ceph peering机制再研究(7)
我们在上一章讲述到在GetInfo状态下抛出GotInfo事件,会直接跳转到GetLog阶段。本章我们就从GetLog开始,继续讲述Ceph的Peering过程。
1. PG::choose_acting()的实现
在具体讲解GetLog阶段之前,我们先讲述PG::choose_acting()函数的实现。这是一个比较重要但却比较复杂的函数,其主要实现如下功能:
-
选出具有权威日志的OSD
-
计算PG::actingbackfill和PG::backfill_targets两个OSD列表
注:actingbackfill保存了当前PG的acting列表,包括需要进行backfill操作的OSD列表;backfill_targets列表保存了需要进行backfill的OSD列表
下面我们来看PG::choose_acting()的大体实现:
/**
* choose acting
*
* calculate the desired acting, and request a change with the monitor
* if it differs from the current acting.
*
* if restrict_to_up_acting=true, we filter out anything that's not in
* up/acting. in order to lift this restriction, we need to
* 1) check whether it's worth switching the acting set any time we get
* a new pg info (not just here, when recovery finishes)
* 2) check whether anything in want_acting went down on each new map
* (and, if so, calculate a new want_acting)
* 3) remove the assertion in PG::RecoveryState::Active::react(const AdvMap)
* TODO!
*/
bool PG::choose_acting(pg_shard_t &auth_log_shard_id,
bool restrict_to_up_acting,
bool *history_les_bound)
{
//1) 调用PG::find_best_info()选取权威日志
//1.1) 如若选取权威日志失败,返回false,之后PG进入InComplete状态
//1.2) 选取权威日志成功,继续执行后面操作
//2) 根据当前的权威日志,调用PG::calc_replicated_acting()计算出acting set(包括want/want_backfill/want_acting_backfill/want_primary)
//(注:up set只是根据osdmap计算出来的,而acting set是真正负责数据读写的,在异常情况发生时,这两个会不相同)
//3) 根据上面计算出的want,分不同情况进行处理
// 3.1) 如若want中OSD数量小于pool.min_size,将PG::want_acting置空,返回false,进入InComplete状态
// 3.2) 调用get_pgbackend()->get_is_recoverable_predicate()判断当前PG是否可以恢复,如果不能进行恢复,将PG::want_acting置空,
// 返回false,进入InComplete状态
// 如下均为可恢复状态
// 3.3) 判断want与acting是否相等,如果不相等,则需要申请pg_temp
// 3.3) 计算backfill_targets
}这里我们对PG::want_acting进行一个简单的说明:其主要用于临时保存我们所期望获取到的acting set。
下面我们按照上面的三个步骤讲述其中过程。
1.1 查找权威日志
/**
* find_best_info
*
* Returns an iterator to the best info in infos sorted by:
* 1) Prefer newer last_update
* 2) Prefer longer tail if it brings another info into contiguity
* 3) Prefer current primary
*/
map<pg_shard_t, pg_info_t>::const_iterator PG::find_best_info(
const map<pg_shard_t, pg_info_t> &infos,
bool restrict_to_up_acting,
bool *history_les_bound) const
{
assert(history_les_bound);
/* See doc/dev/osd_internals/last_epoch_started.rst before attempting
* to make changes to this process. Also, make sure to update it
* when you find bugs! */
eversion_t min_last_update_acceptable = eversion_t::max();
epoch_t max_last_epoch_started_found = 0;
for (map<pg_shard_t, pg_info_t>::const_iterator i = infos.begin();i != infos.end();++i) {
if (!cct->_conf->osd_find_best_info_ignore_history_les &&max_last_epoch_started_found < i->second.history.last_epoch_started) {
*history_les_bound = true;
max_last_epoch_started_found = i->second.history.last_epoch_started;
}
if (!i->second.is_incomplete() && max_last_epoch_started_found < i->second.last_epoch_started) {
max_last_epoch_started_found = i->second.last_epoch_started;
}
}
for (map<pg_shard_t, pg_info_t>::const_iterator i = infos.begin();i != infos.end();++i) {
if (max_last_epoch_started_found <= i->second.last_epoch_started) {
if (min_last_update_acceptable > i->second.last_update)
min_last_update_acceptable = i->second.last_update;
}
}
if (min_last_update_acceptable == eversion_t::max())
return infos.end();
map<pg_shard_t, pg_info_t>::const_iterator best = infos.end();
// find osd with newest last_update (oldest for ec_pool).
// if there are multiples, prefer
// - a longer tail, if it brings another peer into log contiguity
// - the current primary
for (map<pg_shard_t, pg_info_t>::const_iterator p = infos.begin();p != infos.end();++p) {
if (restrict_to_up_acting && !is_up(p->first) &&!is_acting(p->first))
continue;
// Only consider peers with last_update >= min_last_update_acceptable
if (p->second.last_update < min_last_update_acceptable)
continue;
// disqualify anyone with a too old last_epoch_started
if (p->second.last_epoch_started < max_last_epoch_started_found)
continue;
// Disquality anyone who is incomplete (not fully backfilled)
if (p->second.is_incomplete())
continue;
if (best == infos.end()) {
best = p;
continue;
}
// Prefer newer last_update
if (pool.info.require_rollback()) {
if (p->second.last_update > best->second.last_update)
continue;
if (p->second.last_update < best->second.last_update) {
best = p;
continue;
}
} else {
if (p->second.last_update < best->second.last_update)
continue;
if (p->second.last_update > best->second.last_update) {
best = p;
continue;
}
}
// Prefer longer tail
if (p->second.log_tail > best->second.log_tail) {
continue;
} else if (p->second.log_tail < best->second.log_tail) {
best = p;
continue;
}
// prefer current primary (usually the caller), all things being equal
if (p->first == pg_whoami) {
dout(10) << "calc_acting prefer osd." << p->first<< " because it is current primary" << dendl;
best = p;
continue;
}
}
return best;
}函数find_best_info()用于选取一个拥有权威日志的OSD。根据last_epoch_clean到目前为止,各个past interval期间参与该PG的所有目前还处于up状态的OSD上的pg_info_t信息,来选择一个拥有权威日志的OSD,选择的有限顺序如下:
1) 具有最新的last_update的OSD;
2) 如果条件1相同,选择日志更长的OSD;
3) 如果1,2条件都相同,选择当前的主OSD;
下面我们来看代码的具体实现过程:
1) 首先在所有OSD中计算max_last_epoch_started,然后在拥有最大的last_epoch_started的OSD中计算min_last_update_acceptable的值;
注:min_last_update_acceptable表示我们可以接受的最小的last_update值
2) 如果min_last_update_acceptable为eversion_t::max(),返回infos.end(),选取失败;
3) 根据以下条件选择一个OSD:
a) 首先过滤掉last_update小于min_last_update_acceptable,或者last_epoch_started小于max_last_epoch_started_found,或者处于incomplete的OSD;
b) 如果PG是EC类型,选择最小的last_update;如果PG类型是副本,选择最大的last_update的OSD;
c) 如果上述条件都相同,选择log tail最小的,也就是日志最长的OSD;
d) 如果上述条件都相同,选择当前的主OSD;
综上的选择过程可知,拥有权威日志的OSD特征如下:必须是非incomplete的OSD;必须有最大的last_epoch_started;last_update有可能是最大,但至少是min_last_update_acceptable;有可能是最长的OSD;有可能是主OSD。
1.2 计算PG的acting列表
/**
* calculate the desired acting set.
*
* Choose an appropriate acting set. Prefer up[0], unless it is
* incomplete, or another osd has a longer tail that allows us to
* bring other up nodes up to date.
*/
void PG::calc_replicated_acting(
map<pg_shard_t, pg_info_t>::const_iterator auth_log_shard,
unsigned size,
const vector<int> &acting,
pg_shard_t acting_primary,
const vector<int> &up,
pg_shard_t up_primary,
const map<pg_shard_t, pg_info_t> &all_info,
bool compat_mode,
bool restrict_to_up_acting,
vector<int> *want,
set<pg_shard_t> *backfill,
set<pg_shard_t> *acting_backfill,
pg_shard_t *want_primary,
ostream &ss)
{
ss << "calc_acting newest update on osd." << auth_log_shard->first<< " with " << auth_log_shard->second
<< (restrict_to_up_acting ? " restrict_to_up_acting" : "") << std::endl;
pg_shard_t auth_log_shard_id = auth_log_shard->first;
// select primary
map<pg_shard_t,pg_info_t>::const_iterator primary;
if (up.size() &&!all_info.find(up_primary)->second.is_incomplete() &&
all_info.find(up_primary)->second.last_update >=auth_log_shard->second.log_tail) {
ss << "up_primary: " << up_primary << ") selected as primary" << std::endl;
primary = all_info.find(up_primary); // prefer up[0], all thing being equal
} else {
assert(!auth_log_shard->second.is_incomplete());
ss << "up[0] needs backfill, osd." << auth_log_shard_id<< " selected as primary instead" << std::endl;
primary = auth_log_shard;
}
ss << "calc_acting primary is osd." << primary->first<< " with " << primary->second << std::endl;
*want_primary = primary->first;
want->push_back(primary->first.osd);
acting_backfill->insert(primary->first);
unsigned usable = 1;
// select replicas that have log contiguity with primary.
// prefer up, then acting, then any peer_info osds
for (vector<int>::const_iterator i = up.begin();i != up.end();++i) {
pg_shard_t up_cand = pg_shard_t(*i, shard_id_t::NO_SHARD);
if (up_cand == primary->first)
continue;
const pg_info_t &cur_info = all_info.find(up_cand)->second;
if (cur_info.is_incomplete() ||
cur_info.last_update < MIN(primary->second.log_tail,auth_log_shard->second.log_tail)) {
/* We include auth_log_shard->second.log_tail because in GetLog,
* we will request logs back to the min last_update over our
* acting_backfill set, which will result in our log being extended
* as far backwards as necessary to pick up any peers which can
* be log recovered by auth_log_shard's log */
ss << " shard " << up_cand << " (up) backfill " << cur_info << std::endl;
if (compat_mode) {
if (backfill->empty()) {
backfill->insert(up_cand);
want->push_back(*i);
acting_backfill->insert(up_cand);
}
} else {
backfill->insert(up_cand);
acting_backfill->insert(up_cand);
}
} else {
want->push_back(*i);
acting_backfill->insert(up_cand);
usable++;
ss << " osd." << *i << " (up) accepted " << cur_info << std::endl;
}
}
// This no longer has backfill OSDs, but they are covered above.
for (vector<int>::const_iterator i = acting.begin();i != acting.end();++i) {
pg_shard_t acting_cand(*i, shard_id_t::NO_SHARD);
if (usable >= size)
break;
// skip up osds we already considered above
if (acting_cand == primary->first)
continue;
vector<int>::const_iterator up_it = find(up.begin(), up.end(), acting_cand.osd);
if (up_it != up.end())
continue;
const pg_info_t &cur_info = all_info.find(acting_cand)->second;
if (cur_info.is_incomplete() ||cur_info.last_update < primary->second.log_tail) {
ss << " shard " << acting_cand << " (stray) REJECTED "<< cur_info << std::endl;
} else {
want->push_back(*i);
acting_backfill->insert(acting_cand);
ss << " shard " << acting_cand << " (stray) accepted "<< cur_info << std::endl;
usable++;
}
}
if (restrict_to_up_acting) {
return;
}
for (map<pg_shard_t,pg_info_t>::const_iterator i = all_info.begin();i != all_info.end();++i) {
if (usable >= size)
break;
// skip up osds we already considered above
if (i->first == primary->first)
continue;
vector<int>::const_iterator up_it = find(up.begin(), up.end(), i->first.osd);
if (up_it != up.end())
continue;
vector<int>::const_iterator acting_it = find(acting.begin(), acting.end(), i->first.osd);
if (acting_it != acting.end())
continue;
if (i->second.is_incomplete() ||i->second.last_update < primary->second.log_tail) {
ss << " shard " << i->first << " (stray) REJECTED "<< i->second << std::endl;
} else {
want->push_back(i->first.osd);
acting_backfill->insert(i->first);
ss << " shard " << i->first << " (stray) accepted "<< i->second << std::endl;
usable++;
}
}
}本函数计算PG相关的下列OSD列表:
-
want: PG所期望的acting列表
-
backfill: 需要进行backfill的OSD;
-
acting_backfill: 与want的OSD列表相同,只不过这里是pg_shard_t类型
-
want_primary: 所期望的acting set的primary OSD
具体处理过程如下:
1) 首先选择want列表中的primary OSD
a) 如果up_primary处于非incomplete状态,并且其last_update大于等于权威日志的log_tail,说明up_primary的日志和权威日志有重叠,可以通过日志记录恢复,优先选择up_primary为主OSD;
b) 否则选择auth_log_shard,也就是拥有权威日志的OSD为主OSD;
c) 把want_primary加入到want以及acting_backfill列表中;
2) 函数的输入参数size为要选择的副本数,依次从up、acting、all_info里选择size各副本OSD:
a) 如果该OSD上的PG处于incomplete状态,或者cur_info.last_update小于MIN(primary->second.log_tail,auth_log_shard->second.log_tail),则该PG副本无法通过日志修复,只能通过Backfill操作来修复。把该OSD加入backfill和acting_backfill集合中;
b) 否则就可以根据PG日志来修复,只加入acting_backfill和want集合中,不用加入到backfill列表中;
1.3 choose_acting()实现详解
我们在上面介绍了:
-
PG::find_best_info()查找权威日志
-
PG::calc_replicated_acting()计算期望的acting集合
下面我们来详细介绍以下PG::choose_acting()的实现:
bool PG::choose_acting(pg_shard_t &auth_log_shard_id,
bool restrict_to_up_acting,
bool *history_les_bound)
{
map<pg_shard_t, pg_info_t> all_info(peer_info.begin(), peer_info.end());
all_info[pg_whoami] = info;
for (map<pg_shard_t, pg_info_t>::iterator p = all_info.begin();p != all_info.end();++p) {
dout(10) << "calc_acting osd." << p->first << " " << p->second << dendl;
}
map<pg_shard_t, pg_info_t>::const_iterator auth_log_shard = find_best_info(all_info, restrict_to_up_acting, history_les_bound);
if (auth_log_shard == all_info.end()) {
if (up != acting) {
dout(10) << "choose_acting no suitable info found (incomplete backfills?),"<< " reverting to up" << dendl;
want_acting = up;
vector<int> empty;
osd->queue_want_pg_temp(info.pgid.pgid, empty);
} else {
dout(10) << "choose_acting failed" << dendl;
assert(want_acting.empty());
}
return false;
}
assert(!auth_log_shard->second.is_incomplete());
auth_log_shard_id = auth_log_shard->first;
// Determine if compatibility needed
bool compat_mode = !cct->_conf->osd_debug_override_acting_compat;
if (compat_mode) {
bool all_support = true;
OSDMapRef osdmap = get_osdmap();
for (map<pg_shard_t, pg_info_t>::iterator it = all_info.begin();it != all_info.end();++it) {
pg_shard_t peer = it->first;
const osd_xinfo_t& xi = osdmap->get_xinfo(peer.osd);
if (!(xi.features & CEPH_FEATURE_OSD_ERASURE_CODES)) {
all_support = false;
break;
}
}
if (all_support)
compat_mode = false;
}
set<pg_shard_t> want_backfill, want_acting_backfill;
vector<int> want;
pg_shard_t want_primary;
stringstream ss;
if (!pool.info.ec_pool())
calc_replicated_acting(
auth_log_shard,
get_osdmap()->get_pg_size(info.pgid.pgid),
acting,
primary,
up,
up_primary,
all_info,
compat_mode,
restrict_to_up_acting,
&want,
&want_backfill,
&want_acting_backfill,
&want_primary,
ss);
else
calc_ec_acting(
auth_log_shard,
get_osdmap()->get_pg_size(info.pgid.pgid),
acting,
primary,
up,
up_primary,
all_info,
compat_mode,
restrict_to_up_acting,
&want,
&want_backfill,
&want_acting_backfill,
&want_primary,
ss);
dout(10) << ss.str() << dendl;
unsigned num_want_acting = 0;
for (vector<int>::iterator i = want.begin();i != want.end();++i) {
if (*i != CRUSH_ITEM_NONE)
++num_want_acting;
}
// We go incomplete if below min_size for ec_pools since backfill
// does not currently maintain rollbackability
// Otherwise, we will go "peered", but not "active"
if (num_want_acting < pool.info.min_size &&
(pool.info.ec_pool() ||!cct->_conf->osd_allow_recovery_below_min_size)) {
want_acting.clear();
dout(10) << "choose_acting failed, below min size" << dendl;
return false;
}
/* Check whether we have enough acting shards to later perform recovery */
boost::scoped_ptr<IsPGRecoverablePredicate> recoverable_predicate(get_pgbackend()->get_is_recoverable_predicate());
set<pg_shard_t> have;
for (int i = 0; i < (int)want.size(); ++i) {
if (want[i] != CRUSH_ITEM_NONE)
have.insert(pg_shard_t(want[i],pool.info.ec_pool() ? shard_id_t(i) : shard_id_t::NO_SHARD));
}
if (!(*recoverable_predicate)(have)) {
want_acting.clear();
dout(10) << "choose_acting failed, not recoverable" << dendl;
return false;
}
if (want != acting) {
dout(10) << "choose_acting want " << want << " != acting " << acting<< ", requesting pg_temp change" << dendl;
want_acting = want;
if (want_acting == up) {
// There can't be any pending backfill if
// want is the same as crush map up OSDs.
assert(compat_mode || want_backfill.empty());
vector<int> empty;
osd->queue_want_pg_temp(info.pgid.pgid, empty);
} else
osd->queue_want_pg_temp(info.pgid.pgid, want);
return false;
}
want_acting.clear();
actingbackfill = want_acting_backfill;
dout(10) << "actingbackfill is " << actingbackfill << dendl;
assert(backfill_targets.empty() || backfill_targets == want_backfill);
if (backfill_targets.empty()) {
// Caller is GetInfo
backfill_targets = want_backfill;
for (set<pg_shard_t>::iterator i = backfill_targets.begin();i != backfill_targets.end();++i) {
assert(!stray_set.count(*i));
}
} else {
// Will not change if already set because up would have had to change
assert(backfill_targets == want_backfill);
// Verify that nothing in backfill is in stray_set
for (set<pg_shard_t>::iterator i = want_backfill.begin();i != want_backfill.end();++i) {
assert(stray_set.find(*i) == stray_set.end());
}
}
dout(10) << "choose_acting want " << want << " (== acting) backfill_targets " << want_backfill << dendl;
return true;
}函数choose_acting()用来计算PG的acting_backfill和backfill_targets两个OSD列表。其中acting_backfill保存了当前PG的acting列表,包括需要进行backfill操作的OSD列表;backfill_targets列表保存了需要进行backfill操作的OSD列表。其处理过程如下:
1)首先构建all_info列表,然后调用PG::find_best_info()来选举出一个拥有权威日志的OSD,保存在变量auth_log_shard中;
2)如果没有选举出拥有权威日志的OSD,则进入如下流程:
a) 如果up不等于acting,将want_acting设置为up,申请取消pg_temp,返回false。(此种情况下会进入NeedActingChange状态)
b) 否则确保want_acting列表为空,返回false值;(此种情况下会进入InComplete状态)
3) 计算是否是compat_mode模式,检查是,如果所有的OSD都支持纠删码,就设置compat_mode值为false;
4) 根据PG的不同类型,调用不同的函数,对应ReplicatedPG调用函数PG::calc_replicated_acting()来计算PG需要的列表:
set<pg_shard_t> want_backfill, want_acting_backfill;
vector<int> want;
pg_shard_t want_primary;-
want_backfill: 该PG需要i女性backfill的pg_shard
-
want_acting_backfill: 包括进行acting和backfill的pg_shard
-
want: 在compat_mode下,和want_acting_backfill相同
-
want_primary: 所期望的主OSD
5) 下面就是对PG做一些检查:
a) 计算num_want_acting数量,检查如果小于min_size,进行如下操作:
* 如果对于EC,清空want_acting,返回false值;(注:此种情况下,PG会进入InComplete状态)
* 对于ReplicatedPG,如果该PG不允许小于min_size的恢复,清空want_acting,返回false;(注:此种情况下,PG会进入InComplete状态)
b) 调用IsPGRecoverablePredicate来判断PG现有的OSD列表是否可以恢复,如果不能恢复,情况want_acting,返回false值;(注:此种情况下,PG会进入InComplete状态)
6) 检查如果当前want不等于acting,设置want_acting为want:
a) 如果want_acting等于up,申请empty为pg_temp的OSD列表,返回false;(注:此种情况下会进入NeedActingChange状态)
b) 否则申请want为pg_temp的OSD列表;(注:此种情况下PG会进入NeedActingChange状态)
7) 最后设置PG的actingbackfill为want_acting_backfill,设置backfill_targets为want_backfill,并检查backfill_targets里的pg_shard应该不在stray_set里面;
8) 最终返回true值;
下面我们举例说明需要申请pg_temp的场景:
1) 当前PG1.0,其acting列表和up列表都为[0,1,2],PG处于clean状态;
2) 此时,osd0崩溃,导致该PG经过CRUSH算法重新获得acting和up列表都为[3,1,2];
3) 选择出拥有权威日志的osd为1,经过PG::calc_replicated_acting()算法,want列表为[1,3,2],acting_backfill为[1,3,2],want_backfill为[3]。特别注意want列表第一个为主OSD,如果up_primary无法恢复,就选择权威日志的OSD为主OSD。
4) want[1,3,2]不等于acting[3,1,2]时,并且不等于up[3,1,2],需要向monitor申请pg_temp为want;
5) 申请成功pg_temp以后,acting为[1,3,2],up为[3,1,2],osd1作为临时的主OSD,处理读写请求。当该PG恢复处于clean状态,pg_temp取消,acting和up都恢复为[3,1,2]。
2. Peering之GetLog状态处理
我们在前面介绍了Peering之GetInfo状态的处理细节,这里介绍GetLog状态的处理:
PG::RecoveryState::GetLog::GetLog(my_context ctx)
: my_base(ctx),
NamedState(
context< RecoveryMachine >().pg->cct, "Started/Primary/Peering/GetLog"),
msg(0)
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
// adjust acting?
if (!pg->choose_acting(auth_log_shard, false,&context< Peering >().history_les_bound)) {
if (!pg->want_acting.empty()) {
post_event(NeedActingChange());
} else {
post_event(IsIncomplete());
}
return;
}
// am i the best?
if (auth_log_shard == pg->pg_whoami) {
post_event(GotLog());
return;
}
const pg_info_t& best = pg->peer_info[auth_log_shard];
// am i broken?
if (pg->info.last_update < best.log_tail) {
dout(10) << " not contiguous with osd." << auth_log_shard << ", down" << dendl;
post_event(IsIncomplete());
return;
}
// how much log to request?
eversion_t request_log_from = pg->info.last_update;
assert(!pg->actingbackfill.empty());
for (set<pg_shard_t>::iterator p = pg->actingbackfill.begin();p != pg->actingbackfill.end();++p) {
if (*p == pg->pg_whoami) continue;
pg_info_t& ri = pg->peer_info[*p];
if (ri.last_update >= best.log_tail && ri.last_update < request_log_from)
request_log_from = ri.last_update;
}
// how much?
dout(10) << " requesting log from osd." << auth_log_shard << dendl;
context<RecoveryMachine>().send_query(
auth_log_shard,
pg_query_t(
pg_query_t::LOG,
auth_log_shard.shard, pg->pg_whoami.shard,
request_log_from, pg->info.history,
pg->get_osdmap()->get_epoch()));
assert(pg->blocked_by.empty());
pg->blocked_by.insert(auth_log_shard.osd);
pg->publish_stats_to_osd();
}当PG的主OSD获取到所有从OSD(以及past_intervals期间所有参与该PG,且目前仍处于up状态的OSD)的pg_info信息后,就跳转到GetLog状态。
现在我们来看GetLog状态构造函数的处理:
1) 调用函数PG::choose_acting(auth_log_shard)选出具有权威日志的OSD,并计算出acting_backfill和backfill_targets两个OSD列表。输出保存在auth_log_shard里。
2) 如果选择失败并且want_acting不为空,就抛出NeedActingChange事件,状态机转移到Primary/WaitActingChange状态,等待申请临时PG返回结果。如果want_acting为空,就抛出IsInComplete事件,PG状态机转移到Primary/Peering/InComplete状态。表明PG失败,PG就处于InComplete状态。
3) 如果auth_log_shard等于pg->pg_whoami,也就是选出的拥有权威日志的OSD为当前主OSD,直接抛出事件GotLog()完成GetLog过程;
4)如果pg->info.last_update小于权威OSD的log_tail,也就是本OSD的日志和权威日志不重叠,那么本OSD无法恢复,抛出IsInComplete事件。经过函数PG::choose_acting()的选择后,主OSD必须是可恢复的。如果主OSD不可恢复,必须申请一个临时PG,选择拥有权威日志的OSD为临时主OSD;
5) 如果自己不是权威日志的OSD,则需要去拥有权威日志的OSD去拉取权威日志,并与本地合并。
2.1 PG日志
在具体讲解获取权威日志之前,我们先对PG日志相关内容做一个介绍,以方便我们后续的理解。
PG日志(pg log)为一个PG内所有更新操作的记录(下文所指的日志,如不特别指出,都是指PG日志)。每个PG对应一个PG日志,它持久化保存在每个PG对应pgmeta_oid对象的omap属性中。
它有如下特点:
-
记录一个PG内所有对象的更新操作元数据信息,并不记录操作的数据
-
是一个完整的日志记录,版本号是顺序且连续的
2.1.1 pg_log_t数据结构
结构体pg_log_t在内存中保存了该PG的所有操作日志,以及相关的控制结构:
/**
* pg_log_t - incremental log of recent pg changes.
*
* serves as a recovery queue for recent changes.
*/
struct pg_log_t {
/*
* head - newest entry (update|delete)
* tail - entry previous to oldest (update|delete) for which we have
* complete negative information.
* i.e. we can infer pg contents for any store whose last_update >= tail.
*/
eversion_t head; // newest entry
eversion_t tail; // version prior to oldest
// We can rollback rollback-able entries > can_rollback_to
eversion_t can_rollback_to;
// always <= can_rollback_to, indicates how far stashed rollback data can be found
eversion_t rollback_info_trimmed_to;
list<pg_log_entry_t> log; // the actual log.
};需要注意的是,PG日志的记录是以整个PG为单位,包括该PG内所有对象的修改记录。下面我们简要介绍一下各字段含义:
-
head: 日志的头,记录最新的日志记录;
-
tail: 日志的尾(version prior to oldest)
-
can_rollback_to: 用于EC,指示本地可以回滚的版本,可回滚的版本都大于版本can_rollback_to的值;
-
rollback_info_trimmed_to: 在EC的实现中,本地保留了不同版本的数据。本数据段指示本PG里可以删除掉的对象版本;
-
log: 所有日志的列表
2.1.2 pg_log_entry_t数据结构
结构体pg_log_entry_t记录了PG日志的单条记录,其数据结构如下:
/**
* pg_log_entry_t - single entry/event in pg log
*
*/
struct pg_log_entry_t {
enum {
MODIFY = 1, // some unspecified modification (but not *all* modifications)
CLONE = 2, // cloned object from head
DELETE = 3, // deleted object
BACKLOG = 4, // event invented by generate_backlog [deprecated]
LOST_REVERT = 5, // lost new version, revert to an older version.
LOST_DELETE = 6, // lost new version, revert to no object (deleted).
LOST_MARK = 7, // lost new version, now EIO
PROMOTE = 8, // promoted object from another tier
CLEAN = 9, // mark an object clean
};
// describes state for a locally-rollbackable entry
ObjectModDesc mod_desc;
bufferlist snaps; // only for clone entries
hobject_t soid;
osd_reqid_t reqid; // caller+tid to uniquely identify request
vector<pair<osd_reqid_t, version_t> > extra_reqids;
eversion_t version, prior_version, reverting_to;
version_t user_version; // the user version for this entry
utime_t mtime; // this is the _user_ mtime, mind you
__s32 op;
bool invalid_hash; // only when decoding sobject_t based entries
bool invalid_pool; // only when decoding pool-less hobject based entries
};下面简要介绍一下各字段的含义:
-
op: 操作的类型
-
soid: 操作的对象
-
version: 本次操作的版本
-
prior_version: 前一个操作的版本
-
reverting_to: 本次操作回退的版本(仅用于回滚操作)
-
mod_desc: 用于保存本地回滚的一些信息,用于EC模式下的回滚操作
-
snaps: 克隆操作,用于记录当前对象的snap列表
-
reqid: 请求唯一标识(called + tid)
-
user_version: 用户的版本
-
mtime: 还是用户的本地时间
2.1.3 IndexedLog
类IndexedLog继承了pg_log_t,在其基础上添加了根据一个对象来检索日志的功能,以及其他相关的功能。
2.1.4 日志的写入
函数PG::add_log_entry()添加pg_log_entry_t条目到PG日志中。同时更新了info.last_complete和info.last_update字段。
PGLog::write_log()函数将日志写到对应的pgmeta_oid对象的kv存储中。在这里并没有直接写入磁盘,而是先把日志的修改添加到ObjectStore::Transaction类型的事务中,与数据操作组成一个事务整体提交磁盘。这样可以保证数据操作、日志更新及其pg_info信息的更新都在一个事务中,都以原子方式提交到磁盘上。
2.1.5 日志的trim操作
函数trim用来删除不需要的旧日志。当日志的条目数大于min_log_entries时,需要进行trim操作:
void PGLog::trim(LogEntryHandler *handler,eversion_t trim_to,pg_info_t &info)
{
}2.1.6 PG Primary合并权威日志
当PG Primary收到权威日志之后,就会调用PG::proc_master_log()来进行处理,其中最主要的操作就是合并权威日志:
void PG::proc_master_log(
ObjectStore::Transaction& t, pg_info_t &oinfo,
pg_log_t &olog, pg_missing_t& omissing, pg_shard_t from)
{
...
merge_log(t, oinfo, olog, from);
...
}
void PG::merge_log(
ObjectStore::Transaction& t, pg_info_t &oinfo, pg_log_t &olog, pg_shard_t from)
{
PGLogEntryHandler rollbacker;
pg_log.merge_log(t, oinfo, olog, from, info, &rollbacker, dirty_info, dirty_big_info);
rollbacker.apply(this, &t);
}
void PGLog::merge_log(ObjectStore::Transaction& t,
pg_info_t &oinfo, pg_log_t &olog, pg_shard_t fromosd,
pg_info_t &info, LogEntryHandler *rollbacker,
bool &dirty_info, bool &dirty_big_info)
{
...
}这里我们简单描述一下大体的处理过程(详细代码分析,我们会在后面再介绍):
1) 本地日志和权威日志没有重叠的部分:在这种情况下就无法根据日志来进行修复,只能通过Backfill过程来完成修复。所以先确保权威日志与本地日志有重叠的部分:
assert(log.head >= olog.tail && olog.head >= log.tail);2) 本地日志和权威日志有重叠部分的处理:
-
如果olog.tail小于log.tail,也就是权威日志的尾部比本地日志长。这种情况下,只要把日志多出的部分添加到本地日志即可,它不影响missing对象集合
-
本地日志的头部比权威日志的头部长,说明有多出来的divergent日志,调用函数rewind_divergent_log()去处理;
-
本地日志的头部比权威日志的头部短,说明有缺失的日志,其处理过程为:把缺失的日志添加到本地日志中,记录missing的对象,并删除多出来的日志记录;
2.1.7 处理副本日志
PG Primary在GetMissing阶段会拉取各个副本上的有效日志,然后调用PG::proc_replica_log()函数来进行处理,其关键在于计算missing的对象列表,也就是需要修复的对象。
void PG::proc_replica_log(
ObjectStore::Transaction& t,
pg_info_t &oinfo, pg_log_t &olog, pg_missing_t& omissing,
pg_shard_t from)
{
}2.2 获取权威日志流程
在上面我们讲到,如果主OSD不是拥有权威日志的OSD,就需要去拥有权威日志的OSD上拉取权威日志。这里我们先大概给出一张PG Primary发送pg_query_t请求到权威日志的OSD拉取权威日志的流程:

相关数据结构
1) pg_query_t数据结构
/**
* pg_query_t - used to ask a peer for information about a pg.
*
* note: if version=0, type=LOG, then we just provide our full log.
*/
struct pg_query_t {
enum {
INFO = 0,
LOG = 1,
MISSING = 4,
FULLLOG = 5,
};
__s32 type;
eversion_t since;
pg_history_t history;
epoch_t epoch_sent;
shard_id_t to;
shard_id_t from;
pg_query_t(
int t,
shard_id_t to,
shard_id_t from,
eversion_t s,
const pg_history_t& h,
epoch_t epoch_sent)
: type(t), since(s), history(h),epoch_sent(epoch_sent), to(to), from(from) {
assert(t == LOG);
}
};
struct pg_shard_t {
int32_t osd;
shard_id_t shard;
};-
type: 所要查询的类型(有INFO/LOG/MISSING/FULLLOG这些类型)
-
since: 查询从哪一个epoch开始的日志
-
history: pg info的history信息
-
epoch_sent: 发送时刻PG所对应的OSDMap的版本号
-
to: 查询信息所要发送到的PG副本编号
-
from: 查询信息源的PG副本编号
2) MOSDPGQuery数据结构
class MOSDPGQuery : public Message {
version_t epoch;
public:
version_t get_epoch() { return epoch; }
map<spg_t, pg_query_t> pg_list;
MOSDPGQuery() : Message(MSG_OSD_PG_QUERY,HEAD_VERSION,COMPAT_VERSION) {}
MOSDPGQuery(epoch_t e, map<spg_t,pg_query_t>& ls) :
Message(MSG_OSD_PG_QUERY,
HEAD_VERSION,
COMPAT_VERSION),
epoch(e) {
pg_list.swap(ls);
}
};MOSDPGQuery只是将众多的pg_query_t打包起来。其中epoch为MOSDPGQuery发送时候的OSDMap版本号;
3)MQuery数据结构
struct MQuery : boost::statechart::event< MQuery > {
pg_shard_t from;
pg_query_t query;
epoch_t query_epoch;
MQuery(pg_shard_t from, const pg_query_t &query, epoch_t query_epoch):
from(from), query(query), query_epoch(query_epoch) {}
void print(std::ostream *out) const {
*out << "MQuery from " << from << " query_epoch " << query_epoch << " query: " << query;
}
};下面介绍以下各字段的含义:
-
from: MQuery查询来源于PG的哪一个OSD副本
-
query: 具体的查询信息
-
query_epoch: 查询消息(pg_query_t)在发送端构造时刻的epoch值
4)MOSDPGLog数据结构
typedef map<epoch_t, pg_interval_t> pg_interval_map_t;
struct pg_interval_t {
vector<int32_t> up, acting;
epoch_t first, last;
bool maybe_went_rw;
int32_t primary;
int32_t up_primary;
};
class MOSDPGLog : public Message {
epoch_t epoch;
/// query_epoch is the epoch of the query being responded to, or
/// the current epoch if this is not being sent in response to a
/// query. This allows the recipient to disregard responses to old
/// queries.
epoch_t query_epoch;
public:
shard_id_t to;
shard_id_t from;
pg_info_t info;
pg_log_t log;
pg_missing_t missing;
pg_interval_map_t past_intervals;
};下面简单介绍一下各字段:
-
epoch: PG构造MOSDPGLog消息时候的OSDMap版本号
-
query_epoch: 查询消息(pg_query_t)在发送端构造时刻的epoch值
-
to: 消息发送到PG的哪个OSD副本(对于ReplicatedPG来说,可能都是
NOSHARD) -
from: 消息来自于PG的哪个OSD副本(对于ReplicatedPG来说,可能都是
NOSHARD) -
info: 当前的PG info信息
-
log: pg log信息
-
missing: 当前PG的missing列表
-
past_intervals: 本PG副本的past_intervals
5) pg_missing_t数据结构
// src/include/types.h
typedef uint64_t version_t;
/**
* pg_missing_t - summary of missing objects.
*
* kept in memory, as a supplement to pg_log_t
* also used to pass missing info in messages.
*/
struct pg_missing_t {
struct item {
eversion_t need, have;
};
map<hobject_t, item, hobject_t::ComparatorWithDefault> missing; // oid -> (need v, have v)
map<version_t, hobject_t> rmissing; // v -> oid
};下面我们简单介绍一下各字段的含义:
-
item.need: 指示需要的object的版本号
-
item.have: 指示当前已经拥有的object的版本号
-
missing: 保存当前所missing的对象列表
-
rmissing: 一个通过version反向查找object的map
关于pg_log_entry_t中各version的赋值,请参看《ceph中PGLog处理流程》。
PG::fulfill_log()函数
void PG::fulfill_log(
pg_shard_t from, const pg_query_t &query, epoch_t query_epoch)
{
dout(10) << "log request from " << from << dendl;
assert(from == primary);
assert(query.type != pg_query_t::INFO);
MOSDPGLog *mlog = new MOSDPGLog(
from.shard, pg_whoami.shard,
get_osdmap()->get_epoch(),
info, query_epoch);
mlog->missing = pg_log.get_missing();
// primary -> other, when building master log
if (query.type == pg_query_t::LOG) {
dout(10) << " sending info+missing+log since " << query.since<< dendl;
if (query.since != eversion_t() && query.since < pg_log.get_tail()) {
osd->clog->error() << info.pgid << " got broken pg_query_t::LOG since " << query.since
<< " when my log.tail is " << pg_log.get_tail()<< ", sending full log instead\n";
mlog->log = pg_log.get_log(); // primary should not have requested this!!
} else
mlog->log.copy_after(pg_log.get_log(), query.since);
}
else if (query.type == pg_query_t::FULLLOG) {
dout(10) << " sending info+missing+full log" << dendl;
mlog->log = pg_log.get_log();
}
dout(10) << " sending " << mlog->log << " " << mlog->missing << dendl;
ConnectionRef con = osd->get_con_osd_cluster(
from.osd, get_osdmap()->get_epoch());
if (con) {
osd->share_map_peer(from.osd, con.get(), get_osdmap());
osd->send_message_osd_cluster(mlog, con.get());
} else {
mlog->put();
}
}副本构造构造权威日志信息,然后发送给primary。
2.3 GetLog状态下接收权威日志
struct GetLog : boost::statechart::state< GetLog, Peering >, NamedState {
pg_shard_t auth_log_shard;
boost::intrusive_ptr<MOSDPGLog> msg;
explicit GetLog(my_context ctx);
void exit();
typedef boost::mpl::list <
boost::statechart::custom_reaction< QueryState >,
boost::statechart::custom_reaction< MLogRec >,
boost::statechart::custom_reaction< GotLog >,
boost::statechart::custom_reaction< AdvMap >,
boost::statechart::transition< IsIncomplete, Incomplete >
> reactions;
boost::statechart::result react(const AdvMap&);
boost::statechart::result react(const QueryState& q);
boost::statechart::result react(const MLogRec& logevt);
boost::statechart::result react(const GotLog&);
};
boost::statechart::result PG::RecoveryState::GetLog::react(const MLogRec& logevt)
{
assert(!msg);
if (logevt.from != auth_log_shard) {
dout(10) << "GetLog: discarding log from "<< "non-auth_log_shard osd." << logevt.from << dendl;
return discard_event();
}
dout(10) << "GetLog: received master log from osd"<< logevt.from << dendl;
msg = logevt.msg;
post_event(GotLog());
return discard_event();
}
boost::statechart::result PG::RecoveryState::GetLog::react(const GotLog&)
{
dout(10) << "leaving GetLog" << dendl;
PG *pg = context< RecoveryMachine >().pg;
if (msg) {
dout(10) << "processing master log" << dendl;
pg->proc_master_log(*context<RecoveryMachine>().get_cur_transaction(),msg->info,
msg->log, msg->missing, auth_log_shard);
}
pg->start_flush(
context< RecoveryMachine >().get_cur_transaction(),
context< RecoveryMachine >().get_on_applied_context_list(),
context< RecoveryMachine >().get_on_safe_context_list());
return transit< GetMissing >();
}Primary OSD接收到PG权威日志封装成MLogRec事件发送给状态机处理,此时状态机处于GetLog状态,因此会由PG::RecoveryState::GetLog::react(const MLogRec& logevt)函数来处理,在该函数中抛出GotLog()事件。
在PG::RecoveryState::GetLog::react(const GotLog&)中,其处理流程如下:
1) 如果msg不为空,就调用函数PG::proc_master_log()来合并自己缺失的权威日志,并更新自己的pginfo相关的信息。从此,作为主OSD,也是拥有权威日志的OSD。
PG::proc_master_log()函数的实现较为复杂,我们会在下面一节单独来分析。
2) 调用PG::start_flush()添加一个空操作
struct FlushState {
PGRef pg;
epoch_t epoch;
FlushState(PG *pg, epoch_t epoch) : pg(pg), epoch(epoch) {}
~FlushState() {
pg->lock();
if (!pg->pg_has_reset_since(epoch))
pg->queue_flushed(epoch);
pg->unlock();
}
};
typedef ceph::shared_ptr<FlushState> FlushStateRef;
void PG::start_flush(ObjectStore::Transaction *t,
list<Context *> *on_applied,
list<Context *> *on_safe)
{
// flush in progress ops
FlushStateRef flush_trigger (std::make_shared<FlushState>(
this, get_osdmap()->get_epoch()));
t->nop();
flushes_in_progress++;
on_applied->push_back(new ContainerContext<FlushStateRef>(flush_trigger));
on_safe->push_back(new ContainerContext<FlushStateRef>(flush_trigger));
}
void PG::queue_flushed(epoch_t e)
{
dout(10) << "flushed" << dendl;
queue_peering_event(
CephPeeringEvtRef(std::make_shared<CephPeeringEvt>(e, e,FlushedEvt())));
}
boost::statechart::result
PG::RecoveryState::Started::react(const FlushedEvt&)
{
PG *pg = context< RecoveryMachine >().pg;
pg->on_flushed();
return discard_event();
}
void ReplicatedPG::on_flushed()
{
assert(flushes_in_progress > 0);
flushes_in_progress--;
if (flushes_in_progress == 0) {
requeue_ops(waiting_for_peered);
}
if (!is_peered() || !is_primary()) {
pair<hobject_t, ObjectContextRef> i;
while (object_contexts.get_next(i.first, &i)) {
derr << "on_flushed: object " << i.first << " obc still alive" << dendl;
}
assert(object_contexts.empty());
}
pgbackend->on_flushed();
}关于flush操作,我们这里不细述。
3) 调用transit< GetMissing >()跳转到GetMissing状态
经过GetLog阶段的处理后,该PG的主OSD已经获取了权威日志,以及pg_info的权威信息。
2.4 PG::proc_master_log()详细分析
PG Primary在接收到权威日志之后,就会调用PG::proc_master_log()来进行处理:
void PG::proc_master_log(
ObjectStore::Transaction& t, pg_info_t &oinfo,
pg_log_t &olog, pg_missing_t& omissing, pg_shard_t from)
{
dout(10) << "proc_master_log for osd." << from << ": "<< olog << " " << omissing << dendl;
assert(!is_peered() && is_primary());
// merge log into our own log to build master log. no need to
// make any adjustments to their missing map; we are taking their
// log to be authoritative (i.e., their entries are by definitely
// non-divergent).
merge_log(t, oinfo, olog, from);
peer_info[from] = oinfo;
dout(10) << " peer osd." << from << " now " << oinfo << " " << omissing << dendl;
might_have_unfound.insert(from);
// See doc/dev/osd_internals/last_epoch_started
if (oinfo.last_epoch_started > info.last_epoch_started) {
info.last_epoch_started = oinfo.last_epoch_started;
dirty_info = true;
}
if (info.history.merge(oinfo.history))
dirty_info = true;
assert(cct->_conf->osd_find_best_info_ignore_history_les ||info.last_epoch_started >= info.history.last_epoch_started);
peer_missing[from].swap(omissing);
}其处理过程如下:
1) 调用PG::merge_log()合并权威日志
注:我们认为权威日志本身并不会出现分歧
2) 将拥有权威日志的PG副本加入到might_have_unfound;
注:PG::might_have_unfound数组里的OSD可能存放了PG的一些对象,我们后续需要利用这些OSD来进行数据恢复
3)如果oinfo.last_epoch_started大于info.last_epoch_started,说明oinfo所在的PG副本当时已经完成了peering,并可能进行了数据写入。因此这里对于PG Primary再合并了权威日志之后,也可对其last_epoch_started进行更新。
注:这里只是合并了权威日志,实际的对象还没有完成恢复
3) 调用pg_history_t::merge()合并权威pg_info
4) 再peer_missing列表中登记oinfo所在PG副本的缺失对象
2.4.1 PG::merge_log()实现
void PG::merge_log(
ObjectStore::Transaction& t, pg_info_t &oinfo, pg_log_t &olog, pg_shard_t from)
{
PGLogEntryHandler rollbacker;
pg_log.merge_log(t, oinfo, olog, from, info, &rollbacker, dirty_info, dirty_big_info);
rollbacker.apply(this, &t);
}处理过程如下:
-
调用PGLog::merge_log()将权威日志合并到PG::pg_log中
-
调用PGLogEntryHandler::apply()来将相关的pglog的改变以事务的形式保存到ObjectStore中
2.4.1.1 PGLog::merge_log()分析
void PGLog::merge_log(ObjectStore::Transaction& t,
pg_info_t &oinfo, pg_log_t &olog, pg_shard_t fromosd,
pg_info_t &info, LogEntryHandler *rollbacker,
bool &dirty_info, bool &dirty_big_info)
{
dout(10) << "merge_log " << olog << " from osd." << fromosd<< " into " << log << dendl;
// Check preconditions
// If our log is empty, the incoming log needs to have not been trimmed.
assert(!log.null() || olog.tail == eversion_t());
// The logs must overlap.
assert(log.head >= olog.tail && olog.head >= log.tail);
for (map<hobject_t, pg_missing_t::item, hobject_t::BitwiseComparator>::iterator i = missing.missing.begin();
i != missing.missing.end();++i) {
dout(20) << "pg_missing_t sobject: " << i->first << dendl;
}
bool changed = false;
// extend on tail?
// this is just filling in history. it does not affect our
// missing set, as that should already be consistent with our
// current log.
if (olog.tail < log.tail) {
dout(10) << "merge_log extending tail to " << olog.tail << dendl;
list<pg_log_entry_t>::iterator from = olog.log.begin();
list<pg_log_entry_t>::iterator to;
eversion_t last;
for (to = from;to != olog.log.end();++to) {
if (to->version > log.tail)
break;
log.index(*to);
dout(15) << *to << dendl;
last = to->version;
}
mark_dirty_to(last);
// splice into our log.
log.log.splice(log.log.begin(),
olog.log, from, to);
info.log_tail = log.tail = olog.tail;
changed = true;
}
if (oinfo.stats.reported_seq < info.stats.reported_seq || // make sure reported always increases
oinfo.stats.reported_epoch < info.stats.reported_epoch) {
oinfo.stats.reported_seq = info.stats.reported_seq;
oinfo.stats.reported_epoch = info.stats.reported_epoch;
}
if (info.last_backfill.is_max())
info.stats = oinfo.stats;
info.hit_set = oinfo.hit_set;
// do we have divergent entries to throw out?
if (olog.head < log.head) {
rewind_divergent_log(t, olog.head, info, rollbacker, dirty_info, dirty_big_info);
changed = true;
}
// extend on head?
if (olog.head > log.head) {
dout(10) << "merge_log extending head to " << olog.head << dendl;
// find start point in olog
list<pg_log_entry_t>::iterator to = olog.log.end();
list<pg_log_entry_t>::iterator from = olog.log.end();
eversion_t lower_bound = olog.tail;
while (1) {
if (from == olog.log.begin())
break;
--from;
dout(20) << " ? " << *from << dendl;
if (from->version <= log.head) {
dout(20) << "merge_log cut point (usually last shared) is " << *from << dendl;
lower_bound = from->version;
++from;
break;
}
}
mark_dirty_from(lower_bound);
// move aside divergent items
list<pg_log_entry_t> divergent;
while (!log.empty()) {
pg_log_entry_t &oe = *log.log.rbegin();
/*
* look at eversion.version here. we want to avoid a situation like:
* our log: 100'10 (0'0) m 10000004d3a.00000000/head by client4225.1:18529
* new log: 122'10 (0'0) m 10000004d3a.00000000/head by client4225.1:18529
* lower_bound = 100'9
* i.e, same request, different version. If the eversion.version is > the
* lower_bound, we it is divergent.
*/
if (oe.version.version <= lower_bound.version)
break;
dout(10) << "merge_log divergent " << oe << dendl;
divergent.push_front(oe);
log.log.pop_back();
}
list<pg_log_entry_t> entries;
entries.splice(entries.end(), olog.log, from, to);
append_log_entries_update_missing(
info.last_backfill,
info.last_backfill_bitwise,
entries,
&log,
missing,
rollbacker,
this);
log.index();
info.last_update = log.head = olog.head;
info.last_user_version = oinfo.last_user_version;
info.purged_snaps = oinfo.purged_snaps;
map<eversion_t, hobject_t> new_priors;
_merge_divergent_entries(
log,
divergent,
info,
log.can_rollback_to,
missing,
&new_priors,
rollbacker,
this);
for (map<eversion_t, hobject_t>::iterator i = new_priors.begin();i != new_priors.end();++i) {
add_divergent_prior(i->first,i->second);
}
// We cannot rollback into the new log entries
log.can_rollback_to = log.head;
changed = true;
}
dout(10) << "merge_log result " << log << " " << missing << " changed=" << changed << dendl;
if (changed) {
dirty_info = true;
dirty_big_info = true;
}
}我们来看具体处理流程:
1) 进行先决条件检查
-
假如当前PG Primary的log为空,那么必须确保输入进来的日志(incomming log)没有被trim
-
必须确保本地日志与输入进来的权威日志(incomming authoritative log)有重叠
(log.head >= olog.tail && olog.head >= log.tail)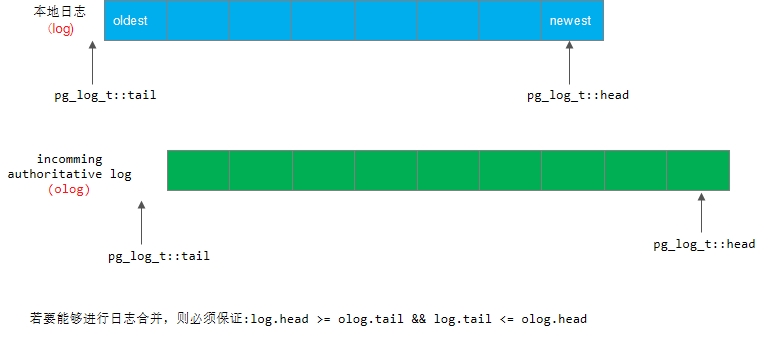
2) 打印当前PG Primary副本的missing对象
3)如果olog.tail小于log.tail,那么将合并tail部分,如下图所示
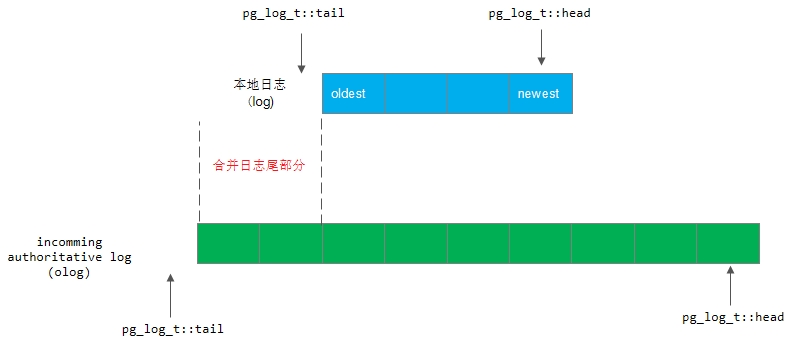
合并完成后,PG Primary的,tail相关指针做相应改变:
info.log_tail = log.tail = olog.tail;
4) 修正PG info的状态信息
void PGLog::merge_log(ObjectStore::Transaction& t,
pg_info_t &oinfo, pg_log_t &olog, pg_shard_t fromosd,
pg_info_t &info, LogEntryHandler *rollbacker,
bool &dirty_info, bool &dirty_big_info)
{
...
if (oinfo.stats.reported_seq < info.stats.reported_seq || // make sure reported always increases
oinfo.stats.reported_epoch < info.stats.reported_epoch) {
oinfo.stats.reported_seq = info.stats.reported_seq;
oinfo.stats.reported_epoch = info.stats.reported_epoch;
}
if (info.last_backfill.is_max())
info.stats = oinfo.stats;
info.hit_set = oinfo.hit_set;
...
}5) 如果olog.head小于log.head,那么产生了分歧,调用PG::rewind_divergent_log()来回退当前的pg log,并更新PG的pg info
void PGLog::merge_log(ObjectStore::Transaction& t,
pg_info_t &oinfo, pg_log_t &olog, pg_shard_t fromosd,
pg_info_t &info, LogEntryHandler *rollbacker,
bool &dirty_info, bool &dirty_big_info)
{
...
// do we have divergent entries to throw out?
if (olog.head < log.head) {
rewind_divergent_log(t, olog.head, info, rollbacker, dirty_info, dirty_big_info);
changed = true;
}
...
}如下图所示:
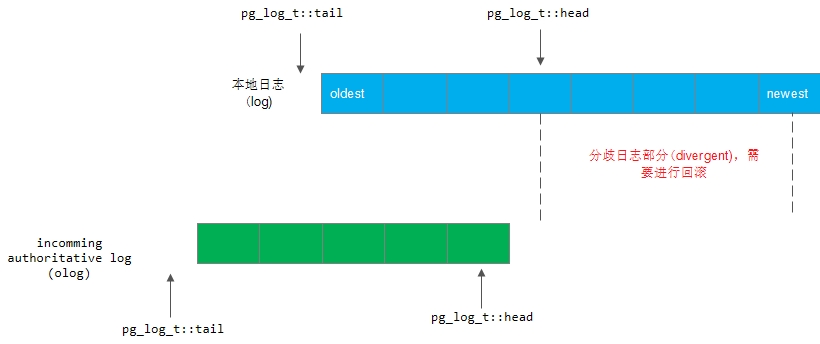
具体的关于PG::rewind_divergent_log()的实现,我们在下面单独讲述。
6) 如果olog.head 大于log.head,那么需要进行日志头部分的合并,如下图所示
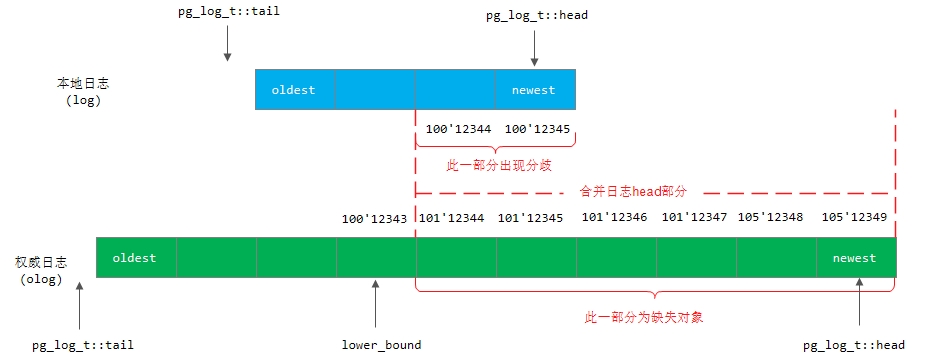
在合并head时,涉及到处理分歧日志以及构建missing对象,这两项在图中都有展示,详细代码实现我们在下面单独讲述。
2.4.1.2 PGLog::merge_log()应用举例
下面我们举例说明函数PGLog::merge_log()的不同处理情形。
1) 情形1: 权威日志的尾部版本比本地日志的尾部小
如下图所示:

本地log的log_tail为obj10(1,6),权威日志olog的log_tail为obj3(1,4)。
日志合并的处理方式如下图所示:

把日志记录obj3(1,4)、obj4(1,5)添加到本地日志中,修改info.log_tail和log.tail指针即可。
2) 情形2: 本地日志的头部比权威日志长
如下图所示:

权威日志的log_head为obj13(1,8),而本地日志的log_head为obj10(1,11)。本地日志的log_head版本大于权威日志的log_head版本,调用函数rewind_divergent_log()来处理本地有分歧的日志。
在本例的具体处理过程为:把对象obj10、obj11、obj13加入missing列表中用于修复。最后删除多余的日志,如下所示:

本例比较简单,函数rewind_divergent_log()会处理比较复杂的一些情况,后面会介绍到。
3) 情形3: 本地日志的头部版本比权威日志的头部短
如下图所示:

权威日志的log_head为obj10(1,11),而本地日志的log_head为obj13(1,8),即本地日志的log_head版本小于权威日志的log_head版本。
其处理方式如下:把本地日志缺失的日志添加到本地,并计算本地缺失的对象。最后把缺失的对象添加到missing object列表中用于后续的修复,处理结果如下所示:

下面我们介绍一下如下两个函数的实现:
-
函数PG::rewind_divergent_log()
-
函数PG::append_log_entries_update_missing()
这里我们首先介绍PG::append_log_entries_update_missing(),其可能会影响到我们对PG::rewind_divergent_log()的理解。
2.4.2 PG::append_log_entries_update_missing()函数
void PGLog::append_log_entries_update_missing(
const hobject_t &last_backfill,
bool last_backfill_bitwise,
const list<pg_log_entry_t> &entries,
IndexedLog *log,
pg_missing_t &missing,
LogEntryHandler *rollbacker,
const DoutPrefixProvider *dpp)
{
if (log && !entries.empty()) {
assert(log->head < entries.begin()->version);
log->head = entries.rbegin()->version;
}
for (list<pg_log_entry_t>::const_iterator p = entries.begin();p != entries.end();++p) {
if (log) {
log->log.push_back(*p);
pg_log_entry_t &ne = log->log.back();
ldpp_dout(dpp, 20) << "update missing, append " << ne << dendl;
log->index(ne);
}
if (cmp(p->soid, last_backfill, last_backfill_bitwise) <= 0) {
missing.add_next_event(*p);
if (rollbacker) {
// hack to match PG::mark_all_unfound_lost
if (p->is_lost_delete() && p->mod_desc.can_rollback()) {
rollbacker->try_stash(p->soid, p->version.version);
} else if (p->is_delete()) {
rollbacker->remove(p->soid);
}
}
}
}
if (log)
log->reset_rollback_info_trimmed_to_riter();
}
/*
* this needs to be called in log order as we extend the log. it
* assumes missing is accurate up through the previous log entry.
*/
void pg_missing_t::add_next_event(const pg_log_entry_t& e)
{
if (e.is_update()) {
map<hobject_t, item, hobject_t::ComparatorWithDefault>::iterator missing_it;
missing_it = missing.find(e.soid);
bool is_missing_divergent_item = missing_it != missing.end();
if (e.prior_version == eversion_t() || e.is_clone()) {
// new object.
if (is_missing_divergent_item) { // use iterator
rmissing.erase((missing_it->second).need.version);
missing_it->second = item(e.version, eversion_t()); // .have = nil
} else // create new element in missing map
missing[e.soid] = item(e.version, eversion_t()); // .have = nil
} else if (is_missing_divergent_item) {
// already missing (prior).
rmissing.erase((missing_it->second).need.version);
(missing_it->second).need = e.version; // leave .have unchanged.
} else if (e.is_backlog()) {
// May not have prior version
assert(0 == "these don't exist anymore");
} else {
// not missing, we must have prior_version (if any)
assert(!is_missing_divergent_item);
missing[e.soid] = item(e.version, e.prior_version);
}
rmissing[e.version.version] = e.soid;
} else
rm(e.soid, e.version);
}函数PG::append_log_entries_update_missing()顾名思义,就是向log中追加entries,并且更新missing列表。通过在PG::merge_log()中传入的参数,我们可知会向PGLog::log中追加entries,并且更新PGLog::missing。
在函数中,会遍历传递进来的entries,针对每一个条目p:
1) 向log追加该entry条目,并调用IndexedLog::index()建立该日志条目索引;
2) 如果p->soid小于等于last_backfill,调用pg_missing_t::add_next_event()添加一个pg_log_entry_t事件。若rollbacker不为空,执行如下:
-
若该日志条目是lost_delete一个object,且支持EC,则调用PGLogEntryHandler::try_stash()暂存该对象;
-
若该日志条目是delete一个object,则PGLogEntryHandler::remove()删除该对象;
2.4.3 PG::rewind_divergent_log()回退分歧日志
/**
* rewind divergent entries at the head of the log
*
* This rewinds entries off the head of our log that are divergent.
* This is used by replicas during activation.
*
* @param t transaction
* @param newhead new head to rewind to
*/
void PGLog::rewind_divergent_log(ObjectStore::Transaction& t, eversion_t newhead,
pg_info_t &info, LogEntryHandler *rollbacker,
bool &dirty_info, bool &dirty_big_info)
{
dout(10) << "rewind_divergent_log truncate divergent future " << newhead << dendl;
assert(newhead >= log.tail);
list<pg_log_entry_t>::iterator p = log.log.end();
list<pg_log_entry_t> divergent;
while (true) {
if (p == log.log.begin()) {
// yikes, the whole thing is divergent!
divergent.swap(log.log);
break;
}
--p;
mark_dirty_from(p->version);
if (p->version <= newhead) {
++p;
divergent.splice(divergent.begin(), log.log, p, log.log.end());
break;
}
assert(p->version > newhead);
dout(10) << "rewind_divergent_log future divergent " << *p << dendl;
}
log.head = newhead;
info.last_update = newhead;
if (info.last_complete > newhead)
info.last_complete = newhead;
if (log.rollback_info_trimmed_to > newhead)
log.rollback_info_trimmed_to = newhead;
log.index();
map<eversion_t, hobject_t> new_priors;
_merge_divergent_entries(
log,
divergent,
info,
log.can_rollback_to,
missing,
&new_priors,
rollbacker,
this);
for (map<eversion_t, hobject_t>::iterator i = new_priors.begin();i != new_priors.end();++i) {
add_divergent_prior(i->first,i->second);
}
if (info.last_update < log.can_rollback_to)
log.can_rollback_to = info.last_update;
dirty_info = true;
dirty_big_info = true;
}PG::rewind_divergent_log()函数就是将当前的PGLog回退到参数newhead指定的未知。我们来看实现流程:
1) 从后往前遍历当前的PGLog,找出PGLog中newhead之后的所有分歧日志放入divergent列表中;
2) 因rewind分歧日志,可能造成pg info也要做相应的变动
3) 调用IndexedLog::index()重建当前的日志索引
4) 调用_merge_divergent_entries()合并分歧日志
5) 将分歧的对象加入到PGLog::divergent_priors中
2.4.3.1 函数_merge_divergent_entries()
/// Merge all entries using above
static void _merge_divergent_entries(
const IndexedLog &log, ///< [in] log to merge against
list<pg_log_entry_t> &entries, ///< [in] entries to merge
const pg_info_t &oinfo, ///< [in] info for merging entries
eversion_t olog_can_rollback_to, ///< [in] rollback boundary
pg_missing_t &omissing, ///< [in,out] missing to adjust, use
map<eversion_t, hobject_t> *priors, ///< [out] target for new priors
LogEntryHandler *rollbacker, ///< [in] optional rollbacker object
const DoutPrefixProvider *dpp ///< [in] logging provider
) {
map<hobject_t, list<pg_log_entry_t>, hobject_t::BitwiseComparator > split;
split_by_object(entries, &split);
for (map<hobject_t, list<pg_log_entry_t>, hobject_t::BitwiseComparator>::iterator i = split.begin();i != split.end();++i) {
boost::optional<pair<eversion_t, hobject_t> > new_divergent_prior;
_merge_object_divergent_entries(
log,
i->first,
i->second,
oinfo,
olog_can_rollback_to,
omissing,
&new_divergent_prior,
rollbacker,
dpp);
if (priors && new_divergent_prior) {
(*priors)[new_divergent_prior->first] = new_divergent_prior->second;
}
}
}处理流程如下:
1) 调用split_by_object()函数将当前分歧列表中的日志按对象来进行划分
static void split_by_object(
list<pg_log_entry_t> &entries,
map<hobject_t, list<pg_log_entry_t>, hobject_t::BitwiseComparator> *out_entries) {
while (!entries.empty()) {
list<pg_log_entry_t> &out_list = (*out_entries)[entries.front().soid];
out_list.splice(out_list.end(), entries, entries.begin());
}
}2) 遍历split列表,然后调用_merge_object_divergent_entries()来合并分歧对象
/**
* _merge_object_divergent_entries
*
* There are 5 distinct cases:
* 1) There is a more recent update: in this case we assume we adjusted the
* store and missing during merge_log
* 2) The first entry in the divergent sequence is a create. This might
* either be because the object is a clone or because prior_version is
* eversion_t(). In this case the object does not exist and we must
* adjust missing and the store to match.
* 3) We are currently missing the object. In this case, we adjust the
* missing to our prior_version taking care to add a divergent_prior
* if necessary
* 4) We can rollback all of the entries. In this case, we do so using
* the rollbacker and return -- the object does not go into missing.
* 5) We cannot rollback at least 1 of the entries. In this case, we
* clear the object out of the store and add a missing entry at
* prior_version taking care to add a divergent_prior if
* necessary.
*/
void PGLog::_merge_object_divergent_entries(
const IndexedLog &log,
const hobject_t &hoid,
const list<pg_log_entry_t> &entries,
const pg_info_t &info,
eversion_t olog_can_rollback_to,
pg_missing_t &missing,
boost::optional<pair<eversion_t, hobject_t> > *new_divergent_prior,
LogEntryHandler *rollbacker,
const DoutPrefixProvider *dpp
)
{
ldpp_dout(dpp, 20) << __func__ << ": merging hoid " << hoid << " entries: " << entries << dendl;
if (cmp(hoid, info.last_backfill, info.last_backfill_bitwise) > 0) {
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid << " after last_backfill" << dendl;
return;
}
// entries is non-empty
assert(!entries.empty());
eversion_t last;
for (list<pg_log_entry_t>::const_iterator i = entries.begin();i != entries.end();++i) {
// all entries are on hoid
assert(i->soid == hoid);
if (i != entries.begin() && i->prior_version != eversion_t()) {
// in increasing order of version
assert(i->version > last);
// prior_version correct
assert(i->prior_version == last);
}
last = i->version;
if (rollbacker)
rollbacker->trim(*i);
}
const eversion_t prior_version = entries.begin()->prior_version;
const eversion_t first_divergent_update = entries.begin()->version;
const eversion_t last_divergent_update = entries.rbegin()->version;
const bool object_not_in_store = !missing.is_missing(hoid) && entries.rbegin()->is_delete();
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid << " prior_version: " << prior_version
<< " first_divergent_update: " << first_divergent_update << " last_divergent_update: " << last_divergent_update << dendl;
ceph::unordered_map<hobject_t, pg_log_entry_t*>::const_iterator objiter = log.objects.find(hoid);
if (objiter != log.objects.end() && objiter->second->version >= first_divergent_update) {
/// Case 1)
assert(objiter->second->version > last_divergent_update);
ldpp_dout(dpp, 10) << __func__ << ": more recent entry found: " << *objiter->second << ", already merged" << dendl;
// ensure missing has been updated appropriately
if (objiter->second->is_update()) {
assert(missing.is_missing(hoid) && missing.missing[hoid].need == objiter->second->version);
} else {
assert(!missing.is_missing(hoid));
}
missing.revise_have(hoid, eversion_t());
if (rollbacker && !object_not_in_store)
rollbacker->remove(hoid);
return;
}
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid <<" has no more recent entries in log" << dendl;
if (prior_version == eversion_t() || entries.front().is_clone()) {
/// Case 2)
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid << " prior_version or op type indicates creation," << " deleting" << dendl;
if (missing.is_missing(hoid))
missing.rm(missing.missing.find(hoid));
if (rollbacker && !object_not_in_store)
rollbacker->remove(hoid);
return;
}
if (missing.is_missing(hoid)) {
/// Case 3)
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid << " missing, " << missing.missing[hoid] << " adjusting" << dendl;
if (missing.missing[hoid].have == prior_version) {
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid << " missing.have is prior_version " << prior_version
<< " removing from missing" << dendl;
missing.rm(missing.missing.find(hoid));
} else {
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid << " missing.have is " << missing.missing[hoid].have
<< ", adjusting" << dendl;
missing.revise_need(hoid, prior_version);
if (prior_version <= info.log_tail) {
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid << " prior_version " << prior_version
<< " <= info.log_tail " << info.log_tail << dendl;
if (new_divergent_prior)
*new_divergent_prior = make_pair(prior_version, hoid);
}
}
return;
}
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid << " must be rolled back or recovered," << " attempting to rollback" << dendl;
bool can_rollback = true;
/// Distinguish between 4) and 5)
for (list<pg_log_entry_t>::const_reverse_iterator i = entries.rbegin();i != entries.rend();++i) {
if (!i->mod_desc.can_rollback() || i->version <= olog_can_rollback_to) {
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid << " cannot rollback "<< *i << dendl;
can_rollback = false;
break;
}
}
if (can_rollback) {
/// Case 4)
for (list<pg_log_entry_t>::const_reverse_iterator i = entries.rbegin(); i != entries.rend();++i) {
assert(i->mod_desc.can_rollback() && i->version > olog_can_rollback_to);
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid<< " rolling back " << *i << dendl;
if (rollbacker)
rollbacker->rollback(*i);
}
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid<< " rolled back" << dendl;
return;
} else {
/// Case 5)
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid << " cannot roll back, "<< "removing and adding to missing" << dendl;
if (rollbacker && !object_not_in_store)
rollbacker->remove(hoid);
missing.add(hoid, prior_version, eversion_t());
if (prior_version <= info.log_tail) {
ldpp_dout(dpp, 10) << __func__ << ": hoid " << hoid << " prior_version " << prior_version << " <= info.log_tail "
<< info.log_tail << dendl;
if (new_divergent_prior)
*new_divergent_prior = make_pair(prior_version, hoid);
}
}
}其基本处理过程如下:
1) 首先进行比较,如果处理的对象hoid大于info.last_backfill,说明该对象本来就不存在,没必要进行修复(?应该是Backfill还没有完成,直接等到下一次Backfill完成)。
注意:这种情况一般发生在如下情形 该PG在上一次Peering操作成功后,PG还没有处于clean状态,正在Backfill过程中,就再次触发了Peering的过程。info.last_backfill为上次最后一个修复的对象。
在本PG完成Peering后就开始修复,先完成Recovery操作,然后会继续完成上次的Backfill操作,所以没有必要在这里检查来修复。
2)通过该对象的日志记录来检查版本是否一致。首先确保是同一个对象,本次日志记录的版本prior_version等于上一条日志记录的version值;
3) 版本first_divergent_update为该对象的日志记录中第一个产生分歧的版本;版本last_divergent_update为最后一个产生分歧的版本;版本prior_version为第一个分歧产生的前一个版本,也就是应该存在的对象版本。布尔变量object_not_in_store用来标记该对象不存在于object store。处理分歧日志的5种情况如下所示:
情形1: 在没有分歧的日志里找到该对象,但是已存在的对象版本大于等于第一个分歧对象的版本。这种情况的出现,是由于在merge_log()中产生权威日志时的日志更新,相应的处理已经做了,这里不做任何处理;
注:此一情形应该是对应于PGLog::merge_log()中,olog.head 大于log.head
情形2: 第一条分歧日志是对象的create操作(即prior_version为eversion_t(),或者entries.front().is_clone())。此种情况下,该对象不存在,我们只需要调整missing列表与object store使两边一致即可。
注:如何调整为一致呢? 如果该object存在于missing列表,那么直接从missing列表删除即可;如果存在于object store,则删除Object store中该对象
情形3: 如果该对象已经处于missing列表中,如下进行处理:
-
如果日志记录显示当前已经拥有的该对象版本have等于prior_version,说明对象不缺失,不需要进行修复,删除missing中的记录;
-
否则,修改需要修复的版本need为prior_version;如果prior_version小于等于info.log_tail时,这是不合理的,设置new_divergent_prior用于后续处理;
情形4: 如果该对象的所有版本都可以回滚,直接通过本地回滚操作就可以修复,不需要加入missing列表来修复;
情形5: 如果不是所有的对象版本都可以回滚,删除相关的版本,把prior_version加入missing记录中用于修复。
总结:对于上面分歧日志的处理,核心的思想就是要使本PG副本达到与权威副本一致的状态。因此,需要根据不同的情形采用不同的方式来达成一致。
[参看]
