ceph peering机制再研究(5)
在上文我们讲到当接收到新的OSDMap,会向该OSD上的所有PG所有PG投递CephPeeringEvt事件。本章我们从该事件讲起,详细地讲述Peering地整个过程。
1. PG::queue_peering_event()
void PG::queue_peering_event(CephPeeringEvtRef evt)
{
if (old_peering_evt(evt))
return;
peering_queue.push_back(evt);
osd->queue_for_peering(this);
}
void PG::queue_null(epoch_t msg_epoch,epoch_t query_epoch)
{
dout(10) << "null" << dendl;
queue_peering_event(
CephPeeringEvtRef(std::make_shared<CephPeeringEvt>(msg_epoch, query_epoch,
NullEvt())));
}我们知道OSD::peering_wq是OSD调度PG进行peering的关键。基本上有如下两种方式会向OSD::perring_wq投递事件:
-
PG::queue_null()
-
PG::queue_peering_event()
下面我们分别搜索这两个函数调用的地方,来看看在什么情况下会向OSD::peering_wq投递peering事件:
1)接收到新的OSDMap,在OSD::consume_map()中投递NullEvt事件
void OSD::consume_map()
{
...
// scan pg's
{
RWLock::RLocker l(pg_map_lock);
for (ceph::unordered_map<spg_t,PG*>::iterator it = pg_map.begin();it != pg_map.end();++it) {
PG *pg = it->second;
pg->lock();
pg->queue_null(osdmap->get_epoch(), osdmap->get_epoch());
pg->unlock();
}
logger->set(l_osd_pg, pg_map.size());
}
}2) OSD::handle_pg_peering_evt()中当需要重生parent pg时,投递NullEvt
void OSD::handle_pg_peering_evt(
spg_t pgid,
const pg_history_t& orig_history,
pg_interval_map_t& pi,
epoch_t epoch,
PG::CephPeeringEvtRef evt)
{
PG::RecoveryCtx rctx = create_context();
switch (result) {
case RES_PARENT: {
....
parent->queue_null(osdmap->get_epoch(), osdmap->get_epoch());
}
}
}3) PG分裂时投递NullEvt
void OSD::add_newly_split_pg(PG *pg, PG::RecoveryCtx *rctx)
{
pg->queue_null(e, e);
}4) PG创建时投递NullEvt
void OSD::handle_pg_create(OpRequestRef op)
{
map<pg_t,utime_t>::iterator ci = m->ctimes.begin();
for (map<pg_t,pg_create_t>::iterator p = m->mkpg.begin();p != m->mkpg.end();++p, ++ci) {
...
handle_pg_peering_evt(
pgid,
history,
pi,
osdmap->get_epoch(),
PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
osdmap->get_epoch(),
osdmap->get_epoch(),
PG::NullEvt()))
);
}
}5) 当PG primary收到非primary发送过来的PGNotify消息时,投递MNotifyRec事件
/** PGNotify
* from non-primary to primary
* includes pg_info_t.
* NOTE: called with opqueue active.
*/
void OSD::handle_pg_notify(OpRequestRef op)
{
...
for (vector<pair<pg_notify_t, pg_interval_map_t> >::iterator it = m->get_pg_list().begin();it != m->get_pg_list().end();++it) {
if (it->first.info.pgid.preferred() >= 0) {
dout(20) << "ignoring localized pg " << it->first.info.pgid << dendl;
continue;
}
handle_pg_peering_evt(
spg_t(it->first.info.pgid.pgid, it->first.to),
it->first.info.history, it->second,
it->first.query_epoch,
PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
it->first.epoch_sent, it->first.query_epoch,
PG::MNotifyRec(pg_shard_t(from, it->first.from), it->first,
op->get_req()->get_connection()->get_features())))
);
}
}6) 当收到pg_log时,投递MLogRec事件
void OSD::handle_pg_log(OpRequestRef op)
{
...
handle_pg_peering_evt(
spg_t(m->info.pgid.pgid, m->to),
m->info.history, m->past_intervals, m->get_epoch(),
PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
m->get_epoch(), m->get_query_epoch(),
PG::MLogRec(pg_shard_t(from, m->from), m)))
);
}7) 当收到pg_info时,投递MInfoRec事件
void OSD::handle_pg_info(OpRequestRef op)
{
for (vector<pair<pg_notify_t,pg_interval_map_t> >::iterator p = m->pg_list.begin();p != m->pg_list.end();++p) {
if (p->first.info.pgid.preferred() >= 0) {
dout(10) << "ignoring localized pg " << p->first.info.pgid << dendl;
continue;
}
handle_pg_peering_evt(
spg_t(p->first.info.pgid.pgid, p->first.to),
p->first.info.history, p->second, p->first.epoch_sent,
PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
p->first.epoch_sent, p->first.query_epoch,
PG::MInfoRec(
pg_shard_t(
from, p->first.from), p->first.info, p->first.epoch_sent)))
);
}
}关于MNotifyRec与MInfoRec的区别:
-
MNotifyRec通常是由非PG primary发送给PG primary的pg_info而产生的(一般是PG Primary主动发起查询,然后非PG primary被动回复);
-
MInfoRec通常是在peering完成后,由PG replica主动告知给PG Primary的pg_info信息;或者PG Replica对比权威pg_info当发现自己有丢失的对象时告知给PG primary的(总结为:MInfoRec一般是已经拥有权威pg_info后,replica将自己的pg_info_t告知给PG primary所产生的?)
8) PG在进行Backfill预约时
void OSD::handle_pg_backfill_reserve(OpRequestRef op)
{
...
PG::CephPeeringEvtRef evt;
if (m->type == MBackfillReserve::REQUEST) {
evt = PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
m->query_epoch,
m->query_epoch,
PG::RequestBackfillPrio(m->priority)));
} else if (m->type == MBackfillReserve::GRANT) {
evt = PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
m->query_epoch,
m->query_epoch,
PG::RemoteBackfillReserved()));
} else if (m->type == MBackfillReserve::REJECT) {
evt = PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
m->query_epoch,
m->query_epoch,
PG::RemoteReservationRejected()));
} else {
assert(0);
}
...
pg->queue_peering_event(evt);
}9)PG在进行Recovery预约时
void OSD::handle_pg_recovery_reserve(OpRequestRef op)
{
PG::CephPeeringEvtRef evt;
if (m->type == MRecoveryReserve::REQUEST) {
evt = PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
m->query_epoch,
m->query_epoch,
PG::RequestRecovery()));
} else if (m->type == MRecoveryReserve::GRANT) {
evt = PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
m->query_epoch,
m->query_epoch,
PG::RemoteRecoveryReserved()));
} else if (m->type == MRecoveryReserve::RELEASE) {
evt = PG::CephPeeringEvtRef(
new PG::CephPeeringEvt(
m->query_epoch,
m->query_epoch,
PG::RecoveryDone()));
} else {
assert(0);
}
...
pg->queue_peering_event(evt);
}10) PG primary在搜到所有副本被激活时产生AllReplicasActivated事件
void PG::all_activated_and_committed()
{
queue_peering_event(
CephPeeringEvtRef(
std::make_shared<CephPeeringEvt>(
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
AllReplicasActivated())));
}11) PG在scrub过程中发现错误时产生DoRecovery事件
void PG::scrub_finish()
{
if (has_error) {
queue_peering_event(
CephPeeringEvtRef(
std::make_shared<CephPeeringEvt>(
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
DoRecovery())));
}
}12) PG执行Flush时产生FlushEvt事件
void PG::queue_flushed(epoch_t e)
{
dout(10) << "flushed" << dendl;
queue_peering_event(
CephPeeringEvtRef(std::make_shared<CephPeeringEvt>(e, e,
FlushedEvt())));
}13) PG Replica或PG Stray收到PG Primary的MOSDPGQuery查询时产生MQuery事件
/** PGQuery
* from primary to replica | stray
* NOTE: called with opqueue active.
*/
void OSD::handle_pg_query(OpRequestRef op)
{
{
RWLock::RLocker l(pg_map_lock);
if (pg_map.count(pgid)) {
PG *pg = 0;
pg = _lookup_lock_pg_with_map_lock_held(pgid);
pg->queue_query(
it->second.epoch_sent, it->second.epoch_sent,
pg_shard_t(from, it->second.from), it->second);
pg->unlock();
continue;
}
}
}
void PG::queue_query(epoch_t msg_epoch,
epoch_t query_epoch,
pg_shard_t from, const pg_query_t& q)
{
dout(10) << "handle_query " << q << " from replica " << from << dendl;
queue_peering_event(
CephPeeringEvtRef(std::make_shared<CephPeeringEvt>(msg_epoch, query_epoch,
MQuery(from, q, query_epoch))));
}14) 扫描到PG太满时产生BackfillTooFull事件
void ReplicatedPG::do_scan(
OpRequestRef op,
ThreadPool::TPHandle &handle)
{
switch (m->op) {
case MOSDPGScan::OP_SCAN_GET_DIGEST:
{
double ratio, full_ratio;
if (osd->too_full_for_backfill(&ratio, &full_ratio)) {
dout(1) << __func__ << ": Canceling backfill, current usage is "<< ratio << ", which exceeds " << full_ratio << dendl;
queue_peering_event(
CephPeeringEvtRef(
std::make_shared<CephPeeringEvt>(
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
BackfillTooFull())));
return;
}
}
}
}15) 收到Backfill完成消息时产生RecoveryDone事件
void ReplicatedPG::do_backfill(OpRequestRef op)
{
}16) PG Primary在activate完成时,根据条件产生不同事件
void ReplicatedPG::on_activate()
{
if(needs_recovery()){
//产生DoRecovery事件
}else if(needs_backfill()){
//产生RequestBackfill事件
}else{
//产生AllReplicasRecovered()事件
}
}16) Recovery过程中根据情况产生相应事件
bool ReplicatedPG::start_recovery_ops(
int max, ThreadPool::TPHandle &handle,
int *ops_started)
{
}2. OSD::process_peering_events()
process_peering_events()是OSD处理peering事件的总入口,是一个非常关键的函数,下面我们来看实现步骤:
void OSD::process_peering_events(
const list<PG*> &pgs,
ThreadPool::TPHandle &handle
)
{
//1) 创建PG::RecoveryCtx
//2) 遍历每一个需要Peering的PG
for (list<PG*>::const_iterator i = pgs.begin();i != pgs.end();++i) {
//2.1) 调用advance_pg()来追赶osdmap(每次至多只会追赶g_conf->osd_map_max_advance个,防止OSD一直被一个PG占用)
//2.2) 从pg::peering_queue中弹出一个CephPeeringEvt事件,然后调用PG::handle_peering_event()来进行处理
//2.3)检查是否需要进行up_thru,并且计算出up_thru的OSD epoch值
//2.4) 保存PG所对应的RecoveryCtx::transaction
}
//3) 如果需要up_thr,则OSD向Monitor申请up_thru
//4) 对PG::RecoveryCtx中的一些上下文信息进行分发
//5) 如果要产生pg_temp,则OSD向Monitor发起生成pg_temp的请求
}如下图所示:
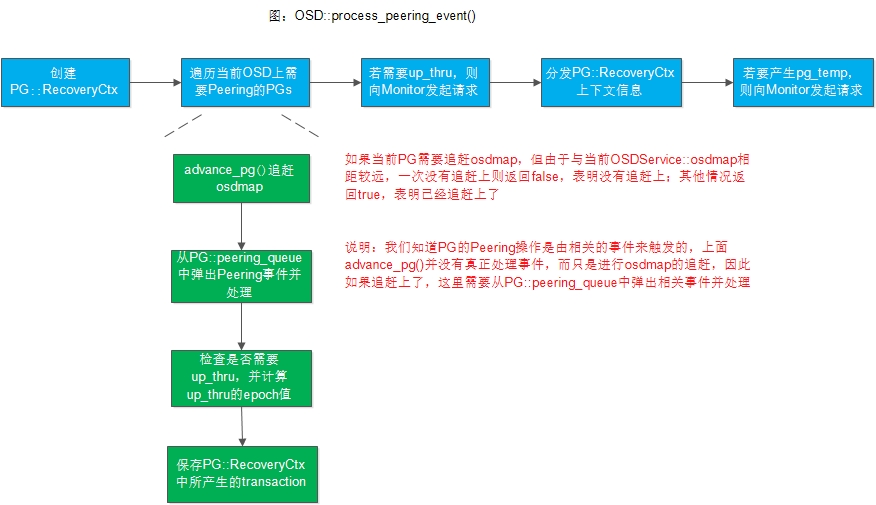
下面我们逐一讲述这一过程:
2.1 创建PG::RecoveryCtx
void OSD::process_peering_events(
const list<PG*> &pgs,
ThreadPool::TPHandle &handle
)
{
OSDMapRef curmap = service.get_osdmap();
PG::RecoveryCtx rctx = create_context();
rctx.handle = &handle;
}
PG::RecoveryCtx OSD::create_context()
{
ObjectStore::Transaction *t = new ObjectStore::Transaction;
C_Contexts *on_applied = new C_Contexts(cct);
C_Contexts *on_safe = new C_Contexts(cct);
map<int, map<spg_t,pg_query_t> > *query_map =new map<int, map<spg_t, pg_query_t> >;
map<int,vector<pair<pg_notify_t, pg_interval_map_t> > > *notify_list = new map<int, vector<pair<pg_notify_t, pg_interval_map_t> > >;
map<int,vector<pair<pg_notify_t, pg_interval_map_t> > > *info_map = new map<int,vector<pair<pg_notify_t, pg_interval_map_t> > >;
PG::RecoveryCtx rctx(query_map, info_map, notify_list,on_applied, on_safe, t);
return rctx;
}代码比较简单,这里不做介绍。
2.2 追赶osdmap
void OSD::process_peering_events(
const list<PG*> &pgs,
ThreadPool::TPHandle &handle
)
{
OSDMapRef curmap = service.get_osdmap();
...
for (list<PG*>::const_iterator i = pgs.begin();i != pgs.end();++i) {
set<boost::intrusive_ptr<PG> > split_pgs;
PG *pg = *i;
pg->lock_suspend_timeout(handle);
curmap = service.get_osdmap();
if (pg->deleting) {
pg->unlock();
continue;
}
if (!advance_pg(curmap->get_epoch(), pg, handle, &rctx, &split_pgs)) {
// we need to requeue the PG explicitly since we didn't actually
// handle an event
peering_wq.queue(pg);
} else {
assert(!pg->peering_queue.empty());
PG::CephPeeringEvtRef evt = pg->peering_queue.front();
pg->peering_queue.pop_front();
pg->handle_peering_event(evt, &rctx);
}
...
}
}上面我们看到会遍历具有CephPeeringEvt事件的PG列表,然后调用advance_pg()函数来判断当前PG是否已经追赶上了OSDService::osdmap:
-
如果没有追赶上,advance_pg()返回false,此时因为我们并没有处理该PG上的CephPeeringEvt,因此需要将PG重新放入peering_wq;
-
如果追赶上了,则从pg->peering_queue中弹出一个事件,然后调用pg->handle_peering_event()来进行处理
这里我们先看OSD::advance_pg()的实现:
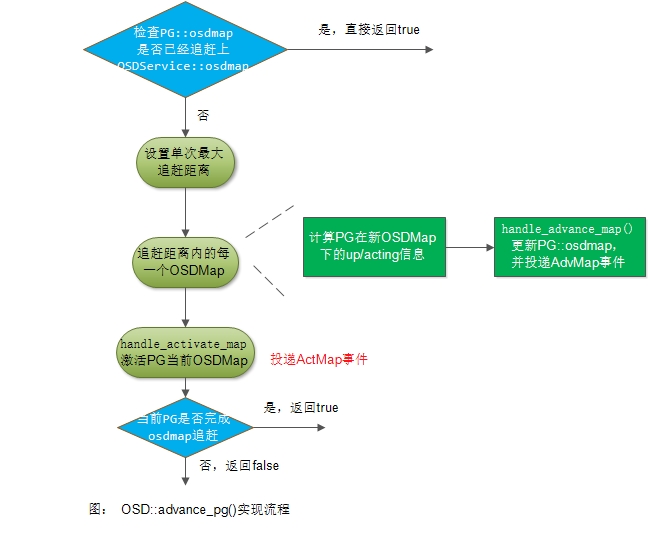
1) 如果当前PG::osdmap已经追上OSDService::osdmap,不需要处理直接返回true
bool OSD::advance_pg(
epoch_t osd_epoch, PG *pg,
ThreadPool::TPHandle &handle,
PG::RecoveryCtx *rctx,
set<boost::intrusive_ptr<PG> > *new_pgs)
{
epoch_t next_epoch = pg->get_osdmap()->get_epoch() + 1;
OSDMapRef lastmap = pg->get_osdmap();
if (lastmap->get_epoch() == osd_epoch)
return true;
}2) 设置单次最大能追赶的距离
bool OSD::advance_pg(
epoch_t osd_epoch, PG *pg,
ThreadPool::TPHandle &handle,
PG::RecoveryCtx *rctx,
set<boost::intrusive_ptr<PG> > *new_pgs)
{
epoch_t min_epoch = service.get_min_pg_epoch();
epoch_t max;
if (min_epoch) {
max = min_epoch + g_conf->osd_map_max_advance;
} else {
max = next_epoch + g_conf->osd_map_max_advance;
}
}3) 追赶osdmap
bool OSD::advance_pg(
epoch_t osd_epoch, PG *pg,
ThreadPool::TPHandle &handle,
PG::RecoveryCtx *rctx,
set<boost::intrusive_ptr<PG> > *new_pgs)
{
for (;next_epoch <= osd_epoch && next_epoch <= max;++next_epoch) {
OSDMapRef nextmap = service.try_get_map(next_epoch);
if (!nextmap) {
dout(20) << __func__ << " missing map " << next_epoch << dendl;
// make sure max is bumped up so that we can get past any
// gap in maps
max = MAX(max, next_epoch + g_conf->osd_map_max_advance);
continue;
}
vector<int> newup, newacting;
int up_primary, acting_primary;
nextmap->pg_to_up_acting_osds(
pg->info.pgid.pgid,
&newup, &up_primary,
&newacting, &acting_primary);
pg->handle_advance_map(
nextmap, lastmap, newup, up_primary,
newacting, acting_primary, rctx);
// Check for split!
set<spg_t> children;
spg_t parent(pg->info.pgid);
if (parent.is_split(
lastmap->get_pg_num(pg->pool.id),
nextmap->get_pg_num(pg->pool.id),
&children)) {
service.mark_split_in_progress(pg->info.pgid, children);
split_pgs(pg, children, new_pgs, lastmap, nextmap,rctx);
}
lastmap = nextmap;
handle.reset_tp_timeout();
}
}这里我们看到首先会调用pg_to_up_acting_osds()来计算在新的OSDMap下当前PG的up set、up_primary、acting set、acting primary。接着会调用PG::handle_advance_map()来处理当前版本OSDMap的追赶,之后还会根据前后两个OSDMap的差异来判断PG是否产生了分裂(如果产生了分裂,则调用split_pgs()进行处理,关于PG的分裂这里不展开说)。
下面我们来看PG::handle_advance_map()的实现:
void PG::handle_advance_map(
OSDMapRef osdmap, OSDMapRef lastmap,
vector<int>& newup, int up_primary,
vector<int>& newacting, int acting_primary,
RecoveryCtx *rctx)
{
update_osdmap_ref(osdmap);
pool.update(osdmap);
if (cct->_conf->osd_debug_verify_cached_snaps) {
interval_set<snapid_t> actual_removed_snaps;
const pg_pool_t *pi = osdmap->get_pg_pool(info.pgid.pool());
assert(pi);
pi->build_removed_snaps(actual_removed_snaps);
if (!(actual_removed_snaps == pool.cached_removed_snaps)) {
derr << __func__ << ": mismatch between the actual removed snaps "
<< actual_removed_snaps << " and pool.cached_removed_snaps "
<< " pool.cached_removed_snaps " << pool.cached_removed_snaps
<< dendl;
}
assert(actual_removed_snaps == pool.cached_removed_snaps);
}
AdvMap evt(
osdmap, lastmap, newup, up_primary,
newacting, acting_primary);
recovery_state.handle_event(evt, rctx);
if (pool.info.last_change == osdmap_ref->get_epoch())
on_pool_change();
}我们来看具体的实现步骤:
-
调用update_osdmap_ref()来更新PG::osdmap
-
产生一个AdvMap事件,并交由PG的recovery_state状态机来进行处理(关于AdvMap事件的处理,我们后面详细讲解)
4) 激活当前OSDMap
void PG::handle_advance_map(
OSDMapRef osdmap, OSDMapRef lastmap,
vector<int>& newup, int up_primary,
vector<int>& newacting, int acting_primary,
RecoveryCtx *rctx)
{
pg->handle_activate_map(rctx);
if (next_epoch <= osd_epoch) {
dout(10) << __func__ << " advanced to max " << max
<< " past min epoch " << min_epoch
<< " ... will requeue " << *pg << dendl;
return false;
}
return true;
}
void PG::handle_activate_map(RecoveryCtx *rctx)
{
dout(10) << "handle_activate_map " << dendl;
ActMap evt;
recovery_state.handle_event(evt, rctx);
if (osdmap_ref->get_epoch() - last_persisted_osdmap_ref->get_epoch() >
cct->_conf->osd_pg_epoch_persisted_max_stale) {
dout(20) << __func__ << ": Dirtying info: last_persisted is "
<< last_persisted_osdmap_ref->get_epoch()
<< " while current is " << osdmap_ref->get_epoch() << dendl;
dirty_info = true;
} else {
dout(20) << __func__ << ": Not dirtying info: last_persisted is "
<< last_persisted_osdmap_ref->get_epoch()
<< " while current is " << osdmap_ref->get_epoch() << dendl;
}
if (osdmap_ref->check_new_blacklist_entries()) check_blacklisted_watchers();
}这里我们看到会生成一个ActMap事件,并交由PG的recovery_state状态机来进行处理(关于ActMap事件的处理,我们后面详细讲解)
2.3 处理up_thru相关
void PG::handle_advance_map(
OSDMapRef osdmap, OSDMapRef lastmap,
vector<int>& newup, int up_primary,
vector<int>& newacting, int acting_primary,
RecoveryCtx *rctx)
{
for (;next_epoch <= osd_epoch && next_epoch <= max;++next_epoch) {
need_up_thru = pg->need_up_thru || need_up_thru;
same_interval_since = MAX(pg->info.history.same_interval_since,same_interval_since);
}
}关于up_thru的作用及原理,请参看其他章节,这里我们不做介绍。
2.4 保存PG::RecoveryCtx中所产生的transaction
void PG::handle_advance_map(
OSDMapRef osdmap, OSDMapRef lastmap,
vector<int>& newup, int up_primary,
vector<int>& newacting, int acting_primary,
RecoveryCtx *rctx)
{
for (;next_epoch <= osd_epoch && next_epoch <= max;++next_epoch) {
dispatch_context_transaction(rctx, pg, &handle);
}
}
void OSD::dispatch_context_transaction(PG::RecoveryCtx &ctx, PG *pg,
ThreadPool::TPHandle *handle)
{
if (!ctx.transaction->empty()) {
if (!ctx.created_pgs.empty()) {
ctx.on_applied->add(new C_OpenPGs(ctx.created_pgs, store));
}
int tr = store->queue_transaction(
pg->osr.get(),
std::move(*ctx.transaction), ctx.on_applied, ctx.on_safe, NULL,
TrackedOpRef(), handle);
delete (ctx.transaction);
assert(tr == 0);
ctx.transaction = new ObjectStore::Transaction;
ctx.on_applied = new C_Contexts(cct);
ctx.on_safe = new C_Contexts(cct);
}
}这里实现较为简单,不做介绍
2.5 分发PG::RecoveryCtx上下文信息,以及处理pg_temp
void PG::handle_advance_map(
OSDMapRef osdmap, OSDMapRef lastmap,
vector<int>& newup, int up_primary,
vector<int>& newacting, int acting_primary,
RecoveryCtx *rctx)
{
...
OSDMapRef curmap = service.get_osdmap();
if (need_up_thru)
queue_want_up_thru(same_interval_since);
dispatch_context(rctx, 0, curmap, &handle);
service.send_pg_temp();
}这里我们主要来看一下dispatch_context的实现:
void OSD::dispatch_context(PG::RecoveryCtx &ctx, PG *pg, OSDMapRef curmap,
ThreadPool::TPHandle *handle)
{
if (service.get_osdmap()->is_up(whoami) && is_active()) {
do_notifies(*ctx.notify_list, curmap);
do_queries(*ctx.query_map, curmap);
do_infos(*ctx.info_map, curmap);
}
delete ctx.notify_list;
delete ctx.query_map;
delete ctx.info_map;
if ((ctx.on_applied->empty() &&
ctx.on_safe->empty() &&
ctx.transaction->empty() &&
ctx.created_pgs.empty()) || !pg) {
delete ctx.transaction;
delete ctx.on_applied;
delete ctx.on_safe;
assert(ctx.created_pgs.empty());
} else {
if (!ctx.created_pgs.empty()) {
ctx.on_applied->add(new C_OpenPGs(ctx.created_pgs, store));
}
int tr = store->queue_transaction(
pg->osr.get(),
std::move(*ctx.transaction), ctx.on_applied, ctx.on_safe, NULL, TrackedOpRef(),
handle);
delete (ctx.transaction);
assert(tr == 0);
}
}这里我们看到,主要是分发上面Peering所产生的notifies、queries、以及infos信息
[参看]
