ceph通用模块
本章介绍Ceph源代码通用库中的一些比较关键而又比较复杂的数据结构。Object和Buffer相关的数据结构是普遍使用的。线程池ThreadPool可以提高消息处理的并发能力。Finisher提供了异步操作时来执行回调函数。Throttle在系统的各个模块各个环节都可以看到,它用来限制系统的请求,避免瞬时大量突发请求对系统的冲击。SafeTimer提供了定时器,为超时和定时任务等提供了相应的机制。理解这些数据结构,能够更好理解后面章节的相关内容。
1. Object
对象Object是默认为4MB大小的数据块。一个对象就对应本地文件系统中的一个文件。在代码实现中,有object、sobject、hobject、ghobject等不同的类。它们之间的类图层次结构如下所示:
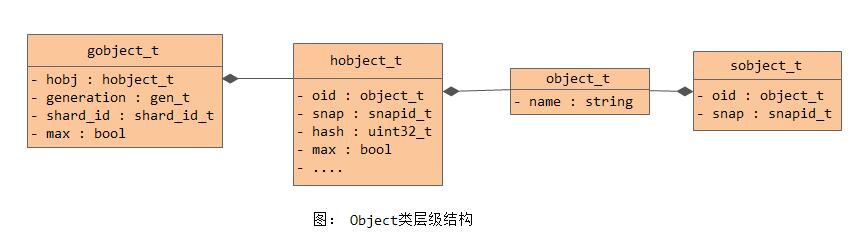
相关代码位置: src/include/object.h src/common/hobject.h
1) object_t
结构object_t对应本地文件系统的一个文件,name就是对象名:
struct object_t {
string name;
....
};另外针对object_t,在代码中对其特化了一个hash方法:
namespace std {
template<> struct hash<object_t> {
size_t operator()(const object_t& r) const {
//static hash<string> H;
//return H(r.name);
return ceph_str_hash_linux(r.name.c_str(), r.name.length());
}
};
} // namespace std2) sobject_t
sobject_t在object_t之上增加了snapshot信息,用于标识是否是快照对象。数据成员snap为快照对象的对应的快照序号。如果一个对象不是快照对象(也就是head对象),那么snap字段就被设置为CEPH_NOSNAP值。
struct sobject_t {
object_t oid;
snapid_t snap;
....
};另外针对sobject_t,在代码中对其特化了一个hash方法:
namespace std {
template<> struct hash<sobject_t> {
size_t operator()(const sobject_t &r) const {
static hash<object_t> H;
static rjhash<uint64_t> I;
return H(r.oid) ^ I(r.snap);
}
};
} // namespace std3) hobject_t
hobject_t的名字应该是hash object的缩写:
struct hobject_t {
object_t oid;
snapid_t snap;
private:
uint32_t hash;
bool max;
uint32_t nibblewise_key_cache;
uint32_t hash_reverse_bits;
static const int64_t POOL_META = -1;
static const int64_t POOL_TEMP_START = -2; // and then negative
friend class spg_t; // for POOL_TEMP_START
public:
int64_t pool;
string nspace;
private:
string key;
};如上所示,其在sobject_t的基础上增加了一些字段:
-
pool: 所在pool的id;
-
nspace: nspace一般为空,它用于标识特殊的对象;
-
key: 对象的特殊标记;
-
hash: hash和key不能同时设置,hash值一般设置为就是pg的id值;
另外针对hobject_t, 在代码中对其特化了一个hash方法:
namespace std {
template<> struct hash<hobject_t> {
size_t operator()(const hobject_t &r) const {
static hash<object_t> H;
static rjhash<uint64_t> I;
return H(r.oid) ^ I(r.snap);
}
};
} // namespace std4) ghobject_t
ghobject_t在对象hobject_t的基础上,添加了generation字段和shard_id字段,这个用于ErasureCode模式下的PG:
typedef version_t gen_t;
struct ghobject_t {
hobject_t hobj;
gen_t generation;
shard_id_t shard_id;
bool max;
....
};-
shard_id: 用于标识对象所在的OSD在EC类型的PG中的序号,对应EC来说,每个OSD在PG中的序号在数据恢复时非常关键。如果是Replicate类型的PG,那么字段就设置为NO_SHARD(-1),该字段对于replicate是没用。
-
generation: 用于记录对象的版本号。当PG为EC时,写操作需要区分写前后两个版本的object,写操作保存对象的上一个版本(generation)的对象,当EC写失败时,可以rollback到上一个版本。
另外针对ghobject_t, 在代码中对其特化了一个hash方法:
namespace std {
template<> struct hash<ghobject_t> {
size_t operator()(const ghobject_t &r) const {
static hash<object_t> H;
static rjhash<uint64_t> I;
return H(r.hobj.oid) ^ I(r.hobj.snap);
}
};
} // namespace std2. Buffer
buffer是一个命名空间,在这个命名空间下定义了Buffer相关的数据结构,这些数据结构在ceph的源代码中广泛使用。下面介绍的buffer:raw类是基础类,其子类完成了Buffer数据空间的分配;buffer::ptr类实现了Buffer内部的一段数据;buffer::list封装了多个数据段。
相关代码位置: src/include/buffer.h src/common/buffer.cc
buffer中定义的相关数据类型在外部引用时,通常都会以如下形式出现:
#ifndef BUFFER_FWD_H
#define BUFFER_FWD_H
namespace ceph {
namespace buffer {
class ptr;
class list;
class hash;
}
using bufferptr = buffer::ptr;
using bufferlist = buffer::list;
using bufferhash = buffer::hash;
}
#endif2.1 buffer::raw
类buffer::raw是一个原始的数据Buffer,在其基础之上添加了长度、引用计数和额外的crc校验信息,结构如下(src/common/buffer.cc):
class buffer::raw {
public:
char *data; //数据指针
unsigned len; //数据长度
atomic_t nref; //引用计数
mutable simple_spinlock_t crc_spinlock; //读写锁,保护crc_map
/*
* crc校验信息,第一个pair未数据段的起始和结束(from, to),第二个pair是c3c32校验码,pair的第一个字段为base crc32校验码,
* 第二个字段为加上数据段后计算出的crc32校验码。
*/
map<pair<size_t, size_t>, pair<uint32_t, uint32_t> > crc_map;
.......
};下列类都继承了buffer::raw,实现了data对应内存空间的申请:
-
类raw_malloc实现了用malloc函数分配内存空间的功能
-
类class buffer::raw_mmap_pages实现了通过mmap来把内存匿名映射到进程的地址空间
-
类class buffer::raw_posix_aligned调用了函数posix_memalign来申请内存地址对齐的内存空间
-
类class buffer::raw_hack_aligned是在系统不支持内存对齐申请的情况下自己实现了内存地址的对齐
-
类class buffer::raw_pipe实现了pipe作为Buffer的内存空间
-
类class buffer::raw_char使用了C++的new操作符来申请内存空间
2.2 buffer::ptr
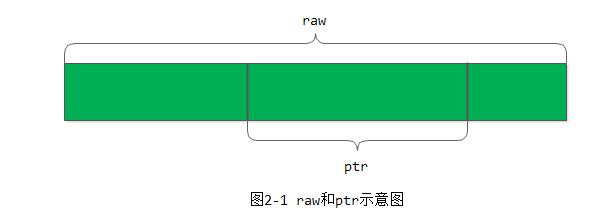
类buffer::ptr就是对于buffer::raw的一个部分数据段。结构如下:
/*
* a buffer pointer. references (a subsequence of) a raw buffer.
*/
class CEPH_BUFFER_API ptr {
raw *_raw;
unsigned _off, _len;
...
};ptr是raw里的一个任意的数据段,_off是在_raw里的偏移量,_len是ptr的长度。raw和ptr的示意图如图2-1所示:
ceph_chapter2_1.jpg
2.3 buffer::list
类buffer::list是一个使用广泛的类,它是多个buffer::ptr的列表,也就是多个内存数据段的列表。结构如下:
/*
* list - the useful bit!
*/
class CEPH_BUFFER_API list {
std::list<ptr> _buffers; //所有的ptr
unsigned _len; //所有的ptr的数据总长度
unsigned _memcopy_count; //当调用函数rebuild用来内存对齐时,需要内存拷贝的数据量
ptr append_buffer; //当有小的数据就添加到这个buffer里
mutable iterator last_p; //访问list的迭代器
....
};buffer::list的重要操作如下所示:
1) 添加一个ptr到list的头部
void push_front(ptr& bp) {
if (bp.length() == 0)
return;
_buffers.push_front(bp);
_len += bp.length();
}2) 添加一个raw到list的头部中,先构造一个ptr,后添加到list中
void push_front(raw *r) {
push_front(ptr(r));
}3) 判断内存是否以参数align对齐,每一个ptr都必须以align对齐
bool buffer::list::is_aligned(unsigned align) const
{
for (std::list<ptr>::const_iterator it = _buffers.begin();it != _buffers.end();++it)
if (!it->is_aligned(align))
return false;
return true;
}4) 添加一个字符到list中,先查看append_buffer是否有足够的空间,如果没有,就新申请一个4KB大小的空间
void buffer::list::append(char c)
{
// put what we can into the existing append_buffer.
unsigned gap = append_buffer.unused_tail_length();
if (!gap) {
// make a new append_buffer!
append_buffer = raw_combined::create(CEPH_BUFFER_APPEND_SIZE);
append_buffer.set_length(0); // unused, so far.
}
append(append_buffer, append_buffer.append(c) - 1, 1); // add segment to the list
}5) 内存对齐
有些情况下,需要内存地址对齐,例如当以directIO方式写入数据至磁盘时,需要内存地址按内存页面大小(page)对齐,也即buffer::list的内存地址都需按page对齐。函数rebuild用来完成对齐的功能。其实现方法也比较简单,检查没有对齐的ptr,申请一块新对齐的内存,把数据拷贝过去,释放内存空间就可以了。
6) buffer::list还集成了其他额外的一些功能
-
把数据写入文件或从文件读取数据的功能
-
计算数据的crc32校验
3. encode/decode
在ceph中,很多地方涉及到需要将某一种类型的数据编码到bufferlist中,这里简单的进行一下说明(编码的主要实现位于src/include/encoding.h中):
template<class T>
inline void encode_raw(const T& t, bufferlist& bl)
{
bl.append((char*)&t, sizeof(t));
}
template<class T>
inline void decode_raw(T& t, bufferlist::iterator &p)
{
p.copy(sizeof(t), (char*)&t);
}
#define WRITE_RAW_ENCODER(type) \
inline void encode(const type &v, bufferlist& bl, uint64_t features=0) { encode_raw(v, bl); } \
inline void decode(type &v, bufferlist::iterator& p) { __ASSERT_FUNCTION decode_raw(v, p); }
WRITE_RAW_ENCODER(__u8)
#ifndef _CHAR_IS_SIGNED
WRITE_RAW_ENCODER(__s8)
#endif
WRITE_RAW_ENCODER(char)
WRITE_RAW_ENCODER(ceph_le64)
WRITE_RAW_ENCODER(ceph_le32)
WRITE_RAW_ENCODER(ceph_le16)
// FIXME: we need to choose some portable floating point encoding here
WRITE_RAW_ENCODER(float)
WRITE_RAW_ENCODER(double)
inline void encode(const bool &v, bufferlist& bl) {
__u8 vv = v;
encode_raw(vv, bl);
}
inline void decode(bool &v, bufferlist::iterator& p) {
__u8 vv;
decode_raw(vv, p);
v = vv;
}
// -----------------------------------
// int types
#define WRITE_INTTYPE_ENCODER(type, etype) \
inline void encode(type v, bufferlist& bl, uint64_t features=0) { \
ceph_##etype e; \
e = v; \
encode_raw(e, bl); \
} \
inline void decode(type &v, bufferlist::iterator& p) { \
ceph_##etype e; \
decode_raw(e, p); \
v = e; \
}
WRITE_INTTYPE_ENCODER(uint64_t, le64)
WRITE_INTTYPE_ENCODER(int64_t, le64)
WRITE_INTTYPE_ENCODER(uint32_t, le32)
WRITE_INTTYPE_ENCODER(int32_t, le32)
WRITE_INTTYPE_ENCODER(uint16_t, le16)
WRITE_INTTYPE_ENCODER(int16_t, le16)从上面可以看出,对基本数据类型的编码还是比较简单,不考虑大小端。
4. 线程池
线程池(ThreadPool)在分布式存储系统的实现中是必不可少的,在ceph的代码中广泛用到。Ceph中线程池的实现也比较复杂,结构如下:
class ThreadPool : public md_config_obs_t {
CephContext *cct;
string name; //线程池的名字
string thread_name; //线程池中线程的名字
string lockname; //锁的名字
Mutex _lock; //线程互斥的锁,也是工作队列访问互斥的锁
Cond _cond; //锁对应的条件变量
bool _stop; //线程池是否停止的标志
int _pause; //暂时终止线程池的标志
int _draining;
Cond _wait_cond;
int ioprio_class, ioprio_priority;
vector<WorkQueue_*> work_queues; //工作队列
int last_work_queue; //最后访问的工作队列(work_queues)
set<WorkThread*> _threads; //线程池中的工作线程
//< need to be joined(如果线程在运行过程中,发现线程数超出了当前的设置,
//那么就会自动退出,从而加入到等待joined的队列中)
list<WorkThread*> _old_threads;
int processing; //当前正在处理的任务数
};类ThreadPool里包含一些比较重要的数据成员:
-
_threads: 工作线程集合;
-
_old_threads: 等待join操作的旧线程集合;
-
work_queues: 工作队列集合,保存所有要处理的任务。一般情况下,一个工作队列对应一个类型的处理任务,一个线程池对应一个工作队列,专门用于处理该类型的任务。如果是后台任务,又不紧急,就可以多个工作队列放置到一个线程池里,该线程池可以处理不同类型的任务。
另外,ThreadPool中还含有大量的内部类,从而使得代码结构比较冗长,这里我们列出:
class ThreadPool : public md_config_obs_t {
public:
//通过heartbeat的方式检测线程池中的线程是否处于健康状态,假如某一个任务执行时间过程,
//则会被heartbeat判断为违规,并打印出相应的提示
class TPHandle {};
private:
/// Basic interface to a work queue used by the worker threads.
struct WorkQueue_ {};
public:
/** @brief Work queue that processes several submitted items at once.
* The queue will automatically add itself to the thread pool on construction
* and remove itself on destruction. */
template<class T>
class BatchWorkQueue : public WorkQueue_ {};
/** @brief Templated by-value work queue.
* Skeleton implementation of a queue that processes items submitted by value.
* This is useful if the items are single primitive values or very small objects
* (a few bytes). The queue will automatically add itself to the thread pool on
* construction and remove itself on destruction. */
template<typename T, typename U = T>
class WorkQueueVal : public WorkQueue_ {};
/** @brief Template by-pointer work queue.
* Skeleton implementation of a queue that processes items of a given type submitted as pointers.
* This is useful when the work item are large or include dynamically allocated memory. The queue
* will automatically add itself to the thread pool on construction and remove itself on
* destruction. */
template<class T>
class WorkQueue : public WorkQueue_ {};
template<typename T>
class PointerWQ : public WorkQueue_ {};
struct WorkThread : public Thread {};
};下面我们简要介绍一下ThreadPool中的一些内部类:
-
TPHandle: 是ThreadPool Handle的简称,线程池中的每一个线程在执行队列任务时,都会通过heartbeat来检测是否工作超时。在src/common/ceph_context.cc中,CephContext会启动一个service线程来执行heartbeat操作,在其中就会检测注册到cct->get_heartbeat_map()中的handle。
-
WorkQueue_: 线程池相关的工作队列的抽象
-
BatchWorkQueue:可以批量的处理工作队列中的任务。此外,在创建BatchWorkQueue时,其会自动的加入到线程池中;而在对其进行销毁时,也可以自动的从线程池中移除。
-
WorkQueueVal: 通过by-value的形式对WorkQueue_进行的特化。对于一些small objects或者基本数据类型而言,直接通过by-value的形式来进行入队列、出队列均能够获得较好的性能。同样在创建WorkQueueVal时,其会自动的加入到线程池中;而在对其进行销毁时,也可以自动的从线程池中移除。
-
WorkQueue:通过by-pointer的形式对WorkQueue_进行特化,这样在处理一些大对象时,使用此队列可以获得较好的性能。同样在创建WorkQueue时,其会自动的加入到线程池中;而在对其进行销毁时,也可以自动的从线程池中移除。
-
PointerWQ: 是一个by-pointer形式的WorkQueue。其用一个std::list来存放相应的任务,注意PointerWQ是一个具体的实现,并不是一个抽象类。(注意PointerWQ::drain()的实现)
-
WorkThread: 线程池中的工作线程的抽象
注: 对于ThreadPool的测试,我们可以参看ceph中已有的单元测试程序src/test/test_workqueue.cc
线程池的实现主要包括:线程池的启动过程,线程池对应的工作队列的管理,线程池对应的执行函数如何执行任务。下面分别介绍这些实现。然后介绍一些Ceph线程池实现的超时检查功能,最后介绍ShardedThreadPool的实现原理。
4.1 线程池的启动
函数ThreadPool::start()用来启动线程池,其在加锁的情况下,调用函数start_threads(),该函数检查当前线程数,如果小于配置的线程数,就创建新的工作线程。
4.2 工作队列
工作队列(WorkQueue)定义了线程池要处理的任务,任务类型在模板参数中指定。在构造函数里,就把自己加入到线程池的工作队列集合中:
template<class T>
class WorkQueue : public WorkQueue_ {
ThreadPool *pool;
public:
WorkQueue(string n, time_t ti, time_t sti, ThreadPool* p) : WorkQueue_(n, ti, sti), pool(p) {
pool->add_work_queue(this);
}
....
};WorkQueue实现了一部分功能: 进队列和出队列,以及加锁,并通过条件变量通知相应的处理线程:
bool queue(T *item) {
pool->_lock.Lock();
bool r = _enqueue(item);
pool->_cond.SignalOne();
pool->_lock.Unlock();
return r;
}
void dequeue(T *item) {
pool->_lock.Lock();
_dequeue(item);
pool->_lock.Unlock();
}
void clear() {
pool->_lock.Lock();
_clear();
pool->_lock.Unlock();
}还有一部分功能,需要使用者自己定义。需要自己定义实现保存任务的容器,添加和删除方法,以及如何处理任务的方法:
virtual bool _enqueue(T *) = 0;
virtual void _dequeue(T *) = 0;
virtual T *_dequeue() = 0;
virtual void _process(T *t, TPHandle &) = 0;4.3 线程池的执行函数
函数worker为线程池的执行函数:
void ThreadPool::worker(WorkThread *wt);其处理过程如下:
1) 首先检查_stop标志,确保线程池没有关闭;
2) 调用函数join_old_threads()把旧的工作线程释放掉。检查如果线程数量大于配置的数量_num_threads,就把当前线程从线程集合中删除,并加入_old_threads队列中,并退出循环;
3) 如果线程池没有暂停,并且work_queues不为空,就从last_work_queue开始,遍历每一个工作队列,如果工作队列不为空,就取出一个item,调用工作队列的处理函数做处理。
4.4 超时检查
TPHandle是一个有意思的事情,每次线程函数执行时,都会设置一个grace超时时间,当线程执行超过该时间,就认为是unhealthy的状态。当执行时间超过suicide_grace时,OSD就会产生断言而导致自杀,代码如下:
struct heartbeat_handle_d {
const std::string name;
atomic_t timeout, suicide_timeout;
time_t grace, suicide_grace;
std::list<heartbeat_handle_d*>::iterator list_item;
explicit heartbeat_handle_d(const std::string& n)
: name(n), grace(0), suicide_grace(0)
{ }
};
class TPHandle {
friend class ThreadPool;
CephContext *cct;
heartbeat_handle_d *hb;
time_t grace;
time_t suicide_grace;
public:
TPHandle(
CephContext *cct,
heartbeat_handle_d *hb,
time_t grace,
time_t suicide_grace)
: cct(cct), hb(hb), grace(grace), suicide_grace(suicide_grace) {}
void reset_tp_timeout();
void suspend_tp_timeout();
};结构体heartbeat_handle_d记录了相关信息,并把该结构添加到HeartbeatMap的系统链表中保存。OSD会有一个定时器,定时检查是否超时。
4.5 SharedThreadPool
这里简单介绍一个SharedThreadPool。在之前的介绍中,ThreadPool实现的线程池,其每个线程都有机会处理工作队列的任意一个任务。这就会导致一个问题,如果任务之间有互斥性,那么正在处理该任务的两个线程有一个必须等待另一个处理完成后才能处理,从而导致线程的阻塞,性能下降。
例如下表2-1所示,线程Thread1和Thread2分别正在处理Job1和Job2:

由于Job1和Job2的关联性,二者不能并发执行,只能顺序执行,二者之间用一个互斥锁来控制。如果Thread1先获得互斥锁就先执行,Thread2必须等待,直到Thread1执行完Job1后释放了互斥锁,Thread2获得该互斥锁才能执行Job2.显然,这种任务的调度方式应对这种不能完全并行的任务是由缺陷的。实际上Thread2可以去执行其他任务,比如Job5。Job1和Job2既然是顺序的,就都可以交给Thread1执行。
因此,引入了SharedThreadPool进行管理。SharedThreadPool对上述的任务调度方式做了改进,其在线程的执行函数里,添加了表示线程的thread_index:
void shardedthreadpool_worker(uint32_t thread_index);具体如何实现Shard方式,还需要使用者自己去实现。其基本的思想就是: 每个线程对应一个任务队列,所有需要顺序执行的任务都放在同一个线程的任务队列里,全部由该线程执行。
5. Finisher
类Finisher用来完成回调函数Context的执行,其内部有一个FinisherThread线程来用于执行Context回调函数:
class Finisher {
CephContext *cct;
Mutex finisher_lock; //Protects access to queues and finisher_running.
Cond finisher_cond; //Signaled when there is something to process
Cond finisher_empty_cond; //Signaled when the finisher has nothing more to process
bool finisher_stop //Set when the finisher should stop
bool finisher_running; //True when the finisher is currently executing contexts.
//需要执行的Context列表。若对应的Context不为NULL,则执行complete(0)回调; 否则,表明应该执行finisher_queue_rval
//队列中相应元素的complete(r)回调
vector<Context*> finisher_queue;
//执行complete(r)这样的回调
list<pair<Context*,int> > finisher_queue_rval;
};6. Throttle
类Throttle用来限制消费的资源数量(也常称为槽位”slot”),当请求的slot数量达到max值时,请求就会被阻塞在一个队列中,直到有新的slot被释放出来,然后会唤醒阻塞在队列中的第一个请求。代码如下(src/common/throttle.cc):
class Throttle {
CephContext *cct;
const std::string name;
PerfCounters *logger;
ceph::atomic_t count, max; //count: 当前占用的slot数量 max: slot数量的最大值
Mutex lock; //等待的互斥锁
list<Cond*> cond; //等待的条件变量。这里采用队列,因为在slot被释放时,排在队列头的请求应该优先被满足
const bool use_perf;
};1) 函数get
函数原型如下:
bool Throttle::get(int64_t c, int64_t m);函数get()用于获取数量为c个slot,参数c默认为1,参数m默认为0。如果m不为默认的值0,就用m值重新设置slot的max值。如果成功获取数量为c个slot,就返回true,否则就阻塞等待。
2) 函数get_or_fail
原型如下:
bool Throttle::get_or_fail(int64_t c);函数get_or_fail()当获取不到数量为c个slot时,就直接返回false,不阻塞等待。
3) 函数put
原型如下:
int64_t Throttle::put(int64_t c);函数put用于释放数量为c个slot资源。
7. SafeTimer
类SafeTimer实现了定时器的功能,代码如下(src/common/timer.cc):
class SafeTimer{
CephContext *cct;
Mutex& lock;
Cond cond;
bool safe_callbacks; //是否是safe_callbacks
SafeTimerThread *thread; //定时器执行线程
//目标时间和定时任务执行函数Context
std::multimap<utime_t, Context*> schedule;
//定时任务<--->定时任务在schedule中的位置映射
std::map<Context*, std::multimap<utime_t, Context*>::iterator> events;
bool stopping;
};添加定时任务的命令如下:
void SafeTimer::add_event_at(utime_t when, Context *callback);取消定时任务的命令如下:
bool SafeTimer::cancel_event(Context *callback);定时任务的执行如下:
void SafeTimer::timer_thread();
[参看]
