ceph客户端条带化
这里我们在具体介绍ceph的客户端(RadosClient)之前,我们会先介绍一下数据的条带化(stripe)。
1. 什么是条带化
条带(stripe)是把连续的数据分割成大小相同的数据块,把每段数据分别写入到阵列中的不同磁盘上的方法。简单的说,条带是一种将多个磁盘驱动器合并为一个卷的方法。许多情况下,这是通过硬件控制器来完成的。
当多个进程同时访问一个磁盘时,可能会出现磁盘冲突。大多数磁盘系统都对访问次数(每秒的IO操作,IOPS)和数据传输率(每秒传输的数据量,TPS)有限制。当达到这些限制时,后面需要访问磁盘的IO请求就需要等待,这时就是所谓的磁盘冲突。避免磁盘冲突是优化IO性能的一个重要指标,而IO性能的优化与其他资源(如CPU和内存)的优化有着很大的区别,IO优化最有效的手段是将IO最大限度的进行平衡。
条带化技术就是一种自动的将IO的负载均衡到多个物理磁盘上的技术,条带化技术就是将一块连续的数据分成很多小部分并把它们分别存储到不同磁盘上去。这就能使多个进程同时访问数据的多个不同部分而不会造成磁盘冲突,而且在需要对这种数据进行顺序访问的时候可以获得最大程度上的IO并行能力,从而获得非常好的性能。由于条带化在IO性能问题上的优越表现,以至于在应用系统所在的计算环境中的多个层次或平台都涉及到了条带化技术,如操作系统和存储系统这两个层次中都可使用条带化技术。
条带化后,条带卷所能提供的速速比单个盘所能提供的速度要快很多。由于现在存储技术成熟,大多数系统都采用条带化来实现系统的IO负载分担,如果OS有LVM软件或者硬件条带设备,决定因数是条带深度(stripe depth)和条带宽度(stripe width)。
1) 条带深度
条带深度指的是条带的大小,有时也被叫做block size,chunk size,stripe length、stripe unit或者granularity。这个参数指的是写在每块磁盘上的条带数据块的大小。RAID的数据块大小一般在2KB到512KB之间(或者更大),其数值是2的N次方,即2KB、4KB、8KB、16KB…这样。
条带大小对性能的影响比条带宽度难以量化的多:
-
减少条带大小:由于条带大小减少了,则文件被分成了更多、更小的数据块。这些数据块会被分散到更多的磁盘上存储,因此提高了传输的性能,但是由于要多次寻找不同的数据块,磁盘定位的性能就下降了。
-
增加条带大小:与减少条带大小相反,会降低传输性能,提高定位性能。
根据上边的论述,我们会发现根据不同的应用类型,不同的性能需求,不同驱动器的不同特点(如SSD硬盘),不存在一个普遍适用的“最佳条带大小”。所以,这也是存储厂家,文件系统编写者允许我们自己定义条带大小的原因。
2) 条带宽度
是指可以同时并发读或写的条带数量。这个数量等于RAID中的物理硬盘数量。例如,一个经过条带化的,具有4块物理硬盘的阵列的条带宽度就是4。增加条带宽度,可以增加阵列的读写性能。道理很明显,增加更多的硬盘,也就增加了可以同时并发读或写的条带数量。在其他条件一样的前提下,一个由8块18G硬盘组成的阵列相比一个由4块36G硬盘组成的阵列具有更高的传输性能。
OLTP系统中的条带化
On-Line Transaction Processing联机事务处理过程(OLTP),也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。
下面我们先来看看在Oracle数据库系统中影响IO大小的相关参数:
-
db_block_size: oracle数据块的大小,也决定了oracle一次单个IO请求中oracle数据块的大小
-
db_file_multiblock_read_count: 在多数据块读时,一次读取数据块的数量,它和参数db_block_size一起决定了一次多数据块读的大小,它们的乘积不能大于操作系统的最大IO大小
-
操作系统的数据块大小: 这个参数决定了Redo Log和Archive Log操作时的数据块大小,对于大多数Unix系统来说,该值为512KB。在Linux系统中,我们可以通过如下方式来进行查看:
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 80G 0 disk
├─sda1 8:1 0 300M 0 part /boot
├─sda2 8:2 0 4.9G 0 part [SWAP]
└─sda3 8:3 0 74.9G 0 part /
sr0 11:0 1 1024M 0 rom
# fdisk -l /dev/sda3 //方式1
Disk /dev/sda3: 80.3 GB, 80348184576 bytes, 156930048 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
# blockdev --getbsz /dev/sda3 //方式2
512-
最大操作系统IO大小: 决定了一次单个的IO操作的IO大小的上限,对于大多数Unix系统来说,由参数max_io_size设置(注: 在Linux上貌似已经没有该参数了)
-
sort_area_size: 内存中sort area的大小,也决定了并发排序操作时的IO大小
-
hash_area_size: 内存中hash area的大小,也决定了哈希操作的IO大小
在OLTP系统中,会存在大量小的并发的IO请求,这时就需要考虑选择比较大的条带深度。使条带深度大于IO大小就称为粗粒度条带(Coarse Grain Striping)。在高度并行系统中,条带深度为(n * db_block_size),其中n为大于1的整数。
通过粗粒度条带能实现最大的IO吞吐量(一次物理IO可以同时相应多个并发的逻辑IO)。大的条带深度能够使像全表扫描那样的多数据块读操作由一个磁盘驱动器来响应,并提高多数据块读操作的性能。
在低并发度的DSS系统中,由于IO请求比较序列化,为避免出现热点磁盘,我们需要避免逻辑IO只有一块磁盘处理。这时,粗粒度条带就不适合了。我们选择小的条带深度,使一个逻辑IO分布到多个磁盘上,从而实现IO的负载均衡。这就叫细粒度条带。条带深度的大小为(n * db_block_size),其中n为小于多数据块读参数(db_file_multiblock_read_count)大小的整数。
注:决策支持系统(Decision Support System)是一个基于计算机用于支持业务或组织决策活动的信息系统。 DSS服务于组织管理、运营和规划管理层(通常是中级和高级管理层),并帮助人们对可能快速变化并且不容易预测结果的问题做出决策。决策支持系统可以全计算机化、人力驱动或二者结合。
通过上面我们可以简单的理解为并发程度高的IO采用粗粒度条带化,并发度低的IO采用细粒度条带化。
IO过程中,你无法保证Oracle数据块的边界能和条带单元的大小对齐。如果条带深度大小和Oracle数据块大小完全相同,而它们的边界没有对齐的话,那么就会存在大量一个单独的IO请求被两块磁盘来完成。
在OLTP系统中,为了避免一个逻辑IO请求被多个物理IO操作完成,条带深度就需要设置为两倍或两倍以上于Oracle数据块大小。例如,如果条带深度是IO大小的N倍,对于大量并发IO请求,我们可以保证最少有(N-1)/N的请求是由一块磁盘来完成。
2. ceph客户端数据的条带化
当用户使用RBD、RGW、CephFS类型客户端接口来存储数据时,会经历一个透明的、将数据转化为RADOS统一处理对象的过程,这个过程就称之为数据条带化或分片处理。
熟悉存储系统的你不会对条带化感到陌生,它是一种提升存储性能和吞吐能力的手段,通过将有序的数据分割成多个区段并分别存储到多个存储设备上,最常见的条带化就是RAID, 而Ceph的条带化处理就类似于RAID。如果想发挥ceph的并行IO处理能力,就应该充分利用客户端的条带化功能。需要注意的是,librados原生接口并不具有条带化功能,比如: 使用librados接口上传1GB的文件,那么落到存储磁盘上的就是1GB大小的文件。存储集群中的Objects也同样不具备条带化功能,实际上是由上述三种类型的客户端将数据条带化之后再存储到集群Objects之中的。
2.1 条带化处理过程
1) 将数据切分为条带单元块;
2) 将条带单元块写入到Object中,直到Object达到最大容量(默认是4M);
3) 再为额外的条带单元块创建新的Object并继续写入数据;
4) 循环上述步骤,直到数据完全写入
假设Object存储上限为4MB,每一个条带单元块占1MB。此时,我们存储一个8MB大小的文件,那么前4MB就存储在Object0中,后4MB就创建Object1来继续存储。
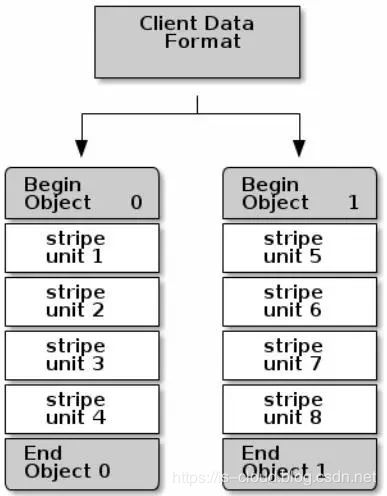
随着存储文件size的增加,可以通过将客户端数据条带化分割存储到多个Objects中,同时由于Object映射到不同的PG上进而会映射到不同的OSD上,这样就能够充分利用每个OSD对应的物理磁盘设备的IO性能,以此实现每个并行的写操作都以最大化的速率进行。随着条带数的增加对写性能的提升也是相当可观的。如下图,数据被分割存储到两个Object Set中,条带单元块存储的顺序为stripe unit 0~31:
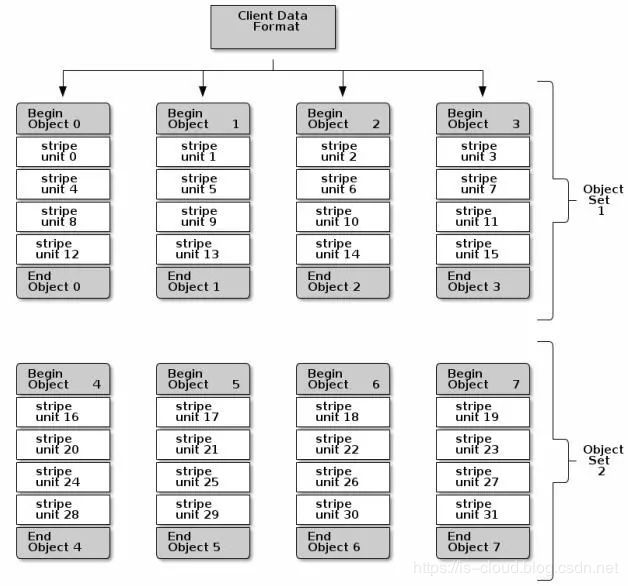
ceph有3个重要参数会对条带化产生影响:
-
order: 表示object size。例如order=22,则2^22即为4MB大小。object的大小应该足够大以便与条带单元块相匹配,而且object的大小应该是条带单元块大小的倍数。RedHat建议的Object大小是16MB。
-
stripe_unit: 表示条带单元块的宽度。客户端写入Object的数据切分为宽度相同的条带单元块(最后一块的宽度可以小于stripe_unit)。条带宽度应该是object大小的一个分数。比如:Object size为4MB,单元块大小为1MB,那么一个Object就能包含4个单元块,以便充分利用object的空间。
-
stripe_count: 条带宽度,也就是一个strip跨多少个对象,也就是一个objectset中对象的个数。
NOTE: 由于客户端会指定单个pool进行写入,所以条带化到objects中的所有数据都会被映射在同一个pool包含的PG内。
假设上图未RBD Image写入的过程,则:
1) RBD image会被保存在总共8个RADOS object中(计算方式: client_data_size除以2^[order])
2) stripe_unit为object size的四分之一,也就是说每个object包含4个stripe
3) stripe_count为4,即每个object set包含4个object。这样,client以4为一个循环,向一个object set中的每个object依次写入stripe,写到第16个stripe后,按照同样的方式写第二个object set。
2.2 地址空间转换
通常,如果我们要读取一个文件的某一段数据,我们只需要(object-name, offset, length)这三个参数就可以了。这个读取过程其实是有一个前提:文件数据存在于一个线性的一维地址空间。如下图所示
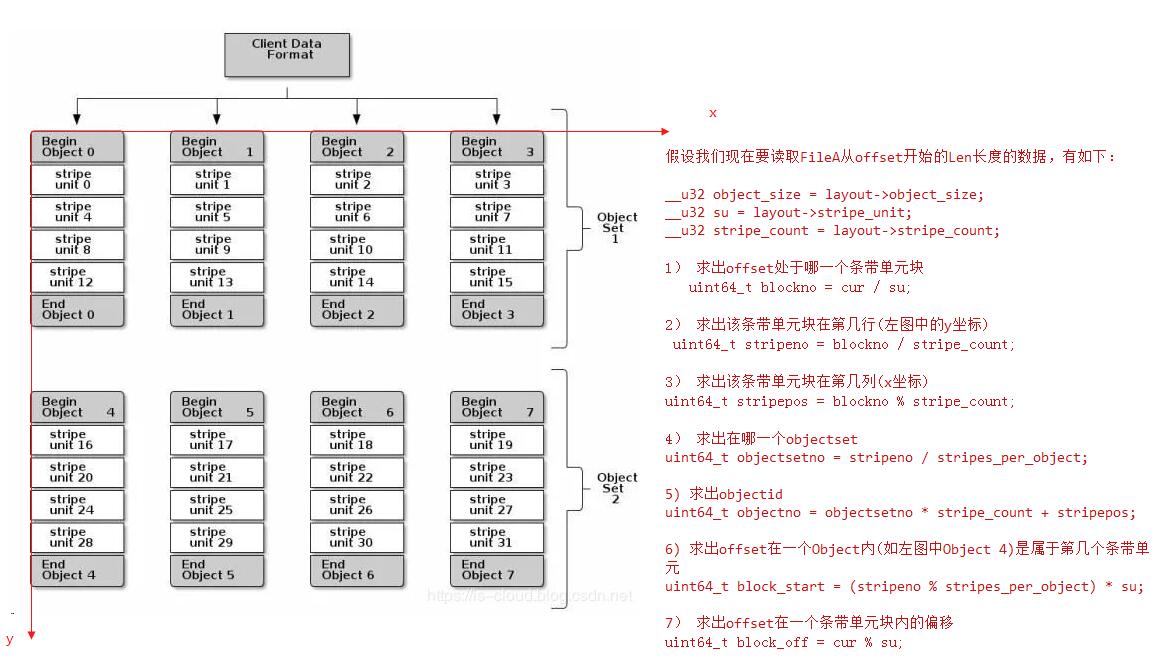
 但现在文件数据经过条带化后,其就变成了一个三维地址空间(objectset, object, stripe)。函数file_to_extents()用于实现此功能:
但现在文件数据经过条带化后,其就变成了一个三维地址空间(objectset, object, stripe)。函数file_to_extents()用于实现此功能:
void Striper::file_to_extents(
CephContext *cct, const char *object_format,
const file_layout_t *layout,
uint64_t offset, uint64_t len,
uint64_t trunc_size,
map<object_t,vector<ObjectExtent> >& object_extents,
uint64_t buffer_offset)
{
ldout(cct, 10) << "file_to_extents " << offset << "~" << len
<< " format " << object_format
<< dendl;
assert(len > 0);
/*
* we want only one extent per object! this means that each extent
* we read may map into different bits of the final read
* buffer.. hence ObjectExtent.buffer_extents
*/
__u32 object_size = layout->object_size;
__u32 su = layout->stripe_unit;
__u32 stripe_count = layout->stripe_count;
assert(object_size >= su);
if (stripe_count == 1) {
ldout(cct, 20) << " sc is one, reset su to os" << dendl;
su = object_size;
}
uint64_t stripes_per_object = object_size / su;
ldout(cct, 20) << " su " << su << " sc " << stripe_count << " os "
<< object_size << " stripes_per_object " << stripes_per_object
<< dendl;
uint64_t cur = offset;
uint64_t left = len;
while (left > 0) {
// layout into objects
uint64_t blockno = cur / su; // which block
// which horizontal stripe (Y)
uint64_t stripeno = blockno / stripe_count;
// which object in the object set (X)
uint64_t stripepos = blockno % stripe_count;
// which object set
uint64_t objectsetno = stripeno / stripes_per_object;
// object id
uint64_t objectno = objectsetno * stripe_count + stripepos;
// find oid, extent
char buf[strlen(object_format) + 32];
snprintf(buf, sizeof(buf), object_format, (long long unsigned)objectno);
object_t oid = buf;
// map range into object
uint64_t block_start = (stripeno % stripes_per_object) * su;
uint64_t block_off = cur % su;
uint64_t max = su - block_off;
uint64_t x_offset = block_start + block_off;
uint64_t x_len;
if (left > max)
x_len = max;
else
x_len = left;
ldout(cct, 20) << " off " << cur << " blockno " << blockno << " stripeno "
<< stripeno << " stripepos " << stripepos << " objectsetno "
<< objectsetno << " objectno " << objectno
<< " block_start " << block_start << " block_off "
<< block_off << " " << x_offset << "~" << x_len
<< dendl;
ObjectExtent *ex = 0;
vector<ObjectExtent>& exv = object_extents[oid];
if (exv.empty() || exv.back().offset + exv.back().length != x_offset) {
exv.resize(exv.size() + 1);
ex = &exv.back();
ex->oid = oid;
ex->objectno = objectno;
ex->oloc = OSDMap::file_to_object_locator(*layout);
ex->offset = x_offset;
ex->length = x_len;
ex->truncate_size = object_truncate_size(cct, layout, objectno,
trunc_size);
ldout(cct, 20) << " added new " << *ex << dendl;
} else {
// add to extent
ex = &exv.back();
ldout(cct, 20) << " adding in to " << *ex << dendl;
ex->length += x_len;
}
ex->buffer_extents.push_back(make_pair(cur - offset + buffer_offset,
x_len));
ldout(cct, 15) << "file_to_extents " << *ex << " in " << ex->oloc
<< dendl;
// ldout(cct, 0) << "map: ino " << ino << " oid " << ex.oid << " osd "
// << ex.osd << " offset " << ex.offset << " len " << ex.len
// << " ... left " << left << dendl;
left -= x_len;
cur += x_len;
}
}这个过程其实还算比较简单,如下图所示:
[参看]
