ceph快照和克隆
本章介绍Ceph的高级数据功能:快照和克隆,它们在企业级存储系统中是必不可少的。这里首先介绍Ceph中快照和克隆的基本概念,其次介绍快照实现相关的数据结构,然后介绍快照操作的原理,最后分析快照的读写操作的源代码实现。
1. 基本概念
下面介绍快照和克隆的基本概念,以及二者之间的区别。
1.1 快照和克隆
快照是一个RBD在某一时刻全部数据的只读镜像。克隆是在某一时刻全部数据的可写镜像。快照和克隆都是某一时间点的镜像,区别在于快照只能读,而克隆可以写。
Ceph支持两种类型的快照:一种是pool级别的快照(pool snap),是给pool整体做一个快照;另一种是用户管理的快照(self managed snap)。目前RBD快照的实现属于后者。用户的写操作必须自己提供SnapContext信息。注意,这两种快照时互斥的,两种快照不能同时存在。也就是说,如果多pool整体做了快照操作,就不能对该pool中的RBD做快照操作。
无论是pool级别的快照,还是RBD的快照,其实现的基本原理都是相同的。都是基于对象的COW(copy-on-write)机制。Ceph可以完成秒级的快照操作和克隆操作。
这里需要特别指出的是,对象的clone操作指的是快照对应的克隆操作,是RADOS在OSD服务端实现的对象拷贝。RBD的clone操作是RBD的客户端实现的RBD层面的克隆。它们俩不是一个概念,希望读者区分开来。
在具体的实现过程中,克隆依赖快照的实现,克隆是在一个快照的基础上实现了可写功能。
下图9-1是快照和克隆的示意图,其生成过程如下所示:
1) 首先创建一个RBD块设备: rbd1
2) 对该块设备rbd1创建一个快照snap1
3) 调用rbd protect来保护该快照,则该快照就不能被删除;
4) 从该快照中克隆出一个新的image,其名字为clone1
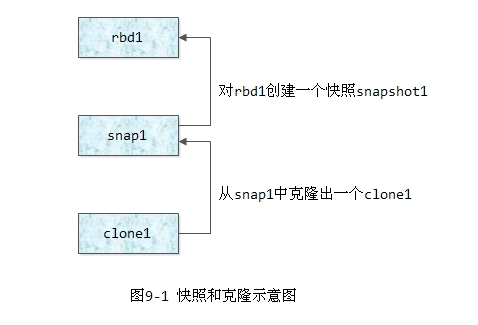
一个image的数据对象和快照对象都在同一个pool中,每个image的对象和对应的快照对象都在相同OSD上的相同PG中。快照的对象拷贝都是在OSD本地进行。
1.2 RBD的快照和克隆比较
RBD的快照和克隆在实现层面完全不同。快照时RADOS支持的,基于OSD服务端的COW机制实现的。而RBD的克隆操作完全是RBD客户端实现的一种COW机制,对于OSD的Server端是无感知的。
怎么理解RBD的克隆操作是由RBD的客户端实现的?如上图9-1所示的快照和克隆,对克隆的image的读写过程如下:
1) 当对克隆image,也就是clone1发起写操作时,客户端对应的OSD发送正常的写请求;
2) OSD返回给客户端应答,表明该OSD上对应的对象不存在;
3) 客户端要发读请求到给克隆image的父image,读取对应snap 1上的数据返回给客户端;
4) 客户端把该快照数据写入克隆image中;
5) 客户端给克隆image发送写操作,写入实际要写入的数据。
由以上过程可知,克隆的拷贝操作是由客户端控制完成,OSD的Server端配合完成普通的读写操作。
当克隆的层级比较多时,需要客户端不断递归到其父image上去读取对应的快照对象,则会严重影响克隆的性能。
如图9-2所示,当读写clone2时,客户端首先给clone2发送写请求,如果对象不存在,就需要向clone1发送读请求,读取clone1对应的snap2的快照数据,并写入clone2,然后完成实际的写入操作。
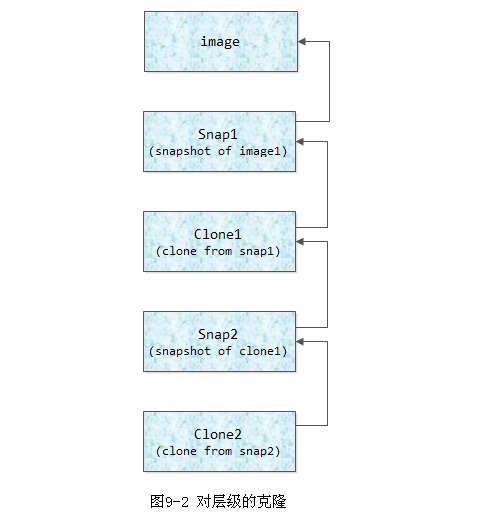
如果clone1上的对象不存在,同样,客户端继续递归,不断给其父image发送读请求,读取snap1的快照数据,并写入clone1中。
如果层级过多就会影响克隆操作的性能。因此系统提供了RBD的flattern操作,可直接把父image的快照对象拷贝给克隆image,这样以后就不需要去向父image查找对象数据了,从而提高了性能。
2. 快照实现的核心数据结构
快照的核心数据结构如下:
-
head对象:也就是对象的原始对象,该对象可以进行写操作;
-
snap对象:对某个对象做快照后,通过cow机制copy出来的快照对象只能读,不能写;
-
snap_seq或者seq: 快照序号,每次做snapshot操作系统都分配一个相应快照序号,该快照序号在后面的写操作中发挥重要作用;
-
snapdir对象: 当head对象被删除后,仍然有snap和clone对象,系统自动创建一个snapdir对象,来保存SnapSet信息。head对象和snapdir对象只有一个存在,其属性都可以保存快照相关的信息。这主要用于文件系统的快照实现。
2.1 SnapContext
在文件src/common/snap_types.h中定义了snap相关的数据结构:
struct SnapContext {
snapid_t seq; // 最新的快照序号
vector<snapid_t> snaps; // 当前存在的快照序号,降序排列
};其中:
-
seq为最新的快照序号;
-
snaps降序保存了该RBD的所有的快照序号
SnapContext数据结构用来在客户端(RBD端)保存snap相关的信息。这个结构持久化存储在RBD的元数据中:
struct librados::IoCtxImpl {
...
snapid_t snap_seq;
::SnapContext snapc;
...
};数据结构IoCtxImpl里的snap_seq一般也称为快照的id(snap id)。当打开一个image时,如果打开的是一个卷的快照,那么snap_seq的值就是该snap对应的快照序号。否则,snap_seq就为CEPH_NOSNAP(-2),来表示操作的不是卷的快照,而是卷本身。
2.2 SnapSet
数据结构SnapSet用于保存Server端(也就是OSD端)与快照相关的信息(src/osd/osd_types.h):
struct SnapSet {
snapid_t seq; //最新的快照序号
bool head_exists; //head对象是否存在
vector<snapid_t> snaps; //所有的快照序号列表(降序排列)
vector<snapid_t> clones; //所有的clone对象序号列表(升序排列)
//和上次clone对象之间overlap的部分
map<snapid_t, interval_set<uint64_t> > clone_overlap;
map<snapid_t, uint64_t> clone_size; //clone对象的size
};下面是其中一些数据字段介绍:
-
seq保存最新的快照序号;
-
head_exists保存head对象是否存在;
-
snaps保存所有的快照序号;
-
clones保存所有快照后的写操作需要clone的对象记录;
这里特别强调的是clones和snaps的区别。由于不是每次做快照操作后,都需要拷贝对象。只当快照操作后又写操作,才会触发相关对象的clone操作复制出一份新的对象,该对象是clone出来的,其快照序号记录在clones队列中,称为clone对象。
-
clone_overlap保存本次clone对象和上次clone对象(或则head对象)的overlap的部分,也就是重叠的部分。clone操作后,每次写操作,都要维护这个信息。这个信息用于在数据恢复阶段对象恢复的优化。
-
clone_size保存每次clone后的对象的size
SnapSet数据结构持久化保存在head对象的xattr的扩展属性中:
-
在Head对象的xattr中保存key为snapset,value为SnapSet结构序列化后的值。
-
在snap对象的xattr中保存key为user.cephos.seq的snap_seq值
3. 快照的工作原理
3.1 快照的创建
RBD快照创建的基本步骤如下:
1) 向Monitor发送请求,获取一个最新的快照序号snap_seq的值;
2) 把该次快照的snap_name和snap_seq的值保存到RBD的元数据中;
在RBD的元数据里保存了所有快照的名字和对应的snap_seq号,并不会触发OSD端的数据操作,所以非常快。
3.2 快照的写操作
当对一个image做了一次快照后,该image写入数据时,由于快照的存在需要启动copy-on-write(cow)机制。下面介绍cow机制的具体实现。
客户端的每次写操作,消息中都必须带数据结构SnapContext信息,它包含了客户端认为的最新快照序号seq,以及该对象的所有快照序号snaps的列表。在OSD端,对象的Snap相关信息保存在SnapSet数据结构中,当有写操作发生时,处理过程按照如下规则进行。
规则1
如果写操作所带的SnapContext的seq值小于SnapSet的seq值,也就是客户端最新的快照序号小于OSD端保存的最新的快照序号,那么直接返回-EOLDSNAP错误。
Ceph客户端始终保持最新的快照序号。如果客户端不是最新的快照序号,可能的情况是:在多个客户端的情形下,其他客户端有可能创建了快照,本客户端有可能没有获取到最新的快照序号。
Ceph有一套Watcher回调通知机制来实现快照序号的更新。如果其他客户端对一个卷做了快照,就会产生一个最新的快照序号。OSD端接收到最新快照序号变化后,通知相应的连接客户端更新最新的快照序号。如果有客户端没有及时更新,也没有太大的问题,OSD端会返回客户端-EOLDSNAP,客户端会主动更新为最新的快照序号,重新发起写操作。
规则2
如果head对象不存在,创建该对象并写入数据,用SnapContext相应的信息更新SnapSet的信息。
规则3
如果写操作所带的SnapContext的seq值等于SnapSet的seq值,做正常的读写
规则4
如果写操作所带的SnapContext的seq值大于SnapSet的seq值:
1) 对当前head对象做copy操作,clone出一个新的快照对象,该快照对象的snap序号为最新的序号,并把clone操作记录在clones列表里,也就是把最新的快照序号加入到clones队列中。
2) 用SnapContext的seq和snaps值更新SnapSet的seq和snaps值;
3) 写入最新的数据到head对象中
3.3 快照的读写操作
快照读取数据时,输入参数为RBD的名字和快照的名字。RBD的客户端通过访问RBD的元数据,来获取快照对应的snap_id,也就是快照对应的snap_seq值。
在OSD端,获取head对象保存的SnapSet数据结构。然后根据SnapSet中的snaps和clones值来计算快照所对应的正确的快照对象。
3.4 快照的回滚
快照的回滚,就是把当前的head对象回滚到某个快照对象。具体操作如下:
1) 删除当前head对象的数据;
2) 拷贝相应的snap对象到head对象;
其源代码的实现在ReplicatedPG::_rollback_to()里。
3.5 快照的删除
删除快照时,直接删除rbd的元数据中保存的Snap相关快照信息,然后给Monitor发快照删除信息。Monitor随后给相应的OSD发送删除的快照序号,然后由OSD控制删除本地相应的快照对象。该快照是否被其他奎照对象共享。
由上可知,Ceph的快照删除是延迟删除,并不是直接立即删除。
4. 快照读写操作源代码分析
在结构体OpContext的上下文中,保存了快照相关的信息(src/osd/ReplicatedPG.h):
struct OpContext {
OpRequestRef op;
osd_reqid_t reqid;
vector<OSDOp> &ops;
const ObjectState *obs; // Old objectstate
const SnapSet *snapset; //旧的Snapset,也就是OSD服务端保存的快照信息
ObjectState new_obs; //resulting ObjectState
SnapSet new_snapset; //新的SnapSet
SnapContext snapc; //写操作带的,也就是客户端的SnapContext信息
....
};在读写的关键流程中,有关快照的处理如下:
1) 在OSD写操作的流程中,在函数ReplicatedPG::execute_ctx()中,把消息带的SnapContext信息保存在了OpContext的snapc中:
void ReplicatedPG::execute_ctx(OpContext *ctx)
{
...
ctx->snapc.seq = m->get_snap_seq();
ctx->snapc.snaps = m->get_snaps();
...
}2) 在OpContext的构造函数里,用结构snapset字段初始化了结构new_snapset的相关字段。当前new_snapset保存的就是OSD服务端的快照信息:
if (obc->ssc) {
new_snapset = obc->ssc->snapset;
snapset = &obc->ssc->snapset;
}3) 在函数ReplicatedPG::prepare_transaction()里调用了函数ReplicatedPG::make_writeable()来完成快照相关的操作。
4.2 make_writeable()函数
函数make_writeable()处理快照相关的写操作,其处理流程如下:
void ReplicatedPG::make_writeable(OpContext *ctx);1) 首先判断,如果服务端的最新快照序号大于客户端的快照序号,就用服务端的快照信息更新客户端的快照信息:
// use newer snapc?
if (ctx->new_snapset.seq > snapc.seq) {
snapc.seq = ctx->new_snapset.seq;
snapc.snaps = ctx->new_snapset.snaps;
dout(10) << " using newer snapc " << snapc << dendl;
}在数据读写的流程中可知,在函数ReplicatedPG::execute_ctx()里已经判断了:客户端的最新快照序号不能小于服务端的快照序号,否则就直接返回-EOLDSNAP错误码给客户端更新快照序号后重试。所以笔者认为这段代码不会进入,所以是无用的代码。
2) 调用函数filter_snapc()把已经删除的快照过滤掉;
3) 如果head对象存在,并且snaps的size不为空(有快照),并且客户端的最新快照序号大于服务端的最新快照序号,在这种情况下要克隆对象,实现对象数据的拷贝:
-
构造clone对象coid,其coid.snap为最新的客户端seq值;
-
计算snaps列表,也就是本次克隆对象对应的所有快照;
-
构造clone_obc,也就是克隆对象coid的ObjectContext。特别需要指出的是该克隆对象的object_info_t中的snaps信息,就是在上一步中计算出的snaps列表
-
调用函数_make_clone()实现对象的克隆操作。此时克隆操作都先封装在新创建的事务t中:
// prepend transaction to op_t
PGBackend::PGTransaction *t = pgbackend->get_transaction();
_make_clone(ctx, t, ctx->clone_obc, soid, coid, snap_oi);
t->append(ctx->op_t.get());
ctx->op_t.reset(t);注意,之前的写操作封装在事务ctx->op_t中,把该事务追加到事务t的尾部,然后删除ctx->op_t事务,事务t赋值给ctx->op_t。这样在事务应用时,就是先做克隆操作,然后才完成写操作。
4) 最后把该克隆对象添加到ctx->new_snapset.clones中,并添加clone_size记录和clone_overlap记录;
5) 根据当前的写操作修改范围modified_ranges,来计算修改clone_overlap的记录,也就是当前head对象和上一次克隆对象的重叠区域,该信息用来优化快照对象的恢复;
6) 更新服务端的快照信息为客户端的快照记录信息。
下面举例说明:
例9-1 快照写操作见下表9-1
说明如下:
1) 在操作1里为第一次写操作,写入的数据位data1,SnapContext的初始seq为0,snaps列表为空。按规则2,OSD端创建对象并写入对象数据,用SnapContext的数据更新SnapSet中的数据;
2) 在操作2里,创建了该RBD一个快照,名字为snap1,并向Monitor申请分配一个快照序号,其值为1.在该卷的元数据里添加了快照的名字和对应的快照序号。
3) 操作3里,写入数据data2,写操作所带SnapContext中seq值为1,snap列表为{1}。在OSD端处理,此时SnapContext的seq大于SnapSet的seq,操作按照规则4:
a) 更新SnapSet中的seq为1,snaps列表更新为{1}值;
b) 创建快照对象obj1_1,拷贝当前head对象的数据data1到快照对象obj1_1中(快照对象名字下划线后面为快照序号,Ceph目前快照对象的名字中含有快照序号)。此时快照对象obj1_1的数据为data1,并在clones中添加clone操作记录,clone列表的值为{1};
c) 向head对象obj1_head中写入数据data2
4) 操作4和操作5连续做了两次快照操作,快照的名字分别为snap3和snap6,分配的快照序号分别为3,6(在Ceph里,快照序号是由Monitor分配的,全局唯一,所以单个RBD的快照序号不一定连续)。
5) 操作6写入数据data3,此时写操作所带SnapContext中的seq值为6,snaps值为{6,3,1}共三个快照。此时SnapSet的seq为1,操作按规则4处理过程如下:
a) 更新SnapSet结构中的seq值为6,snaps值为{6,3,1};
b) 创建快照对象obj1_6,拷贝当前head对象的数据data2到快照对象obj1_6中,并把本次克隆操作记录添加到clone队列中。更新后的clone队列的值为{1,6};
c) 向head对象obj1_head中写入数据data3。
4.3 快照的读操作
快照的读取操作核心在函数ReplicatedPG::find_object_context()里实现,其原理是根据读对象的快照序号,查找实际对应的克隆对象的ObjectContext。基本步骤如下:
1) 如果对象的快照序号oid.snap大于服务端的最新快照序号ssc->snapset.seq,获取head对象就该快照对应的实际数据对象。
2) 计算oid.snap首次大于ssc->snapset.clones列表中的克隆对象,就是oid对应的克隆对象。
例如在例9-1中,最后的Snapset为:
SnapSet={
seq=6,
snaps={6,3,1},
clones={1,6},
...
};
这时候读取seq为3的快照,由于seq为3的快照并没有写入数据,也就没有对应的克隆对象,通过计算可知,seq为3的快照和snap为1的快照对象数据是一样的,所以就读取obj1_1对象数据。
5. 总结
Ceph的基于Copy-On-Write的机制实现了秒级的快照,其效率的核心原理在于做快照操作时不会直接拷贝数据,而是只做了快照的记录,当只有实际的写操作发生时,才会实现对象的拷贝操作。实质就是把整个卷的拷贝操作开销分散到后续每次写操作过程中,这样就实现了快照操作知识增加了新的快照记录,所以快照操作可以在秒级实现。
[参看]
