CRUSH数据分布算法
本章我们介绍一下ceph的数据分布算法CRUSH,它是一个相对比较独立的模块,和其他模块的耦合性比较少,功能比较清晰,比较容易理解。在客户端和服务器都有CRUSH的计算,了解它可以更好地理解后面的章节。
CRUSH算法解决了PG的副本如何分布在集群的OSD上的问题。我们首先会介绍CRUSH算法的原理,并给出相应的示例,然后进一步分析其实现的一些核心代码。
1. 数据分布算法的挑战
存储系统的数据分布算法要解决数据如何分布到集群中的各个节点和磁盘上,其面临如下的挑战:
-
数据分布和负载均衡: 首先是数据分布均衡,使数据能均匀地分布在各个节点和磁盘上。其次是负载均衡,使数据访问(读写等操作)的负载在各个节点和磁盘上均衡。
-
灵活应对集群伸缩: 系统可以方便地增加或者删除存储设备(包括节点和设备失效的处理)。当增加或者删除存储设备后,能自动实现数据的均衡,并且迁移的数据尽可能地少。
-
支持大规模集群: 为了支持大规模的存储集群,就要求数据分布算法维护的元数据相对较小,并且计算量不能太大。随着集群规模的增加,数据分布算法的开销比较小。
在分布式存储系统中,数据分布算法对于分布式存储系统至关重要。目前有两种基本实现方法,一种是基于集中式的元数据查询的方式,如HDFS的实现: 文件的分布信息(layout信息)是通过访问集中式元数据服务器获得;另一种是基于分布式算法以计算获得。例如一致性哈希算法(DHT)等。Ceph的数据分布算法CRUSH就属于后者。
2. CRUSH算法的原理
CRUSH算法的全称为: Controlled、Scalable、Decentralized Placement of Replicated Data,可控的、可扩展的、分布式的副本数据放置算法。
由前面介绍过的RADOS对象寻址过程可知,CRUSH算法解决PG如何映射到OSD列表中。其过程可以看成函数:
CRUSH(X) -> (OSDi, OSDj, OSDk)输入参数:
-
X为要计算的PG的pg_id
-
Hierachical Cluster Map为Ceph集群的拓扑结构
-
Placement Rules为选择策略
输出一组可用的OSD列表。
下面将分别详细介绍Hierachical Cluster Map的定义和组织方式。Placement rules定义了副本选择的规则。最后介绍Bucket随机选择算法的实现。
2.1 层次化的Cluster Map
层次化的Cluster Map定义了OSD集群具有层级关系的静态拓扑结构。OSD的层级使得CRUSH算法在选择OSD时实现了机架感知(rack awareness)的能力,也就是通过规则定义,使得副本可以分布在不同的机架、不同的机房中,提供数据的安全性。
层级化的Cluster Map的一些基本概念如下:
-
Device: 最基本的存储设备,也就是OSD,一个OSD对应一个磁盘存储设备;
-
Bucket: 设备的容器,可以递归的包含多个设备或者子类型的bucket。Bucket的类型可以有很多种,例如host就代表了一个节点,可以包含多个device;rack就是机架,包含多个host等。在ceph里,默认的有root、datacenter、room、row、rack、host六个等级。用户也可以自己定义新的类型。每个device都设置了自己的权重,和自己的存储空间相关。bucket的权重就是子bucket(或者device)的权重之和。
下面举例说明bucket的用法:
例4-1 Cluster Map的定义
host test1{ //类型host,名字为test1
id -2 //bucket的id,一般为负值
# weight 3.000 //权重,默认为子item的权重之和
alg straw //bucket随机选择的算法
hash 0 //bucket随机选择的算法使用的hash函数,这里0代表使用hash函数jenkins1
item osd.1 weight 1.000 //item1: osd.1和权重
item osd.2 weight 1.000
item osd.3 weight 1.000
}
host test2{
id -3
# weight 3.000
alg straw
hash 0
item osd.3 weight 1.000
item osd.4 weight 1.000
item osd.5 weight 1.000
}
root default{ //root的类型为bucket,名字为default
id -1 //id号
# weight 6.000
alg straw
hash 0
item test1 weight 3.000
item test2 weight 3.000
}根据上面Cluster Map的语法定义,下图4-1给出了比较直观的层级化的树形结构。
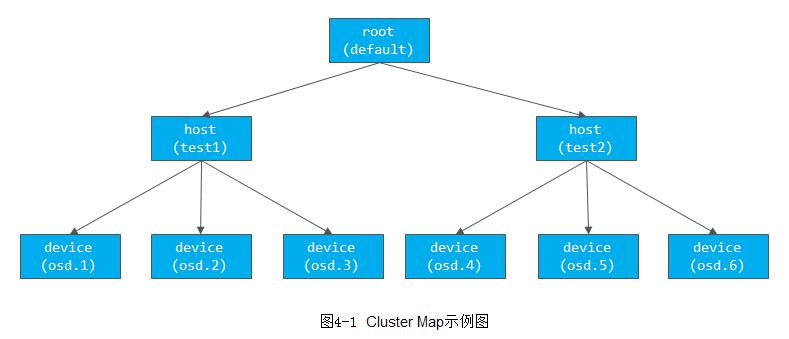
在上面的Cluster Map定义中:
-
有一个root类型的bucket,名字为default
-
root下面有两个host类型的bucket,名字分别为test1和test2,其下分别有三个osd设备,每个device的权重都为1.000,说明它们的容量大小都相同。host的权重为子设备之和为3.000,它是自动计算的,不需要设置
-
Hash设置了使用的hash函数,值0代表使用rjenkins1函数。(参看src/crush/hash.h)
-
alg代表在该bucket里选择子item的算法
2.2 Placement Rules
Cluster Map反映了存储系统层级的物理拓扑结构。Placement Rules决定了一个PG的对象副本是如何选择的,通过这些可以自己设定规则,用户可以设定副本在集群中的分布。其定义格式如下:
take(a)
choose
choose firstn {num} type {bucket-type}
chooseleaf firstn {num} type {bucket-type}
If {num} == 0, choose pool-num-replicas buckets (all-available).
If {num} > 0 && < pool-num-replicas, choose that many buckets.
If {num} < 0, it means pool-num-replicas - |{num}|.
EmitPlacement Rules的执行流程如下:
1) take操作选择一个bucket,一般是root类型的bucket。
2) choose操作有不同的选择方式,其输入都是上一步的输出:
a) choose firstn深度优先选择出num个类型为bucket-type的子bucket
b) chooseleaf先选择出num个类型为bucket-type的子bucket,然后递归到叶节点,选择一个OSD设备:
如果num为0,num就为pool设置的副本数; 如果num大于0,小于pool的副本数,那么就选出num个; 如果num小于0, 就选出pool的副本数减去num的绝对值;
3) emit输出结果。
操作chooseleaf firstn {num} type {bucket-type}可以等同于两个操作:
a) choose firstn {num} type {bucket-type}
b) choose firstn 1 type osd
下面我们给出一个rules的示例:
rule replicated_sata {
ruleset 5
type replicated
min_size 1
max_size 10
step take ceph-test-sata
step chooseleaf firstn 0 type rack
step emit
}例4-2 Placement Rules: 三个副本分布在三个Cabinet中
如下图4-2所示的Cluster Map: 顶层是一个root bucket,每个root下有4个row类型bucket。每个row下面有4个cabinet,每个cabinet下有若干个OSD设备(图中有4个host,每个host有若干个OSD设备,但是在本crush map中并没有设置host这一级别的bucket,而是直接把4个host上的所有OSD设备定义为一个cabinet):
rule replicated_ruleset {
ruleset 0 //ruleset的编号id
type replicated //类型replicated或者erasure code
min_size 1 //副本数最小值
max_size 10 //副本数最大值
step take root //选择一个root bucket,做下一步的输入
step choose firstn 1 type row //选择一个row,同一排
step choose firstn 3 type cabinet //选择三个cabinet,三副本分别在不同的cabinet
step choose firstn 1 type osd //在上一步输出的3个cabinet中,分别选择一个OSD
step emit
}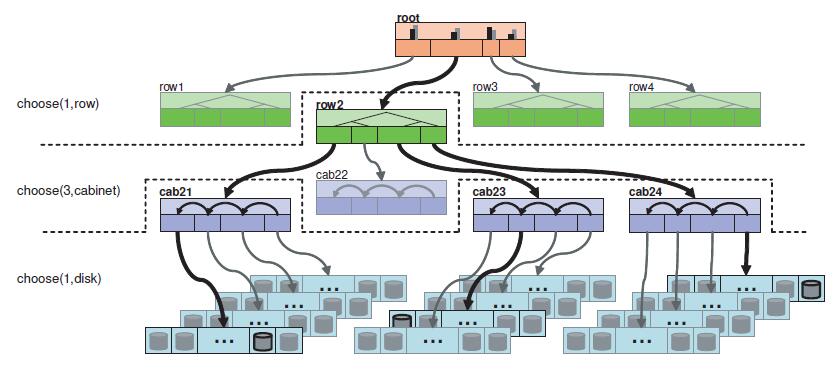
根据上面的定义和图中所示的Cluster Map,选择算法的执行过程如下:
1) 选中root bucket作为下一个步骤的输入;
2) 从root类型的bucket中选择一个row类的子bucket,其选择的算法在root的定义中设置,一般设置为straw算法;
3) 从上一步的输出row中,选择三个cabinet,其选择的算法在row中定义;
4) 从上一步输出的三个cabinet中,分别选出一个OSD,并输出
根据本rule sets,选择出三个OSD设备分布在一个row上的三个cabinet中。
例4-3 Placement Rules: 主副本分布在SSD上,其他副本分布在HDD上
如下图4-3所示的Cluster Map: 定义了两个root类型的bucket,一个是名为SSD的root类型的bucket,其OSD存储介质都是SSD盘。它包含两个host,每个host上的设备都是SSD磁盘;另一个是名为HDD的root类型的bucket,其OSD存储介质都是HDD磁盘,它有两个host,每个host上的设备都是HDD磁盘。
rule ssd-primary {
ruleset 5
type replicated
min_size 5
max_size 10
step take ssd //选择ssd这个root bucket为输入
step chooseleaf firstn 1 type host //选择一个host, 并递归选择叶子节点OSD
step emit //输出结果
step take hdd //选择hdd这个root bucket为输入
step chooseleaf firstn -1 type host //选择总副本数减一个host,并分别递归选择一个叶子节点OSD
step emit //输出结果
}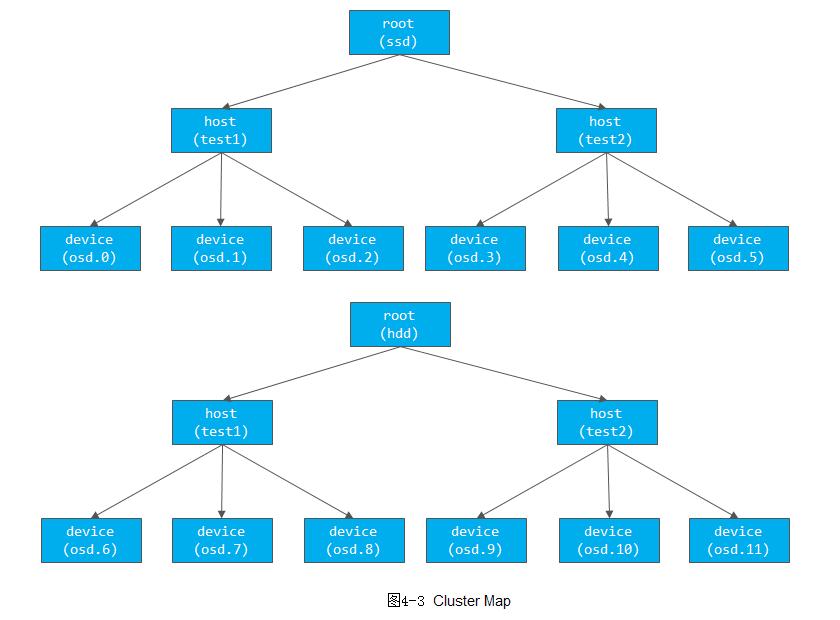
根据上图4-3所示的Cluster Map,代码中的ruleset的执行过程如下:
1) 首先take操作选择ssd为root类型的bucket;
2) 在ssd的root中先选择一个host,然后以该host为输入,递归至叶子节点,选择一个OSD设备;
3) 输出选择的设备,也就是ssd设备;
4) 选择hdd作为root的输入;
5) 选择2个host(副本数减一,默认3副本),并分别递归选择一个OSD设备,最终选出两个hdd设备
6) 输出最终结果。
最终输出3个设备,一个是SSD类型的磁盘,另外两个是HDD磁盘。通过上述规则,就可以把PG的主副本分布在SSD类型的OSD上,其他副本分布在HDD类型的磁盘上。
2.3 Bucket随机选择算法
Bucket随机选择算法解决了如何从Bucket中选择出需要的子item的问题。它定义了四种不同的Bucket选择算法,每种Bucket的选择算法基于不同的数据结构,采用不同的伪随机选择函数。
在本节涉及的Hash函数,其参数分别为:
hash(x, r, i)-
x为要计算的PG的id;
-
r为选择的副本序号;
-
i为bucket的id号
下面具体介绍Bucket的四种随机选择算法的过程,并介绍当选择算法出现冲突、失效或过载等特殊情况的处理。
1. Uniform Bucket
Uniform类型适用于每个item具有相同权重,且item很少添加和删除,也就是item的数量比较固定。它用了伪随机排列算法。uniform bucket实现结构如下(src/crush/crush.h):
struct crush_bucket_uniform {
struct crush_bucket h;
__u32 item_weight; /* 16-bit fixed point; all items equally weighted */
};2. List Bucket
List类型的Bucket中,其子item在内存中使用数据结构中的链表来保存,其所包含的item可以具有任意权重。具体查找方法如下:
1) 从List Bucket的表头item开始查找,它先得到表头item的权重Wh,剩余链表中所有item的权重之和为Ws;
2) 根据本节提到的hash(x, r, i)函数得到一个[0~1]的值v,假如这个值v在[0~Wh/Ws]之中,则选择表头item,并返回表头item的id值。
3) 否则继续遍历剩余的链表,继续递归选择。
通过上述介绍可知,List类型的Bucket查找复杂度是O(n)。
list bucket实现结构如下(src/crush/crush.h):
struct crush_bucket_list {
struct crush_bucket h;
__u32 *item_weights; /* 16-bit fixed point */
__u32 *sum_weights; /* 16-bit fixed point. element i is sum of weights 0..i, inclusive */
};3. Tree Bucket
Tree类型的Bucket其item组织成树结构: 每个item组成决策树的叶子节点。根节点和中间节点是虚节点,其权重等于左右子树的权重之和。由于item在叶子节点,所以每次选择只能走到叶子节点才能选择一个item处理。其具体查找方法如下:
1) 从该Tree Bucket的root item(虚节点)开始遍历
2) 它先得到节点的左子树的权重Wl,得到节点的权重为Wn,然后根据hash函数hash(x, r, i)得到一个[0~1]的值v:
a) 如果v在[0~Wl/Wn]之间,那么左子树中继续选择item;
b) 否则在右子树中选择item;
&empsp;c) 继续比那里子树,直到到达叶子节点,叶子节点item为最终选出的一个结果。
由上述过程可知,Tree Bucket每次选择一个item都要遍历到子节点。其查找复杂度是O(log n)。
tree bucket实现结构如下(src/crush/crush.h):
struct crush_bucket_tree {
struct crush_bucket h; /* note: h.size is _tree_ size, not number of actual items */
__u8 num_nodes;
__u32 *node_weights;
};4. Straw Bucket
straw类的Bucket为默认的选择算法。该Bucket中的item选中概率是相同的,其实现如下:
1) 函数f(Wi)为和item的权重Wi相关的函数,决定了每个item被选中的概率。
2) 给每个item计算出一个长度,其计算公式为:
length = f(Wi) * hash(x, r, i)length值最大的item就是被选中的item。
straw bucket实现结构如下(src/crush/crush.h):
struct crush_bucket_straw {
struct crush_bucket h;
__u32 *item_weights; /* 16-bit fixed point */
__u32 *straws; /* 16-bit fixed point */
};5. Bucket选择算法的对比
如下表4-1所示:
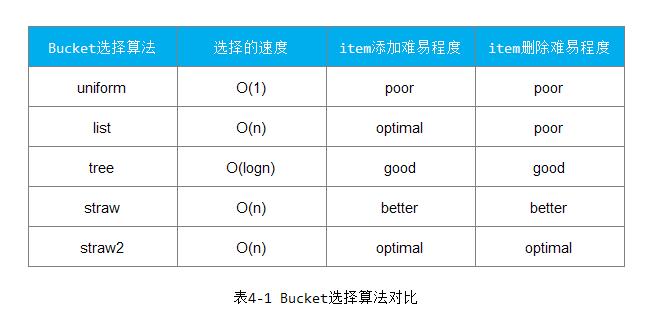
算法straw比较容易应对item的添加和删除,为默认的Bucket选择算法。算法straw2是对算法staw的一些改进,可以减少数据的迁移数量。
6. 冲突、失效或者过载
当通过上述Bucket选择算法选出一个OSD后,有可能出现冲突(重复选择)、对应的OSD已经失效了、或者过载(负载过重)的情况,就需要重新选择一次。
根据上述算法分析,选择时都依赖哈希函数:
hash(x, r, i)其中,x为PG的id,r为选在的副本数,i为bucket的id号。当选择出现删除情况,即需要重新选择。而上述各种Bucket选择算法都依赖hash函数,因此当重新选择时,把参数r顺序增加即可通过上述hash函数重新计算一个新的hash值。
例4-4 冲突选择过程
过程如下表4-2所示:
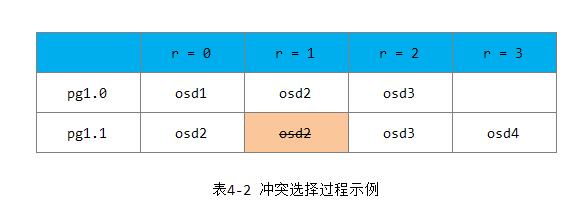
说明如下:
1) pg 1.0根据副本r分别等于0、1、2来计算hash(x, r, i),处理OSD列表{osd1, osd2, osd3}。
2) pg 1.1根据同样的方法: 在r等于0时选择出了osd2,在r等于1时又选择了osd2,产生了冲突。这是就用r分别等于2、3来继续选择剩余的副本。最终pg 1.1选择出的OSD列表为{osd2, osd3, osd4}。
3. 代码是现房分析
在介绍了CRUSH算法的原理之后,下面就分析CRUSH算法实现的关键数据结构,并对具体实现函数进行分析。
3.1 相关的数据结构
CRUSH算法相关的数据结构有crush_map结构、crush_bucket结构和crush_rule结构,下面将详细介绍。
1. crush_map
结构crush_map定义了静态的所有Cluster Map的bucket。bucket为动态申请的二维数组,保存了所有的bucket结构。rules定义了所有的crush_rule结构(src/crush/:
/*
* CRUSH map includes all buckets, rules, etc.
*/
struct crush_map {
struct crush_bucket **buckets;
struct crush_rule **rules;
__s32 max_buckets;
__u32 max_rules;
__s32 max_devices;
/* choose local retries before re-descent */
__u32 choose_local_tries;
/* choose local attempts using a fallback permutation before
* re-descent */
__u32 choose_local_fallback_tries;
/* choose attempts before giving up */
__u32 choose_total_tries;
/* attempt chooseleaf inner descent once for firstn mode; on
* reject retry outer descent. Note that this does *not*
* apply to a collision: in that case we will retry as we used
* to. */
__u32 chooseleaf_descend_once;
/* if non-zero, feed r into chooseleaf, bit-shifted right by (r-1)
* bits. a value of 1 is best for new clusters. for legacy clusters
* that want to limit reshuffling, a value of 3 or 4 will make the
* mappings line up a bit better with previous mappings. */
__u8 chooseleaf_vary_r;
/* if true, it makes chooseleaf firstn to return stable results (if
* no local retry) so that data migrations would be optimal when some
* device fails. */
__u8 chooseleaf_stable;
#ifndef __KERNEL__
/*
* version 0 (original) of straw_calc has various flaws. version 1
* fixes a few of them.
*/
__u8 straw_calc_version;
/*
* allowed bucket algs is a bitmask, here the bit positions
* are CRUSH_BUCKET_*. note that these are *bits* and
* CRUSH_BUCKET_* values are not, so we need to or together (1
* << CRUSH_BUCKET_WHATEVER). The 0th bit is not used to
* minimize confusion (bucket type values start at 1).
*/
__u32 allowed_bucket_algs;
__u32 *choose_tries;
#endif
};2. crush_bucket
结构crush_bucket用于保存bucket相关的信息(src/crush/crush.h):
struct crush_bucket {
__s32 id; // this'll be negative
__u16 type; // non-zero; type=0 is reserved for devices
__u8 alg; // one of CRUSH_BUCKET_*
__u8 hash; // which hash function to use, CRUSH_HASH_*
__u32 weight; // 16-bit fixed point, bucket的权重
__u32 size; // num items,即bucket下的item的数量
//子bucket在crush_bucket结构buckets数组的下标,这里特别要注意的是,其子item的crush_bucket结构体都统一保存在crush map
//结构中的buckets数组中,这里只保存其在数组中的下标
__s32 *items;
/*
* 以下是随机排序选择算法的一些Cache的参数:主要用于uniform bucket,而对于其他bucket类型,在进行fallback线性搜索
* 时也会用到
*/
__u32 perm_x; //要选择的x
__u32 perm_n; //排列的总的元素
__u32 *perm; //排列组合的结果
};3. crush rule
结构crush_rule(src/crush/crush.h):
struct crush_rule_step {
__u32 op; //step操作步的操作码
__s32 arg1; //如果是take,参数就是选择的bucket的id号;如果是select,就是选择的数量
__s32 arg2; //如果是select,是选择的类型
};
struct crush_rule_mask {
__u8 ruleset; //ruleset的编号
__u8 type; //类型(replicated,...)
__u8 min_size; //最小的size
__u8 max_size; //最大的size
};
struct crush_rule {
__u32 len; //steps数组的长度
struct crush_rule_mask mask; //ruleset相关的配置参数
struct crush_rule_step steps[0]; //操作步
};3.2 代码实现
代码builder.c和build.h(src/crush/build.c)文件里主要实现了如何构造crush_map数据结构。crush.c和crush.h文件里定义了crush_map相关的数据结构和destroy方法。文件crushcompiler.h和crushcompiler.cc为crush_map的词法和语法分析相关处理。类CrushWrapper是对CRUSH的所有核心实现进行的封装。CRUSH算法的核心实现在mapper.c文件里。
1. crush_do_rule
函数crush_do_rule里完成了CRUSH算法的选择过程(src/crush/mapper.cc):
int crush_do_rule(const struct crush_map *map, //crush map结构
int ruleno, //ruleset的号
int x, //输入,一般是PG的id
int *result, //输出OSD列表
int result_max, //输出OSD列表的数量
const __u32 *weight, //所有OSD的权重,通过它来判断OSD是否out
int weight_max, //所有OSD的数量
int *scratch) 函数crush_do_rule()根据step的数量,循环调用相关的函数选择bucket。如果是深度优先,就调用函数crush_choose_firstn;如果是广度优先,就调用函数crush_choose_indep来选择。
2. crush_choose_firstn
函数调用crush_bucket_choose选择需要的副本数,并对选择出来的OSD做了相关的冲突检查,如果冲突或者失效或者过载,继续选择新的OSD。
3. bucket算法
函数crush_bucket_choose()根据不同类型的bucket,选择不同的算法来实现从bucket中选出item:
static int crush_bucket_choose(struct crush_bucket *in, int x, int r)
{
dprintk(" crush_bucket_choose %d x=%d r=%d\n", in->id, x, r);
BUG_ON(in->size == 0);
switch (in->alg) {
case CRUSH_BUCKET_UNIFORM:
return bucket_uniform_choose((struct crush_bucket_uniform *)in,
x, r);
case CRUSH_BUCKET_LIST:
return bucket_list_choose((struct crush_bucket_list *)in,
x, r);
case CRUSH_BUCKET_TREE:
return bucket_tree_choose((struct crush_bucket_tree *)in,
x, r);
case CRUSH_BUCKET_STRAW:
return bucket_straw_choose((struct crush_bucket_straw *)in,
x, r);
case CRUSH_BUCKET_STRAW2:
return bucket_straw2_choose((struct crush_bucket_straw2 *)in,
x, r);
default:
dprintk("unknown bucket %d alg %d\n", in->id, in->alg);
return in->items[0];
}
}这里介绍最常用的straw算法:
static int bucket_straw_choose(struct crush_bucket_straw *bucket,
int x, int r);函数bucket_straw_choose用于straw类型的bucket的选择,输入参数x为pgid,r为副本数,其具体实现如下:
1) 对每个item,计算hash值
draw = crush_hash32_3(bucket->h.hash, x, bucket->h.items[i], r);2)获取低16位,并乘以权重相关的修正值
draw &= 0xffff;
draw *= bucket->straws[i];3) 选取draw值最大的item为选中的item
由上可知,这种算法类似抽签,是一种伪随机选择算法。
4. 对CRUSH算法的评价
通过以上分析,可以了解到CRUSH算法实质是一种可分层确定性伪随机选择算法,它是ceph分布式文件系统的一个亮点和创新。
优点如下:
-
输入元数据(cluster map,placement rules)较少,可以应对大规模集群
-
可以应对集群的扩容和缩容
-
采用以概率为基础的统计上的均衡,在大规模集群中可以实现数据均衡。
目前存在的缺点如下:
-
在小规模集群中,会有一定的数据不均衡现象
-
增加新设备时,导致旧设备之间也有数据的迁移
[参看]
