ceph peering机制再研究(4)
本章我们会先讲述一下PriorSet以及pg_info_t数据结构,然后开始正式的讲解Ceph的Peering流程。
1. PriorSet
PriorSet是运行于PG Primary上,用于构建一个Recovery状态。下面我们来看看其数据结构:
struct PriorSet {
const bool ec_pool;
set<pg_shard_t> probe; /// current+prior OSDs we need to probe.
set<int> down; /// down osds that would normally be in @a probe and might be interesting.
map<int, epoch_t> blocked_by; /// current lost_at values for any OSDs in cur set for which (re)marking them lost would affect cur set
bool pg_down; /// some down osds are included in @a cur; the DOWN pg state bit should be set.
boost::scoped_ptr<IsPGRecoverablePredicate> pcontdec;
};各字段含义如下:
-
ec_pool: 当前PG所在的pool是否是ec_pool
-
probe: current_interval以及past_intervals中我们需要probe的OSD,也就是需要去获取pg_info的OSD列表
-
down: 保存了probe中down掉的osd,以及其他感兴趣的处于down状态的osd
-
blocked_by: 用于记录当前osd的lost_at值。如果lost_at值发生改变,会影响当前所构建出来的PriorSet
-
pg_down: 如果当前存在一些down OSDs导致我们不能进行数据恢复,会将此标志设置为true
-
pcontdec: 断言PG是否可以进行恢复。函数IsPGRecoverablePredicate实际上是一个类的运算符重载。对于不同类型的PG有不同的实现。对于ReplicatedPG对应的实现类为RPCRecPred,其至少保证有一个处于Up状态的OSD;对应ErasureCode(n+m)类型的PG,至少有n各处于up状态的OSD。
1.1 PriorSet构造函数
/*---------------------------------------------------*/
#undef dout_prefix
#define dout_prefix (*_dout << (debug_pg ? debug_pg->gen_prefix() : string()) << " PriorSet: ")
PG::PriorSet::PriorSet(bool ec_pool,
IsPGRecoverablePredicate *c,
const OSDMap &osdmap,
const map<epoch_t, pg_interval_t> &past_intervals,
const vector<int> &up,
const vector<int> &acting,
const pg_info_t &info,
const PG *debug_pg)
: ec_pool(ec_pool), pg_down(false), pcontdec(c)
{
/*
* We have to be careful to gracefully deal with situations like
* so. Say we have a power outage or something that takes out both
* OSDs, but the monitor doesn't mark them down in the same epoch.
* The history may look like
*
* 1: A B
* 2: B
* 3: let's say B dies for good, too (say, from the power spike)
* 4: A
*
* which makes it look like B may have applied updates to the PG
* that we need in order to proceed. This sucks...
*
* To minimize the risk of this happening, we CANNOT go active if
* _any_ OSDs in the prior set are down until we send an MOSDAlive
* to the monitor such that the OSDMap sets osd_up_thru to an epoch.
* Then, we have something like
*
* 1: A B
* 2: B up_thru[B]=0
* 3:
* 4: A
*
* -> we can ignore B, bc it couldn't have gone active (alive_thru
* still 0).
*
* or,
*
* 1: A B
* 2: B up_thru[B]=0
* 3: B up_thru[B]=2
* 4:
* 5: A
*
* -> we must wait for B, bc it was alive through 2, and could have
* written to the pg.
*
* If B is really dead, then an administrator will need to manually
* intervene by marking the OSD as "lost."
*/
// Include current acting and up nodes... not because they may
// contain old data (this interval hasn't gone active, obviously),
// but because we want their pg_info to inform choose_acting(), and
// so that we know what they do/do not have explicitly before
// sending them any new info/logs/whatever.
for (unsigned i=0; i<acting.size(); i++) {
if (acting[i] != CRUSH_ITEM_NONE)
probe.insert(pg_shard_t(acting[i], ec_pool ? shard_id_t(i) : shard_id_t::NO_SHARD));
}
// It may be possible to exlude the up nodes, but let's keep them in
// there for now.
for (unsigned i=0; i<up.size(); i++) {
if (up[i] != CRUSH_ITEM_NONE)
probe.insert(pg_shard_t(up[i], ec_pool ? shard_id_t(i) : shard_id_t::NO_SHARD));
}
for (map<epoch_t,pg_interval_t>::const_reverse_iterator p = past_intervals.rbegin();p != past_intervals.rend();++p) {
const pg_interval_t &interval = p->second;
dout(10) << "build_prior " << interval << dendl;
if (interval.last < info.history.last_epoch_started)
break; // we don't care
if (interval.acting.empty())
continue;
if (!interval.maybe_went_rw)
continue;
// look at candidate osds during this interval. each falls into
// one of three categories: up, down (but potentially
// interesting), or lost (down, but we won't wait for it).
set<pg_shard_t> up_now;
bool any_down_now = false; // any candidates down now (that might have useful data)
// consider ACTING osds
for (unsigned i=0; i<interval.acting.size(); i++) {
int o = interval.acting[i];
if (o == CRUSH_ITEM_NONE)
continue;
pg_shard_t so(o, ec_pool ? shard_id_t(i) : shard_id_t::NO_SHARD);
const osd_info_t *pinfo = 0;
if (osdmap.exists(o))
pinfo = &osdmap.get_info(o);
if (osdmap.is_up(o)) {
// include past acting osds if they are up.
probe.insert(so);
up_now.insert(so);
} else if (!pinfo) {
dout(10) << "build_prior prior osd." << o << " no longer exists" << dendl;
down.insert(o);
} else if (pinfo->lost_at > interval.first) {
dout(10) << "build_prior prior osd." << o << " is down, but lost_at " << pinfo->lost_at << dendl;
up_now.insert(so);
down.insert(o);
} else {
dout(10) << "build_prior prior osd." << o << " is down" << dendl;
down.insert(o);
any_down_now = true;
}
}
// if not enough osds survived this interval, and we may have gone rw,
// then we need to wait for one of those osds to recover to
// ensure that we haven't lost any information.
if (!(*pcontdec)(up_now) && any_down_now) {
// fixme: how do we identify a "clean" shutdown anyway?
dout(10) << "build_prior possibly went active+rw, insufficient up;"<< " including down osds" << dendl;
for (vector<int>::const_iterator i = interval.acting.begin();i != interval.acting.end();++i) {
if (osdmap.exists(*i) && // if it doesn't exist, we already consider it lost.
osdmap.is_down(*i)) {
pg_down = true;
// make note of when any down osd in the cur set was lost, so that
// we can notice changes in prior_set_affected.
blocked_by[*i] = osdmap.get_info(*i).lost_at;
}
}
}
}
dout(10) << "build_prior final: probe " << probe<< " down " << down<< " blocked_by " << blocked_by<< (pg_down ? " pg_down":"")<< dendl;
}下面我们看具体的实现步骤:
1)把当前PG的acting set和up set中的OSD加入到probe列表中(这里时current_interval)
2) 遍历past_intervals阶段:
a) 如果interval.last小于info.history.last_epoch_started,这种情况下past_interval就没有意义,直接跳过;
b) 如果该interval的acting set为空,就跳过;
c) 如果该interval没有读写操作,就跳过
d) 对于当前interval的每一个处于acting状态的OSD进行检查:
* 如果该OSD当前处于up状态,就加入到up_now列表中。并同时加入到probe列表中,用于获取权威日志以及后续数据恢复;
* 如果该OSD当前已不在OSDMap中,那么就将其加入到down列表中;
* 如果该OSD当前不是up状态,但是在该past_interval期间还处于up状态,且该OSD的lost_at值大于该interval.first,说明是后期人工将其置为lost状态的,就将该OSD加入到up_now列表,并将其加入到down列表。(注:因为该OSD当前实际并不是处于up状态,这里加入up_now列表仅仅是为了可以通过pcontdec的检测,从而有机会跳过该OSD,使peering不会因为该OSD被阻塞,但是这存在丢失数据的风险)
* 否则,加入到down列表,并且将any_down_now置为true;
e) 如果当前interval确实有宕掉的OSD,就调用函数pcontdec,也就是IsPGRecoverablePredicate函数。该函数判断该PG在该interval期间的数据是否可以恢复,如果无法恢复,就直接设置pg_down为true值。同时会将对应down掉的OSD加入到block_by中,表明是由于哪些OSD阻塞了当前的恢复。(注:这里将prior_set的pg_down设置为true之后,并不是马上就结束Peering动作,而仍然会向probe中的OSD发起get_info动作,但是在进入GetLog阶段前会判断本标志,就会阻塞Peering的进一步推进)
1.2 build_prior()函数
build_prior()函数是用来构建PriorSet:
void PG::build_prior(std::unique_ptr<PriorSet> &prior_set)
{
if (1) {
// sanity check
for (map<pg_shard_t,pg_info_t>::iterator it = peer_info.begin();it != peer_info.end();++it) {
assert(info.history.last_epoch_started >= it->second.history.last_epoch_started);
}
}
prior_set.reset(
new PriorSet(
pool.info.ec_pool(),
get_pgbackend()->get_is_recoverable_predicate(),
*get_osdmap(),
past_intervals,
up,
acting,
info,
this));
PriorSet &prior(*prior_set.get());
if (prior.pg_down) {
state_set(PG_STATE_DOWN);
}
if (get_osdmap()->get_up_thru(osd->whoami) < info.history.same_interval_since) {
dout(10) << "up_thru " << get_osdmap()->get_up_thru(osd->whoami)<< " < same_since " << info.history.same_interval_since<< ", must notify monitor" << dendl;
need_up_thru = true;
} else {
dout(10) << "up_thru " << get_osdmap()->get_up_thru(osd->whoami)<< " >= same_since " << info.history.same_interval_since<< ", all is well" << dendl;
need_up_thru = false;
}
set_probe_targets(prior_set->probe);
}
void PG::set_probe_targets(const set<pg_shard_t> &probe_set)
{
Mutex::Locker l(heartbeat_peer_lock);
probe_targets.clear();
for (set<pg_shard_t>::iterator i = probe_set.begin();i != probe_set.end();++i) {
probe_targets.insert(i->osd);
}
}这里代码比较简单,就是构建PriorSet,然后检查当前OSD的up_thru是否小于info.history.same_interval_since,如果是则设置need_up_thru标志为true。
1.3 判断一个新的OSDMap是否会影响PriorSet
// true if the given map affects the prior set
bool PG::PriorSet::affected_by_map(const OSDMapRef osdmap, const PG *debug_pg) const
{
for (set<pg_shard_t>::iterator p = probe.begin();p != probe.end();++p) {
int o = p->osd;
// did someone in the prior set go down?
if (osdmap->is_down(o) && down.count(o) == 0) {
dout(10) << "affected_by_map osd." << o << " now down" << dendl;
return true;
}
// did a down osd in cur get (re)marked as lost?
map<int, epoch_t>::const_iterator r = blocked_by.find(o);
if (r != blocked_by.end()) {
if (!osdmap->exists(o)) {
dout(10) << "affected_by_map osd." << o << " no longer exists" << dendl;
return true;
}
if (osdmap->get_info(o).lost_at != r->second) {
dout(10) << "affected_by_map osd." << o << " (re)marked as lost" << dendl;
return true;
}
}
}
// did someone in the prior down set go up?
for (set<int>::const_iterator p = down.begin();p != down.end();++p) {
int o = *p;
if (osdmap->is_up(o)) {
dout(10) << "affected_by_map osd." << *p << " now up" << dendl;
return true;
}
// did someone in the prior set get lost or destroyed?
if (!osdmap->exists(o)) {
dout(10) << "affected_by_map osd." << o << " no longer exists" << dendl;
return true;
}
// did a down osd in down get (re)marked as lost?
map<int, epoch_t>::const_iterator r = blocked_by.find(o);
if (r != blocked_by.end()) {
if (osdmap->get_info(o).lost_at != r->second) {
dout(10) << "affected_by_map osd." << o << " (re)marked as lost" << dendl;
return true;
}
}
}
return false;
}affected_by_map()函数用于判断一个新的OSDMap是否会影响当前的PriorSet,如果不会影响则在Peering阶段收到AdvMap事件时,就不必再重新回到Reset阶段开启一个新的Peering动作。
下面我们来看其实现:
1) 遍历prior.probe列表:
-
如果probe列表中的OSD当前进入down状态,肯定会改变PriorSet,返回true
-
如果处于down状态的OSD被移出osdmap,或者被重新标记为lost,那么也会影响PriorSet,返回true(注: 似乎不会有此种情况发生)
2) 遍历prior.down列表
-
如果down列表中的OSD重新up,肯定会改变PriorSet,返回true
-
如果down列表中的OSD被移出osdmap,也会影响PriorSet,返回true
-
如果被block_by的osd被重新设置lost_at,那么也会影响PriorSet,返回true(因为重新构建PriorSet时,可能可以绕过该OSD)
2. pg_info_t数据结构
数据结构pg_info_t保存了PG在OSD上的一些描述信息。该数据结构在Peering的整个过程,以及后续的数据修复中都发挥了重要的作用,理解该数据结构的各个关节字段的含义可以更好地理解相关的过程。pg_info_t数据结构如下:
/**
* pg_info_t - summary of PG statistics.
*
* some notes:
* - last_complete implies we have all objects that existed as of that
* stamp, OR a newer object, OR have already applied a later delete.
* - if last_complete >= log.bottom, then we know pg contents thru log.head.
* otherwise, we have no idea what the pg is supposed to contain.
*/
struct pg_info_t {
spg_t pgid;
eversion_t last_update; ///< last object version applied to store.
eversion_t last_complete; ///< last version pg was complete through.
epoch_t last_epoch_started; ///< last epoch at which this pg started on this osd
version_t last_user_version; ///< last user object version applied to store
eversion_t log_tail; ///< oldest log entry.
hobject_t last_backfill; ///< objects >= this and < last_complete may be missing
bool last_backfill_bitwise; ///< true if last_backfill reflects a bitwise (vs nibblewise) sort
interval_set<snapid_t> purged_snaps;
pg_stat_t stats;
pg_history_t history;
pg_hit_set_history_t hit_set;
};结构pg_history_t保存了PG的一些历史信息:
/**
* pg_history_t - information about recent pg peering/mapping history
*
* This is aggressively shared between OSDs to bound the amount of past
* history they need to worry about.
*/
struct pg_history_t {
epoch_t epoch_created; // epoch in which PG was created
epoch_t last_epoch_started; // lower bound on last epoch started (anywhere, not necessarily locally)
epoch_t last_epoch_clean; // lower bound on last epoch the PG was completely clean.
epoch_t last_epoch_split; // as parent
epoch_t last_epoch_marked_full; // pool or cluster
/**
* In the event of a map discontinuity, same_*_since may reflect the first
* map the osd has seen in the new map sequence rather than the actual start
* of the interval. This is ok since a discontinuity at epoch e means there
* must have been a clean interval between e and now and that we cannot be
* in the active set during the interval containing e.
*/
epoch_t same_up_since; // same acting set since
epoch_t same_interval_since; // same acting AND up set since
epoch_t same_primary_since; // same primary at least back through this epoch.
eversion_t last_scrub;
eversion_t last_deep_scrub;
utime_t last_scrub_stamp;
utime_t last_deep_scrub_stamp;
utime_t last_clean_scrub_stamp;
};2.1 last_epoch_started介绍
last_epoch_started字段有两个地方出现,一个是pg_info_t结构里的last_epoch_started,代表最后一次Peering成功后的epoch值,是本地PG完成Peering后就设置的。另一个是pg_history_t结构里的last_epoch_started,是PG里所有的OSD都完成Peering后设置的epoch值。
2.2 last_complete和last_backfill的区别
在这里特别指出last_update和last_complete、last_backfill之间的区别。下面通过一个例子来讲解,同时也可以大概了解PG数据恢复的流程。在数据恢复过程中先进行Recovery过程,再进行Backfill过程(我们会在后面的章节进行讲解)。
情况1: 在PG处于clean状态时,last_complete就等于last_update的值,并等于PG日志中的head版本。它们都是同步更新,此时没有区别。last_backfill设置为MAX值。例如: 下面的PG日志里有三条日志记录。此时last_update和last_complete以及pg_log.head都指向版本(1,2)。由于没有缺失的对象,不需要恢复,last_backfill设置为MAX值。示例如下所示:

情况2: 当该osd1发生异常之后,过一段时间又重新恢复,当完成了Peering状态后的情况。此时该PG可以继续接受更新操作。例如:下面的灰色字体的日志记录为该osd1崩溃期间缺失的日志,obj7为新的写入的操作日志记录。last_update指向最新的更新版本(1,7),last_complete依然指向版本(1,2)。即last_update指的是最新的版本,last_complete指的是上次的更新版本。过程如下:

注:obj7的epoch似乎不应该为1了
last_complete为Recovery修复进程完成的指针。当该PG开始进行Recovery工作时,last_complete指针随着Recovery过程推进,它指向完成修复的版本。例如:当Recovery完成后last_complete指向最后一个修复的对象版本(1,6),如下图所示:

last_backfill为Backfill修复进程的指针。在Ceph Peering的过程中,该PG有osd2无法根据PG日志来恢复,就需要进行backfill过程。last_backfill初始化为MIN对象,用来记录Backfill的修复进程中已修复的对象。例如:进行Backfill操作时,扫描本地对象(按照对象的hash值排序)。last_backfill随修复的过程不断推进。如果对象小于等于last_backfill,就是已经修复完成的对象。如果对象大于last_backfill且对象的版本小于last_complete,就是处于缺失还没有修复的对象。过程如下所示:

当恢复完成之后,last_backfill设置为MAX值,表明恢复完成,设置last_complete等于last_update的值。
3. Peering的触发
通常在如下两种情形下会触发PG的Peering过程:
- OSD启动时主动触发
int OSD::init()
{
...
consume_map();
...
}
void OSD::consume_map()
{
...
}- 接收到新的OSDMap触发
对于上面第一种情况,这里不做介绍。这里主要讲述当OSD接受到新的OSDMap时,是如何触发Peering流程的。如下图所示:

3.1 接收新的OSDMap
OSD继承自Dispatcher,因此其可以作为网络消息的接收者:
bool OSD::ms_dispatch(Message *m)
{
....
while (dispatch_running) {
dout(10) << "ms_dispatch waiting for other dispatch thread to complete" << dendl;
dispatch_cond.Wait(osd_lock);
}
dispatch_running = true;
do_waiters();
_dispatch(m);
do_waiters();
dispatch_running = false;
dispatch_cond.Signal();
...
}
void OSD::do_waiters()
{
assert(osd_lock.is_locked());
dout(10) << "do_waiters -- start" << dendl;
finished_lock.Lock();
while (!finished.empty()) {
OpRequestRef next = finished.front();
finished.pop_front();
finished_lock.Unlock();
dispatch_op(next);
finished_lock.Lock();
}
finished_lock.Unlock();
dout(10) << "do_waiters -- finish" << dendl;
}
void OSD::activate_map(){
...
// process waiters
take_waiters(waiting_for_osdmap);
}
void take_waiters(list<OpRequestRef>& ls) {
finished_lock.Lock();
finished.splice(finished.end(), ls);
finished_lock.Unlock();
}ms_dispatch()所分发的一般是实时性不需要那么强的消息,因此这里我们看到其会调用do_waiters()来等待阻塞在osdmap上的消息分发完成。
如下是对osdmap的分发:
void OSD::_dispatch(Message *m)
{
...
switch (m->get_type()) {
// map and replication
case CEPH_MSG_OSD_MAP:
handle_osd_map(static_cast<MOSDMap*>(m));
break;
}
}3.2 handle_osd_map()实现对新OSDMap的处理
handle_osd_map()的实现比较简单,其主要是对接收到的Message中的相关OSDMap信息进行处理。如下图所示:
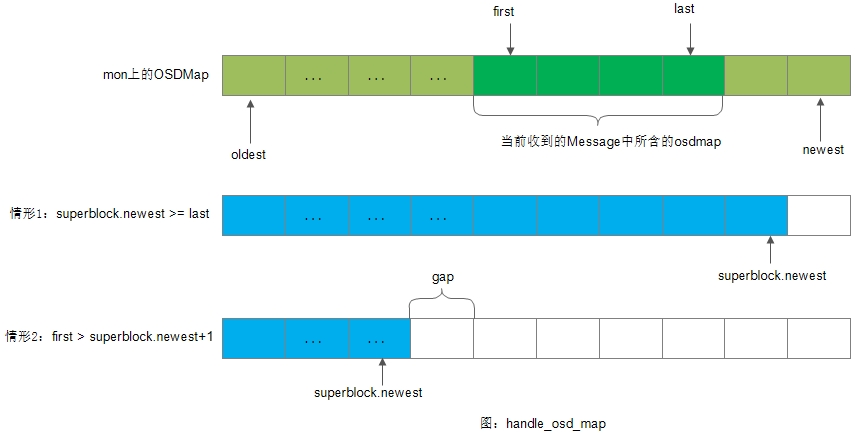
1)如果接收到的osdmaps中,最后一个OSDMap小于等于superblock.newest,则直接跳过
2) 如果收到的osdmaps中,第一个OSDMap大于superblock.newest +1,那么中间肯定存在缝隙,可分如下几种情况处理:
-
如果Monitor上最老的osdmap小于等于superblock.newest+1,那么说明我们仍然可以获取到OSD所需的所有OSDMap,此时只需要发起一个订阅请求即可;
-
如果Monitor上最老的osdmap大于superblock.newest+1,且monitor.oldest小于m.first,则当前OSD是无法从Monitor获得所有的OSDMap了,此时只能尝试从Monitor获取尽可能多的osdmap,因此也发起一个订阅请求;
-
如果Monitor上最老的osdmap大于superblock.newest+1,且monitor.oldest等于m.first,则此时虽然存在缝隙,但是我们也不能从Monitor获取到更多的OSDMap,此时将skip_maps置为true;
3)遍历Message中的所有OSDMap,然后存入缓存以及硬盘
注: 当skip_maps置为true时,我们要将superblock上保存的最老的OSDMap设置为m.first,确保OSD上所保存的OSDMap是连续的
3.3 处理已提交的OSDMaps
当接收到的OSDMap保存成功之后,就会回调_committed_osd_maps(),下面我们来看该函数的实现:
1)遍历接收到的osdmaps,如果有OSD在新的osdmap中不存在了或者不为up状态了,那么在发布新的OSDMap之前,必须等待阻塞在当前osdmap上的请求处理完成
void OSD::_committed_osd_maps(epoch_t first, epoch_t last, MOSDMap *m)
{
...
// advance through the new maps
for (epoch_t cur = first; cur <= last; cur++) {
OSDMapRef newmap = get_map(cur);
service.pre_publish_map(newmap); //将新的osdmap标记为预发布状态
/*
* kill connections to newly down osds
* (等待当前OSDMap上的请求处理完成)
*/
bool waited_for_reservations = false;
set<int> old;
osdmap->get_all_osds(old);
for (set<int>::iterator p = old.begin(); p != old.end(); ++p) {
if (*p != whoami &&
osdmap->have_inst(*p) && // in old map
(!newmap->exists(*p) || !newmap->is_up(*p))) { // but not the new one
if (!waited_for_reservations) {
service.await_reserved_maps();
waited_for_reservations = true;
}
note_down_osd(*p);
}
}
//将newmap发布
osdmap = newmap;
}
}2)若当前所设置的最新的OSDMap合法,且当前OSD处于active状态,那么检测当前OSD状态看是否符合OSDMap要求:
void OSD::_committed_osd_maps(epoch_t first, epoch_t last, MOSDMap *m)
{
...
if (osdmap->get_epoch() > 0 && is_active()) {
if (!osdmap->exists(whoami)) {
//当前OSD已经在OSDMap中不存在了,则发起相应的信号关闭当前OSD
}else if (!osdmap->is_up(whoami) ||
!osdmap->get_addr(whoami).probably_equals(
client_messenger->get_myaddr()) ||
!osdmap->get_cluster_addr(whoami).probably_equals(
cluster_messenger->get_myaddr()) ||
!osdmap->get_hb_back_addr(whoami).probably_equals(
hb_back_server_messenger->get_myaddr()) ||
(osdmap->get_hb_front_addr(whoami) != entity_addr_t() &&
!osdmap->get_hb_front_addr(whoami).probably_equals(
hb_front_server_messenger->get_myaddr()))){
//当前OSD的绑定信息出现了错误,需要重新绑定
}
}
}3)消费并激活OSDMap
void OSD::_committed_osd_maps(epoch_t first, epoch_t last, MOSDMap *m)
{
...
// yay!
consume_map();
if (is_active() || is_waiting_for_healthy())
maybe_update_heartbeat_peers();
if (!is_active()) {
dout(10) << " not yet active; waiting for peering wq to drain" << dendl;
peering_wq.drain();
} else {
activate_map();
}
...
}对于consume_map()函数,我们放到后面来讲解,现在我们来看一下activate_map()的实现:
void OSD::activate_map()
{
...
service.activate_map();
// process waiters
take_waiters(waiting_for_osdmap);
}
void take_waiters(list<OpRequestRef>& ls) {
finished_lock.Lock();
finished.splice(finished.end(), ls);
finished_lock.Unlock();
}我们知道waiting_for_osdmap里面存放的是一些因等待新osdmap而阻塞的请求,现在新的osdmap已经发布了,因此这里将相关的请求放入到finished队列里。
注:waiting_for_osdmap里面存放的是不需要绑定session的消息
3.4 消费OSDMap
在OSD::consume_map()中主要做如下事情:
1) 遍历pg_map,检查是否有PG需要移除,或者是否有PG需要分裂
void OSD::consume_map()
{
// scan pg's
{
RWLock::RLocker l(pg_map_lock);
for (ceph::unordered_map<spg_t,PG*>::iterator it = pg_map.begin();it != pg_map.end();++it) {
PG *pg = it->second;
pg->lock();
if (pg->is_primary())
num_pg_primary++;
else if (pg->is_replica())
num_pg_replica++;
else
num_pg_stray++;
if (!osdmap->have_pg_pool(pg->info.pgid.pool())) {
//pool is deleted!
to_remove.push_back(PGRef(pg));
} else {
service.init_splits_between(it->first, service.get_osdmap(), osdmap);
}
pg->unlock();
}
}
for (list<PGRef>::iterator i = to_remove.begin();i != to_remove.end();to_remove.erase(i++)) {
RWLock::WLocker locker(pg_map_lock);
(*i)->lock();
_remove_pg(&**i);
(*i)->unlock();
}
to_remove.clear();
}2) 将OSDMap发布到OSDService
void OSD::consume_map()
{
...
service.pre_publish_map(osdmap);
service.await_reserved_maps();
service.publish_map(osdmap);
dispatch_sessions_waiting_on_map();
}这里注意,我们在_committed_osd_maps()函数里只是将新收到的OSDMap发布给了OSD,在这里才将该最新的OSD发布到OSDService里。我们在进行数据读写操作时用的都是OSDService::osdmap。在真正发布之前,我们需要等到前一个OSDMap上的请求都执行完成。
session_waiting_for_map中所存放的一般是需要绑定session且因等待osdmap而阻塞的消息,因此这里我们调用dispatch_sessions_waiting_on_map()来对阻塞的消息进行分发。
注:要绑定session,一般是说明请求与OSDMap严重相关,且一般需要对相关的请求做响应
3)移除session_waiting_for_pg中不符合条件的PG
void OSD::consume_map()
{
// remove any PGs which we no longer host from the session waiting_for_pg lists
set<spg_t> pgs_to_check;
get_pgs_with_waiting_sessions(&pgs_to_check);
for (set<spg_t>::iterator p = pgs_to_check.begin();p != pgs_to_check.end();++p) {
if (!(osdmap->is_acting_osd_shard(p->pgid, whoami, p->shard))) {
set<Session*> concerned_sessions;
get_sessions_possibly_interested_in_pg(*p, &concerned_sessions);
for (set<Session*>::iterator i = concerned_sessions.begin();i != concerned_sessions.end();++i) {
{
Mutex::Locker l((*i)->session_dispatch_lock);
session_notify_pg_cleared(*i, osdmap, *p);
}
(*i)->put();
}
}
}
}由于OSDMap发生变化,当前OSD上的一些PG可能会由pg primary变为pg replica,因此这里将session_waiting_for_pg中一些不再符合条件的PG移除。
4) 向当前OSD上的所有PG发送CephPeeringEvt事件
void OSD::consume_map()
{
// scan pg's
{
RWLock::RLocker l(pg_map_lock);
for (ceph::unordered_map<spg_t,PG*>::iterator it = pg_map.begin();it != pg_map.end();++it) {
PG *pg = it->second;
pg->lock();
pg->queue_null(osdmap->get_epoch(), osdmap->get_epoch());
pg->unlock();
}
logger->set(l_osd_pg, pg_map.size());
}
}
void PG::queue_null(epoch_t msg_epoch,epoch_t query_epoch)
{
dout(10) << "null" << dendl;
queue_peering_event(
CephPeeringEvtRef(std::make_shared<CephPeeringEvt>(msg_epoch, query_epoch,
NullEvt())));
}
void PG::queue_peering_event(CephPeeringEvtRef evt)
{
if (old_peering_evt(evt))
return;
peering_queue.push_back(evt);
osd->queue_for_peering(this);
}
void OSDService::queue_for_peering(PG *pg)
{
peering_wq.queue(pg);
}这里我们看到,OSD会遍历pg_map上的所有PG(包括pg primary以及pg replica),然后向其发送NullEvt事件。事件最终会添加进PG::peering_queue中,并且会将该PG添加到OSDService::peering_wq(即OSD::peering_wq,因为OSDService::peering_wq只是一个引用)
这里我们注意,CephPeeringEvt::epoch_sent以及CephPeeringEvt::epoch_requested都设置为了当前OSD::osdmap的版本号。
[参看]
