ceph peering机制再研究(6)
在前面的章节中,我们从OSD接收到新的OSDMap开始讲起,然后讲述到其会向状态机投递两个事件:
-
AdvMap事件(advance map)
-
ActMap事件(activate map)
本章承接上文,从这两个事件入手,引出本文重点: PG Peering。但是在这里我还是想要先给出一张整体架构图,以更好的理解Peering流程。
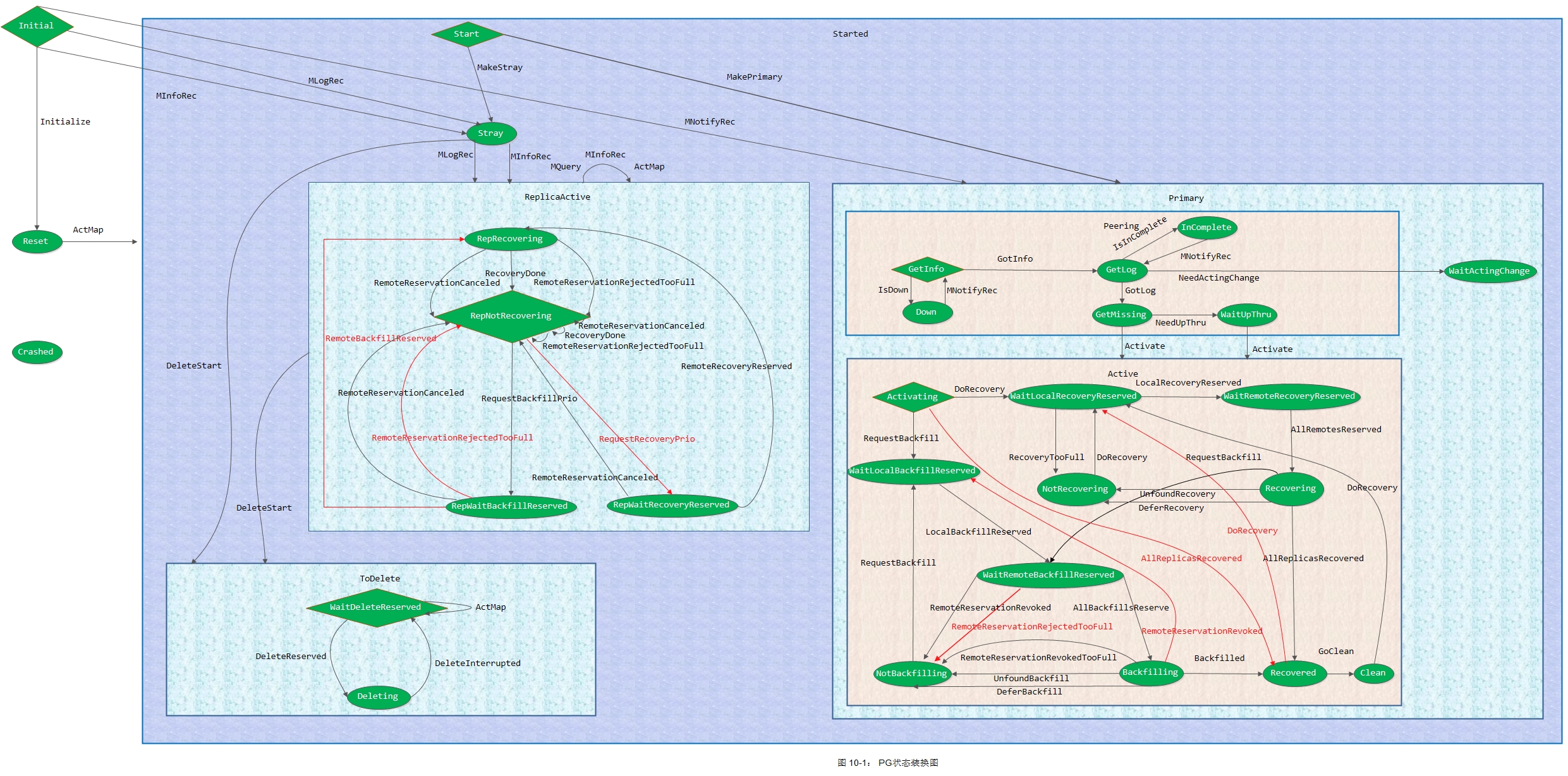
1. PG状态机接收到AdvMap事件
我们先来看看AdvMap事件数据结构:
struct AdvMap : boost::statechart::event< AdvMap > {
OSDMapRef osdmap;
OSDMapRef lastmap;
vector<int> newup, newacting;
int up_primary, acting_primary;
};各字段含义如下:
-
osdmap: 当前PG advance到的osdmap
-
lastmap: 当前PG上一版的osdmap
-
newup: AdvMap::osdmap版本下的up set
-
newacting: AdvMap.osdmap版本下的acting set
-
up_primary: AdvMap.osdmap版本下的up primary
-
acting_primary: AdvMap.osdmap版本下的acting primary
我们在代码中搜索AdvMap,发现在如下状态下都会接受AdvMap事件:
-
Started状态
-
Reset状态
-
Peering状态
-
Active状态
-
GetLog状态
-
WaitActingChange状态
-
InComplete状态
查看对应的代码,发现大部分都是先判断是否要重新启动Peering,如果要,则跳转到Reset状态,然后继续处理AdvMap事件。
1.1 Active状态下对AdvMap事件的处理
这里我们假设集群的初始状态为active+clean,因此这里收到AdvMap事件后是调用如下函数来进行处理:
boost::statechart::result PG::RecoveryState::Active::react(const AdvMap& advmap)
{
PG *pg = context< RecoveryMachine >().pg;
dout(10) << "Active advmap" << dendl;
if (!pg->pool.newly_removed_snaps.empty()) {
pg->snap_trimq.union_of(pg->pool.newly_removed_snaps);
dout(10) << *pg << " snap_trimq now " << pg->snap_trimq << dendl;
pg->dirty_info = true;
pg->dirty_big_info = true;
}
for (size_t i = 0; i < pg->want_acting.size(); i++) {
int osd = pg->want_acting[i];
if (!advmap.osdmap->is_up(osd)) {
pg_shard_t osd_with_shard(osd, shard_id_t(i));
assert(pg->is_acting(osd_with_shard) || pg->is_up(osd_with_shard));
}
}
bool need_publish = false;
/* Check for changes in pool size (if the acting set changed as a result,
* this does not matter) */
if (advmap.lastmap->get_pg_size(pg->info.pgid.pgid) != pg->get_osdmap()->get_pg_size(pg->info.pgid.pgid)) {
if (pg->get_osdmap()->get_pg_size(pg->info.pgid.pgid) <= pg->actingset.size()) {
pg->state_clear(PG_STATE_UNDERSIZED);
if (pg->needs_recovery()) {
pg->state_set(PG_STATE_DEGRADED);
} else {
pg->state_clear(PG_STATE_DEGRADED);
}
} else {
pg->state_set(PG_STATE_UNDERSIZED);
pg->state_set(PG_STATE_DEGRADED);
}
need_publish = true; // degraded may have changed
}
// if we haven't reported our PG stats in a long time, do so now.
if (pg->info.stats.reported_epoch + pg->cct->_conf->osd_pg_stat_report_interval_max < advmap.osdmap->get_epoch()) {
dout(20) << "reporting stats to osd after " << (advmap.osdmap->get_epoch() - pg->info.stats.reported_epoch)
<< " epochs" << dendl;
need_publish = true;
}
if (need_publish)
pg->publish_stats_to_osd();
return forward_event();
}下面我们来看具体实现步骤:
1) 检查pool size是否发生改变
unsigned get_pg_size(pg_t pg) const {
map<int64_t,pg_pool_t>::const_iterator p = pools.find(pg.pool());
assert(p != pools.end());
return p->second.get_size();
}
struct pg_pool_t {
__u8 size, min_size; ///< number of osds in each pg
__u8 crush_ruleset; ///< crush placement rule set
unsigned get_type() const { return type; }
unsigned get_size() const { return size; }
unsigned get_min_size() const { return min_size; }
int get_crush_ruleset() const { return crush_ruleset; }
};通常情况下OSDMap的变化不会导致pool的OSD size发生变化,因为一个pool的OSD个数一般是在设置rule时就已经确定了。因此,在这里如果前后两个OSDMap中,PG所在pool的osd size发生改变,则很有可能是通过执行如下命令进行了更改:
# ceph osd pool set {pool-name} size 2
因此如果pg->get_osdmap()->get_pg_size(pg->info.pgid.pgid)小于等于pg->actingset.size(),说明当前已经对pool的osd size进行了降低,因此会先清除PG_STATE_UNDERSIZED标识;否则说明当前已经对pool的osd size进行了增加,因此需要将PG状态设置为undersized + degraded。
2)将AdvMap事件继续往父状态机投递
在函数的最后我们看到通过forward_event()将事件继续往父状态机投递:
boost::statechart::result PG::RecoveryState::Active::react(const AdvMap& advmap)
{
...
return forward_event();
}Active状态的父状态为Primary,而Primary的父状态为Started。因此这里会投递到Started状态来进行处理。
1.2 Started处理Active抛上来的AdvMap事件
现在我们来看Started状态机是如何处理Active抛上来的AdvMap事件:
boost::statechart::result PG::RecoveryState::Started::react(const AdvMap& advmap)
{
dout(10) << "Started advmap" << dendl;
PG *pg = context< RecoveryMachine >().pg;
pg->check_full_transition(advmap.lastmap, advmap.osdmap);
if (pg->should_restart_peering(
advmap.up_primary,
advmap.acting_primary,
advmap.newup,
advmap.newacting,
advmap.lastmap,
advmap.osdmap)) {
dout(10) << "should_restart_peering, transitioning to Reset" << dendl;
post_event(advmap);
return transit< Reset >();
}
pg->remove_down_peer_info(advmap.osdmap);
return discard_event();
}1) 检查OSDMap及pool是否由not full转变为full
void PG::check_full_transition(OSDMapRef lastmap, OSDMapRef osdmap)
{
bool changed = false;
if (osdmap->test_flag(CEPH_OSDMAP_FULL) &&!lastmap->test_flag(CEPH_OSDMAP_FULL)) {
dout(10) << " cluster was marked full in " << osdmap->get_epoch() << dendl;
changed = true;
}
const pg_pool_t *pi = osdmap->get_pg_pool(info.pgid.pool());
assert(pi);
if (pi->has_flag(pg_pool_t::FLAG_FULL)) {
const pg_pool_t *opi = lastmap->get_pg_pool(info.pgid.pool());
if (!opi || !opi->has_flag(pg_pool_t::FLAG_FULL)) {
dout(10) << " pool was marked full in " << osdmap->get_epoch() << dendl;
changed = true;
}
}
if (changed) {
info.history.last_epoch_marked_full = osdmap->get_epoch();
dirty_info = true;
}
}代码实现较为简单,这里不做过多说明。
2) 检查是否需要重新发起新的peering
bool PG::should_restart_peering(
int newupprimary,
int newactingprimary,
const vector<int>& newup,
const vector<int>& newacting,
OSDMapRef lastmap,
OSDMapRef osdmap)
{
if (pg_interval_t::is_new_interval(
primary.osd,
newactingprimary,
acting,
newacting,
up_primary.osd,
newupprimary,
up,
newup,
osdmap,
lastmap,
info.pgid.pgid)) {
dout(20) << "new interval newup " << newup<< " newacting " << newacting << dendl;
return true;
} else {
return false;
}
}这里我们看到,只要产生了一个新的interval,PG::should_restart_peering()就会返回true,否则返回false。
-
若产生了新的interval,则状态机转变为Reset状态,并向其抛出AdvMap事件
-
若没有产生新的interval,则移除PG::peer_info中所有处于down状态的OSD的信息(未知此场景如何产生!),然后抛弃AdvMap事件。
这里因为我们要探讨PG的Peering流程,因此我们假设PG的一个副本OSD由up状态转变为down状态,从而会产生一个新的interval,因此会转到Reset状态。
1.3 Reset状态对AdvMap事件的处理
接着上面的假设,PG产生了新的interval,因此会转到Reset状态,并向其投递AdvMap事件:
boost::statechart::result PG::RecoveryState::Reset::react(const AdvMap& advmap)
{
PG *pg = context< RecoveryMachine >().pg;
dout(10) << "Reset advmap" << dendl;
// make sure we have past_intervals filled in. hopefully this will happen
// _before_ we are active.
pg->generate_past_intervals();
pg->check_full_transition(advmap.lastmap, advmap.osdmap);
if (pg->should_restart_peering(
advmap.up_primary,
advmap.acting_primary,
advmap.newup,
advmap.newacting,
advmap.lastmap,
advmap.osdmap)) {
dout(10) << "should restart peering, calling start_peering_interval again"<< dendl;
pg->start_peering_interval(
advmap.lastmap,
advmap.newup, advmap.up_primary,
advmap.newacting, advmap.acting_primary,
context< RecoveryMachine >().get_cur_transaction());
}
pg->remove_down_peer_info(advmap.osdmap);
return discard_event();
}我们简单分析一下实现流程:
1)调用PG::generate_past_intervals()来产生past_intervals,如果后续需要进行peering操作,那么就可以利用past_intervals的相关信息
2)检查是否需要重新发起新的peering
-
如果需要重新peering,那么就调用PG::start_peering_interval()开启一个新的peering流程
-
如果没有必要进行重新peering,则直接丢弃相应的事件
我们仍然按照上面的假设,PG会进行新的Peering操作,因此会调用到PG::start_peering_interval()
1.4 启动一个peering interval
此函数会在初始化一个peering之前被调用:
/* Called before initializing peering during advance_map */
void PG::start_peering_interval(
const OSDMapRef lastmap,
const vector<int>& newup, int new_up_primary,
const vector<int>& newacting, int new_acting_primary,
ObjectStore::Transaction *t)
{
//1) 将上一次的Peering进行重置
//2) 利用新的OSDMap初始化PG的up set、up primary、acting set、primary,并更新当前的PGinfo 信息
//3) 判断up、acting、primary是否发生变化,并更新PG状态
//4) 处理PG角色变化相关的问题
}PG::start_peering_interval()处理主流程如下图所示:

注:如果要进行Peering,那么PG的所有副本(主副本以及从副本)都会调用到此函数
1.4.1 进行Peering重置
因为这里我们要开启一个新的Peering流程,因此需要把前面未完成的Peering进行重置:
/* Called before initializing peering during advance_map */
void PG::start_peering_interval(
const OSDMapRef lastmap,
const vector<int>& newup, int new_up_primary,
const vector<int>& newacting, int new_acting_primary,
ObjectStore::Transaction *t)
{
const OSDMapRef osdmap = get_osdmap();
set_last_peering_reset();
}
void PG::set_last_peering_reset()
{
dout(20) << "set_last_peering_reset " << get_osdmap()->get_epoch() << dendl;
if (last_peering_reset != get_osdmap()->get_epoch()) {
last_peering_reset = get_osdmap()->get_epoch();
reset_interval_flush();
}
}
void PG::reset_interval_flush()
{
dout(10) << "Clearing blocked outgoing recovery messages" << dendl;
recovery_state.clear_blocked_outgoing();
Context *c = new QueuePeeringEvt<IntervalFlush>(this, get_osdmap()->get_epoch(), IntervalFlush());
if (!osr->flush_commit(c)) {
dout(10) << "Beginning to block outgoing recovery messages" << dendl;
recovery_state.begin_block_outgoing();
} else {
dout(10) << "Not blocking outgoing recovery messages" << dendl;
delete c;
}
}
void PG::RecoveryState::begin_block_outgoing() {
assert(!messages_pending_flush);
assert(orig_ctx);
assert(rctx);
messages_pending_flush = BufferedRecoveryMessages();
rctx = RecoveryCtx(*messages_pending_flush, *orig_ctx);
}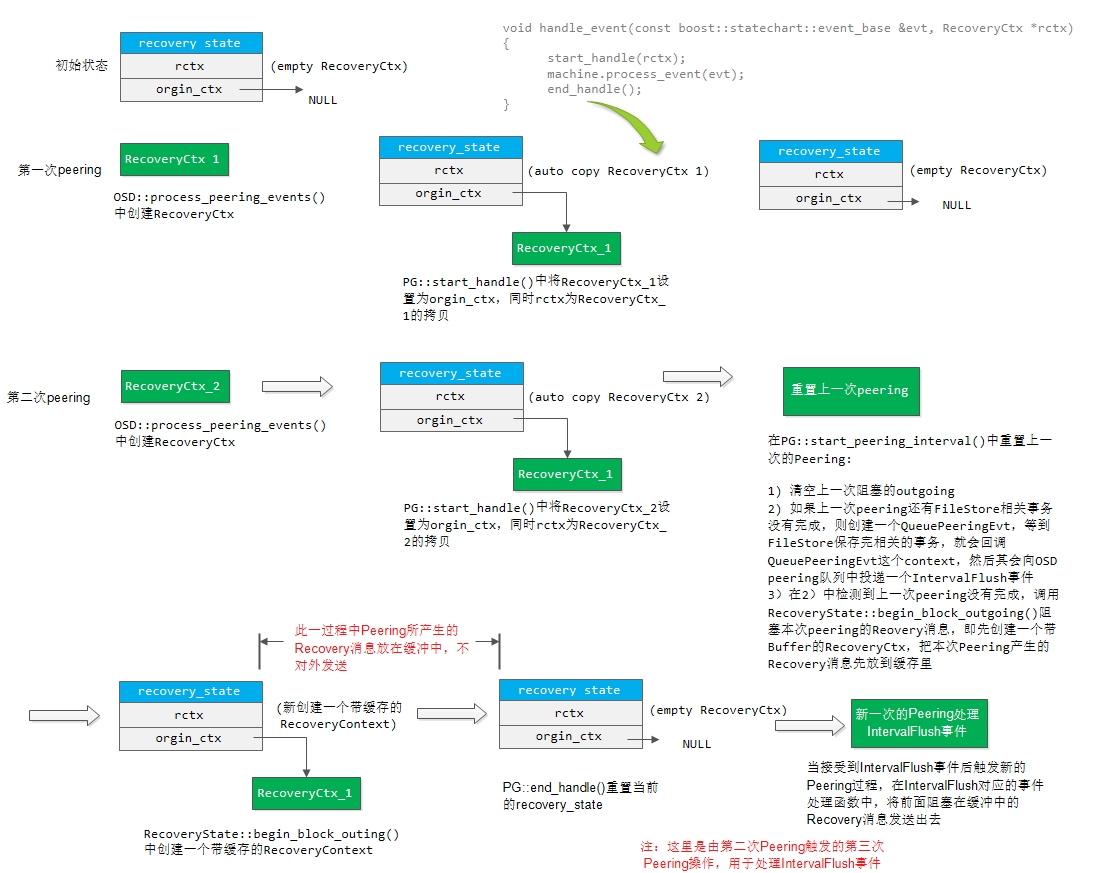
如上图所示,假设我们当前是属于第二次Peering阶段。如果该PG还有一些FileStore上的事务未处理完成,则会创建一个BufferedRecoveryMessages,然后将本次Peering所产生的RecoveryMessage都放入该Buffer中。等到FileStore中的事务处理完成就会回调一个Context,然后向OSD::peering_wq中投递一个IntervalFlush事件,这时就会将上一次所缓冲的RecoveryMessage发送出去。
注:之所以要把RecoveryMessages放到Buffer中缓存起来,猜测可能的原因是FileStore上的事务可能会产生相关的回调,从而将破坏PG本次Peering的状态机。
1.4.2 初始化新的up、acting信息,并更新pginfo信息
/* Called before initializing peering during advance_map */
void PG::start_peering_interval(
const OSDMapRef lastmap,
const vector<int>& newup, int new_up_primary,
const vector<int>& newacting, int new_acting_primary,
ObjectStore::Transaction *t)
{
...
vector<int> oldacting, oldup;
int oldrole = get_role();
unreg_next_scrub();
pg_shard_t old_acting_primary = get_primary();
pg_shard_t old_up_primary = up_primary;
bool was_old_primary = is_primary();
acting.swap(oldacting);
up.swap(oldup);
init_primary_up_acting(
newup,
newacting,
new_up_primary,
new_acting_primary);
if (info.stats.up != up ||info.stats.acting != acting ||
info.stats.up_primary != new_up_primary || info.stats.acting_primary != new_acting_primary) {
info.stats.up = up;
info.stats.up_primary = new_up_primary;
info.stats.acting = acting;
info.stats.acting_primary = new_acting_primary;
info.stats.mapping_epoch = info.history.same_interval_since;
}
pg_stats_publish_lock.Lock();
pg_stats_publish_valid = false;
pg_stats_publish_lock.Unlock();
// This will now be remapped during a backfill in cases
// that it would not have been before.
if (up != acting)
state_set(PG_STATE_REMAPPED);
else
state_clear(PG_STATE_REMAPPED);
...
}我们在OSD::advance_pg()中调用OSD::pg_to_up_acting_osds()算出了最新的up set、up_primary、acting set、primary,但是还没有真正设置到PG。在这里PG::start_peering_interval()中调用init_primary_up_acting(),这时就将这些真正设置到PG中。
接着更新PG的状态信息(info.stats)。之后根据up set与acting set是否相同,来设置PG的REMAPPED标识(注:一般出现pg_temp时会导致up set与acting set不一致)。
1.4.3 处理PG角色变化相关问题
/* Called before initializing peering during advance_map */
void PG::start_peering_interval(
const OSDMapRef lastmap,
const vector<int>& newup, int new_up_primary,
const vector<int>& newacting, int new_acting_primary,
ObjectStore::Transaction *t)
{
...
int oldrole = get_role();
...
int role = osdmap->calc_pg_role(osd->whoami, acting, acting.size());
if (pool.info.is_replicated() || role == pg_whoami.shard)
set_role(role);
else
set_role(-1);
// did acting, up, primary|acker change?
if (!lastmap) {
dout(10) << " no lastmap" << dendl;
dirty_info = true;
dirty_big_info = true;
info.history.same_interval_since = osdmap->get_epoch();
} else {
std::stringstream debug;
assert(info.history.same_interval_since != 0);
boost::scoped_ptr<IsPGRecoverablePredicate> recoverable(get_is_recoverable_predicate());
bool new_interval = pg_interval_t::check_new_interval(
old_acting_primary.osd,
new_acting_primary,
oldacting, newacting,
old_up_primary.osd,
new_up_primary,
oldup, newup,
info.history.same_interval_since,
info.history.last_epoch_clean,
osdmap,
lastmap,
info.pgid.pgid,
recoverable.get(),
&past_intervals,
&debug);
dout(10) << __func__ << ": check_new_interval output: "<< debug.str() << dendl;
if (new_interval) {
dout(10) << " noting past " << past_intervals.rbegin()->second << dendl;
dirty_info = true;
dirty_big_info = true;
info.history.same_interval_since = osdmap->get_epoch();
}
}
if (old_up_primary != up_primary || oldup != up) {
info.history.same_up_since = osdmap->get_epoch();
}
// this comparison includes primary rank via pg_shard_t
if (old_acting_primary != get_primary()) {
info.history.same_primary_since = osdmap->get_epoch();
}
on_new_interval();
dout(10) << " up " << oldup << " -> " << up
<< ", acting " << oldacting << " -> " << acting
<< ", acting_primary " << old_acting_primary << " -> " << new_acting_primary
<< ", up_primary " << old_up_primary << " -> " << new_up_primary
<< ", role " << oldrole << " -> " << role
<< ", features acting " << acting_features
<< " upacting " << upacting_features
<< dendl;
// deactivate.
state_clear(PG_STATE_ACTIVE);
state_clear(PG_STATE_PEERED);
state_clear(PG_STATE_DOWN);
state_clear(PG_STATE_RECOVERY_WAIT);
state_clear(PG_STATE_RECOVERING);
peer_purged.clear();
actingbackfill.clear();
snap_trim_queued = false;
scrub_queued = false;
// reset primary state?
if (was_old_primary || is_primary()) {
osd->remove_want_pg_temp(info.pgid.pgid);
}
clear_primary_state();
// pg->on_*
on_change(t);
assert(!deleting);
// should we tell the primary we are here?
send_notify = !is_primary();
if (role != oldrole ||was_old_primary != is_primary()) {
// did primary change?
if (was_old_primary != is_primary()) {
state_clear(PG_STATE_CLEAN);
clear_publish_stats();
// take replay queue waiters
list<OpRequestRef> ls;
for (map<eversion_t,OpRequestRef>::iterator it = replay_queue.begin();it != replay_queue.end();++it)
ls.push_back(it->second);
replay_queue.clear();
requeue_ops(ls);
}
on_role_change();
// take active waiters
requeue_ops(waiting_for_peered);
} else {
// no role change.
// did primary change?
if (get_primary() != old_acting_primary) {
dout(10) << *this << " " << oldacting << " -> " << acting << ", acting primary "
<< old_acting_primary << " -> " << get_primary() << dendl;
} else {
// primary is the same.
if (is_primary()) {
// i am (still) primary. but my replica set changed.
state_clear(PG_STATE_CLEAN);
dout(10) << oldacting << " -> " << acting<< ", replicas changed" << dendl;
}
}
}
}我们来看实现过程:
1) 调用pg_interval_t::check_new_interval()检查是否产生了一个新的interval,如果是则更新info.history.same_interval_since。
2) 如果old_up_primary不等于当前的up_primary,或者oldup不等于当前的up set,那么更新info.history.same_up_since
3) 如果old_acting_primary不等于当前的Primary,那么更新info.history.same_primary_since
4) 清除PG的相关状态标志
// deactivate.
state_clear(PG_STATE_ACTIVE);
state_clear(PG_STATE_PEERED);
state_clear(PG_STATE_DOWN);
state_clear(PG_STATE_RECOVERY_WAIT);
state_clear(PG_STATE_RECOVERING);需要说明的是,因为这里我们会停止Recovery操作,因此将PG_STATE_RECOVERING标志清除。
5) 根据PG当前副本role的变化情况,进行以下处理
首先我们先来看看role的计算:
//注:role的取值可以为 0 -- primary 1 -- replica -1 -- none
int OSDMap::calc_pg_role(int osd, const vector<int>& acting, int nrep)
{
if (!nrep)
nrep = acting.size();
return calc_pg_rank(osd, acting, nrep);
}
int OSDMap::calc_pg_rank(int osd, const vector<int>& acting, int nrep)
{
if (!nrep)
nrep = acting.size();
for (int i=0; i<nrep; i++)
if (acting[i] == osd)
return i;
return -1;
}-
如果role发生了变化,那么会回调on_role_change()函数,同时将waiting_for_peered当中的请求重新放入OSD::op_wq中
-
如果role没有发生变化(比如前后都是replica角色),判断PG的Primary是否发生改变,如果发生了改变,那么打印出相关日志信息
总结:
到此为止,OSD::advance_pg()中调用pg->handle_advance_map()所产生的AdvMap事件就已经处理完成。
仔细观察上面的流程,PG Replicas也是通过Reset::react(AdvMap)进入到PG::start_peering_interval()阶段。
2. PG状态机接收到ActMap事件
在OSD::advance_pg()中,调用pg->handle_advance_map()产生AdvMap事件并处理完成之后,接着又会调用pg->handle_activate_map()产生ActMap事件:
bool OSD::advance_pg(
epoch_t osd_epoch, PG *pg,
ThreadPool::TPHandle &handle,
PG::RecoveryCtx *rctx,
set<boost::intrusive_ptr<PG> > *new_pgs)
{
...
pg->handle_activate_map(rctx);
}
void PG::handle_activate_map(RecoveryCtx *rctx)
{
dout(10) << "handle_activate_map " << dendl;
ActMap evt;
recovery_state.handle_event(evt, rctx);
if (osdmap_ref->get_epoch() - last_persisted_osdmap_ref->get_epoch() >cct->_conf->osd_pg_epoch_persisted_max_stale) {
dout(20) << __func__ << ": Dirtying info: last_persisted is "<< last_persisted_osdmap_ref->get_epoch()
<< " while current is " << osdmap_ref->get_epoch() << dendl;
dirty_info = true;
} else {
dout(20) << __func__ << ": Not dirtying info: last_persisted is "<< last_persisted_osdmap_ref->get_epoch()
<< " while current is " << osdmap_ref->get_epoch() << dendl;
}
if (osdmap_ref->check_new_blacklist_entries()) check_blacklisted_watchers();
}我们看到其向recovery_state投递ActMap事件。
我们搜索ActMap,发现在如下状态下会接受ActMap事件:
-
Reset状态
-
Primary状态
-
Active状态
-
ReplicaActive状态
-
Stray状态
-
WaitUpThru状态
在我们前面的假设中,PG开始是处于active + clean状态,后面经过AdvMap事件进入到Reset状态。下面我们就从Reset状态下对ActMap事件的处理开始讲起。
2.1 Reset状态下对ActMap事件的处理
boost::statechart::result PG::RecoveryState::Reset::react(const ActMap&)
{
PG *pg = context< RecoveryMachine >().pg;
if (pg->should_send_notify() && pg->get_primary().osd >= 0) {
context< RecoveryMachine >().send_notify(
pg->get_primary(),
pg_notify_t(
pg->get_primary().shard, pg->pg_whoami.shard,
pg->get_osdmap()->get_epoch(),
pg->get_osdmap()->get_epoch(),
pg->info),
pg->past_intervals);
}
pg->update_heartbeat_peers();
pg->take_waiters();
return transit< Started >();
}
void RecoveryMachine::send_notify(pg_shard_t to,const pg_notify_t &info, const pg_interval_map_t &pi) {
assert(state->rctx);
assert(state->rctx->notify_list);
(*state->rctx->notify_list)[to.osd].push_back(make_pair(info, pi));
}1)非Primary PG向Primary PG发送pg_notify_t请求
如果PG::should_send_notify()为true,且我们知道PG当前的主OSD是什么,就会调用RecoveryMachine::send_notify()来向主OSD发送pg_notify_t消息。
在PG::start_peering_interval()函数中:
void PG::start_peering_interval(
const OSDMapRef lastmap,
const vector<int>& newup, int new_up_primary,
const vector<int>& newacting, int new_acting_primary,
ObjectStore::Transaction *t)
{
// should we tell the primary we are here?
send_notify = !is_primary();
}从上面我们看到,对于非PG Primary(包括PG Replicas、PG Strays),其都会将send_notify置为true。
2)PG的状态由Reset状态转到Started状态
2.2 进入Started状态
struct Started : boost::statechart::state< Started, RecoveryMachine, Start >, NamedState {
};上面看到,Started的默认初始子状态为Start状态,因此这里会马上进入Start状态。
2.3 进入Start状态
struct Start : boost::statechart::state< Start, Started >, NamedState {
explicit Start(my_context ctx);
void exit();
typedef boost::mpl::list <
boost::statechart::transition< MakePrimary, Primary >,
boost::statechart::transition< MakeStray, Stray >
> reactions;
};
PG::RecoveryState::Start::Start(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Start")
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
if (pg->is_primary()) {
dout(1) << "transitioning to Primary" << dendl;
post_event(MakePrimary());
} else { //is_stray
dout(1) << "transitioning to Stray" << dendl;
post_event(MakeStray());
}
}从上面我们看到,对于PG Primary来说产生MakePrimary事件,进入Primary状态;否则产生MakeStray事件,进入Stray状态。
到此,PG对相应事件的处理就明显分为不同的路径:
-
Primary路径
-
Stray路径
这里因为PG Primary主导整个Peering过程,因此我们先从Primary路径开始讲起。对于Stray路径,我们后面会讲解到。
2.4 进入Primary状态
struct Primary : boost::statechart::state< Primary, Started, Peering >, NamedState {
explicit Primary(my_context ctx);
void exit();
typedef boost::mpl::list <
boost::statechart::custom_reaction< ActMap >,
boost::statechart::custom_reaction< MNotifyRec >,
boost::statechart::transition< NeedActingChange, WaitActingChange >
> reactions;
boost::statechart::result react(const ActMap&);
boost::statechart::result react(const MNotifyRec&);
};
PG::RecoveryState::Primary::Primary(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary")
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
assert(pg->want_acting.empty());
// set CREATING bit until we have peered for the first time.
if (pg->info.history.last_epoch_started == 0) {
pg->state_set(PG_STATE_CREATING);
// use the history timestamp, which ultimately comes from the
// monitor in the create case.
utime_t t = pg->info.history.last_scrub_stamp;
pg->info.stats.last_fresh = t;
pg->info.stats.last_active = t;
pg->info.stats.last_change = t;
pg->info.stats.last_peered = t;
pg->info.stats.last_clean = t;
pg->info.stats.last_unstale = t;
pg->info.stats.last_undegraded = t;
pg->info.stats.last_fullsized = t;
pg->info.stats.last_scrub_stamp = t;
pg->info.stats.last_deep_scrub_stamp = t;
pg->info.stats.last_clean_scrub_stamp = t;
}
}Primary的默认初始子状态为Peering,因此我们这里会马上进入到Peering状态。
2.5 进入Peering状态
struct Peering : boost::statechart::state< Peering, Primary, GetInfo >, NamedState {
std::unique_ptr< PriorSet > prior_set;
bool history_les_bound; //< need osd_find_best_info_ignore_history_les
explicit Peering(my_context ctx);
void exit();
typedef boost::mpl::list <
boost::statechart::custom_reaction< QueryState >,
boost::statechart::transition< Activate, Active >,
boost::statechart::custom_reaction< AdvMap >
> reactions;
boost::statechart::result react(const QueryState& q);
boost::statechart::result react(const AdvMap &advmap);
};
PG::RecoveryState::Peering::Peering(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Peering"),
history_les_bound(false)
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
assert(!pg->is_peered());
assert(!pg->is_peering());
assert(pg->is_primary());
pg->state_set(PG_STATE_PEERING);
}Peering的默认初始子状态为GetInfo状态,因此这里会马上进入GetInfo状态。
3. Peering状态详细处理
我们接着上面,对于PG Primary进入Peering状态后,马上进入Peering的默认初始子状态GetInfo。下图是Peering过程的一个整体状态转换图:
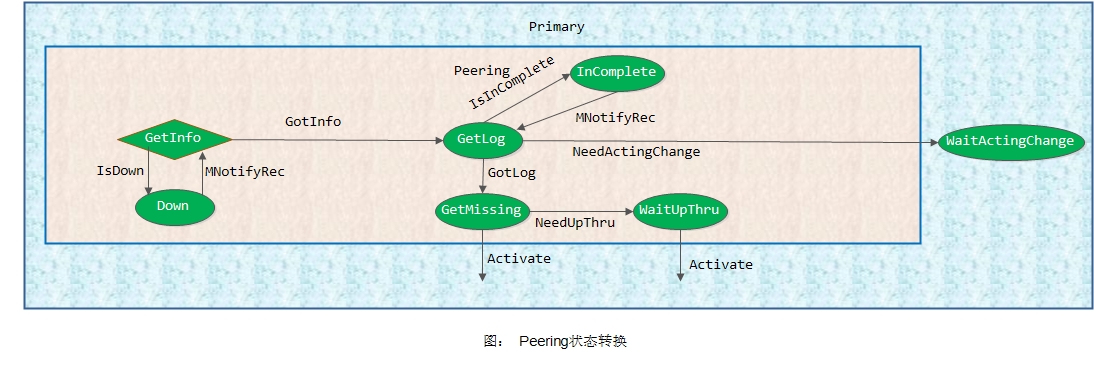
现在我们从GetInfo状态开始讲起。
3.1 GetInfo状态
struct GetInfo : boost::statechart::state< GetInfo, Peering >, NamedState {
set<pg_shard_t> peer_info_requested;
explicit GetInfo(my_context ctx);
void exit();
void get_infos();
typedef boost::mpl::list <
boost::statechart::custom_reaction< QueryState >,
boost::statechart::transition< GotInfo, GetLog >,
boost::statechart::custom_reaction< MNotifyRec >
> reactions;
boost::statechart::result react(const QueryState& q);
boost::statechart::result react(const MNotifyRec& infoevt);
};
PG::RecoveryState::GetInfo::GetInfo(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Peering/GetInfo")
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
pg->generate_past_intervals();
unique_ptr<PriorSet> &prior_set = context< Peering >().prior_set;
assert(pg->blocked_by.empty());
if (!prior_set.get())
pg->build_prior(prior_set);
pg->reset_min_peer_features();
get_infos();
if (peer_info_requested.empty() && !prior_set->pg_down) {
post_event(GotInfo());
}
}在GetInfo构造函数中,首先调用PG::generate_past_intervals()产生past_intervals,之后调用PG::build_prior()来生成Recovery过程中所需要依赖的OSD列表。
之后调用get_infos()来获取PG各副本的pg info信息。我们来看该函数实现。
3.1.1 获取PG各副本pg info信息
void PG::RecoveryState::GetInfo::get_infos()
{
PG *pg = context< RecoveryMachine >().pg;
unique_ptr<PriorSet> &prior_set = context< Peering >().prior_set;
pg->blocked_by.clear();
for (set<pg_shard_t>::const_iterator it = prior_set->probe.begin();it != prior_set->probe.end();++it) {
pg_shard_t peer = *it;
if (peer == pg->pg_whoami) {
continue;
}
if (pg->peer_info.count(peer)) {
dout(10) << " have osd." << peer << " info " << pg->peer_info[peer] << dendl;
continue;
}
if (peer_info_requested.count(peer)) {
dout(10) << " already requested info from osd." << peer << dendl;
pg->blocked_by.insert(peer.osd);
} else if (!pg->get_osdmap()->is_up(peer.osd)) {
dout(10) << " not querying info from down osd." << peer << dendl;
} else {
dout(10) << " querying info from osd." << peer << dendl;
context< RecoveryMachine >().send_query(
peer, pg_query_t(pg_query_t::INFO,
it->shard, pg->pg_whoami.shard,
pg->info.history,
pg->get_osdmap()->get_epoch()));
peer_info_requested.insert(peer);
pg->blocked_by.insert(peer.osd);
}
}
pg->publish_stats_to_osd();
}1)清理PG::blocked_by
PG::blocked_by用于记录当前PG被哪些OSD所阻塞,这样在执行pg stats时我们就知道这些阻塞信息。一般在一个状态退出,就会将其进行清理。比如在GetInfo状态退出时,就有如下:
void PG::RecoveryState::GetInfo::exit()
{
context< RecoveryMachine >().log_exit(state_name, enter_time);
PG *pg = context< RecoveryMachine >().pg;
utime_t dur = ceph_clock_now(pg->cct) - enter_time;
pg->osd->recoverystate_perf->tinc(rs_getinfo_latency, dur);
pg->blocked_by.clear();
}2) 向相应的Peer发送pg_query_t查询请求
我们在GetInfo构造函数中创建了PriorSet,其中就告诉了我们需要向哪些OSD发送查询信息。这里遍历PriorSet,向当前仍处于Up状态的OSD发送pg_query_t查询请求。
3.1.2 重要提醒
到目前为止,在OSD::advance_pg()中所触发的AdvMap以及ActMap事件就已经处理完成。接下来就是接受Peer返回过来的pg info信息了。
3.1.3 接收Peer返回过来的pg info信息
这里我们先大概给出一张PG Primary发送pg_query_t查询请求,然后Peer返回响应的一个大体流程图:
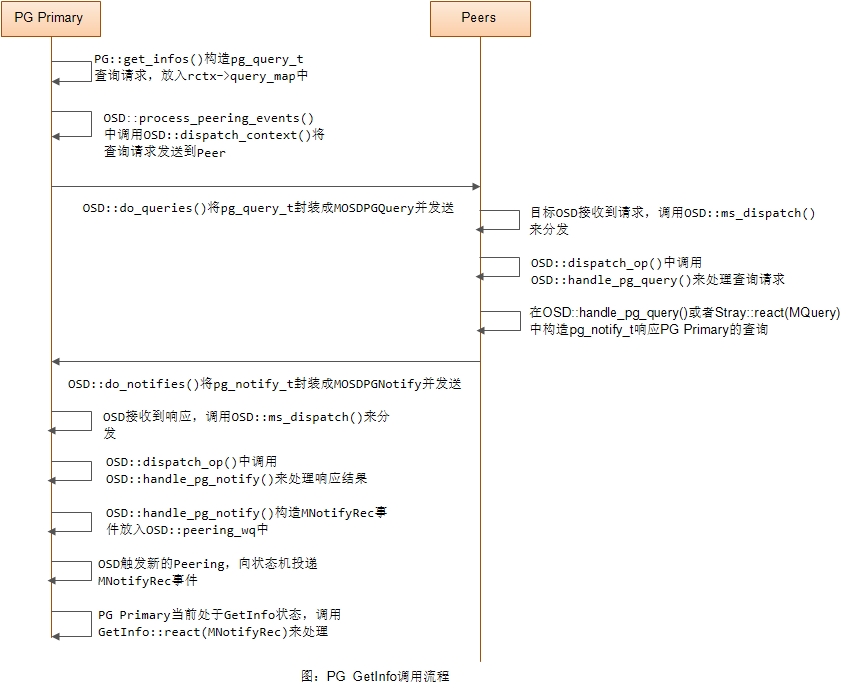
MNotifyRec数据结构
这里我们先来看一下查询pg_info的响应的数据结构:
struct MNotifyRec : boost::statechart::event< MNotifyRec > {
pg_shard_t from;
pg_notify_t notify;
uint64_t features;
MNotifyRec(pg_shard_t from, pg_notify_t ¬ify, uint64_t f) :
from(from), notify(notify), features(f) {}
void print(std::ostream *out) const {
*out << "MNotifyRec from " << from << " notify: " << notify<< " features: 0x" << hex << features << dec;
}
};
struct pg_notify_t {
epoch_t query_epoch; //查询时请求消息的epoch
epoch_t epoch_sent; //发送时响应消息的epoch
pg_info_t info; //pg_info的信息
shard_id_t to; //目标OSD
shard_id_t from; //源OSD
};GetInfo状态下对MNotifyRec事件的处理
因为我们实在GetInfo状态下发送的pg_info查询请求,假设没有新的Peering事件触发状态改变的话,我们会使用GetInfo::react(MNotifyRec)函数来处理。在讲解该函数之前,我们先来看一下PG::proc_replica_info()函数:
bool PG::proc_replica_info(
pg_shard_t from, const pg_info_t &oinfo, epoch_t send_epoch)
{
map<pg_shard_t, pg_info_t>::iterator p = peer_info.find(from);
if (p != peer_info.end() && p->second.last_update == oinfo.last_update) {
dout(10) << " got dup osd." << from << " info " << oinfo << ", identical to ours" << dendl;
return false;
}
if (!get_osdmap()->has_been_up_since(from.osd, send_epoch)) {
dout(10) << " got info " << oinfo << " from down osd." << from<< " discarding" << dendl;
return false;
}
dout(10) << " got osd." << from << " " << oinfo << dendl;
assert(is_primary());
peer_info[from] = oinfo;
might_have_unfound.insert(from);
unreg_next_scrub();
if (info.history.merge(oinfo.history))
dirty_info = true;
reg_next_scrub();
// stray?
if (!is_up(from) && !is_acting(from)) {
dout(10) << " osd." << from << " has stray content: " << oinfo << dendl;
stray_set.insert(from);
if (is_clean()) {
purge_strays();
}
}
// was this a new info? if so, update peers!
if (p == peer_info.end())
update_heartbeat_peers();
return true;
}
bool pg_history_t::merge(const pg_history_t &other) {
// Here, we only update the fields which cannot be calculated from the OSDmap.
bool modified = false;
if (epoch_created < other.epoch_created) {
epoch_created = other.epoch_created;
modified = true;
}
if (last_epoch_started < other.last_epoch_started) {
last_epoch_started = other.last_epoch_started;
modified = true;
}
if (last_epoch_clean < other.last_epoch_clean) {
last_epoch_clean = other.last_epoch_clean;
modified = true;
}
if (last_epoch_split < other.last_epoch_split) {
last_epoch_split = other.last_epoch_split;
modified = true;
}
if (last_epoch_marked_full < other.last_epoch_marked_full) {
last_epoch_marked_full = other.last_epoch_marked_full;
modified = true;
}
if (other.last_scrub > last_scrub) {
last_scrub = other.last_scrub;
modified = true;
}
if (other.last_scrub_stamp > last_scrub_stamp) {
last_scrub_stamp = other.last_scrub_stamp;
modified = true;
}
if (other.last_deep_scrub > last_deep_scrub) {
last_deep_scrub = other.last_deep_scrub;
modified = true;
}
if (other.last_deep_scrub_stamp > last_deep_scrub_stamp) {
last_deep_scrub_stamp = other.last_deep_scrub_stamp;
modified = true;
}
if (other.last_clean_scrub_stamp > last_clean_scrub_stamp) {
last_clean_scrub_stamp = other.last_clean_scrub_stamp;
modified = true;
}
return modified;
}
void PG::update_heartbeat_peers()
{
assert(is_locked());
if (!is_primary())
return;
set<int> new_peers;
for (unsigned i=0; i<acting.size(); i++) {
if (acting[i] != CRUSH_ITEM_NONE)
new_peers.insert(acting[i]);
}
for (unsigned i=0; i<up.size(); i++) {
if (up[i] != CRUSH_ITEM_NONE)
new_peers.insert(up[i]);
}
for (map<pg_shard_t,pg_info_t>::iterator p = peer_info.begin();p != peer_info.end();++p)
new_peers.insert(p->first.osd);
bool need_update = false;
heartbeat_peer_lock.Lock();
if (new_peers == heartbeat_peers) {
dout(10) << "update_heartbeat_peers " << heartbeat_peers << " unchanged" << dendl;
} else {
dout(10) << "update_heartbeat_peers " << heartbeat_peers << " -> " << new_peers << dendl;
heartbeat_peers.swap(new_peers);
need_update = true;
}
heartbeat_peer_lock.Unlock();
if (need_update)
osd->need_heartbeat_peer_update();
}1) 首先检查如果该OSD的pg_info信息已经存在,并且last_update参数相同,则说明已经处理过,返回false。
2) 调用函数OSDMap::has_been_up_since()检查该OSD在send_epoch时已经处于up状态
3) 确保自己是主OSD,把从from返回来的pg_info信息保存到peer_info数组,并加入might_have_unfound数组里
注:PG::might_have_unfound数组里的OSD可能存放了PG的一些对象,我们后续需要利用这些OSD来进行数据恢复
4) 调用函数unreg_next_scrub()使该PG不在scrub操作的队列里
5) 调用info.history.merge()函数处理副本OSD发送过来的pg_info信息。处理的方法是:更新为最新的字段。
6) 调用函数reg_next_scrub()注册PG下一次scrub的时间
7) 如果该OSD既不在up数组中也不在acting数组中,那就加入stray_set列表中。当PG处于clean状态时,就会调用purge_strays()函数删除stray状态的PG及其上的对象数据。
8) 如果是一个新的OSD,就调用函数update_heartbeat_peers()更新需要heartbeat的OSD列表
接下来我们看GetInfo状态下对MNotifyRec事件的处理:
boost::statechart::result PG::RecoveryState::GetInfo::react(const MNotifyRec& infoevt)
{
PG *pg = context< RecoveryMachine >().pg;
set<pg_shard_t>::iterator p = peer_info_requested.find(infoevt.from);
if (p != peer_info_requested.end()) {
peer_info_requested.erase(p);
pg->blocked_by.erase(infoevt.from.osd);
}
epoch_t old_start = pg->info.history.last_epoch_started;
if (pg->proc_replica_info(infoevt.from, infoevt.notify.info, infoevt.notify.epoch_sent)) {
// we got something new ...
unique_ptr<PriorSet> &prior_set = context< Peering >().prior_set;
if (old_start < pg->info.history.last_epoch_started) {
dout(10) << " last_epoch_started moved forward, rebuilding prior" << dendl;
pg->build_prior(prior_set);
// filter out any osds that got dropped from the probe set from
// peer_info_requested. this is less expensive than restarting
// peering (which would re-probe everyone).
set<pg_shard_t>::iterator p = peer_info_requested.begin();
while (p != peer_info_requested.end()) {
if (prior_set->probe.count(*p) == 0) {
dout(20) << " dropping osd." << *p << " from info_requested, no longer in probe set" << dendl;
peer_info_requested.erase(p++);
} else {
++p;
}
}
get_infos();
}
dout(20) << "Adding osd: " << infoevt.from.osd << " peer features: "<< hex << infoevt.features << dec << dendl;
pg->apply_peer_features(infoevt.features);
// are we done getting everything?
if (peer_info_requested.empty() && !prior_set->pg_down) {
/*
* make sure we have at least one !incomplete() osd from the
* last rw interval. the incomplete (backfilling) replicas
* get a copy of the log, but they don't get all the object
* updates, so they are insufficient to recover changes during
* that interval.
*/
if (pg->info.history.last_epoch_started) {
for (map<epoch_t,pg_interval_t>::reverse_iterator p = pg->past_intervals.rbegin();p != pg->past_intervals.rend();++p) {
if (p->first < pg->info.history.last_epoch_started)
break;
if (!p->second.maybe_went_rw)
continue;
pg_interval_t& interval = p->second;
dout(10) << " last maybe_went_rw interval was " << interval << dendl;
OSDMapRef osdmap = pg->get_osdmap();
/*
* this mirrors the PriorSet calculation: we wait if we
* don't have an up (AND !incomplete) node AND there are
* nodes down that might be usable.
*/
bool any_up_complete_now = false;
bool any_down_now = false;
for (unsigned i=0; i<interval.acting.size(); i++) {
int o = interval.acting[i];
if (o == CRUSH_ITEM_NONE)
continue;
pg_shard_t so(o, pg->pool.info.ec_pool() ? shard_id_t(i) : shard_id_t::NO_SHARD);
if (!osdmap->exists(o) || osdmap->get_info(o).lost_at > interval.first)
continue; // dne or lost
if (osdmap->is_up(o)) {
pg_info_t *pinfo;
if (so == pg->pg_whoami) {
pinfo = &pg->info;
} else {
assert(pg->peer_info.count(so));
pinfo = &pg->peer_info[so];
}
if (!pinfo->is_incomplete())
any_up_complete_now = true;
} else {
any_down_now = true;
}
}
if (!any_up_complete_now && any_down_now) {
dout(10) << " no osds up+complete from interval " << interval << dendl;
pg->state_set(PG_STATE_DOWN);
pg->publish_stats_to_osd();
return discard_event();
}
break;
}
}
dout(20) << "Common peer features: " << hex << pg->get_min_peer_features() << dec << dendl;
dout(20) << "Common acting features: " << hex << pg->get_min_acting_features() << dec << dendl;
dout(20) << "Common upacting features: " << hex << pg->get_min_upacting_features() << dec << dendl;
post_event(GotInfo());
}
}
return discard_event();
}下面我们来看具体的处理过程:
1)首先从peer_info_requested里删除该peer,同时从blocked_by队列里删除
2)调用函数PG::proc_replica_info()来处理副本的pg_info信息。如果获取到了一个新的有效的pg_info,则PG::proc_replica_info()返回true,继续下面的步骤3);否则丢弃该事件
3)在变量old_start里保存了调用PG::proc_replica_info()前主OSD的pg->info.history.last_epoch_started,如果该epoch值小于合并后的值,说明该值被更新了,副本OSD上的epoch值比较新,需要进行如下操作:
a) 调用PG::build_prior()重新构建prior_set对象
b) 从peer_info_requested队列中去掉上次构建的prior_set中存在的OSD,这里最新构建上次不存在的OSD列表;
c) 调用get_infos()函数重新发送查询peer_info请求
4)调用pg->apply_peer_features()更新相关的features值
5) 当peer_info_requested队列为空,并且prior_set不处于pg_down状态时,说明收到所有OSD的peer_info并处理完成
6)之后检查past_interval阶段至少有一个OSD处于up状态且非incomplete状态;否则该PG无法恢复,标记状态为PG_STATE_DOWN并直接返回。如下图所示:
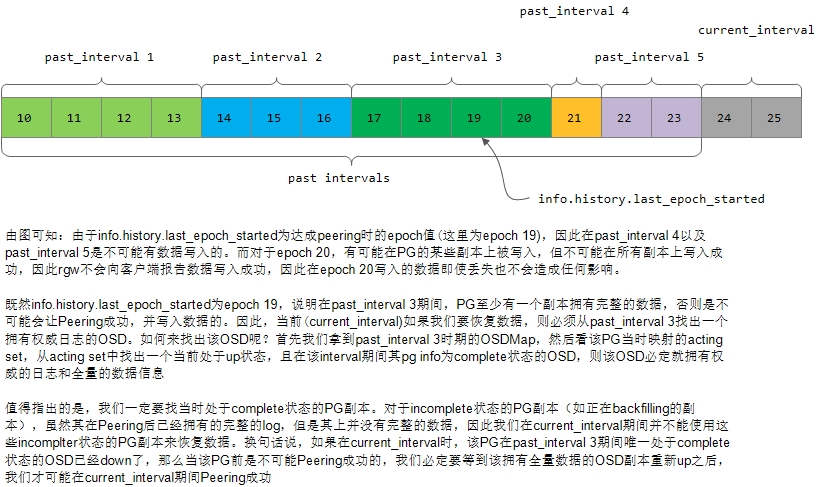
7)最后完成处理,调用函数post_event(GotInfo())抛出GotInfo事件进入状态机的下一个状态。
在GetInfo状态里直接定义了当前状态接收到GotInfo事件后,直接跳转到下一个状态GetLog里:
struct GetInfo : boost::statechart::state< GetInfo, Peering >, NamedState {
set<pg_shard_t> peer_info_requested;
explicit GetInfo(my_context ctx);
void exit();
void get_infos();
typedef boost::mpl::list <
boost::statechart::custom_reaction< QueryState >,
boost::statechart::transition< GotInfo, GetLog >,
boost::statechart::custom_reaction< MNotifyRec >
> reactions;
boost::statechart::result react(const QueryState& q);
boost::statechart::result react(const MNotifyRec& infoevt);
};
[参看]
