ceph数据一致性浅析
ceph作为一个分布式存储系统,保证数据的一致性是很重要的一个方面。ceph的数据存储是以PG为单位来进行的,而数据的一致性也是通过PG的相关操作来实现的。本章涉及到的内容包括:
-
PG的创建过程
-
Ceph Peering机制
下面我们先给出一幅PG状态机的总体状态转换图:
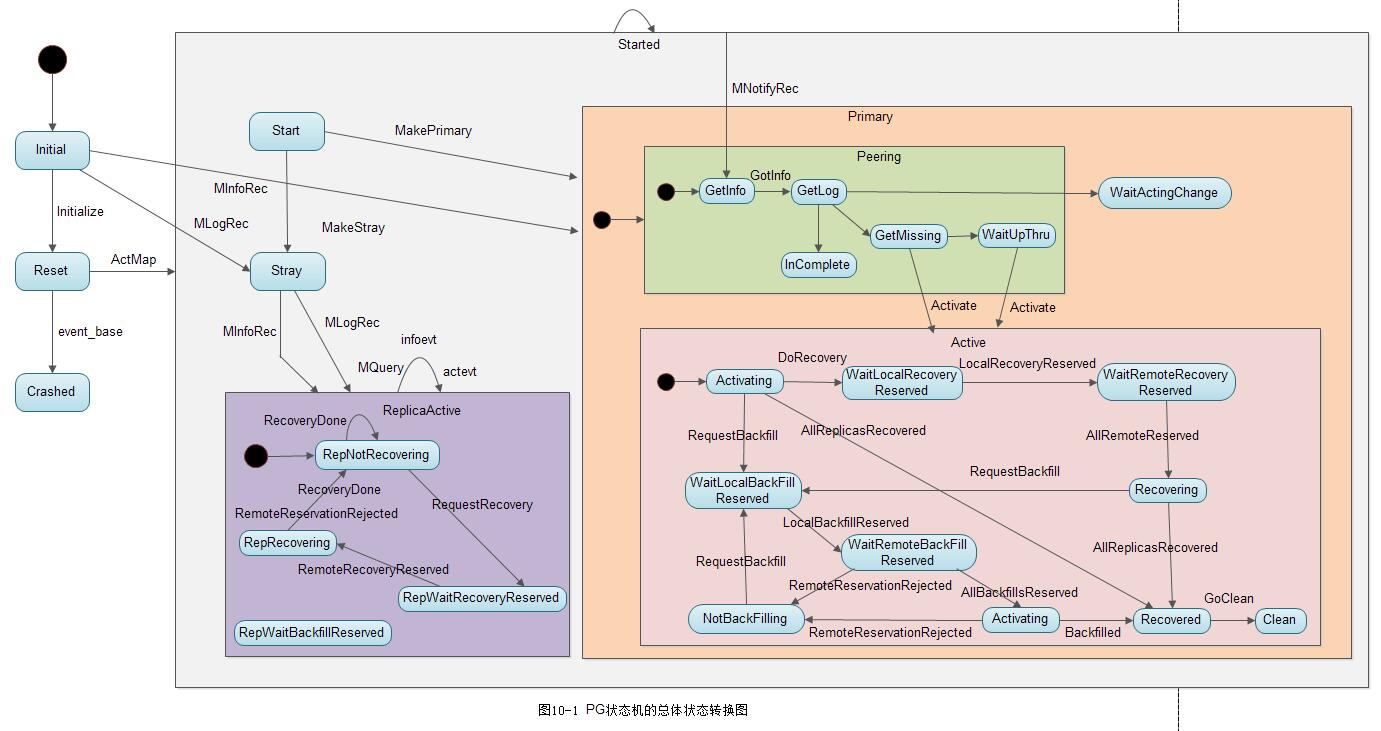
1. PG的创建过程
PG的创建是由monitor节点发起的,形成请求message发送给主osd,在OSD上创建PG。
1.1 monitor节点处理
1) register_new_pgs()
在monitor中由PGMonitor发现是否创建了pool, pool中是否存在PG需要进行创建。首先来看函数PGMonitor::register_new_pgs()
bool PGMonitor::register_new_pgs()
{
....
// first pgs in this pool
bool new_pool = pg_map.pg_pool_sum.count(poolid) == 0;
for (ps_t ps = 0; ps < pool.get_pg_num(); ps++) //标记位置1
{
pg_t pgid(ps, poolid, -1); //标记位置2
if (pg_map.pg_stat.count(pgid)) //标记位置3
{
dout(20) << "register_new_pgs have " << pgid << dendl;
continue;
}
created++;
register_pg(osdmap, pgid, pool.get_last_change(), new_pool); //标记位置4
}
}标记位置1:循环遍历当前这个pool中的所有PG
标记位置2: 根据当前这个pool中PG的序号和pool的id,形成pgid。(pgid就是用来统计哪个pool中的第几个pg而已,使用m_seed作为pg序号,m_pool作为pool序号,如下所示:)
struct pg_t {
uint64_t m_pool;
uint32_t m_seed;
int32_t m_preferred;
....
};
标记位置3: pg_map中统计了所有的PG,如果发现当前的PG不在pg_map中,说明这个pg是需要被创建的
标记位置4: 使用register_pg()函数开始处理申请这个PG
2) 申请PG
register_pg()函数开始对PG的申请进行处理,这时已经有了pgid和pool的信息:
void PGMonitor::register_pg(OSDMap *osdmap,
pg_t pgid, epoch_t epoch,
bool new_pool)
{
....
pg_stat_t &stats = pending_inc.pg_stat_updates[pgid]; //标记位置1
stats.state = PG_STATE_CREATING; //标记位置2
stats.created = epoch;
stats.parent = parent;
stats.parent_split_bits = split_bits;
stats.mapping_epoch = epoch;
//标记位置3
osdmap->pg_to_up_acting_osds(
pgid,
&stats.up,
&stats.up_primary,
&stats.acting,
&stats.acting_primary);
}
void OSDMap::_pg_to_up_acting_osds(const pg_t& pg, vector<int> *up, int *up_primary,
vector<int> *acting, int *acting_primary) const
{
}标记位置1: 将刚创建的pgid统计到pending_inc.pg_stat_updates结构中
标记位置2: 设置这个PG的状态为PG_STATE_CREATING
标记位置3: 将PG映射到OSD上,这时候需要osdmap,最终通过_pg_to_up_acting_osds()函数完成映射
接下来会将这个pending_inc进行打包,然后推行propose_pending(),开始提议,等待完成最后推行(这其实是paxos协议的一部分)。
3) propose_pending()
在check_osd_map()函数中首先执行了register_new_pgs(),之后将映射好的PG通过propose_pending()完成推行,形成一致的PGMap。(说明: 类PGMonitor继承了PaxosService):
void PGMonitor::check_osd_map(epoch_t epoch)
{
if (map_pg_creates())
propose = true;
if (register_new_pgs())
propose = true;
if ((need_check_down_pgs || !need_check_down_pg_osds.empty()) && check_down_pgs())
propose = true;
if (propose)
propose_pending();
}
void PaxosService::propose_pending()
{
paxos->queue_pending_finisher(new C_Committed(this));
paxos->trigger_propose(); //标记位置1
}标记位置1: 触发提议的表决
4) 触发提议表决
bool Paxos::trigger_propose()
{
if (is_active()) {
dout(10) << __func__ << " active, proposing now" << dendl;
propose_pending();
return true;
} else {
dout(10) << __func__ << " not active, will propose later" << dendl;
return false;
}
}
void Paxos::propose_pending()
{
...
state = STATE_UPDATING;
begin(bl);
}上面完成投票表决之后,就会调用refresh_from_paxos()完成提议的推行。
5) 进行提议的推行
void Monitor::refresh_from_paxos(bool *need_bootstrap)
{
for (int i = 0; i < PAXOS_NUM; ++i) {
paxos_service[i]->refresh(need_bootstrap); //标记位置1
}
for (int i = 0; i < PAXOS_NUM; ++i) {
paxos_service[i]->post_refresh();
}
}
void PaxosService::refresh(bool *need_bootstrap)
{
update_from_paxos(need_bootstrap);
}
void PGMonitor::update_from_paxos(bool *need_bootstrap)
{
PGMap::Incremental inc;
try {
bufferlist::iterator p = bl.begin();
inc.decode(p); //标记位置1
} catch (const std::exception &e) {
dout(0) << "update_from_paxos: error parsing "
<< "incremental update: " << e.what() << dendl;
assert(0 == "update_from_paxos: error parsing incremental update");
return;
}
pg_map.apply_incremental(g_ceph_context, inc); //标记位置2
}决策推行函数update_from_paxos(),在这里会根据仲裁决定,然后处理结果,上面说道已经推行了创建的PG。
标记位置1: 重新解析pgid;
标记位置2: 将这个决议交给pg_map进行处理,调用PGMap::apply_incremental()
6) 发送请求到OSD以创建PG
我们在上面Monitor::refresh_from_paxos()后面会调用post_refresh(),此函数会最后向对应的OSD发出创建PG的命令:
void PaxosService::post_refresh()
{
post_paxos_update();
}
void PGMonitor::post_paxos_update()
{
if (mon->osdmon()->osdmap.get_epoch()) {
send_pg_creates();
}
}
void PGMonitor::send_pg_creates()
{
if (osdmap.is_up(osd))
send_pg_creates(osd, NULL, 0);
}
epoch_t PGMonitor::send_pg_creates(int osd, Connection *con, epoch_t next)
{
m = new MOSDPGCreate(pg_map.last_osdmap_epoch);
if (con) {
con->send_message(m);
} else {
assert(mon->osdmon()->osdmap.is_up(osd));
mon->messenger->send_message(m, mon->osdmon()->osdmap.get_inst(osd));
}
}上面创建了一个MOSDPGCreate对象,然后向其发送消息进行PG的创建。MOSDPGCreate实现了Message类:
struct MOSDPGCreate : public Message {
MOSDPGCreate()
: Message(MSG_OSD_PG_CREATE, HEAD_VERSION, COMPAT_VERSION) {}
MOSDPGCreate(epoch_t e)
: Message(MSG_OSD_PG_CREATE, HEAD_VERSION, COMPAT_VERSION),
epoch(e) { }
};1.2 osd节点处理
osd这时收到一个消息,根据消息命令字MSG_OSD_PG_CREATE,发现这是一个创建PG的消息,然后交给handle_pg_create()进行处理:
void OSD::dispatch_op(OpRequestRef op)
{
switch (op->get_req()->get_type()) {
case MSG_OSD_PG_CREATE:
handle_pg_create(op);
}
void OSD::handle_pg_create(OpRequestRef op)
{
MOSDPGCreate *m = (MOSDPGCreate*)op->get_req();
if (!require_mon_peer(op->get_req()->get())) { //标记位置1
return;
}
if (!require_same_or_newer_map(op, m->epoch, false)) //标记位置2
return;
//标记位置3
for (map<pg_t,pg_create_t>::iterator p = m->mkpg.begin();p != m->mkpg.end(); ++p, ++ci)
{
}
maybe_update_heartbeat_peers(); //标记位置4
}标记位置1: 调用函数require_mon_peer确保是由Monitor发送的创建消息
标记位置2: 调用函数require_same_or_newer_map检查epoch是否一致。如果对方的epoch比自己拥有的更新,就更新自己的epoch;否则就直接拒绝该请求。
标记位置3: 对消息中mkpg列表里每一个PG,开始执行如下创建操作
-
检查该PG的参数split_bits,如果不为0,那么就是PG的分裂请求,这里不做处理;检查PG的preferred,如果设置了,就跳过,目前不支持; 检查确认该pool存在; 检查本OSD是该PG的主OSD; 如果参数up不等于acting,说明该PG有temp_pg,至少确定该PG存在,直接跳过。
-
调用函数_have_pg获取该PG对应的类。如果该PG已经存在,跳过
-
调用PG::_create在本地对象存储中创建相应的collection
-
调用函数_create_lock_pg初始化PG
-
调用函数pg->handle_create(&rctx)给新创建PG状态机投递事件,PG的状态发生相应的改变,后面会介绍
-
所有修改操作都打包在事务rctx.transaction中,调用函数dispatch_context将事务提交到本地对象存储中
标记位置4:调用函数maybe_update_heartbeat_peers来更新OSD的心跳列表
1.3 PG在从OSD上的创建
上面1.1、1.2讲述的是PG在主OSD上的创建流程。Monitor并不会给PG的从OSD发送消息来创建该PG, 而是由该主OSD上的PG在Peering过程中创建。主OSD给从OSD的PG状态机投递事件时,在函数handle_pg_peering_evt中,如果发现该PG不存在,才完成创建该PG。
函数handle_pg_peering_evt是处理Peering状态机事件的入口。该函数会查找相应的PG,如果该PG不存在,就创建该PG。该PG的状态机进入RecoveryMachine/Stray状态。
1.4 PG的加载
当OSD重启时,调用函数OSD::init(),该函数调用load_pgs函数加载已经存在的PG,其处理过程和创建PG的过程相似。
2. PG创建后状态机的状态转换
如下图10-2为PG总体状态转换图的简化版: 状态Peering、Active、ReplicaActive4的内部状态没有添加进去。
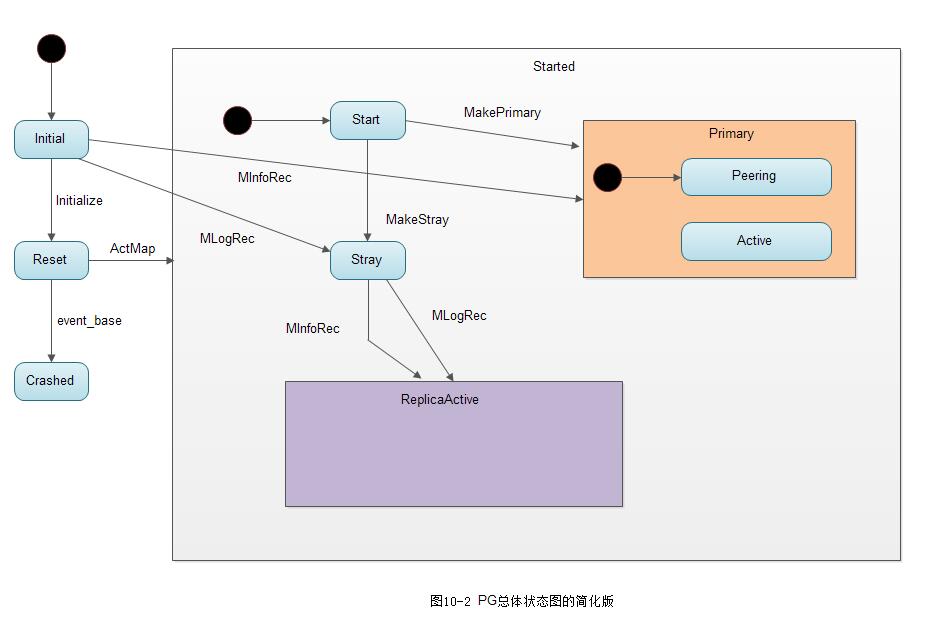
通过该图可以了解PG的高层状态转换过程,如下所示:
1) 当PG创建后,同时在该类内部创建了一个属于该PG的RecoveryMachine类型的状态机,该状态机的初始化状态为默认初始化状态Initial
2) 在PG创建后,调用函数pg->handle_create(&rctx)来给状态机投递事件:
void PG::handle_create(RecoveryCtx *rctx)
{
dout(10) << "handle_create" << dendl;
rctx->created_pgs.insert(this);
Initialize evt;
recovery_state.handle_event(evt, rctx);
ActMap evt2;
recovery_state.handle_event(evt2, rctx);
}由以上代码可知: 该函数首先向RecoveryMachine投递了Initialize类型的事件。由上图10-2可知,状态机在RecoveryMachine/Initial状态接收到Initialize类型的事件后直接转移到Reset状态。其次,向RecoveryMachine投递了ActMap事件。
3) 状态Reset接收到ActMap事件,跳转到Started状态
boost::statechart::result PG::RecoveryState::Reset::react(const ActMap&)
{
PG *pg = context< RecoveryMachine >().pg;
if (pg->should_send_notify() && pg->get_primary().osd >= 0) {
context< RecoveryMachine >().send_notify(
pg->get_primary(),
pg_notify_t(
pg->get_primary().shard, pg->pg_whoami.shard,
pg->get_osdmap()->get_epoch(),
pg->get_osdmap()->get_epoch(),
pg->info),
pg->past_intervals);
}
pg->update_heartbeat_peers();
pg->take_waiters();
return transit< Started >();
}在自定义的react函数里直接调用了transit函数跳转到Started状态。
4) 进入状态RecoveryMachine/Started后,就进入RecoveryMachine/Started的默认的子状态RecoveryMachine/Started/Start中
/*-------Start---------*/
PG::RecoveryState::Start::Start(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Start")
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
if (pg->is_primary()) {
dout(1) << "transitioning to Primary" << dendl;
post_event(MakePrimary());
} else { //is_stray
dout(1) << "transitioning to Stray" << dendl;
post_event(MakeStray());
}
}由以上代码可知,在Start状态的构造函数中,根据本OSD在该PG中担任的角色不同分别进行如下处理:
-
如果是主OSD,就调用函数post_event,抛出事件MakePrimary,进入主OSD的默认子状态Primary/Peering中
-
如果是从OSD,就调用函数post_event,抛出事件MakeStray,进入Started/Stray状态
对于一个PG的OSD处于Stray状态,是指该OSD上的PG副本目前状态不确定,但是可以响应主OSD的各种查询操作。它有两种可能: 一种是最终转移到状态ReplicaActive,处于活跃状态,成为PG的一个副本; 另一种可能的情况是: 如果是数据迁移的源端,可能一直保持Stray状态,该OSD上的副本可能在数据迁移完成后,PG以及数据就都被删除了。
3. Ceph的Peering过程分析
在介绍了statechart状态机和PG的创建过程后,正式开始Peering过程介绍。Peering的过程使一个PG内的OSD达成一个一致状态。当主从副本达成一个一致的状态后,PG处于active状态,Peering过程的状态就结束了。但此时该PG的三个OSD的数据副本上的数据并非完全一致。
PG在如下两种情况下触发Peering过程:
-
当系统初始化时,OSD重新启动导致PG重新加载,或者PG新创建时,PG会发起一次Peering的过程
-
当有OSD失效,OSD的增加或者删除等导致PG的acting set发生了变化,该PG就会重新发起一次Peering过程
3.1 基本概念
1) acting set和up set
acting set是一个PG对应副本所在的OSD列表,该列表是有序的,列表中第一个OSD为主OSD。在通常情况下,up set和acting set列表完全相同。要理解它们的不同之处,需要理解下面介绍的“临时PG”概念。
2) 临时PG
假设一个PG的acting set为[0,1,2]列表。此时如果osd0出现故障,导致CRUSH算法重新分配该PG的acting set为[3,1,2]。此时osd3为该PG的主OSD,但是OSD3为新加入的OSD,并不能负担该PG上的读操作。所以PG向Monitor申请一个临时的PG,osd1为临时的主OSD,这是up set变为[1,3,2],acting set依然为[3,1,2],导致acting set和up set不同。当osd3完成Backfill过程之后,临时PG被取消,该PG的up set修复为acting set,此时acting set和up set都是[3,1,2]列表。
3) 权威日志
权威日志(在代码里一般简写为olog)是一个PG的完整顺序且连续操作的日志记录。该日志将作为数据修复的依据。
4) up_thru
引入up_thru的概念是为了解决特殊情况: 当两个以上的OSD处于down状态,但是Monitor在两次epoch中检测到了这种状态,从而导致Monitor认为它们是先后宕掉。后宕的OSD有可能产生数据更新,导致需要等待该OSD的修复,否则有可能产生数据丢失。
例10-1: up_thru处理过程
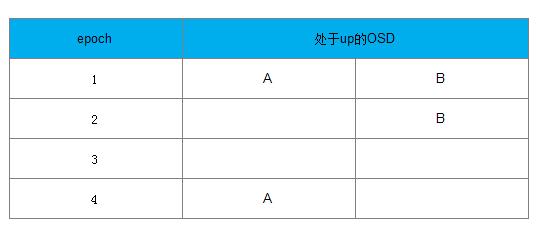
过程如下所示:
a) 在epoch 1时,一个PG中有A、B两个OSD(两个副本)都处于up状态。
b) 在epoch 2时,Monitor检测到了A处于down状态,B仍然处于up状态。由于Monitor的检测可能滞后,实际可能有两种情况:
情况1: 此时B其实也已经和A同时宕了,只是Monitor没有检测到。此时PG不可能完成PG的Peering过程,PG没有新数据写入; 情况2: 此时B确实处于up状态,由于B上保持了完整的数据,PG可以完成Peering过程并处于active状态,可以接受新的数据写操作。
上述两种情况,Monitor无法区分。
c) 在epoch 3时,Monitor检测到B也宕了
d) 在epoch 4时,A恢复了up的状态后,该PG发起Peering过程,该PG是否允许完成Peering过程处于active状态,可以接受读写操作?
d.1) 如果在epoch 2时,属于情况1: PG并没有数据更新,B上不会写入数据,A上的数据保存完整,此时PG可以完成Peering过程
从而处于active状态,接受写操作
d.2) 如果在epoch 2时,属于情况2: PG上有新数据更新到了osd B,此时osd A缺失一些数据,该PG不能完成Peering过程
为了使Monitor能够区分上述两种情况,引入了up_thru的概念, up_thru记录了每个OSD完成Peering后的epoch值。其初始值设置为0。
在上述情况2, PG如果可以恢复为active状态,在Peering过程,须向Monitor发送消息,Monitor用数组up_thru[osd]来记录该OSD完成Peering后的epoch值。
当引入up_thru后,上述例子的处理过程如下:
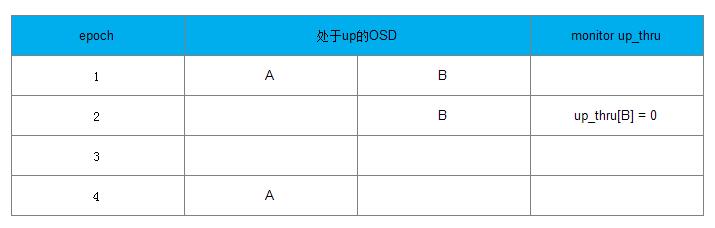
情况1的处理流程如下:
a) 在epoch 1时, up_thru[B]为0,也就是说B在epoch为0时参与完成Peering。
b) 在epoch 2时,Monitor检查到OSD A处于down状态, OSD B仍处于up状态(实际B已经处于down状态),PG没有完成Peering过程,不会向Monitor上报更新up_thru的值。
c) epoch 3时,A 和 B两个OSD都宕了
d) epoch 4时,A恢复up状态, PG开始Peering过程,发现up_thru[B]为0,说明在epoch为2时没有更新操作,该PG可以完成Peering过程, PG处于active状态
情况2的处理如下所示:
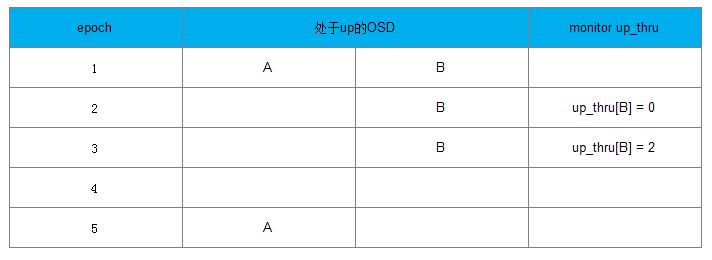
情况2的处理流程如下:
a) 在epoch 1时,up_thru[B]为0,也就是说B在epoch为0时参与完成Peering过程
b) 在epoch 2时, Monitor检查到OSD A处于down状态,OSD B还处于up状态,该PG完成了Peering过程,向Monitor上报B的up_thru变为当前epoch的值为2,此时PG可接受写操作请求
c) 在epoch 4时,A和B都宕了,B的up_thru为2
d) 在epoch 5时, A处于up状态,开始Peering过程,发现up_thru[B]为2,说明在epoch为2时完成了Peering,有可能有更新操作,该PG需要等待B恢复。否则可能丢失B上更新的数据。
3.2 PG日志
PG日志(pg log)为一个PG内所有更新操作的记录(下文所指的日志,如不特别指出,都是指PG日志)。每个PG对应一个PG日志,它持久化保存在每个PG对应pgmeta_oid对象的omap属性中。
它有如下特点:
-
记录一个PG内所有对象的更新操作元数据信息,并不记录操作的数据
-
是一个完整的日志记录,版本号是顺序的且连续的
1) pg_log_t
结构体pg_log_t在内存中保存了该PG的所有操作日志,以及相关的控制结构:
struct pg_log_t {
eversion_t head; // 日志的头, 记录最新的日志记录
eversion_t tail; // 日志的尾, 记录最旧的日志记录
// 用于EC,指示本地可以回滚的版本,可回滚的版本都大于版本can_rollback_to的值
eversion_t can_rollback_to;
//在EC的实现中,本地保留了不同版本的数据。本数据段指示本PG里可以删除掉的对象版本
eversion_t rollback_info_trimmed_to;
//所有日志的列表
list<pg_log_entry_t> log;
....
};需要注意的是,PG日志的记录是以整个PG为单位,包括该PG内所有对象的修改记录。
[参看]
