监视OSD与PG
要实现高可用与高可靠性,我们就需要有相应的容错方法来管理硬件与软件出现的问题。ceph本身是没有单点故障的,即使处于degraded模式下仍可以对外提供服务。我们在data placement一章介绍了ceph通过添加一个中间层,从而避免数据与某个OSD地址的直接产生绑定。这就意味着如果我们要从根源上跟踪系统错误的话,就必须要能够找到对应的PG以及底层的OSD。
Tip: 集群中的一个错误也许会使得不能访问某一特定的对象,但这并不意味着你不能访问其他对象。
通常情况下ceph具有自修复能力。然而,当问题存在之后,我们可以通过查看OSD以及PG的状态来进行定位。
1. MONITORING OSD
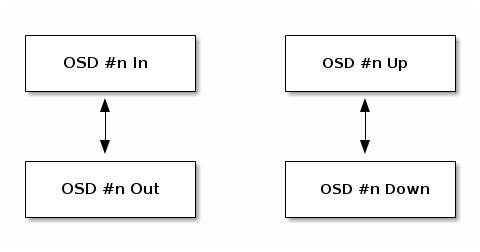
关于OSD的状态有如下描述:
An OSD’s status is either in the cluster (in) or out of the cluster (out); and, it is either up and running (up), or it is down and not running (down). If an OSD is up, it may be either in the cluster (you can read and write data) or it is out of the cluster. If it was in the cluster and recently moved out of the cluster, Ceph will migrate placement groups to other OSDs. If an OSD is out of the cluster, CRUSH will not assign placement groups to the OSD. If an OSD is down, it should also be out.
注: 假如一个OSD的状态时down+in,那么整个集群就会出现unhealthy状态
当你执行ceph health或者ceph -s或者ceph -w时,你也许会发现集群并不总是处于HEALTH OK状态。从OSD层面来看,在如下一些情况下也许你并不期望集群报告为HEALTH OK状态:
-
集群未启动(并不能对外部的请求作出响应)
-
集群刚刚启动或重启,并未准备好响应外部请求,因为PG可能正在创建(creating),OSD可能也正处于peering状态
-
刚刚添加或移除OSD
-
刚刚修改完cluster map
监控OSD的另一个重要方面是确保当集群处于up+running状态时,集群中的所有OSD处于in+up+running状态。如果要查询是否所有的OSD都处于running状态,执行:
# ceph osd stat x osds: y up, z in; epoch: eNNNN
查询的结果会告诉你总的OSD个数(x),当前有多少处于up状态(y),有多少处于in状态(z),最后会显示当前的OSD map epoch。
假如当前集群中处于in状态的OSD个数大于up状态的OSD个数,执行如下命令查看哪些OSD当前处于down状态:
# ceph osd tree #ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 2.00000 pool openstack -3 2.00000 rack dell-2950-rack-A -2 2.00000 host dell-2950-A1 0 ssd 1.00000 osd.0 up 1.00000 1.00000 1 ssd 1.00000 osd.1 down 1.00000 1.00000
假如某一个osd当前处于down状态,执行如下命令来启动:
# sudo systemctl start ceph-osd@1
2. PG集合
当CRUSH将PG映射到OSD时,其首先会查询对应存储池(pool)的副本策略,之后PG中的每一个副本映射到不同的OSD。例如,假设当前存储池(pool)策略要求每个PG要有3个副本,则CRUSH可能会为其指定osd.1、osd.2、osd.3。CRUSH算法会根据CRUSH map中所设定的失败域(failure domain)来伪随机指定PG中OSD的映射,因此在一个大的ceph集群中你可能会很少看到一个PG内的OSD是相邻的。我们将一个PG中副本OSD集合称为Acting Set。在某些情况下,Acting Set中的某个OSD处于down状态或者不能处理该PG中的对象请求。在如下一些场景下就很可能会出现这种情况:
-
刚刚添加(add)或移除(remove)了一个osd,之后CRUSH会对PG进行重新映射,在这一过程中可能会更改Acting Set的OSD组成,并通过
backfill来实现数据的迁移。 -
一个OSD在过去某个时间处于down状态,之后重启了,目前处于recovering状态
-
Acting Set中的某个OSD当前处于down状态或者并不能响应相关的服务请求,其工作由另一个OSD临时接替
ceph使用Up Set来处理客户端请求。所谓Up Set,其实就是实际处理客户端请求的一组OSD。在大多数情况下,Up Set列表与Acting Set列表是完全相同的。而当两者不相同时,通常表明‘Ceph正在迁移数据,某一个OSD正在进行恢复’ 或者 ‘当前集群存在问题(比如: pg处于stuck stale状态)’。
要获取当前PG的所有列表,执行:
# ceph pg dump
如果要查看某一个PG的Acting Set与Up set,执行:
# ceph pg map {pg-num}
osdmap eNNN pg {raw-pg-num} ({pg-num}) -> up [0,1,2] acting [0,1,2]注: 假如Up Set与Acting Set不相等的话,通常意味着集群当前正处于重平衡状态,或者整个集群出现了潜在的故障
3. Peering
在允许向PG写数据之前,该PG必须处于active+clean状态。ceph是通过PG中主OSD与副本OSD之间的peer来获取该PG状态的:
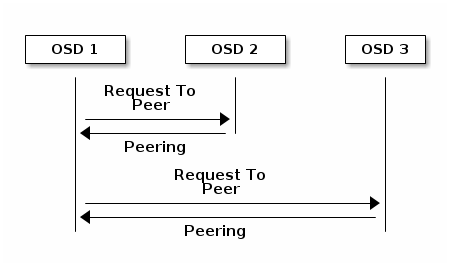
同时OSD也会向monitor主动报告其自身的状态。
4. 监控PG状态
假如你执行ceph health或者ceph -s或者ceph -w命令,你可能会发现ceph集群并不总是处于HEALTH OK状态。在你检查完OSD是否正处于运行状态之后,你也应该再检查一下PG的状态。在PG处于peering相关场景下,集群的状态可能就不是HEALTH OK了:
-
刚刚创建完一个pool,pg还为peer完成
-
PG当前正处于recovering状态
-
刚刚向集群中添加一个OSD或者从集群中移除一个OSD
-
刚刚修改完crush map,PG正处于迁移过程
-
在PG中不同副本之间的数据出现了不一致
-
一个PG的副本之间正处于scrubbing状态
-
ceph没有足够的空间来完成backfilling操作
假设出现上面的情况之一,整个集群将会处于HEALTH WARN状态。在大部分情况下,整个ceph集群都可以完成自我修复。但在有一些情况下,可能就需要人工介入来进行处理。监控PG运行情况的另一个方面就是确保在ceph集群处于up+running状态时,所有的PG处于active+clean状态。如果要查询所有PG的状态,请执行:
# ceph pg stat v61459532: x pgs: y active+clean, z active+clean+scrubbing+deep; 63243 GB data, 187 TB used, 450 TB / 638 TB avail; 21507 kB/s rd, 2751 kB/s wr, 362 op/s
上面的结果告诉我们当前总的PG个数为x,其中有y个PG处于active+clean状态,z个PG处于active+clean+scrubbing+deep状态
注: 大部分情况下,ceph集群中的PG状态都可能会有多种
另外,通过上面的命令在查询PG状态时也会打印出当前数据的使用容量,剩余容量以及总容量。这些数据在某一些场景下很有用:
-
ceph集群快达要到near full ratio或者full ratio
-
由于CRUSH的配置错误使得数据并没有均衡的分布到整个集群
1) PG ID
PG ID由三个部分组成: 存储池ID(pool number)、period(.)、pg ID(十六进制数表示):
{pool-num}.{pg-id}你可以通过执行ceph osd lspools命令来查看存储池ID以及它们的名称。比如ceph集群创建的第一个pool,其pool id为1,因此该存储池中的PG ID就类似于1.1f。
2) PG查询相关命令
如果要获取整个PG列表,请执行如下命令:
# ceph pg dump
如果想格式化输出(json格式)到一个指定文件,则可以执行如下命令:
# ceph pg dump -o {filename} --format=json
如果要查询某一个特定PG,可以执行如下的命令:
# ceph pg {poolnum}.{pg-id} query
上面命令执行之后将会以json格式打印出该PG的详细信息。
4.1 PG状态
如下我们将详细地介绍PG的常见状态。
1) CREATING
当创建存储池(pool)时,将会一并创建所指定个数的PG。在PG正处于创建过程中时,该PG的状态为creating。一旦PG创建完成,该PG Acting Set中的OSD将会开始执行peer操作。peer完成后,pg的状态变为active+clean,此时就表明ceph客户端可以开始向该PG写入数据了:

2) PEERING
当ceph正在对一个PG进行peering时,将尝试使PG中各数据副本达成一致的状态。当PG完成peering之后,这就意味着该PG中OSD之间针对当前PG的状态达成了一致。然而,peering完成之后并不意味着当前PG中各个副本都拥有当前最新的数据。
权威历史(Authoritative History)
在客户端进行写操作时,必须要等到PG acting set中的所有OSD都写成功之后才会向客户端返回ACK响应。这就保证了自上次peering操作完成后,acting set中至少有一个成员拥有每一次成功写操作(acknowledged write operation)的完整历史记录。
对每一个acknowledged write operation都有精确的记录,这就使得ceph可以构建出该PG的一个完整且有序的操作历史,然后就可以将该PG的所有OSD副本都更新到最新的一致状态。
3) ACTIVE
一旦ceph完成Peering操作之后,pg就会变为active状态。active状态意味着PG中的数据是可以执行读写操作的。
4) CLEAN
当一个PG处于clean状态时,说明PG的主OSD与副本OSD已经完成了peer,并且主副本OSD上的数据也已经是一致的了。ceph会对PG中的所有数据都复制到正确的副本数。
5) DEGRADED
当一个客户端向主OSD写入一个对象时,主OSD负责将该对象也写入到副本OSD。在主OSD将对象写入到硬盘之后,PG将会处于degraded状态,直到主OSD收到了所有副本OSD的ack应答为止。
一个PG处于active+degraded状态的原因是: 某一个OSD虽然处于active状态,但该OSD当前却并不含有全部的对象。假如某一个OSD进入down状态,ceph将会把与该OSD相关联的PG都置为degraded状态。之后如果该OSD重新上线,则相关的PG必须重新peer。然而,即使某一个pg处于degraded状态,只要该PG仍是active的,那么仍可以向该PG写入新的数据。
假如某一个OSD处于down状态,并且PG处于degraded状态一直持续的话,ceph就可能将该down状态的OSD移出集群,标记为out状态。
假如某一个OSD下线(处于down状态),那么相关的PG会处于degraded状态,在该状态持续一段时间之后(通常是300s),ceph就有可能将该down状态的OSD标记为out状态,指示该OSD已经移出集群, 然后开始将该down OSD上面的数据remap到另一个OSD。一个OSD从down状态变为out状态的时间由mon osd down out interval来控制,默认值为300s。
此外,如果ceph在某一个PG中找不到对应的object的话,ceph也可能会将该pg标记为degraded状态。对于unfound的对象,将不能够进行读写,但是你仍然可以访问处于degraded状态下PG中的其他对象。
6) RECOVERING
ceph具有高容错性,能够应对运行过程中出现的软件或硬件相关的问题。当一个osd下线(down)之后,该OSD上的数据就有可能会落后于其他副本。之后该OSD重新上线,相关的PG就必须进行更新以反应当前的最新状态。在这一过程中,OSD可能就会显示为recovering状态。
Recovery发生的概率还是很高的,因为硬件的错误会导致多个OSD都失效,之后肯定就需要对数据进行恢复。例如,某个rack的路由器出现了故障,这就可能导致多台主机上的OSD落后于当前的集群状态。之后当故障解决之后,相关的OSD就必须进行恢复。
ceph提供了许多的配置参数来平衡相应的资源,使得在数据恢复期间也能够尽量正常的为外部提供服务。osd recovery delay start配置参数用于设置在restart、re-peer多长时间之后开始进行recovery操作; osd recovery thread timeout用于设置线程的超时时间,因为多个OSD都可能失效,这样最好是错开来进行restart、repeer,以防止消耗太多的资源。osd recovery max active配置参数限制了每个OSD能够同时处理的recovery请求个数,以防止因消耗资源过多而不能对外提供服务; The osd recovery max chunk配置参数限制了在进行数据恢复时chunk的大小,用以降低网络拥塞。
7) BACKFILLING
当一个新的OSD加入到集群中之后,CRUSH会对PG进行重新映射,以将一些数据能够存放到新添加的OSD上。强制新添加的OSD马上就接受PG的指派可能会导致该OSD瞬间压力过高。而backfilling操作可以在后台进行,一旦backfilling操作完成,新添加的OSD就能够服务外部的请求。
在backfill操作过程中,你可能会看到多种状态:backfill_wait状态表明当前有一个backfill操作被挂起;backfilling状态表明backfill操作正在进行中;backfill_toofull表明s收到了一个backfill操作请求,但是由于存储容量的限制,使得该backfill操作不能够完成。当一个PG不能够backfilled时,就会显示为incomplete状态
backfill_toofull状态有可能只是暂时性的,因为当PG中相关的数据有可能会被移除,这样后面就又有可用的存储空间了。backfill_toofull状态类似于backfill_wait,只要后续相关的条件满足之后backfill就可以成功完成。
ceph提供了一系列的设置用于管理由于PG重新映射(特别是重新映射到一个新的OSD)导致的高负载。默认情况下,osd_max_backfills设置一个OSD可以同时进行的backfill数(包括backfill to与backfill from)为1。backfill full ratio用于设置一个OSD 在backfill时硬盘容量达到full ratio时就会解决相关的backfill请求,我们可以通过osd set-backfillfull-ratio命令来更改相关的值;假如某一个OSD拒绝了一个backfill请求,osd backfill retry interval使得一个OSD会在其指定的时间之后再次发起backfill请求。OSD也可以通过设置osd backfill scan min以及osd backfill scan max来管理扫描周期(默认情况下值分别为64/512)。
8) REMAPPED
当一个PG的Acting Set发生了改变之后,PG中的数据就会从老的acting set迁移到新的acting set。在这一迁移过程中,新的primary OSD可能会有一段时间不能正常的提供服务,因此还是需要请求原来到的primary OSD,直到PG中相关的数据迁移完成。一旦数据迁移完成,会使用新acting set中的primary OSD来提供服务。
9) STALE
ceph会使用heartbeat来检测hosts与daemons的运行状况,ceph-osd守护进程本身也可能会进入stuck状态,此时其就不能周期性的报告相关的运行数据(例如:临时性的网络故障)。默认情况下,OSD守护进程会隔0.5s就报告一次PG、up through、boot以及failure数据,这个报告频率是高于heartbeat的阈值的。假如一个PG的主OSD不能向monitor报告相关的运行数据,或者是PG中的其他OSD向monitor报告主OSD已经失效(down),则monitor将会把该PG的状态标记为stale。
当启动集群的时候,我们可能会经常看到stale状态,直到peering过程完成。在ceph集群运行一段时间之后,如果看到一些PG进入stale状态,这通常表明这些PG的主OSD失效(down)或者是主OSD没有向monitor报告相应的状态。
如下我们对PG相关状态进行一下总结:
-
Activating: Peering已经完成,PG正在等待所有PG实例同步并固化Peering的结果(Info、Log等)
-
Active: 活跃态。PG可以正常处理来自客户端的读写请求
-
Backfilling: 正在后台填充态。 backfill是recovery的一种特殊场景,指peering完成后,如果基于当前权威日志无法对Up Set当中的某些PG实例实施增量同步(例如承载这些PG实例的OSD离线太久,或者是新的OSD加入集群导致的PG实例整体迁移) 则通过完全拷贝当前Primary所有对象的方式进行全量同步
-
Backfill-toofull: 某个需要被Backfill的PG实例,其所在的OSD可用空间不足,Backfill流程当前被挂起
-
Backfill-wait: 等待Backfill 资源预留
-
Clean: 干净态。PG当前不存在待修复的对象, Acting Set和Up Set内容一致,并且大小等于存储池的副本数
-
Creating: PG正在被创建
-
Deep: PG正在或者即将进行对象一致性扫描清洗
-
Degraded: 降级状态。Peering完成后,PG检测到任意一个PG实例存在不一致(需要被同步/修复)的对象,或者当前ActingSet 小于存储池副本数
-
Down: Peering过程中,PG检测到某个不能被跳过的Interval中(例如该Interval期间,PG完成了Peering,并且成功切换至Active状态,从而有可能正常处理了来自客户端的读写请求),当前剩余在线的OSD不足以完成数据修复
-
Incomplete: Peering过程中, 由于 a. 无非选出权威日志 b. 通过choose_acting选出的Acting Set后续不足以完成数据修复,导致Peering无非正常完成
-
Inconsistent 不一致态。集群清理和深度清理后检测到PG中的对象在副本存在不一致,例如对象的文件大小不一致或Recovery结束后一个对象的副本丢失
-
Peered: Peering已经完成,但是PG当前ActingSet规模小于存储池规定的最小副本数(min_size)
-
Peering: 正在同步态。PG正在执行同步处理
-
Recovering: 正在恢复态。集群正在执行迁移或同步对象和他们的副本
-
Recovering-wait: 等待Recovery资源预留
-
Remapped: 重新映射态。PG活动集任何的一个改变,数据发生从老活动集到新活动集的迁移。在迁移期间还是用老的活动集中的主OSD处理客户端请求,一旦迁移完成新活动集中的主OSD开始处理
-
Repair: PG在执行Scrub过程中,如果发现存在不一致的对象,并且能够修复,则自动进行修复状态
-
Scrubbing: PG正在或者即将进行对象一致性扫描
-
Unactive: 非活跃态。PG不能处理读写请求
-
Unclean: 非干净态。PG不能从上一个失败中恢复
-
Stale: 未刷新态。PG状态没有被任何OSD更新,这说明所有存储这个PG的OSD可能挂掉, 或者Mon没有检测到Primary统计信息(网络抖动) Undersized PG当前Acting Set小于存储池副本数
-
Undersized: PG当前Acting Set小于存储池副本数
4.2 identifying troubled PGS
如上文提到的,一个PG如果其状态不是active+clean的话,并不一定意味着出现了问题。通常情况下,当一个PG进入stuck状态之后,ceph很可能不能够完成自我修复。stuck状态包括如下:
-
unclean: PG所包含的对象的副本数与所期望的不一致,需要对这些对象进行恢复
-
inactive: 由于拥有最新数据的OSD还没有运行(up),导致对应的PG不能进行读写操作
-
stale: PG当前处于unknown state,这是由于容纳该这些PG的OSD已经有一段时间没有向Monitor报告相关的状态了(由mon osd report timeout进行配置)
如果要找出处于stuck状态的PG,可以执行如下的命令:
# ceph pg dump_stuck [unclean|inactive|stale|undersized|degraded]
4.3 finding an object location
要向ceph对象存储中存放一个对象,ceph客户端必须:
-
指定对象名称(object name)
-
指定一个pool
ceph客户端接收到最新的cluster map之后,使用CRUSH算法计算出对象到PG的映射,然后再动态的计算出PG到OSD的映射。要查找一个对象的存储位置,只需要object name与pool name两个参数。例如:
# ceph osd map {poolname} {object-name} [namespace]
示例: 定位一个object
如下我们给出一个示例,讲解如何定位一个object。首先我们需要创建一个object,需要指定如下三个参数:
-
对象名称
-
文件路径,即从本地某个路径来读取内容作为我们要上传的对象的内容
-
所要上传到的存储池
例如:
# rados put {object-name} {file-path} --pool=data
# rados put test-object-1 testfile.txt --pool=data
之后我们可以执行如下命令来列出存储池中的所有对象:
# rados -p data ls
之后,我们可以通过如下命令打印出一个对象的location,例如:
# ceph osd map {pool-name} {object-name}
# ceph osd map data test-object-1
osdmap e537 pool 'data' (1) object 'test-object-1' -> pg 1.d1743484 (1.4) -> up ([0,1], p0) acting ([0,1], p0)最后,作为示例,我们可以通过执行删除命令,删除我们刚上传的对象:
# rados rm test-object-1 --pool=data
随着集群的不断运行,对象的location可能也会动态的发生改变。ceph动态平衡的一个好处就是可以不用人工进行干预。
5. PG状态详解及故障模拟
5.1 Degraded
5.1.1 说明
降级(degraded): 通常我们知道,每个PG有三个副本,分别保存在不同的OSD中,在非故障情况下,这个PG是active+clean状态,那么如果一个PG的副本挂掉了,这个PG就是降级状态。
5.1.2 故障模拟
a. 停止osd.1
# systemctl stop ceph-osd@1
b. 查看PG状态
# ceph pg stat 20 pgs: 20 active+undersized+degraded; 14512 kB data, 302 GB used, 6388 GB / 6691 GB avail; 12/36 objects degraded (33.333%)
c. 查看集群监控状态
# ceph health detail
HEALTH_WARN 1 osds down; Degraded data redundancy: 12/36 objects degraded (33.333%), 20 pgs unclean, 20 pgs degraded; application not enabled on 1 pool(s)
OSD_DOWN 1 osds down
osd.1 (root=default,host=ceph-xx-cc00) is down
PG_DEGRADED Degraded data redundancy: 12/36 objects degraded (33.333%), 20 pgs unclean, 20 pgs degraded
pg 1.0 is active+undersized+degraded, acting [0,2]
pg 1.1 is active+undersized+degraded, acting [2,0]
d. 客户端IO操作
//写入对象 # rados -p test_pool put myobject ceph.conf //读取对象到文件 # rados -p test_pool get myobject.old //查看文件 # ll ceph.conf* -rw-r--r-- 1 root root 6211 Jun 25 14:01 ceph.conf -rw-r--r-- 1 root root 6211 Jul 3 19:57 ceph.conf.old
故障总结:
为了模拟故障(size=3, min_size=2),我们手动停止了osd.1,然后查看PG状态,可见,它此刻的状态是active+undersized+degraded。当一个PG所在的OSD挂掉之后,这个PG就会进入undersized+degraded状态,而后面的[0,2]的意义就是还有两个副本存活在osd.0和osd.2上,并且这个时候客户端可以正常读写IO。
5.1.3 总结
-
降级就是在发生了一些故障比如OSD挂掉之后,Ceph将这个OSD上的所有PG标记为Degraded
-
降级的集群可以正常读写数据,降级的PG只是相当于小毛病而已,并不是严重的问题
-
undersized的意思就是当前存活的PG副本数为2,小于副本数3,将其做此标记,表示存货副本数不足,也不是严重问题
5.2 Peered
5.2.1 说明
peering已经完成,但是PG当前Acting Set规模小于存储池规定的最小副本数(min_size).
5.2.2 故障模拟
a. 停掉两个副本osd.1、osd.0
# systemctl stop ceph-osd@1 # systemctl stop ceph-osd@0
b. 查看集群健康状况
# ceph health detail
HEALTH_WARN 1 osds down; Reduced data availability: 4 pgs inactive; Degraded data redundancy: 26/39 objects degraded (66.667%), 20 pgs unclean, 20 pgs degraded; application not enabled on 1 pool(s)
OSD_DOWN 1 osds down
osd.0 (root=default,host=ceph-xx-cc00) is down
PG_AVAILABILITY Reduced data availability: 4 pgs inactive
pg 1.6 is stuck inactive for 516.741081, current state undersized+degraded+peered, last acting [2]
pg 1.10 is stuck inactive for 516.737888, current state undersized+degraded+peered, last acting [2]
pg 1.11 is stuck inactive for 516.737408, current state undersized+degraded+peered, last acting [2]
pg 1.12 is stuck inactive for 516.736955, current state undersized+degraded+peered, last acting [2]
PG_DEGRADED Degraded data redundancy: 26/39 objects degraded (66.667%), 20 pgs unclean, 20 pgs degraded
pg 1.0 is undersized+degraded+peered, acting [2]
pg 1.1 is undersized+degraded+peered, acting [2]
c. 客户端IO操作(夯住)
//读取对象到文件,夯住IO # rados -p test_pool get myobject ceph.conf.old
故障总结:
-
现在PG只剩下osd.2上存活,并且PG还多了一个状态
peered,英文的意思是仔细看,这里我们可以理解成协商、搜索。 -
这时候读取文件,会发现指令会卡在那个地方一直不动,为什么就不能读取内容了? 因为我们设置min_size=2,如果存活数小于2,比如这里的1,那么就不会响应外部的IO请求
d. 调整min_size可以解决IO夯住问题
//设置min_size = 1 # ceph osd pool set test_pool min_size 1 set pool 1 min_size to 1
e. 查看集群监控状态
# ceph health detail
HEALTH_WARN 1 osds down; Degraded data redundancy: 26/39 objects degraded (66.667%), 20 pgs unclean, 20 pgs degraded, 20 pgs undersized; application not enabled on 1 pool(s)
OSD_DOWN 1 osds down
osd.0 (root=default,host=ceph-xx-cc00) is down
PG_DEGRADED Degraded data redundancy: 26/39 objects degraded (66.667%), 20 pgs unclean, 20 pgs degraded, 20 pgs undersized
pg 1.0 is stuck undersized for 65.958983, current state active+undersized+degraded, last acting [2]
pg 1.1 is stuck undersized for 65.960092, current state active+undersized+degraded, last acting [2]
pg 1.2 is stuck undersized for 65.960974, current state active+undersized+degraded, last acting [2]
f. 客户端IO操作
//读取对象到文件中 # ll -lh ceph.conf* -rw-r--r-- 1 root root 6.1K Jun 25 14:01 ceph.conf -rw-r--r-- 1 root root 6.1K Jul 3 20:11 ceph.conf.old -rw-r--r-- 1 root root 6.1K Jul 3 20:11 ceph.conf.old.1
故障总结:
-
可以看到,PG状态peered没有了,并且客户端文件IO可以正常读写了
-
当min_size=1时,只要集群里面有一份副本活着,就可以响应外部的IO请求
5.2.3 总结
-
Peered状态我们这里可以将它理解成它在等待其他副本上线
-
当min_size=2时,也就是必须保证有两个副本存活的时候就可以去除Peered状态
-
处于Peered状态的PG是不能响应外部的请求,并且IO被挂起
5.3 Remapped
5.3.1 说明
peering完成,PG当前Acting Set与Up Set不一致就会出现Remapped状态
5.3.2 故障模拟
a. 停止osd.x
# systemctl stop ceph-osd@x
b. 间隔5分钟,启动osd.x
# systemctl start ceph-osd@x
c. 查看PG状态
# ceph pg stat 1416 pgs: 6 active+clean+remapped, 1288 active+clean, 3 stale+active+clean, 119 active+undersized+degraded; 74940 MB data, 250 GB used, 185 TB / 185 TB avail; 1292/48152 objects degraded (2.683%) # ceph pg dump | grep remapped dumped all 13.cd 0 0 0 0 0 0 2 2 active+clean+remapped 2018-07-03 20:26:14.478665 9453'2 20716:11343 [10,23] 10 [10,23,14] 10 9453'2 2018-07-03 20:26:14.478597 9453'2 2018-07-01 13:11:43.262605 3.1a 44 0 0 0 0 373293056 1500 1500 active+clean+remapped 2018-07-03 20:25:47.885366 20272'79063 20716:109173 [9,23] 9 [9,23,12] 9 20272'79063 2018-07-03 03:14:23.960537 20272'79063 2018-07-03 03:14:23.960537 5.f 0 0 0 0 0 0 0 0 active+clean+remapped 2018-07-03 20:25:47.888430 0'0 20716:15530 [23,8] 23 [23,8,22] 23 0'0 2018-07-03 06:44:05.232179 0'0 2018-06-30 22:27:16.778466 3.4a 45 0 0 0 0 390070272 1500 1500 active+clean+remapped 2018-07-03 20:25:47.886669 20272'78385 20716:108086 [7,23] 7 [7,23,17] 7 20272'78385 2018-07-03 13:49:08.190133 7998'78363 2018-06-28 10:30:38.201993 13.102 0 0 0 0 0 0 5 5 active+clean+remapped 2018-07-03 20:25:47.884983 9453'5 20716:11334 [1,23] 1 [1,23,14] 1 9453'5 2018-07-02 21:10:42.028288 9453'5 2018-07-02 21:10:42.028288 13.11d 1 0 0 0 0 4194304 1539 1539 active+clean+remapped 2018-07-03 20:25:47.886535 20343'22439 20716:86294 [4,23] 4 [4,23,15] 4 20343'22439 2018-07-03 17:21:18.567771 20343'22439 2018-07-03 17:21:18.567771 //2分钟之后查询 # ceph pg stat 1416 pgs: 2 active+undersized+degraded+remapped+backfilling, 10 active+undersized+degraded+remapped+backfill_wait, 1401 active+clean, 3 stale+active+clean; 74940 MB data, 247 GB used, 179 TB / 179 TB avail; 260/48152 objects degraded (0.540%); 49665 kB/s, 9 objects/s recovering # ceph pg dump | grep remapped dumped all 13.1e8 2 0 2 0 0 8388608 1527 1527 active+undersized+degraded+remapped+backfill_wait 2018-07-03 20:30:13.999637 9493'38727 20754:165663 [18,33,10] 18 [18,10] 18 9493'38727 2018-07-03 19:53:43.462188 0'0 2018-06-28 20:09:36.303126
d. 客户端IO操作
//rados读写正常 # rados -p test_pool put myobject /tmp/test.log
5.3.3 总结
-
在OSD挂掉或者扩容的时候,PG上的OSD会按照CRUSH算法重新分配PG所属的OSD编号,并且会把PG remap到别的OSD上去
-
remapped状态时,PG当前acting set与up set不一致
-
客户端IO可以正常读写
5.4 Recovery
5.4.1 说明
指PG通过PGLog日志针对数据不一致的对象进行同步和修复的过程
5.4.2 故障模拟
a. 停止osd.x
# systemctl stop ceph-osd@x
b. 间隔1分钟启动osd.x
# systemctl start ceph-osd@x
c. 查看集群监控状态
# ceph health detail
HEALTH_WARN Degraded data redundancy: 183/57960 objects degraded (0.316%), 17 pgs unclean, 17 pgs degraded
PG_DEGRADED Degraded data redundancy: 183/57960 objects degraded (0.316%), 17 pgs unclean, 17 pgs degraded
pg 1.19 is active+recovery_wait+degraded, acting [29,9,17]
5.4.3 总结
-
Recovery是通过记录的PGLog进行恢复数据的
-
记录的PGLog在osd_max_pg_log_entries=10000条以内,这个时候通过PGLog就能增量恢复数据
5.5 Backfill
5.5.1 说明
当PG的副本无法通过PGLog来恢复数据,这个时候就需要进行全量同步,通过完全拷贝当前Primary所有对象的方式进行全量同步。
5.5.2 故障模拟
a. 停止osd.x
# systemctl stop ceph-osd@x
b. 间隔10分钟启动osd.x
# systemctl start ceph-osd@x
c. 查看集群健康状态
# ceph health detail
HEALTH_WARN Degraded data redundancy: 6/57927 objects degraded (0.010%), 1 pg unclean, 1 pg degraded
PG_DEGRADED Degraded data redundancy: 6/57927 objects degraded (0.010%), 1 pg unclean, 1 pg degraded
pg 3.7f is active+undersized+degraded+remapped+backfilling, acting [21,29]
5.5.3 总结
-
无法根据记录的PGLog进行恢复数据时,就需要执行Backfill过程全量恢复数据
-
如果超过osd_max_pg_log_entries=10000条, 这个时候需要全量恢复数据
5.6 Stale
5.6.1 说明
-
mon检测到当前PG的Primary所在的OSD宕机
-
Primary超时未向mon上报pg相关的信息(例如网络阻塞)
-
PG内三个副本都挂掉的情况
5.6.2 故障模拟
a. 分别停止PG中的三个副本osd,首先停止osd.23
# systemctl stop ceph-osd@23
b. 然后停止osd.24
# systemctl stop ceph-osd@24
c. 查看停止两个副本后,PG 1.45的状态(undersized+degraded+peered)
# ceph health detail
HEALTH_WARN 2 osds down; Reduced data availability: 9 pgs inactive; Degraded data redundancy: 3041/47574 objects degraded (6.392%), 149 pgs unclean, 149 pgs degraded, 149 pgs undersized
OSD_DOWN 2 osds down
osd.23 (root=default,host=ceph-xx-osd02) is down
osd.24 (root=default,host=ceph-xx-osd03) is down
PG_AVAILABILITY Reduced data availability: 9 pgs inactive
pg 1.45 is stuck inactive for 281.355588, current state undersized+degraded+peered, last acting [10]
d. 再停止PG 1.45中第三个副本osd.10
# systemctl stop ceph-osd@10
e. 查看停止三个副本PG 1.45的状态(stale + undersized + degraded + peered)
# ceph health detail
HEALTH_WARN 3 osds down; Reduced data availability: 26 pgs inactive, 2 pgs stale; Degraded data redundancy: 4770/47574 objects degraded (10.026%), 222 pgs unclean, 222 pgs degraded, 222 pgs undersized
OSD_DOWN 3 osds down
osd.10 (root=default,host=ceph-xx-osd01) is down
osd.23 (root=default,host=ceph-xx-osd02) is down
osd.24 (root=default,host=ceph-xx-osd03) is down
PG_AVAILABILITY Reduced data availability: 26 pgs inactive, 2 pgs stale
pg 1.9 is stuck inactive for 171.200290, current state undersized+degraded+peered, last acting [13]
pg 1.45 is stuck stale for 171.206909, current state stale+undersized+degraded+peered, last acting [10]
pg 1.89 is stuck inactive for 435.573694, current state undersized+degraded+peered, last acting [32]
pg 1.119 is stuck inactive for 435.574626, current state undersized+degraded+peered, last acting [28]
f. 客户端IO操作
//#读写挂载磁盘IO 夯住 # rados -p test_pool put myobject /tmp/test.log # ll /mnt/
故障总结:
先停止同一个PG内两个副本,状态是 undersized+degraded+peered 然后停止同一个PG内三个副本,状态是stale+undersized+degraded+peered
5.6.3 总结
-
当出现一个PG内三个副本都挂掉的情况,就会出现stale状态
-
此时,该PG不能提供客户端读写,IO挂起夯住
-
Primary超时未向mon上报PG相关的信息(例如网络阻塞),也会出现stale状态
5.7 Inconsistent
5.7.1 说明
PG通过scrub检测到某个或者某些对象在PG实例间出现了不一致。
5.7.2 故障模拟
a. 删除PG 3.0中副本osd.34头文件
# rm -rf /var/lib/ceph/osd/ceph-34/current/3.0_head/DIR_0/1000000697c.0000122c__head_19785300__3
b. 手动执行PG 3.0进行数据清理
# ceph pg scrub 3.0 instructing pg 3.0 on osd.34 to scrub
c. 检查集群监控状态
# ceph health detail
HEALTH_ERR 1 scrub errors; Possible data damage: 1 pg inconsistent
OSD_SCRUB_ERRORS 1 scrub errors
PG_DAMAGED Possible data damage: 1 pg inconsistent
pg 3.0 is active+clean+inconsistent, acting [34,23,1]
d. 修复PG 3.0
# ceph pg repair 3.0
instructing pg 3.0 on osd.34 to repair
//查看集群监控状态
# ceph health detail
HEALTH_ERR 1 scrub errors; Possible data damage: 1 pg inconsistent, 1 pg repair
OSD_SCRUB_ERRORS 1 scrub errors
PG_DAMAGED Possible data damage: 1 pg inconsistent, 1 pg repair
pg 3.0 is active+clean+scrubbing+deep+inconsistent+repair, acting [34,23,1]
//集群监控状态已恢复正常
# ceph health detail
HEALTH_OK
故障总结:
当PG内部三个副本有数据不一致的情况,想要修复不一致的数据文件,只需要执行ceph pg repair修复指令,ceph就会从其他的副本中将丢失的文件拷贝过来进行数据修复。
5.7.3 总结
-
当OSD短暂挂掉的时候,因为集群内黑存在着两个副本,是可以正常写入的,但是osd.34内的数据并没有得到更新,过了一会osd.34上线了,这个时候osd.34的数据是陈旧的,就通过其他的OSD向osd.34进行数据的恢复,使其数据为最新的,而在这个恢复过程中,PG的状态会从inconsistent->recover->clean,最终恢复正常
-
这是集群自愈的一种场景
5.8 Down
5.8.1 说明
Peering过程中,PG检测到某个不能跳过的Interval中(例如该Interval期间,PG完成了peering,并且成功切换至active状态,从而有可能正常处理了来自客户端的读写请求),当前剩余在线的OSD不足以完成数据修复
5.8.2 故障模拟
a. 查看PG 3.7f内的副本数
# ceph pg dump | grep ^3.7f dumped all 3.7f 43 0 0 0 0 494927872 1569 1569 active+clean 2018-07-05 02:52:51.512598 21315'80115 21356:111666 [5,21,29] 5 [5,21,29] 5 21315'80115 2018-07-05 02:52:51.512568 6206'80083 2018-06-29 22:51:05.831219
b. 停止PG 3.7f副本osd.21
# systemctl stop ceph-osd@21
c. 查看PG 3.7状态
# ceph pg dump | grep ^3.7f dumped all 3.7f 66 0 89 0 0 591396864 1615 1615 active+undersized+degraded 2018-07-05 15:29:15.741318 21361'80161 21365:128307 [5,29] 5 [5,29] 5 21315'80115 2018-07-05 02:52:51.512568 6206'80083 2018-06-29 22:51:05.831219
d. 客户端写入数据,一定要确保数据写入到PG 3.7的副本中[5,29]
# fio -filename=/mnt/xxxsssss -direct=1 -iodepth 1 -thread -rw=read -ioengine=libaio -bs=4M -size=2G -numjobs=30 -runtime=200 -group_reporting -name=read-libaio
read-libaio: (g=0): rw=read, bs=4M-4M/4M-4M/4M-4M, ioengine=libaio, iodepth=1
...
fio-2.2.8
Starting 30 threads
read-libaio: Laying out IO file(s) (1 file(s) / 2048MB)
Jobs: 5 (f=5): [_(5),R(1),_(5),R(1),_(3),R(1),_(2),R(1),_(1),R(1),_(9)] [96.5% done] [1052MB/0KB/0KB /s] [263/0/0 iops] [eta 00m:02s] s]
read-libaio: (groupid=0, jobs=30): err= 0: pid=32966: Thu Jul 5 15:35:16 2018
read : io=61440MB, bw=1112.2MB/s, iops=278, runt= 55203msec
slat (msec): min=18, max=418, avg=103.77, stdev=46.19
clat (usec): min=0, max=33, avg= 2.51, stdev= 1.45
lat (msec): min=18, max=418, avg=103.77, stdev=46.19
clat percentiles (usec):
| 1.00th=[ 1], 5.00th=[ 1], 10.00th=[ 1], 20.00th=[ 2],
| 30.00th=[ 2], 40.00th=[ 2], 50.00th=[ 2], 60.00th=[ 2],
| 70.00th=[ 3], 80.00th=[ 3], 90.00th=[ 4], 95.00th=[ 5],
| 99.00th=[ 7], 99.50th=[ 8], 99.90th=[ 10], 99.95th=[ 14],
| 99.99th=[ 32]
bw (KB /s): min=15058, max=185448, per=3.48%, avg=39647.57, stdev=12643.04
lat (usec) : 2=19.59%, 4=64.52%, 10=15.78%, 20=0.08%, 50=0.03%
cpu : usr=0.01%, sys=0.37%, ctx=491792, majf=0, minf=15492
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=15360/w=0/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: io=61440MB, aggrb=1112.2MB/s, minb=1112.2MB/s, maxb=1112.2MB/s, mint=55203msec, maxt=55203msec
e. 停止PG 3.7f中副本osd.29,并且查看PG 3.7f状态(undersized+degraded+peered)
//停止该PG副本osd.29 # systemctl stop ceph-osd@29 //查看该PG 3.7f状态为undersized+degraded+peered # ceph pg dump | grep ^3.7f dumped all 3.7f 70 0 140 0 0 608174080 1623 1623 undersized+degraded+peered 2018-07-05 15:35:51.629636 21365'80169 21367:132165 [5] 5 [5] 5 21315'80115 2018-07-05 02:52:51.512568 6206'80083 2018-06-29 22:51:05.831219
f. 停止PG 3.7f中副本osd.5,并且查看PG 3.7f状态(undersized+degraded+peered)
//停止该PG副本osd.5 # systemctl stop ceph-osd@5 //查看该PG状态undersized+degraded+peered # ceph pg dump | grep ^3.7f dumped all 3.7f 70 0 140 0 0 608174080 1623 1623 stale+undersized+degraded+peered 2018-07-05 15:35:51.629636 21365'80169 21367:132165 [5] 5 [5] 5 21315'80115 2018-07-05 02:52:51.512568 6206'80083 2018-06-29 22:51:05.831219
g. 拉起PG 3.7f 中副本osd.21(此时的osd.21数据比较陈旧),查看PG状态(down)
//拉起该PG的osd.21 # systemctl start ceph-osd@21 //查看该PG的状态down # ceph pg dump | grep ^3.7f dumped all 3.7f 66 0 0 0 0 591396864 1548 1548 down 2018-07-05 15:36:38.365500 21361'80161 21370:111729 [21] 21 [21] 21 21315'80115 2018-07-05 02:52:51.512568 6206'80083 2018-06-29 22:51:05.831219
h. 客户端IO操作
//此时客户端IO都会夯住 # ll /mnt/
故障总结:
首先有一个PG 3.7f,有三个副本[5,21,29],当停掉一个osd.21之后,写入数据到osd.5、osd.29。这个时候停掉osd.29、osd.5,最后拉起osd.21。这个时候osd.21的数据比较陈旧,就会出现PG为down的情况,这个时候客户端IO会夯住,只能拉起挂掉的osd才能修复问题。
5.8.3 PG为Down的OSD丢失或者无法拉起
修复方式(生产环境已验证)
a. 删除无法拉起的OSD
b. 创建对应编号的OSD
c. PG的Down状态就会消失
d. 对于unfound 的PG ,可以选择delete或者revert
ceph pg {pg-id} mark_unfound_lost revert|delete5.8.4 结论
- 典型场景: A(主)、B、C
a. 首先kill B b. 新写入数据到 A、C c. kill A和C d. 拉起B
-
出现PG为down的场景是由于osd节点数据太旧,并且其他在线的OSD不足以完成数据修复
-
这个时候该PG不能提供客户端IO读写,IO会挂起夯住
5.9 Incomplete
Peering过程中,由于a) 无法选出权威日志 b)通过choose_acting选出的acting set后续不足以完成数据修复,导致Peering无法完成
常见于ceph集群在peering状态下,来回重启服务器,或者掉电。
5.9.1 总结
比如: PG 1.1是incomplete,先对比PG 1.1的主副本之间PG里面的对象数,哪个对象数多,就把哪个PG export出来。然后import到对象数少的PG里面,然后再mark complete(注:一定要先export PG备份)
简单方式,数据可能又丢的情况
a. stop the osd that is primary for the incomplete PG; b. run: ceph-objectstore-tool --data-path ... --journal-path ... --pgid $PGID --op mark-complete c. start the osd.
保证数据完整性
//1. 查看pg 1.1主副本里面的对象数,假设主本对象数多,则到主本所在osd节点执行 # ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-0/ --journal-path /var/lib/ceph/osd/ceph-0/journal --pgid 1.1 --op export --file /home/pg1.1 //2. 然后将/home/pg1.1 scp到副本所在节点(有多个副本,每个副本都要这么操作),然后到副本所在节点执行 # ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-1/ --journal-path /var/lib/ceph/osd/ceph-1/journal --pgid 1.1 --op import --file /home/pg1.1 //3. 然后再makr complete # ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-1/ --journal-path /var/lib/ceph/osd/ceph-1/journal --pgid 1.1 --op mark-complete //4. 最后启动osd # start osd
验证方案
//1. 把状态incomplete的pg,标记为complete。建议操作前,先在测试环境验证,并熟悉ceph-objectstore-tool工具的使用。
PS:使用ceph-objectstore-tool之前需要停止当前操作的osd,否则会报错。
//2. 查询pg 7.123的详细信息,在线使用查询
# ceph pg 7.123 query > /export/pg-7.123-query.txt
//3. 每个osd副本节点进行查询
# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-641/ --type bluestore --pgid 7.123 --op info > /export/pg-7.123-info-osd641.txt
如
pg 7.123 OSD 1 存在1,2,3,4,5 object
pg 7.123 OSD 2 存在1,2,3,6 object
pg 7.123 OSD 2 存在1,2,3,7 object
//4. 查询对比数据
//4.1 导出pg的object清单
# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-641/ --type bluestore --pgid 7.123 --op list > /export/pg-7.123-object-list-osd-641.txt
//4.2 查询pg的object数量
# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-641/ --type bluestore --pgid 7.123 --op list|wc -l
//4.3 对比所有副本的object是否一致。
# diff -u /export/pg-7.123-object-list-osd-1.txt /export/pg-7.123-object-list-osd-2.txt
比如:pg 7.123是incomplete,对比7.123的所有副本之间pg里面的object数量。
- 如上述情况,diff对比后,每个副本(主从所有副本)的object list是否一致。避免有数据不一致。使用数量最多,并且diff对比后,数量最多的包含所有object的备份。
- 如上述情况,diff对比后,数量是不一致,最多的不包含所有的object,则需要考虑不覆盖导入,再导出。最终使用完整的所有的object进行导入。注:import是需要提前remove pg后进行导入,等于覆盖导入。
- 如上述情况,diff对比后,数据是一致,则使用object数量最多的备份,然后import到object数量少的pg里面 然后在所有副本mark complete,一定要先在所有副本的osd节点export pg备份,避免异常后可恢复pg。
//5. 导出备份
查看pg 7.123所有副本里面的object数量,参考上述情况,假设osd-641的object数量多,数据diff对比一致后,则到object数量最多,object list一致的副本osd节点执行(最好是每个副本都进行导出备份,为0也需要导出备份)
# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-641/ --type bluestore --pgid 7.123 --op export --file /export/pg1.414-osd-1.obj
//6. 导入备份
然后将/export/pg1.414-osd-1.obj scp到副本所在节点,在对象少的副本osd节点执行导入。(最好是每个副本都进行导出备份,为0也需要导出备份)
将指定的pg元数据导入到当前pg,导入前需要先删除当前pg(remove之前请先export备份一下pg数据)。需要remove当前pg,否则无法导入,提示已存在。
# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-57/ --type bluestore --pgid 7.123 --op remove 需要加–force才可以删除。
# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-57/ --type bluestore --pgid 7.123 --op import --file /export/pg1.414-osd-1.obj
//7. 标记pg状态,makr complete(主从所有副本执行)
# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-57/ --type bluestore --pgid 7.123 --op mark-complete
[参看]:
