常归档数据接收完成之后,就会调用Learner::OnSendCheckpoint_End(),之后要求我们LoadCheckpointState()
-
CheckpointMgr: Checkpoint机制管理器,统一管理整个归档机制。
3. 状态机(StateMachine)
再来看StateMachine接口,这次我们重点关注Checkpoint相关接口:
class StateMachine
{
public:
virtual const uint64_t GetCheckpointInstanceID(const int iGroupIdx) const;
virtual int LockCheckpointState();
virtual int GetCheckpointState(const int iGroupIdx, std::string& sDirPath,
std::vector<std::string>& vecFileList);
virtual void UnLockCheckpointState();
virtual int LoadCheckpointState(const int iGroupIdx, const std::string& sCheckpointTmpFileDirPath,
const std::vector<std::string>& vecFileList, const uint64_t llCheckpointInstanceID);
virtual bool ExecuteForCheckpoint(const int iGroupIdx, const uint64_t llInstanceID,
const std::string& sPaxosValue);
};接口说明如下:
-
GetCheckpointInstanceID(): Checkpoint所指向的最大InstanceID,在此之前的paxos log数据状态机已经不需要了。但通常为了其他节点的数据对齐需要,我们仍然会保留其之前的SetHoldPaxosLogCount()个paxos log
-
LockCheckpointState(): 用于开发者锁定状态机Checkpoint数据,这个锁定的意思是指这份数据文件不能被修改、移动和删除。因为接下来PhxPaxos就要将这些文件发送给其他节点,而如果这个过程中出现了修改,则发送的数据可能乱掉。
-
GetCheckpointState(): PhxPaxos获取Checkpoint文件列表,从而将文件发送给其他节点
-
UnLockCheckpointState(): 当PhxPaxos发送Checkpoint数据到其他节点后,会调用解锁函数,解除对开发者的状态机Checkpoint数据的锁定
-
LoadCheckpointState(): 当一个节点获得来自其他节点的Checkpoint数据时,会调用这个函数,将这份数据交由开发者进行处理(开发者往往要做的事情就是将这份Checkpoint数据覆盖当前节点的数据),当调用此函数完成后,PhxPaxos将会进行进程自杀操作,通过重启来完成一个新Checkpoint数据的启动。
-
ExecuteForCheckpoint(): paxos log归档的replay接口
4. Replayer
Replayer是一个独立的线程,负责将选中的提案值Checkpoint操作。实现逻辑非常简单,读取本机的Checkpoint InstanceID,定时和Max Chosen InstanceID比较,如果Checkpoint落后于Max Chosen InstanceID,则通过调用状态机的ExecuteForCheckpoint()进行重演:
void Replayer :: run()
{
PLGHead("Checkpoint.Replayer [START]");
uint64_t llInstanceID = m_poSMFac->GetCheckpointInstanceID(m_poConfig->GetMyGroupIdx()) + 1;
while (true)
{
if (m_bIsEnd)
{
PLGHead("Checkpoint.Replayer [END]");
return;
}
if (!m_bCanrun)
{
//PLGImp("Pausing, sleep");
m_bIsPaused = true;
Time::MsSleep(1000);
continue;
}
//本节点的所有提案值已全部重演
if (llInstanceID >= m_poCheckpointMgr->GetMaxChosenInstanceID())
{
//PLGImp("now maxchosen instanceid %lu small than excute instanceid %lu, wait",
//m_poCheckpointMgr->GetMaxChosenInstanceID(), llInstanceID);
Time::MsSleep(1000);
continue;
}
//重演
bool bPlayRet = PlayOne(llInstanceID);
if (bPlayRet)
{
PLGImp("Play one done, instanceid %lu", llInstanceID);
llInstanceID++;
}
else
{
PLGErr("Play one fail, instanceid %lu", llInstanceID);
Time::MsSleep(500);
}
}
}PlayOne()的实现逻辑如下:
bool Replayer :: PlayOne(const uint64_t llInstanceID)
{
//读取数据库中的paxos log
AcceptorStateData oState;
int ret = m_oPaxosLog.ReadState(m_poConfig->GetMyGroupIdx(), llInstanceID, oState);
if (ret != 0)
{
return false;
}
//调用状态机的ExecuteForCheckpoint
bool bExecuteRet = m_poSMFac->ExecuteForCheckpoint(
m_poConfig->GetMyGroupIdx(), llInstanceID, oState.acceptedvalue());
if (!bExecuteRet)
{
PLGErr("Checkpoint sm excute fail, instanceid %lu", llInstanceID);
}
return bExecuteRet;
}5. Paxos Log清理(Cleaner)
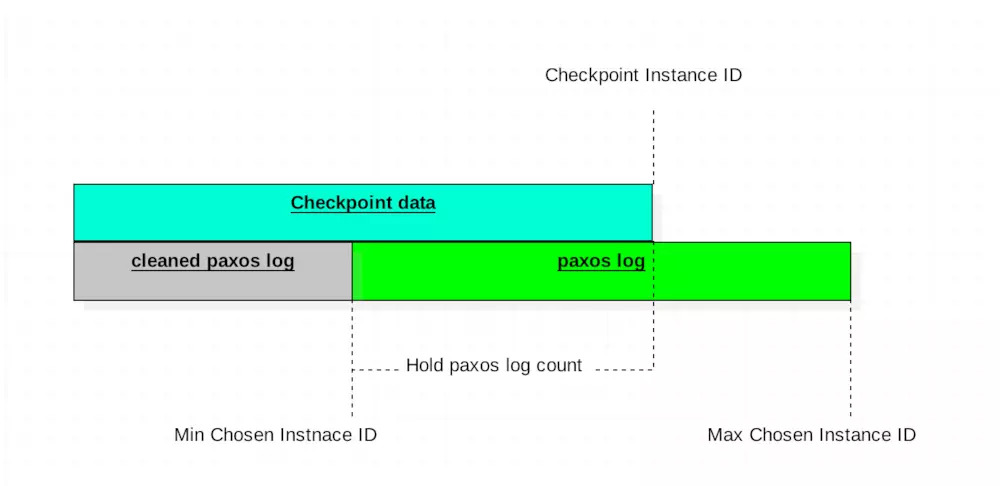
在PhxPaxos中,每个Group启动一个Cleaner线程清理本Group的paxos log。在Group中,instanceID是不断递增的,每个instanceID对应一个paxos log,当加入Checkpoint之后,我们有三个关键的instanceID:
-
min Chosen InstanceID: 本节点,选定提案的最小instanceID,即最老的paxos log所对应的instanceID
-
Checkpoint instanceID: 本节点,Checkpoint确定的最大instanceID,即在这之前的paxos log数据Checkpoint都已经不需要了。
-
max Chosen InstanceID: 本节点,选定提案的最大instanceID,即最新的paxos log所对应的instanceID
注意: 这里强调的是本节点, 不同节点数据可能不同
除此之外,还有一个配置: Node::SetHoldPaxosLogCount()控制需要保留多少在StateMachine::GetCheckpointInstanceID()之前的PaxosLog。保留一定数量的PaxosLog的目的在于,如果其他节点数据不对齐,可以通过保留的这部分paxos log完成对齐,而不需要checkpoint数据介入。
正常情况下,三者关系如下:
 清理动作由Cleaner线程的run()动作触发,触发频率、清理数据量等通过配置参数指定。为了减少清理动作对系统产生的副作用,PhxPaxos将清理动作拆解到毫秒级别分批次运行。假设我们设定每秒清理2000条记录(Cleaner_DELETE_QPS=2000),那么执行间隔为iSleepMs=1ms,每次删除数据量为iDeleteInterval=3条。代码逻辑如下:
清理动作由Cleaner线程的run()动作触发,触发频率、清理数据量等通过配置参数指定。为了减少清理动作对系统产生的副作用,PhxPaxos将清理动作拆解到毫秒级别分批次运行。假设我们设定每秒清理2000条记录(Cleaner_DELETE_QPS=2000),那么执行间隔为iSleepMs=1ms,每次删除数据量为iDeleteInterval=3条。代码逻辑如下:
//control delete speed to avoid affecting the io too much.
int iDeleteQps = Cleaner_DELETE_QPS;
int iSleepMs = iDeleteQps > 1000 ? 1 : 1000 / iDeleteQps;
int iDeleteInterval = iDeleteQps > 1000 ? iDeleteQps / 1000 + 1 : 1;根据此频率触发清理动作,下面我们来看run()函数的实现:
void Cleaner :: run()
{
m_bIsStart = true;
Continue();
//control delete speed to avoid affecting the io too much.
int iDeleteQps = Cleaner_DELETE_QPS;
int iSleepMs = iDeleteQps > 1000 ? 1 : 1000 / iDeleteQps;
int iDeleteInterval = iDeleteQps > 1000 ? iDeleteQps / 1000 + 1 : 1;
PLGDebug("DeleteQps %d SleepMs %d DeleteInterval %d",
iDeleteQps, iSleepMs, iDeleteInterval);
while (true)
{
if (m_bIsEnd)
{
PLGHead("Checkpoint.Cleaner [END]");
return;
}
if (!m_bCanrun)
{
PLGImp("Pausing, sleep");
m_bIsPaused = true;
Time::MsSleep(1000);
continue;
}
uint64_t llInstanceID = m_poCheckpointMgr->GetMinChosenInstanceID();
uint64_t llCPInstanceID = m_poSMFac->GetCheckpointInstanceID(m_poConfig->GetMyGroupIdx()) + 1;
uint64_t llMaxChosenInstanceID = m_poCheckpointMgr->GetMaxChosenInstanceID();
int iDeleteCount = 0;
while ((llInstanceID + m_llHoldCount < llCPInstanceID)
&& (llInstanceID + m_llHoldCount < llMaxChosenInstanceID))
{
bool bDeleteRet = DeleteOne(llInstanceID);
if (bDeleteRet)
{
//PLGImp("delete one done, instanceid %lu", llInstanceID);
llInstanceID++;
iDeleteCount++;
if (iDeleteCount >= iDeleteInterval)
{
iDeleteCount = 0;
Time::MsSleep(iSleepMs);
}
}
else
{
PLGDebug("delete system fail, instanceid %lu", llInstanceID);
break;
}
}
if (llCPInstanceID == 0)
{
PLGStatus("sleep a while, max deleted instanceid %lu checkpoint instanceid (no checkpoint) now instanceid %lu",
llInstanceID, m_poCheckpointMgr->GetMaxChosenInstanceID());
}
else
{
PLGStatus("sleep a while, max deleted instanceid %lu checkpoint instanceid %lu now instanceid %lu",
llInstanceID, llCPInstanceID, m_poCheckpointMgr->GetMaxChosenInstanceID());
}
Time::MsSleep(OtherUtils::FastRand() % 500 + 500);
}
}触发清理paxos log的条件包括checkpoint instanceID和min chosen instanceID之间的记录超过需要保留的条数,且max chosen instanceID和min chosen instanceID之间的记录超过了保留条数。后面一个判定只是一种保险的附加逻辑,因为实际上max chosen instanceID >= checkpoint instanceID永远成立。
bool Cleaner :: DeleteOne(const uint64_t llInstanceID)
{
WriteOptions oWriteOptions;
oWriteOptions.bSync = false;
int ret = m_poLogStorage->Del(oWriteOptions, m_poConfig->GetMyGroupIdx(), llInstanceID);
if (ret != 0)
{
return false;
}
m_poCheckpointMgr->SetMinChosenInstanceIDCache(llInstanceID);
if (llInstanceID >= m_llLastSave + DELETE_SAVE_INTERVAL)
{
int ret = m_poCheckpointMgr->SetMinChosenInstanceID(llInstanceID + 1);
if (ret != 0)
{
PLGErr("SetMinChosenInstanceID fail, now delete instanceid %lu", llInstanceID);
return false;
}
m_llLastSave = llInstanceID;
PLGImp("delete %d instance done, now minchosen instanceid %lu",
DELETE_SAVE_INTERVAL, llInstanceID + 1);
}
return true;
}删除数据包括两个动作: 删除paxos log;更新本节点的min chosen instanceID信息。但如果每删除一条都调用SetMinChoseInstance()来写入数据库的话,效率极低,因此这里会每隔DELETE_SAVE_INTERVAL才会真正写到数据库。
6. CheckpointMgr
CheckpointMgr真正管理的只有Cleaner、Replayer两个对象,负责管理这两个线程的初始化、启动、停止等典型动作。关于Cleaner和Replayer前面已经讲过了,此处不再赘述。来看CheckpointMgr另外一组功能:
class CheckpointMgr
{
public:
//准备发起Checkpoint请求
int PrepareForAskforCheckpoint(const nodeid_t iSendNodeID);
//当前是否处于Checkpoint模式,退出Checkpoint模式。后面两个函数只是设置和查看标志位(m_
const bool InAskforcheckpointMode() const;
//退出Checkpoint模式
void ExitCheckpointMode();
...
}后面两个函数只是设置和查看标志位(m_bInAskforCheckpointMode),来看PrepareForAskforCheckpoint()的实现:
int CheckpointMgr :: PrepareForAskforCheckpoint(const nodeid_t iSendNodeID)
{
if (m_setNeedAsk.find(iSendNodeID) == m_setNeedAsk.end())
{
m_setNeedAsk.insert(iSendNodeID);
}
if (m_llLastAskforCheckpointTime == 0)
{
m_llLastAskforCheckpointTime = Time::GetSteadyClockMS();
}
uint64_t llNowTime = Time::GetSteadyClockMS();
//发起请求已经超过1分钟,强制进入Checkpoint Mode
if (llNowTime > m_llLastAskforCheckpointTime + 60000)
{
PLGImp("no majority reply, just ask for checkpoint");
}
else
{
//未超过半数节点响应并同意Checkpoint请求
if ((int)m_setNeedAsk.size() < m_poConfig->GetMajorityCount())
{
PLGImp("Need more other tell us need to askforcheckpoint");
return -2;
}
}
m_llLastAskforCheckpointTime = 0;
m_bInAskforCheckpointMode = true;
return 0;
}何时触发进入Checkpoint模式呢? 当本节点向其他节点发起learn请求,其他节点保存的min chosen instanceID比本地的instanceID还要大。这说明本节点无法再向该节点通过learn完成追赶,这时调用PrepareForAskForCheckpoint()请求进入Checkpoint模式。而真正进入Checkpoint模式如下两个条件之一:
-
已有超过半数节点无法通过Learn方式完成追赶,进入Checkpoint模式;
-
距离首个告知无法支持Learn追赶的节点距今已超过1分钟,仍有其他节点告知追赶无法完成,为避免差距进一步拉大,进入Checkpoint模式;
一旦决定进入Checkpoint模式,向对应告知的节点发起Checkpoint请求:
void Learner :: AskforCheckpoint(const nodeid_t iSendNodeID)
{
PLGHead("START");
int ret = m_poCheckpointMgr->PrepareForAskforCheckpoint(iSendNodeID);
if (ret != 0)
{
return;
}
PaxosMsg oPaxosMsg;
oPaxosMsg.set_instanceid(GetInstanceID());
oPaxosMsg.set_nodeid(m_poConfig->GetMyNodeID());
oPaxosMsg.set_msgtype(MsgType_PaxosLearner_AskforCheckpoint);
PLGHead("END InstanceID %lu MyNodeID %lu", GetInstanceID(), oPaxosMsg.nodeid());
SendMessage(iSendNodeID, oPaxosMsg);
}对应节点接收该消息后,启动CheckpointSender线程,发送Checkpoint数据。
7. CheckpointSender/CheckpointReceiver
CheckpointSender的定位很明确,一旦启动线程,立即执行Checkpoint发送数据。线程核心函数如下:
void CheckpointSender :: run()
{
m_bIsStarted = true;
m_llAbsLastAckTime = Time::GetSteadyClockMS();
//pause checkpoint replayer
bool bNeedContinue = false;
//暂停replayer
while (!m_poCheckpointMgr->GetReplayer()->IsPaused())
{
if (m_bIsEnd)
{
m_bIsEnded = true;
return;
}
bNeedContinue = true;
m_poCheckpointMgr->GetReplayer()->Pause();
PLGDebug("wait replayer paused.");
Time::MsSleep(100);
}
//锁定所有的状态机
int ret = LockCheckpoint();
if (ret == 0)
{
//发送Checkpoint数据
SendCheckpoint();
//解锁状态机
UnLockCheckpoint();
}
//恢复replayer
if (bNeedContinue)
{
m_poCheckpointMgr->GetReplayer()->Continue();
}
PLGHead("Checkpoint.Sender [END]");
m_bIsEnded = true;
}-
Replayer负责本地追赶Learner数据,当需要发起Checkpoint操作时,要保证Checkpoint文件不变,因此PhxPaxos机制需要首先暂停Replayer;
-
Checkpoint之前,调用所有状态机的LockCheckpoint()锁定Checkpoint文件;
-
Checkpoint之后,调用所有状态机的UnLockCheckpoint()解除锁定;
-
恢复Replayer,追赶落后的Learner数据
SendCheckpoint内部又分为三个阶段: Checkpoint开始、Checkpoint数据传输、Checkpoint结束。
7.1 Checkpoint开始
通过向对方发送带CheckpointSendFileFlag_BEGIN标识的CheckpointMsgType_SendFile消息告知对方马上要发送checkpoint文件了:
int Learner :: SendCheckpointBegin(
const nodeid_t iSendNodeID,
const uint64_t llUUID,
const uint64_t llSequence,
const uint64_t llCheckpointInstanceID)
{
CheckpointMsg oCheckpointMsg;
oCheckpointMsg.set_msgtype(CheckpointMsgType_SendFile);
oCheckpointMsg.set_nodeid(m_poConfig->GetMyNodeID());
oCheckpointMsg.set_flag(CheckpointSendFileFlag_BEGIN);
oCheckpointMsg.set_uuid(llUUID);
oCheckpointMsg.set_sequence(llSequence);
oCheckpointMsg.set_checkpointinstanceid(llCheckpointInstanceID);
PLGImp("END, SendNodeID %lu uuid %lu sequence %lu cpi %lu",
iSendNodeID, llUUID, llSequence, llCheckpointInstanceID);
return SendMessage(iSendNodeID, oCheckpointMsg, Message_SendType_TCP);
}CheckpointReceiver接收到该消息后,回调如下函数:
int Learner :: OnSendCheckpoint_Begin(const CheckpointMsg & oCheckpointMsg)
{
int ret = m_oCheckpointReceiver.NewReceiver(oCheckpointMsg.nodeid(), oCheckpointMsg.uuid());
if (ret == 0)
{
PLGImp("NewReceiver ok");
ret = m_poCheckpointMgr->SetMinChosenInstanceID(oCheckpointMsg.checkpointinstanceid());
if (ret != 0)
{
PLGErr("SetMinChosenInstanceID fail, ret %d CheckpointInstanceID %lu",
ret, oCheckpointMsg.checkpointinstanceid());
return ret;
}
}
return ret;
}上面会做如下几件事情:
-
删除本地的、当前Group的所有临时Checkpoint文件
-
删除数据库中的所有paxos log
-
重置min chosen instanceID,以Checkpoint Sender发送过来的数据作为基线
值得注意的是,整个过程中没有提及本机的Cleaner和Replayer,难道不应该把这些一并停掉?再有,先删除本地数据库中的paxos log再重置min chosen instanceID,过程中可能又有新的数据写入了,并发问题怎么解决呢?
记得CheckpointMgr中有一个InAskforCheckpointMode()方法,判断当前是否处于Checkpoint模式,搜索其使用者,我们看到这样一段逻辑:
void Instance :: OnReceive(const std::string & sBuffer)
{
....
if (iCmd == MsgCmd_PaxosMsg)
{
if (m_oCheckpointMgr.InAskforcheckpointMode())
{
PLGImp("in ask for checkpoint mode, ignord paxosmsg");
return;
}
PaxosMsg oPaxosMsg;
bool bSucc = oPaxosMsg.ParseFromArray(sBuffer.data() + iBodyStartPos, iBodyLen);
if (!bSucc)
{
BP->GetInstanceBP()->OnReceiveParseError();
PLGErr("PaxosMsg.ParseFromArray fail, skip this msg");
return;
}
if (!ReceiveMsgHeaderCheck(oHeader, oPaxosMsg.nodeid()))
{
return;
}
OnReceivePaxosMsg(oPaxosMsg);
}
....
}当本节点接收到来自其他节点的数据时,如果当前处于Checkpoint模式,则非Checkpoint相关的数据包全部丢弃。因此,即便Cleaner和Replayer未停止,即便删除数据和重置之间存在时间间隔也不会有问题。因为整个Checkpoint过程中,并没有新的消息被处理,一切处于停滞状态。
注: 这里CheckpointSender实现上看起来存在一点问题,貌似会发送所有的Checkpoint文件? 因为看GetCheckpointState()函数参数并没有指定开始instanceID ?
7.2 Checkpoint数据传输
Checkpoint执行过程代码虽然很多,但是逻辑并不复杂:
void CheckpointSender :: SendCheckpoint()
{
...
std::vector<StateMachine *> vecSMList = m_poSMFac->GetSMList();
for (auto & poSM : vecSMList)
{
ret = SendCheckpointFofaSM(poSM);
if (ret != 0)
{
return;
}
}
....
}Checkpoint数据传输、处理过程中数据包标识为CheckpointSendFileFlag_ING。其会遍历本节点的所有状态机对象,依次做每个状态机的Checkpoint对账。通过调用状态机的GetCheckpointState()获取本状态机的全部Checkpoint文件列表,并依次发送。单次发送大小不超过1M。
CheckpointReceiver的伪代码如下:
create file if not exist
open file
append file
end7.3 Checkpoint结束
一旦所有的Checkpoint数据发送完成,需要发送CheckpointSendFileFlag_END消息到Checkpoint的发起者,处理逻辑如下:
int Learner :: OnSendCheckpoint_End(const CheckpointMsg& oCheckpointMsg)
{
if (!m_oCheckpointReceiver.IsReceiverFinish(oCheckpointMsg.nodeid(),
oCheckpointMsg.uuid(), oCheckpointMsg.sequence()))
{
PLGErr("receive end msg but receiver not finish");
return -1;
}
BP->GetCheckpointBP()->ReceiveCheckpointDone();
std::vector<StateMachine*> vecSMList = m_poSMFac->GetSMList();
//遍历所有的状态机
for (auto & poSM : vecSMList)
{
if (poSM->SMID() == SYSTEM_V_SMID
|| poSM->SMID() == MASTER_V_SMID)
{
//system variables sm no checkpoint
//master variables sm no checkpoint
continue;
}
//获取Checkpoint路径和文件信息
string sTmpDirPath = m_oCheckpointReceiver.GetTmpDirPath(poSM->SMID());
std::vector<std::string> vecFilePathList;
int ret = FileUtils :: IterDir(sTmpDirPath, vecFilePathList);
if (ret != 0)
{
PLGErr("IterDir fail, dirpath %s", sTmpDirPath.c_str());
}
if (vecFilePathList.size() == 0)
{
PLGImp("this sm %d have no checkpoint", poSM->SMID());
continue;
}
//通知状态机Checkpoint文件变更
ret = poSM->LoadCheckpointState(
m_poConfig->GetMyGroupIdx(),
sTmpDirPath,
vecFilePathList,
oCheckpointMsg.checkpointinstanceid());
if (ret != 0)
{
BP->GetCheckpointBP()->ReceiveCheckpointAndLoadFail();
return ret;
}
}
BP->GetCheckpointBP()->ReceiveCheckpointAndLoadSucc();
PLGImp("All sm load state ok, start to exit process");
//退出PhxPaxos
exit(-1);
return 0;
}引用《状态机Checkpoint详解》中的文字:
StateMachine::LoadCheckpointState()当一个节点获得来自其他节点的Checkpoint数据时,会调用这个函数,将这份数据交由开发者进行处理(开发者往往要做的事情就是将这份Checkpoint数据覆盖当前节点的数据)。当调用此函数完成后,PhxPaxos将会进行进程自杀,通过重启来完成一个新Checkpoint数据的启动。
也就是说,整个Checkpoint的对账过程,业务侧并没有感知,PhxPaxos内部只是将这些文件放到了一个临时路径,只在最后一刻才通过LoadCheckpointState()来通知业务处理。
8. 总结
Checkpoint机制在每个节点默认启用两个线程: Cleaner、Replayer。Cleaner负责定期清理过时的Paxos log。Replayer则负责追赶状态机的Execute数据到ExecuteForCheckpoint。另外,如果某个节点落后太多,通过Learner无法完成追赶时,将触发启动Checkpoint的另外一个线程CheckpointSender。CheckpointSender负责发送本节点的Checkpoint文件到CheckpointReceiver。一旦数据发送完成,CheckpointReceiver将进行进程自杀操作,通过重启完成Checkpoint数据同步。
Checkpoint机制并不是PhxPaxos算法的一部分,而是真正工程化的产物。它尝试解决的工程问题包括:
-
某个节点落后太多的场景下,如何实现快速追赶;
-
系统长时间运行场景下,如何避免海量日志;
-
系统异常等故障场景下,如何保证系统的可靠性;
OK,至此我们已经了解了PhxPaxos的基础网络部件、paxos角色以及工程化的Checkpoint机制,终于可以浮到水面窥视PhxPaxos的全貌了。
参看:
