ceph peering机制再研究(8)
在上一章我们讲述到PG Primary获取到权威日志之后,会进入到GetMissing阶段。本文介绍GetMissing阶段的处理,包括日志操作以及Active操作。
1. Peering之GetMissing状态处理
GetMissing的处理过程为:首先,拉取各个从OSD上的有效日志;其次,用主OSD上的权威日志与各个从OSD的日志进行对比,从而计算出各个从OSD上不一致的对象并保存在对应的pg_missing_t结构中,作为后续数据修复的依据。
主OSD的不一致的对象信息,已经在调用函数PG::proc_master_log()合并权威日志的过程中计算出来,所以这里只计算从OSD上不一致的对象。
1.1 GetMissing状态
在GetMissing的构造函数里,通过对比主OSD上的权威pg_info信息,来获取从OSD上的日志信息。
struct GetMissing : boost::statechart::state< GetMissing, Peering >, NamedState {
set<pg_shard_t> peer_missing_requested;
explicit GetMissing(my_context ctx);
void exit();
typedef boost::mpl::list <
boost::statechart::custom_reaction< QueryState >,
boost::statechart::custom_reaction< MLogRec >,
boost::statechart::transition< NeedUpThru, WaitUpThru >
> reactions;
boost::statechart::result react(const QueryState& q);
boost::statechart::result react(const MLogRec& logevt);
};
PG::RecoveryState::GetMissing::GetMissing(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Peering/GetMissing")
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
assert(!pg->actingbackfill.empty());
for (set<pg_shard_t>::iterator i = pg->actingbackfill.begin();i != pg->actingbackfill.end();++i) {
if (*i == pg->get_primary()) continue;
const pg_info_t& pi = pg->peer_info[*i];
if (pi.is_empty())
continue; // no pg data, nothing divergent
if (pi.last_update < pg->pg_log.get_tail()) {
dout(10) << " osd." << *i << " is not contiguous, will restart backfill" << dendl;
pg->peer_missing[*i];
continue;
}
if (pi.last_backfill == hobject_t()) {
dout(10) << " osd." << *i << " will fully backfill; can infer empty missing set" << dendl;
pg->peer_missing[*i];
continue;
}
if (pi.last_update == pi.last_complete && // peer has no missing
pi.last_update == pg->info.last_update) { // peer is up to date
// replica has no missing and identical log as us. no need to
// pull anything.
// FIXME: we can do better here. if last_update==last_complete we
// can infer the rest!
dout(10) << " osd." << *i << " has no missing, identical log" << dendl;
pg->peer_missing[*i];
continue;
}
// We pull the log from the peer's last_epoch_started to ensure we
// get enough log to detect divergent updates.
eversion_t since(pi.last_epoch_started, 0);
assert(pi.last_update >= pg->info.log_tail); // or else choose_acting() did a bad thing
if (pi.log_tail <= since) {
dout(10) << " requesting log+missing since " << since << " from osd." << *i << dendl;
context< RecoveryMachine >().send_query(
*i,
pg_query_t(
pg_query_t::LOG,
i->shard, pg->pg_whoami.shard,
since, pg->info.history,
pg->get_osdmap()->get_epoch()));
} else {
dout(10) << " requesting fulllog+missing from osd." << *i
<< " (want since " << since << " < log.tail " << pi.log_tail << ")"<< dendl;
context< RecoveryMachine >().send_query(
*i,
pg_query_t(
pg_query_t::FULLLOG,
i->shard, pg->pg_whoami.shard,
pg->info.history, pg->get_osdmap()->get_epoch()));
}
peer_missing_requested.insert(*i);
pg->blocked_by.insert(i->osd);
}
if (peer_missing_requested.empty()) {
if (pg->need_up_thru) {
dout(10) << " still need up_thru update before going active" << dendl;
post_event(NeedUpThru());
return;
}
// all good!
post_event(Activate(pg->get_osdmap()->get_epoch()));
} else {
pg->publish_stats_to_osd();
}
}在GetMissing构造函数中,遍历pg->actingbackfill的OSD列表,针对每一个pg_shard_t做如下处理:
1) 不需要获取PG日志的情况
a) 如果当前副本为PG Primary,因为其已经有了完整的权威日志,因此可以直接跳过;
b) 如果pi.is_empty()为空,没有任何信息,需要Backfill过程来修复,不需要获取日志;
c) 如果pi.last_update小于pg->pg_log.get_tail(),该OSD的pg_info记录中,last_update小于权威日志的尾部记录,该OSD的日志和权威日志不重叠,该OSD操作已经远远落后于权威OSD,已经无法根据日志来修复,需要Backfill过程来修复;
d)pi.last_backfill为hobject_t(),说明在past interval期间,该OSD标记需要执行full Backfill操作,实际并没开始Backfill的工作,需要继续Backfill过程
e) pi.last_upate等于pi.last_complete,说明该PG没有丢失的对象,已经完成Recovery操作阶段,并且pi.last_update等于pg->info.last_update,说明该OSD的日志和权威日志的最后更新一致,说明该PG副本数据完整,不需要恢复;
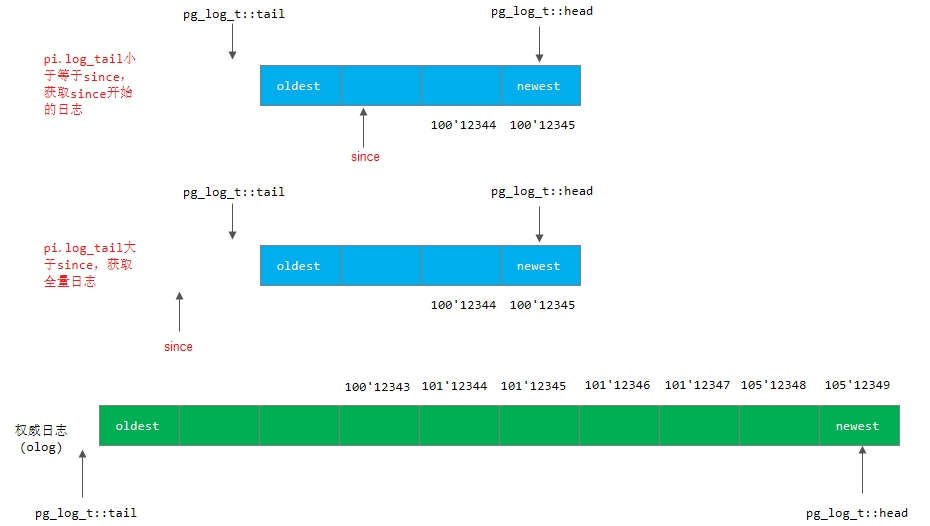
2)获取日志情况: 当pi.last_update大于等于pg->info.log_tail,该OSD的日志记录和权威日志记录重叠,可以通过日志来修复。变量since是从last_epoch_started开始的版本值:
a) 如果该PG的日志记录pi.log_tail小于等于版本值since,那就发送消息pg_query_t::LOG,从since开始获取日志记录;
b) 如果该PG的日志记录pi.log_tail大于版本值since,就发送消息pg_query_t::FULLLOG来获取该OSD的全部日志记录。
注:这里我们只需要发送last_epoch_started之后的日志就可以,因为last_epoch_started之前的日志一定是达成一致的。
3) 最后检查如果peer_missing_requested为空,说明所有获取日志的请求返回并处理完成。如果pg->need_up_thru为true,抛出NeedUpThru事件,会进入到WaitUpThru状态;否则,直接调用post_event(Activate(pg->get_osdmap()->get_epoch()))抛出Activate事件。
下面举例说明日志的两种情况:

当前last_epoch_started的只为10,since为last_epoch_started后的首个日志版本值,当前需要恢复的有效日志是经过since操作之后的日志,之前的日志已经没有用了。
对应osd0,其日志log_tail大于since,全部拷贝osd0上的日志;对应osd1,其日志log_tail小于since,只拷贝从since开始的日志记录。
1.2 获取副本日志流程
下面我们给出PG Primary获取副本日志的调用流程:

1.3 PG Primary收到从副本上的日志处理
当一个PG的主OSD接收到从OSD返回的获取日志ACK应答后,就把该消息封装成MLogRec事件。状态GetMissing接收到该事件后,在下列事件函数里处理该事件:
boost::statechart::result PG::RecoveryState::GetMissing::react(const MLogRec& logevt)
{
PG *pg = context< RecoveryMachine >().pg;
peer_missing_requested.erase(logevt.from);
pg->proc_replica_log(*context<RecoveryMachine>().get_cur_transaction(),
logevt.msg->info, logevt.msg->log, logevt.msg->missing, logevt.from);
if (peer_missing_requested.empty()) {
if (pg->need_up_thru) {
dout(10) << " still need up_thru update before going active" << dendl;
post_event(NeedUpThru());
} else {
dout(10) << "Got last missing, don't need missing "<< "posting CheckRepops" << dendl;
post_event(Activate(pg->get_osdmap()->get_epoch()));
}
}
return discard_event();
}具体处理过程如下:
1) 调用PG::proc_replica_log()处理日志。通过日志的对比,获取该OSD上处于missing状态的对象列表;
2) 如果peer_missing_requested为空,即所有的获取日志请求返回并处理。如果pg->need_up_thru为true,那么抛出NeedUpThru()事件;否则,直接调用函数post_event(Activate(pg->get_osdmap()->get_epoch()))进入Activate流程。
注:logevt.msg->missing是从OSD进行PG加载时自己发现所缺失的对象
PG::proc_replica_log()函数
下面我们来看PG::proc_replica_log()函数的具体实现:
void PG::proc_replica_log(
ObjectStore::Transaction& t,
pg_info_t &oinfo, pg_log_t &olog, pg_missing_t& omissing,
pg_shard_t from)
{
dout(10) << "proc_replica_log for osd." << from << ": "<< oinfo << " " << olog << " " << omissing << dendl;
pg_log.proc_replica_log(t, oinfo, olog, omissing, from);
peer_info[from] = oinfo;
dout(10) << " peer osd." << from << " now " << oinfo << " " << omissing << dendl;
might_have_unfound.insert(from);
for (map<hobject_t, pg_missing_t::item, hobject_t::ComparatorWithDefault>::iterator i = omissing.missing.begin();
i != omissing.missing.end();++i) {
dout(20) << " after missing " << i->first << " need " << i->second.need<< " have " << i->second.have << dendl;
}
peer_missing[from].swap(omissing);
}从上面可以看到,其实际是调用PGLog::proc_replica_log()来进行处理:它通过比较该OSD的日志和本地权威日志,来计算该OSD上处于missing状态的对象列表。下面我们来看该函数的是实现:
void PGLog::proc_replica_log(
ObjectStore::Transaction& t,
pg_info_t &oinfo, const pg_log_t &olog, pg_missing_t& omissing,
pg_shard_t from) const
{
dout(10) << "proc_replica_log for osd." << from << ": "<< oinfo << " " << olog << " " << omissing << dendl;
if (olog.head < log.tail) {
dout(10) << __func__ << ": osd." << from << " does not overlap, not looking "<< "for divergent objects" << dendl;
return;
}
if (olog.head == log.head) {
dout(10) << __func__ << ": osd." << from << " same log head, not looking "<< "for divergent objects" << dendl;
return;
}
assert(olog.head >= log.tail);
/*
basically what we're doing here is rewinding the remote log,
dropping divergent entries, until we find something that matches
our master log. we then reset last_update to reflect the new
point up to which missing is accurate.
later, in activate(), missing will get wound forward again and
we will send the peer enough log to arrive at the same state.
*/
for (map<hobject_t, pg_missing_t::item, hobject_t::BitwiseComparator>::iterator i = omissing.missing.begin();
i != omissing.missing.end();++i) {
dout(20) << " before missing " << i->first << " need " << i->second.need<< " have " << i->second.have << dendl;
}
list<pg_log_entry_t>::const_reverse_iterator first_non_divergent =log.log.rbegin();
while (1) {
if (first_non_divergent == log.log.rend())
break;
if (first_non_divergent->version <= olog.head) {
dout(20) << "merge_log point (usually last shared) is "<< *first_non_divergent << dendl;
break;
}
++first_non_divergent;
}
/* Because olog.head >= log.tail, we know that both pgs must at least have
* the event represented by log.tail. Thus, lower_bound >= log.tail. It's
* possible that olog/log contain no actual events between olog.head and
* log.tail, however, since they might have been split out. Thus, if
* we cannot find an event e such that log.tail <= e.version <= log.head,
* the last_update must actually be log.tail.
*/
eversion_t lu = (first_non_divergent == log.log.rend() || first_non_divergent->version < log.tail) ?
log.tail :first_non_divergent->version;
list<pg_log_entry_t> divergent;
list<pg_log_entry_t>::const_iterator pp = olog.log.end();
while (true) {
if (pp == olog.log.begin())
break;
--pp;
const pg_log_entry_t& oe = *pp;
// don't continue past the tail of our log.
if (oe.version <= log.tail) {
++pp;
break;
}
if (oe.version <= lu) {
++pp;
break;
}
divergent.push_front(oe);
}
IndexedLog folog;
folog.log.insert(folog.log.begin(), olog.log.begin(), pp);
folog.index();
_merge_divergent_entries(
folog,
divergent,
oinfo,
olog.can_rollback_to,
omissing,
0,
0,
this);
if (lu < oinfo.last_update) {
dout(10) << " peer osd." << from << " last_update now " << lu << dendl;
oinfo.last_update = lu;
}
if (omissing.have_missing()) {
eversion_t first_missing = omissing.missing[omissing.rmissing.begin()->second].need;
oinfo.last_complete = eversion_t();
list<pg_log_entry_t>::const_iterator i = olog.log.begin();
for (;i != olog.log.end();++i) {
if (i->version < first_missing)
oinfo.last_complete = i->version;
else
break;
}
} else {
oinfo.last_complete = oinfo.last_update;
}
}PGLog::proc_replica_log()所做的事情基本上是:rewind从OSD日志、drop分歧的日志条目,从而与权威日志达成一致。之后更新该从OSD的peer_info.last_update以精确的反应该从OSD所丢失的对象。
之后在PG::activate()函数中,missing将再次向前推进,我们将向Peer发送足够的日志信息,从而使各个副本达成一致。
下面我们来看具体的处理流程:
1) 如果从OSD的日志olog.head小于当前权威日志log.tail,没有日志重叠,不能处理此种情况,直接返回;
2) 如果从OSD的日志olog.head等于当前权威日志log.head,说明没有分歧对象,直接返回;
3) 从后往前遍历当前的权威日志log,与从OSD的olog进行对比,从而找出第一条非分歧日志(first_none_divergent);
void PGLog::proc_replica_log(
ObjectStore::Transaction& t,
pg_info_t &oinfo, const pg_log_t &olog, pg_missing_t& omissing,
pg_shard_t from) const
{
...
list<pg_log_entry_t>::const_reverse_iterator first_non_divergent =log.log.rbegin();
while (1) {
if (first_non_divergent == log.log.rend())
break;
if (first_non_divergent->version <= olog.head) {
dout(20) << "merge_log point (usually last shared) is "<< *first_non_divergent << dendl;
break;
}
++first_non_divergent;
}
/* Because olog.head >= log.tail, we know that both pgs must at least have
* the event represented by log.tail. Thus, lower_bound >= log.tail. It's
* possible that olog/log contain no actual events between olog.head and
* log.tail, however, since they might have been split out. Thus, if
* we cannot find an event e such that log.tail <= e.version <= log.head,
* the last_update must actually be log.tail.
*/
eversion_t lu = (first_non_divergent == log.log.rend() || first_non_divergent->version < log.tail) ?
log.tail :first_non_divergent->version;
...
}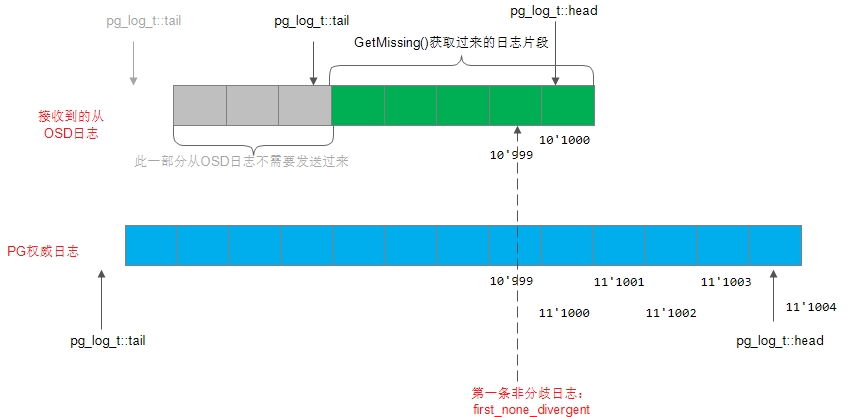
注:上面的lu为该从OSD在合并权威日志后,其应该对应的last_update值
4) 找出分歧日志,并将分歧日志加入到divergent列表中
void PGLog::proc_replica_log(
ObjectStore::Transaction& t,
pg_info_t &oinfo, const pg_log_t &olog, pg_missing_t& omissing,
pg_shard_t from) const
{
…
list<pg_log_entry_t> divergent;
list<pg_log_entry_t>::const_iterator pp = olog.log.end();
while (true) {
if (pp == olog.log.begin())
break;
--pp;
const pg_log_entry_t& oe = *pp;
// don't continue past the tail of our log.
if (oe.version <= log.tail) {
++pp;
break;
}
if (oe.version <= lu) {
++pp;
break;
}
divergent.push_front(oe);
}
... }
4) 把接收到的从OSD的日志中的非分歧部分构造成IndexedLog,之后调用_merge_divergent_entries()来继续处理 void PGLog::proc_replica_log( ObjectStore::Transaction& t, pg_info_t &oinfo, const pg_log_t &olog, pg_missing_t& omissing, pg_shard_t from) const { … IndexedLog folog; folog.log.insert(folog.log.begin(), olog.log.begin(), pp); folog.index(); _merge_divergent_entries( folog, divergent, oinfo, olog.can_rollback_to, omissing, 0, 0, this);
if (lu < oinfo.last_update) {
dout(10) << " peer osd." << from << " last_update now " << lu << dendl;
oinfo.last_update = lu;
}
.... } 关于_merge_divergent_entries()我们前面已经介绍过,其会构造出一个missing对象列表,存放于参数omissing中;之后可能还需要修正oinfo.last_update值;
5) 如果合并日志后,发现从OSD的omissing不为空,那么说明该从OSD有对象丢失,可能需要修正oinfo.last_complete的值;否则,说明该OSD没有对象丢失,直接将oinfo.last_complete更新为oinfo.last_update。
2. activate操作
由上可知,如果GetMissing()处理成功,就会抛出Activate()事件,从而执行activate流程。进行到本阶段为止,可以说Peering主要工作已经完成,剩下的后续流程就是激活各个副本。搜索Activate,我们发现如下几个地方会处理该事件:
-
ReplicaActive状态下处理Activate事件
-
Peering状态下收到Activate事件直接跳转到Active状态
struct Peering : boost::statechart::state< Peering, Primary, GetInfo >, NamedState {
...
typedef boost::mpl::list <
boost::statechart::custom_reaction< QueryState >,
boost::statechart::transition< Activate, Active >,
boost::statechart::custom_reaction< AdvMap >
> reactions;
};这里对于PG Primary来说,就是跳转到Active状态。我们来看Active状态构造函数的实现:
/*---------Active---------*/
PG::RecoveryState::Active::Active(my_context ctx)
: my_base(ctx),
NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Active"),
remote_shards_to_reserve_recovery(
unique_osd_shard_set(
context< RecoveryMachine >().pg->pg_whoami,
context< RecoveryMachine >().pg->actingbackfill)),
remote_shards_to_reserve_backfill(
unique_osd_shard_set(
context< RecoveryMachine >().pg->pg_whoami,
context< RecoveryMachine >().pg->backfill_targets)),
all_replicas_activated(false)
{
context< RecoveryMachine >().log_enter(state_name);
PG *pg = context< RecoveryMachine >().pg;
assert(!pg->backfill_reserving);
assert(!pg->backfill_reserved);
assert(pg->is_primary());
dout(10) << "In Active, about to call activate" << dendl;
pg->start_flush(
context< RecoveryMachine >().get_cur_transaction(),
context< RecoveryMachine >().get_on_applied_context_list(),
context< RecoveryMachine >().get_on_safe_context_list());
pg->activate(*context< RecoveryMachine >().get_cur_transaction(),
pg->get_osdmap()->get_epoch(),
*context< RecoveryMachine >().get_on_safe_context_list(),
*context< RecoveryMachine >().get_query_map(),
context< RecoveryMachine >().get_info_map(),
context< RecoveryMachine >().get_recovery_ctx());
// everyone has to commit/ack before we are truly active
pg->blocked_by.clear();
for (set<pg_shard_t>::iterator p = pg->actingbackfill.begin();p != pg->actingbackfill.end();++p) {
if (p->shard != pg->pg_whoami.shard) {
pg->blocked_by.insert(p->shard);
}
}
pg->publish_stats_to_osd();
dout(10) << "Activate Finished" << dendl;
}在状态Active的构造函数里,其处理过程如下:
1) 在构造函数里初始化了remote_shards_to_reserve_recovery和remote_shards_to_reserve_backfill,即需要Recovery操作和Backfill操作的OSD;
2)调用函数PG::start_flush()来完成相关数据的flush工作;
3)调用函数PG::activate()完成最后的激活工作;
2.1 MissingLoc
在讲解PG::activate()函数之前,我们先介绍类MissingLoc。MissingLoc用来记录missing状态对象的位置,也就是缺失对象的正确版本分布在哪些OSD上。恢复这些时,就去这些OSD上去拉取正确对象的数据:
class MissingLoc {
map<hobject_t, pg_missing_t::item, hobject_t::BitwiseComparator> needs_recovery_map;
map<hobject_t, set<pg_shard_t>, hobject_t::BitwiseComparator > missing_loc;
set<pg_shard_t> missing_loc_sources;
PG *pg;
set<pg_shard_t> empty_set;
public:
boost::scoped_ptr<IsPGReadablePredicate> is_readable;
boost::scoped_ptr<IsPGRecoverablePredicate> is_recoverable;
};下面介绍一下各字段的含义:
-
needs_recovery_map: 需要进行recovery操作的对象列表。key为缺失的对象,value为item(缺失版本,现在版本)
-
missing_loc: 缺失对象的正确版本在哪些OSD上
-
missing_loc_source: 所有缺失对象所在的OSD集合
下面介绍一些MissingLoc的处理函数:
2.1.1 MissingLoc::add_active_missing()
void add_active_missing(const pg_missing_t &missing) {
for (map<hobject_t, pg_missing_t::item, hobject_t::BitwiseComparator>::const_iterator i =missing.missing.begin();
i != missing.missing.end(); ++i) {
map<hobject_t, pg_missing_t::item, hobject_t::BitwiseComparator>::const_iterator j =
needs_recovery_map.find(i->first);
if (j == needs_recovery_map.end()) {
needs_recovery_map.insert(*i);
} else {
assert(i->second.need == j->second.need);
}
}
}add_active_missing()函数的作用是把参数missing中的缺失对象添加到MissingLoc的needs_recovery_map里。
2.1.2 MissingLoc::add_source_info()
bool PG::MissingLoc::add_source_info(
pg_shard_t fromosd,
const pg_info_t &oinfo,
const pg_missing_t &omissing,
bool sort_bitwise,
ThreadPool::TPHandle* handle)
{
bool found_missing = false;
unsigned loop = 0;
// found items?
for (map<hobject_t,pg_missing_t::item, hobject_t::ComparatorWithDefault>::const_iterator p = needs_recovery_map.begin();
p != needs_recovery_map.end();++p) {
const hobject_t &soid(p->first);
eversion_t need = p->second.need;
if (handle && ++loop >= g_conf->osd_loop_before_reset_tphandle) {
handle->reset_tp_timeout();
loop = 0;
}
if (oinfo.last_update < need) {
dout(10) << "search_for_missing " << soid << " " << need<< " also missing on osd." << fromosd
<< " (last_update " << oinfo.last_update << " < needed " << need << ")"<< dendl;
continue;
}
if (!oinfo.last_backfill.is_max() && oinfo.last_backfill_bitwise != sort_bitwise) {
dout(10) << "search_for_missing " << soid << " " << need << " also missing on osd." << fromosd
<< " (last_backfill " << oinfo.last_backfill << " but with wrong sort order)" << dendl;
continue;
}
if (cmp(p->first, oinfo.last_backfill, sort_bitwise) >= 0) {
// FIXME: this is _probably_ true, although it could conceivably
// be in the undefined region! Hmm!
dout(10) << "search_for_missing " << soid << " " << need << " also missing on osd." << fromosd
<< " (past last_backfill " << oinfo.last_backfill << ")" << dendl;
continue;
}
if (oinfo.last_complete < need) {
if (omissing.is_missing(soid)) {
dout(10) << "search_for_missing " << soid << " " << need << " also missing on osd." << fromosd << dendl;
continue;
}
}
dout(10) << "search_for_missing " << soid << " " << need << " is on osd." << fromosd << dendl;
missing_loc[soid].insert(fromosd);
missing_loc_sources.insert(fromosd);
found_missing = true;
}
dout(20) << "needs_recovery_map missing " << needs_recovery_map << dendl;
return found_missing;
}add_source_info()函数用于计算每个缺失的对象是否在参数(fromosd)指定的OSD上。下面我们来看具体实现:
遍历MissingLoc::needs_recovery_map里的所有对象,对每个对象做如下处理:
1) 如果oinfo.last_update小于need(所需的缺失对象版本),直接跳过;
2) 如果该PG副本的last_backfill指针小于MAX值,说明还处于Backfill阶段,但是sort_bitwise不正确,跳过;
3) 如果该对象大于等于last_backfill,显然该对象不存在,跳过;
4) 如果该对象大于last_complete,说明该对象或者是上次Peering之后缺失的对象,还没来得及修复;或者是新创建的对象。检查如果在missing记录已经存在,就是上次缺失的对象;否则就是新创建的对象,存在该OSD中
5) 经过上述检查后,确认该对象在参数(fromosd)指定的OSD上,在MissingLoc::missing_loc中添加该对象的location为fromosd。
2.1.3 PG::search_for_missing()
/*
* Process information from a replica to determine if it could have any
* objects that i need.
*
* TODO: if the missing set becomes very large, this could get expensive.
* Instead, we probably want to just iterate over our unfound set.
*/
bool PG::search_for_missing(
const pg_info_t &oinfo, const pg_missing_t &omissing,
pg_shard_t from,
RecoveryCtx *ctx)
{
unsigned num_unfound_before = missing_loc.num_unfound();
bool found_missing = missing_loc.add_source_info(from, oinfo, omissing, get_sort_bitwise(), ctx->handle);
if (found_missing && num_unfound_before != missing_loc.num_unfound())
publish_stats_to_osd();
if (found_missing && (get_osdmap()->get_features(CEPH_ENTITY_TYPE_OSD, NULL) & CEPH_FEATURE_OSD_ERASURE_CODES)) {
pg_info_t tinfo(oinfo);
tinfo.pgid.shard = pg_whoami.shard;
(*(ctx->info_map))[from.osd].push_back(
make_pair(
pg_notify_t(
from.shard, pg_whoami.shard,
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
tinfo),
past_intervals));
}
return found_missing;
}PG::search_for_missing()其实就是调用MissingLoc::add_source_info()函数,检查副本from是否有我们当前所缺失的对象。
2.2 PG::activate()操作
PG::activate()函数是Peering过程的最后一步,该函数完成以下功能:
-
更新一些pg_info的参数信息
-
给replica发消息,激活副本PG;
-
计算MissingLoc,也就是缺失对象分布在哪些OSD上,用于后续的恢复
void PG::activate(ObjectStore::Transaction& t,
epoch_t activation_epoch,
list<Context*>& tfin,
map<int, map<spg_t,pg_query_t> >& query_map,
map<int,
vector<
pair<pg_notify_t,
pg_interval_map_t> > > *activator_map,
RecoveryCtx *ctx)
{
assert(!is_peered());
assert(scrubber.callbacks.empty());
assert(callbacks_for_degraded_object.empty());
// -- crash recovery?
if (acting.size() >= pool.info.min_size && is_primary() && pool.info.crash_replay_interval > 0 &&
may_need_replay(get_osdmap())) {
replay_until = ceph_clock_now(cct);
replay_until += pool.info.crash_replay_interval;
dout(10) << "activate starting replay interval for " << pool.info.crash_replay_interval << " until " << replay_until << dendl;
state_set(PG_STATE_REPLAY);
// TODOSAM: osd->osd-> is no good
osd->osd->replay_queue_lock.Lock();
osd->osd->replay_queue.push_back(pair<spg_t,utime_t>(info.pgid, replay_until));
osd->osd->replay_queue_lock.Unlock();
}
// twiddle pg state
state_clear(PG_STATE_DOWN);
send_notify = false;
if (is_primary()) {
// only update primary last_epoch_started if we will go active
if (acting.size() >= pool.info.min_size) {
assert(cct->_conf->osd_find_best_info_ignore_history_les || info.last_epoch_started <= activation_epoch);
info.last_epoch_started = activation_epoch;
}
} else if (is_acting(pg_whoami)) {
/* update last_epoch_started on acting replica to whatever the primary sent
* unless it's smaller (could happen if we are going peered rather than
* active, see doc/dev/osd_internals/last_epoch_started.rst) */
if (info.last_epoch_started < activation_epoch)
info.last_epoch_started = activation_epoch;
}
const pg_missing_t &missing = pg_log.get_missing();
if (is_primary()) {
last_update_ondisk = info.last_update;
min_last_complete_ondisk = eversion_t(0,0); // we don't know (yet)!
}
last_update_applied = info.last_update;
last_rollback_info_trimmed_to_applied = pg_log.get_rollback_trimmed_to();
need_up_thru = false;
// write pg info, log
dirty_info = true;
dirty_big_info = true; // maybe
// find out when we commit
t.register_on_complete(
new C_PG_ActivateCommitted(this,get_osdmap()->get_epoch(),activation_epoch));
// initialize snap_trimq
if (is_primary()) {
dout(20) << "activate - purged_snaps " << info.purged_snaps << " cached_removed_snaps " << pool.cached_removed_snaps << dendl;
snap_trimq = pool.cached_removed_snaps;
interval_set<snapid_t> intersection;
intersection.intersection_of(snap_trimq, info.purged_snaps);
if (intersection == info.purged_snaps) {
snap_trimq.subtract(info.purged_snaps);
} else {
dout(0) << "warning: info.purged_snaps (" << info.purged_snaps << ") is not a subset of pool.cached_removed_snaps ("
<< pool.cached_removed_snaps << ")" << dendl;
snap_trimq.subtract(intersection);
}
dout(10) << "activate - snap_trimq " << snap_trimq << dendl;
if (!snap_trimq.empty() && is_clean())
queue_snap_trim();
}
// init complete pointer
if (missing.num_missing() == 0) {
dout(10) << "activate - no missing, moving last_complete " << info.last_complete << " -> " << info.last_update << dendl;
info.last_complete = info.last_update;
pg_log.reset_recovery_pointers();
} else {
dout(10) << "activate - not complete, " << missing << dendl;
pg_log.activate_not_complete(info);
}
log_weirdness();
// if primary..
if (is_primary()) {
assert(ctx);
// start up replicas
assert(!actingbackfill.empty());
for (set<pg_shard_t>::iterator i = actingbackfill.begin(); i != actingbackfill.end(); ++i) {
if (*i == pg_whoami) continue;
pg_shard_t peer = *i;
assert(peer_info.count(peer));
pg_info_t& pi = peer_info[peer];
dout(10) << "activate peer osd." << peer << " " << pi << dendl;
MOSDPGLog *m = 0;
pg_missing_t& pm = peer_missing[peer];
bool needs_past_intervals = pi.dne();
/*
* cover case where peer sort order was different and
* last_backfill cannot be interpreted
*/
bool force_restart_backfill = !pi.last_backfill.is_max() && pi.last_backfill_bitwise != get_sort_bitwise();
if (pi.last_update == info.last_update && !force_restart_backfill) {
// empty log
if (!pi.last_backfill.is_max())
osd->clog->info() << info.pgid << " continuing backfill to osd." << peer
<< " from (" << pi.log_tail << "," << pi.last_update << "] " << pi.last_backfill << " to " << info.last_update;
if (!pi.is_empty() && activator_map) {
dout(10) << "activate peer osd." << peer << " is up to date, queueing in pending_activators" << dendl;
(*activator_map)[peer.osd].push_back(
make_pair(
pg_notify_t(
peer.shard, pg_whoami.shard,
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
info),
past_intervals));
} else {
dout(10) << "activate peer osd." << peer << " is up to date, but sending pg_log anyway" << dendl;
m = new MOSDPGLog(i->shard, pg_whoami.shard,get_osdmap()->get_epoch(), info);
}
} else if ( pg_log.get_tail() > pi.last_update || pi.last_backfill == hobject_t() ||
force_restart_backfill || (backfill_targets.count(*i) && pi.last_backfill.is_max())) {
/* ^ This last case covers a situation where a replica is not contiguous
* with the auth_log, but is contiguous with this replica. Reshuffling
* the active set to handle this would be tricky, so instead we just go
* ahead and backfill it anyway. This is probably preferrable in any
* case since the replica in question would have to be significantly
* behind.
*/
// backfill
osd->clog->info() << info.pgid << " starting backfill to osd." << peer << " from (" << pi.log_tail << "," << pi.last_update
<< "] " << pi.last_backfill << " to " << info.last_update;
pi.last_update = info.last_update;
pi.last_complete = info.last_update;
pi.set_last_backfill(hobject_t(), get_sort_bitwise());
pi.last_epoch_started = info.last_epoch_started;
pi.history = info.history;
pi.hit_set = info.hit_set;
pi.stats.stats.clear();
// initialize peer with our purged_snaps.
pi.purged_snaps = info.purged_snaps;
m = new MOSDPGLog(i->shard, pg_whoami.shard,get_osdmap()->get_epoch(), pi);
// send some recent log, so that op dup detection works well.
m->log.copy_up_to(pg_log.get_log(), cct->_conf->osd_min_pg_log_entries);
m->info.log_tail = m->log.tail;
pi.log_tail = m->log.tail; // sigh...
pm.clear();
} else {
// catch up
assert(pg_log.get_tail() <= pi.last_update);
m = new MOSDPGLog(i->shard, pg_whoami.shard,get_osdmap()->get_epoch(), info);
// send new stuff to append to replicas log
m->log.copy_after(pg_log.get_log(), pi.last_update);
}
// share past_intervals if we are creating the pg on the replica
// based on whether our info for that peer was dne() *before*
// updating pi.history in the backfill block above.
if (needs_past_intervals)
m->past_intervals = past_intervals;
// update local version of peer's missing list!
if (m && pi.last_backfill != hobject_t()) {
for (list<pg_log_entry_t>::iterator p = m->log.log.begin();p != m->log.log.end();++p)
if (cmp(p->soid, pi.last_backfill, get_sort_bitwise()) <= 0)
pm.add_next_event(*p);
}
if (m) {
dout(10) << "activate peer osd." << peer << " sending " << m->log << dendl;
//m->log.print(cout);
osd->send_message_osd_cluster(peer.osd, m, get_osdmap()->get_epoch());
}
// peer now has
pi.last_update = info.last_update;
// update our missing
if (pm.num_missing() == 0) {
pi.last_complete = pi.last_update;
dout(10) << "activate peer osd." << peer << " " << pi << " uptodate" << dendl;
} else {
dout(10) << "activate peer osd." << peer << " " << pi << " missing " << pm << dendl;
}
}
// Set up missing_loc
set<pg_shard_t> complete_shards;
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
if (*i == get_primary()) {
missing_loc.add_active_missing(missing);
if (!missing.have_missing())
complete_shards.insert(*i);
} else {
assert(peer_missing.count(*i));
missing_loc.add_active_missing(peer_missing[*i]);
if (!peer_missing[*i].have_missing() && peer_info[*i].last_backfill.is_max())
complete_shards.insert(*i);
}
}
// If necessary, create might_have_unfound to help us find our unfound objects.
// NOTE: It's important that we build might_have_unfound before trimming the
// past intervals.
might_have_unfound.clear();
if (needs_recovery()) {
// If only one shard has missing, we do a trick to add all others as recovery
// source, this is considered safe since the PGLogs have been merged locally,
// and covers vast majority of the use cases, like one OSD/host is down for
// a while for hardware repairing
if (complete_shards.size() + 1 == actingbackfill.size()) {
missing_loc.add_batch_sources_info(complete_shards, ctx->handle);
} else {
missing_loc.add_source_info(pg_whoami, info, pg_log.get_missing(),get_sort_bitwise(), ctx->handle);
for (set<pg_shard_t>::iterator i = actingbackfill.begin(); i != actingbackfill.end(); ++i) {
if (*i == pg_whoami) continue;
dout(10) << __func__ << ": adding " << *i << " as a source" << dendl;
assert(peer_missing.count(*i));
assert(peer_info.count(*i));
missing_loc.add_source_info(
*i,
peer_info[*i],
peer_missing[*i],
get_sort_bitwise(),
ctx->handle);
}
}
for (map<pg_shard_t, pg_missing_t>::iterator i = peer_missing.begin(); i != peer_missing.end(); ++i) {
if (is_actingbackfill(i->first))
continue;
assert(peer_info.count(i->first));
search_for_missing(
peer_info[i->first],
i->second,
i->first,
ctx);
}
build_might_have_unfound();
state_set(PG_STATE_DEGRADED);
dout(10) << "activate - starting recovery" << dendl;
osd->queue_for_recovery(this);
if (have_unfound())
discover_all_missing(query_map);
}
// degraded?
if (get_osdmap()->get_pg_size(info.pgid.pgid) > actingset.size()) {
state_set(PG_STATE_DEGRADED);
state_set(PG_STATE_UNDERSIZED);
}
state_set(PG_STATE_ACTIVATING);
}
}我们来看具体的处理流程:
1) 如果PG在上一个Interval时的所有OSD副本在当前interval(current interval)下均崩溃了,说明时崩溃恢复场景。此时,如果需要客户回答,就把PG添加到replay_queue队列里;
2)更新info.last_epoch_started变量。info.last_epoch_started指的是PG的当前OSD副本在完成目前Peering进程后的更新;而info.history.last_epoch_started是PG的所有OSD副本都确认完成Peering的更新;
3) 更新一些相关的字段
4) 注册C_PG_ActivateCommitted回调函数,该函数最终完成activate的工作
注:对于PG Primary来说,其也要激活本身,当transaction完成回调C_PG_ActivateCommitted,就表示PG Primary激活完成;对于PG Replicas而言,其同样会调用PG::activate(),然后注册C_PG_ActivateCommitted回调函数,在该副本激活完成,就会在该回调函数中向PG Primary报告本副本激活情况。
5) 初始化snap_trimq快照相关的变量;
6)设置info.last_complete指针:
-
如果missing.num_missing()等于0,表明处于clean状态。直接更新info.last_complete等于info.last_update,并调用pg_log.reset_recovery_pointers()调整log的complete_to指针;
-
否则,如果有需要恢复的对象,就调用函数pg_log.activate_not_complete(info),设置info.last_complete为缺失的第一个对象的前一版本;
7)以下都是主OSD的操作,给每个从OSD发送MOSDPGLog类型的消息,激活该PG的从OSD上的副本。分别对应三种不同处理:
-
如果pi.last_update等于info.last_update,且不需要执行backfill,这种情况下,该OSD本身就是clean的,不需要给该OSD发送其他信息。添加到activator_map只发送pg_info来激活从OSD。其最终的执行是在PeeringWQ的线程函数OSD::process_peering_events()执行完状态机的事件处理后,在函数OSD::dispatch_context()里调用OSD::do_infos()函数实现;
-
对于需要backfill操作的OSD,发送pg_info,以及osd_min_pg_log_entries数量的PG日志
-
对于需要Recovery操作的OSD,发送pg_info,以及从OSD所缺失的日志
之后调用OSD::send_message_osd_cluster()将MOSDPGLog消息发送给从OSD
8)设置MissingLoc,也就是统计缺失的对象,以及缺失对象所在的OSD(即恢复时可以从哪些OSD上找到),核心就是调用MissingLoc::add_source_info()函数,见上面的MissingLoc分析
void PG::activate(ObjectStore::Transaction& t,
epoch_t activation_epoch,
list<Context*>& tfin,
map<int, map<spg_t,pg_query_t> >& query_map,
map<int,
vector<
pair<pg_notify_t,
pg_interval_map_t> > > *activator_map,
RecoveryCtx *ctx)
{
...
if(is_primary()){
...
// Set up missing_loc
set<pg_shard_t> complete_shards;
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
if (*i == get_primary()) {
missing_loc.add_active_missing(missing);
if (!missing.have_missing())
complete_shards.insert(*i);
} else {
assert(peer_missing.count(*i));
missing_loc.add_active_missing(peer_missing[*i]);
if (!peer_missing[*i].have_missing() && peer_info[*i].last_backfill.is_max())
complete_shards.insert(*i);
}
}
}
}9) 如果有任何一个副本需要恢复,把该PG加入到osd->queue_for_recovery(this)队列中
void PG::activate(ObjectStore::Transaction& t,
epoch_t activation_epoch,
list<Context*>& tfin,
map<int, map<spg_t,pg_query_t> >& query_map,
map<int,
vector<
pair<pg_notify_t,
pg_interval_map_t> > > *activator_map,
RecoveryCtx *ctx)
{
...
if(is_primary()){
...
if (needs_recovery()) {
// If only one shard has missing, we do a trick to add all others as recovery
// source, this is considered safe since the PGLogs have been merged locally,
// and covers vast majority of the use cases, like one OSD/host is down for
// a while for hardware repairing
if (complete_shards.size() + 1 == actingbackfill.size()) {
missing_loc.add_batch_sources_info(complete_shards, ctx->handle);
} else {
missing_loc.add_source_info(pg_whoami, info, pg_log.get_missing(),get_sort_bitwise(), ctx->handle);
for (set<pg_shard_t>::iterator i = actingbackfill.begin(); i != actingbackfill.end(); ++i) {
if (*i == pg_whoami) continue;
dout(10) << __func__ << ": adding " << *i << " as a source" << dendl;
assert(peer_missing.count(*i));
assert(peer_info.count(*i));
missing_loc.add_source_info(
*i,
peer_info[*i],
peer_missing[*i],
get_sort_bitwise(),
ctx->handle);
}
}
for (map<pg_shard_t, pg_missing_t>::iterator i = peer_missing.begin(); i != peer_missing.end(); ++i) {
if (is_actingbackfill(i->first))
continue;
assert(peer_info.count(i->first));
search_for_missing(
peer_info[i->first],
i->second,
i->first,
ctx);
}
build_might_have_unfound();
state_set(PG_STATE_DEGRADED);
dout(10) << "activate - starting recovery" << dendl;
osd->queue_for_recovery(this);
if (have_unfound())
discover_all_missing(query_map);
}
}
}注:complete_shards就是不需要进行recovery操作的PG副本集合
这里计算每一个PG副本(包括PG Primary、PG Replicas)所缺失的对象可以从哪些OSD来恢复时,来用了一点小小的技巧:假如只有一个副本有object丢失,则直接调用MissingLoc::add_batch_sources_info()来批量添加,即可以直接从其他所有副本中恢复missing objects;否则,调用MissingLoc::add_source_info()将PG Primary本身以及其他PG Replicas都添加到MissingLoc中。
之后,调用PG::search_for_missing()来检查peer_missing列表中的OSD是否有我们想要的object。
之后,调用PG::build_might_have_unfound()来构建PG::might_have_unfound集合,即我们当前所缺失的对象有可能在哪些OSD上能够找到。
之后,再调用OSD::queue_for_recovery(this)将当前PG添加到恢复队列中。
最后,假如PG Primary上仍然还有一些对象找不到,调用PG::discovery_all_missing()来在might_have_unfound集合中查找。
10)如果PG当前actingset的size小于该PG在当前OSDMap中的副本数,也就是当前的OSD不够,就标记PG的状态为PG_STATE_DEGRADED和PG_STATE_UNDERSIZED,最后标记PG为PG_STATE_ACTIVATING状态。
2.3 激活流程
在上面我们讲到PG Primary会向副本发送MOSDPGInfo或MOSDPGLog消息来激活:
-
假如副本处于clean状态,通过OSD::do_infos()发送MOSDPGInfo消息
-
否则,通过OSD::send_message_osd_cluster()来向副本发送MOSDPGLog消息
这里我们给出这一激活流程图:
1)PG Primary发送MOSDPGInfo消息到PG Replica

2) PG Primary发送MOSDPGLog消息到PG Replica

2.4 收到从OSD的MOSDPGLog的应对
当收到从OSD发送的MOSDPGLog的ACK消息后(即上面激活流程图中的MOSDPGInfo消息),触发MInfoRec事件,下面这个函数处理该事件:
boost::statechart::result PG::RecoveryState::Active::react(const MInfoRec& infoevt)
{
PG *pg = context< RecoveryMachine >().pg;
assert(pg->is_primary());
assert(!pg->actingbackfill.empty());
// don't update history (yet) if we are active and primary; the replica
// may be telling us they have activated (and committed) but we can't
// share that until _everyone_ does the same.
if (pg->is_actingbackfill(infoevt.from)) {
dout(10) << " peer osd." << infoevt.from << " activated and committed" << dendl;
pg->peer_activated.insert(infoevt.from);
pg->blocked_by.erase(infoevt.from.shard);
pg->publish_stats_to_osd();
if (pg->peer_activated.size() == pg->actingbackfill.size()) {
pg->all_activated_and_committed();
}
}
return discard_event();
}
/*
* update info.history.last_epoch_started ONLY after we and all
* replicas have activated AND committed the activate transaction
* (i.e. the peering results are stable on disk).
*/
void PG::all_activated_and_committed()
{
dout(10) << "all_activated_and_committed" << dendl;
assert(is_primary());
assert(peer_activated.size() == actingbackfill.size());
assert(!actingbackfill.empty());
assert(blocked_by.empty());
queue_peering_event(
CephPeeringEvtRef(
std::make_shared<CephPeeringEvt>(
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
AllReplicasActivated())));
}处理过程比较简单:检查该请求的源OSD在本PG的actingbackfill列表中,之后将其从PG::blocked_by中删除。最后检查,当收集到所有的从OSD发送的ACK,就调用函数PG::all_activated_and_committed()触发AllReplicasActivated事件。
对应主OSD在事务回调函数C_PG_ActivateCommitted里实现,最终调用PG::_activate_committed()加入PG::peer_activated集合里。
2.5 AllReplicasActivated事件处理
如下函数处理AllReplicasActivated事件:
boost::statechart::result PG::RecoveryState::Active::react(const AllReplicasActivated &evt)
{
PG *pg = context< RecoveryMachine >().pg;
all_replicas_activated = true;
pg->state_clear(PG_STATE_ACTIVATING);
pg->state_clear(PG_STATE_CREATING);
if (pg->acting.size() >= pg->pool.info.min_size) {
pg->state_set(PG_STATE_ACTIVE);
} else {
pg->state_set(PG_STATE_PEERED);
}
// info.last_epoch_started is set during activate()
pg->info.history.last_epoch_started = pg->info.last_epoch_started;
pg->dirty_info = true;
pg->share_pg_info();
pg->publish_stats_to_osd();
pg->check_local();
// waiters
if (pg->flushes_in_progress == 0) {
pg->requeue_ops(pg->waiting_for_peered);
}
pg->on_activate();
return discard_event();
}
void ReplicatedPG::on_activate()
{
// all clean?
if (needs_recovery()) {
dout(10) << "activate not all replicas are up-to-date, queueing recovery" << dendl;
queue_peering_event(
CephPeeringEvtRef(
std::make_shared<CephPeeringEvt>(
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
DoRecovery())));
} else if (needs_backfill()) {
dout(10) << "activate queueing backfill" << dendl;
queue_peering_event(
CephPeeringEvtRef(
std::make_shared<CephPeeringEvt>(
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
RequestBackfill())));
} else {
dout(10) << "activate all replicas clean, no recovery" << dendl;
queue_peering_event(
CephPeeringEvtRef(
std::make_shared<CephPeeringEvt>(
get_osdmap()->get_epoch(),
get_osdmap()->get_epoch(),
AllReplicasRecovered())));
}
publish_stats_to_osd();
if (!backfill_targets.empty()) {
last_backfill_started = earliest_backfill();
new_backfill = true;
assert(!last_backfill_started.is_max());
dout(5) << "on activate: bft=" << backfill_targets << " from " << last_backfill_started << dendl;
for (set<pg_shard_t>::iterator i = backfill_targets.begin(); i != backfill_targets.end(); ++i) {
dout(5) << "target shard " << *i << " from " << peer_info[*i].last_backfill << dendl;
}
}
hit_set_setup();
agent_setup();
}当所有的replica处于activated状态时,进行如下处理:
1)取消PG_STATE_ACTIVATING和PG_STATE_CREATING状态,如果该pg->acting.size()大于等于pool的min_size,设置该PG为PG_STATE_ACTIVE状态,否则设置为PG_STATE_PEERED状态。
2) ReplicatedPG::check_local()检查本地的stray对象是否都被删除;
3) 如果有读写请求在等待Peering操作完成,则把该请求添加到处理队列pg->requeue_ops(pg->waiting_for_peered)
4) 调用函数ReplicatedPG::on_activate(),如果需要Recovery操作,触发DoRecovery()事件;如果需要Backfill操作,触发RequestBackfill()事件;否则触发AllReplicasRecovered()事件。
5)初始化Cache Tier需要的hit_set对象;
5)初始化Cache Tier需要的agent对象
2.6 补充
在上面的ReplicatedPG::on_activate()中,会调用PG::needs_recovery()和PG::needs_backfill()来判断是否要执行recovery动作和backfill动作。下面我们来分别看一下这两个函数:
2.6.1 PG::needs_recovery()
bool PG::needs_recovery() const
{
assert(is_primary());
const pg_missing_t &missing = pg_log.get_missing();
if (missing.num_missing()) {
dout(10) << __func__ << " primary has " << missing.num_missing() << " missing" << dendl;
return true;
}
assert(!actingbackfill.empty());
set<pg_shard_t>::const_iterator end = actingbackfill.end();
set<pg_shard_t>::const_iterator a = actingbackfill.begin();
for (; a != end; ++a) {
if (*a == get_primary()) continue;
pg_shard_t peer = *a;
map<pg_shard_t, pg_missing_t>::const_iterator pm = peer_missing.find(peer);
if (pm == peer_missing.end()) {
dout(10) << __func__ << " osd." << peer << " doesn't have missing set"<< dendl;
continue;
}
if (pm->second.num_missing()) {
dout(10) << __func__ << " osd." << peer << " has "<< pm->second.num_missing() << " missing" << dendl;
return true;
}
}
dout(10) << __func__ << " is recovered" << dendl;
return false;
}从上面我们看到,实现也比较简单:首先判断PG Primary自身是否有missing对象,如果有则直接返回true;接着遍历actingbackfill,看PG的Replicas是否有missing对象,如果有直接返回true。
2.6.2 PG::needs_backfill()
bool PG::needs_backfill() const
{
assert(is_primary());
// We can assume that only possible osds that need backfill
// are on the backfill_targets vector nodes.
set<pg_shard_t>::const_iterator end = backfill_targets.end();
set<pg_shard_t>::const_iterator a = backfill_targets.begin();
for (; a != end; ++a) {
pg_shard_t peer = *a;
map<pg_shard_t, pg_info_t>::const_iterator pi = peer_info.find(peer);
if (!pi->second.last_backfill.is_max()) {
dout(10) << __func__ << " osd." << peer << " has last_backfill " << pi->second.last_backfill << dendl;
return true;
}
}
dout(10) << __func__ << " does not need backfill" << dendl;
return false;
}基本处理流程为:遍历PG::backfill_targets列表,发现有一个副本需要backfill,则直接返回true。
3. 副本端的状态转移
当创建PG后,根据不同的角色,如果是主OSD,PG对应的状态机就进入了Primary状态。如果不是主OSD,就进入Stray状态。
3.1 Stray状态
Stray状态有两种情况:
- 情况1: 只接收到PGInfo的处理
boost::statechart::result PG::RecoveryState::Stray::react(const MInfoRec& infoevt)
{
PG *pg = context< RecoveryMachine >().pg;
dout(10) << "got info from osd." << infoevt.from << " " << infoevt.info << dendl;
if (pg->info.last_update > infoevt.info.last_update) {
// rewind divergent log entries
ObjectStore::Transaction* t = context<RecoveryMachine>().get_cur_transaction();
pg->rewind_divergent_log(*t, infoevt.info.last_update);
pg->info.stats = infoevt.info.stats;
pg->info.hit_set = infoevt.info.hit_set;
}
assert(infoevt.info.last_update == pg->info.last_update);
assert(pg->pg_log.get_head() == pg->info.last_update);
post_event(Activate(infoevt.info.last_epoch_started));
return transit<ReplicaActive>();
}从PG接收到主PG发送的MInfoRec事件,也就是接收到主OSD发送的pg_info信息。其判断如果当前pg->info.last_update大于infoevt.info.last_update,说明当前的日志有divergent的日志,调用函数rewind_divergent_log()清理日志即可。最后抛出Activate(infoevt.info.last_epoch_started)事件,进入ReplicaActive状态。
注:上面rewind_divergent_log()只需要将相应的指针回退即可,并不需要擦除相关数据
- 情况2:接收到MOSDPGLog消息
boost::statechart::result PG::RecoveryState::Stray::react(const MLogRec& logevt)
{
PG *pg = context< RecoveryMachine >().pg;
MOSDPGLog *msg = logevt.msg.get();
dout(10) << "got info+log from osd." << logevt.from << " " << msg->info << " " << msg->log << dendl;
ObjectStore::Transaction* t = context<RecoveryMachine>().get_cur_transaction();
if (msg->info.last_backfill == hobject_t()) {
// restart backfill
pg->unreg_next_scrub();
pg->info = msg->info;
pg->reg_next_scrub();
pg->dirty_info = true;
pg->dirty_big_info = true; // maybe.
PGLogEntryHandler rollbacker;
pg->pg_log.claim_log_and_clear_rollback_info(msg->log, &rollbacker);
rollbacker.apply(pg, t);
pg->pg_log.reset_backfill();
} else {
pg->merge_log(*t, msg->info, msg->log, logevt.from);
}
assert(pg->pg_log.get_head() == pg->info.last_update);
post_event(Activate(logevt.msg->info.last_epoch_started));
return transit<ReplicaActive>();
}当从PG接收到MLogRec事件,就对应着接收到主PG发送的MOSDPGLog消息,其通知从PG执行activate操作,具体处理过程如下:
1) 如果msg->info.last_backfill为hobject_t(),则说明本副本是需要执行Backfill的OSD
2)否则就是需要执行Recovery操作的OSD,调用PG::merge_log()把主OSD发送过来的日志合并
抛出Activate(logevt.msg->info.last_epoch_started)事件,使副本转移到ReplicaActive状态。
3.2 ReplicaActive状态
对于副本PG,在Stray状态下接收到MInfoRec或MLogRec事件后,会抛出Activate()事件,并跳转到ReplicaActive状态。下面我们来看处理过程:
boost::statechart::result PG::RecoveryState::ReplicaActive::react(const Activate& actevt) {
dout(10) << "In ReplicaActive, about to call activate" << dendl;
PG *pg = context< RecoveryMachine >().pg;
map<int, map<spg_t, pg_query_t> > query_map;
pg->activate(*context< RecoveryMachine >().get_cur_transaction(),
actevt.activation_epoch,
*context< RecoveryMachine >().get_on_safe_context_list(),
query_map, NULL, NULL);
dout(10) << "Activate Finished" << dendl;
return discard_event();
}当处于ReplicaActive状态,接收到Activate()事件,就调用函数PG::activate(),在函数PG::_activate_committed()给PG Primary发送应答信息,告诉PG Primary自己处于激活(acitvate)状态,设置PG为Active或Peered状态。
注:参看PG::_activate_committed()实现,如果acting.size()大于等于pool.info.min_size,则将PG设置为Active状态,否则设置为Peered状态。
4. 状态机异常处理
在上面的流程介绍中,只介绍了正常状态机的转换流程。Ceph之所以用状态机来实现PG的状态转换,就是可以实现任何异常情况下的处理。下面介绍当OSD失效时导致相关的PG重新进行Peering的机制。
当一个OSD失效,Monitor会通过heartbeat检测到,导致OSDMap发生了变化,Monitor会把最新的osdmap推送给OSD,导致OSD上受到影响的PG重新进行Peering操作。
具体流程如下:
1) 在函数OSD::handle_osd_map()处理osdmap的变化,该函数调用OSD::consume_map(),对每一个PG调用pg->queue_null,把PG加入到peering_wq中;
2) peering_wq的处理函数OSD::process_peering_events()调用OSD::advance_pg()函数,在该函数里调用PG::handle_advance_map()给PG状态机RecoveryMachine发送AdvMap事件:
boost::statechart::result PG::RecoveryState::Started::react(const AdvMap& advmap)
{
dout(10) << "Started advmap" << dendl;
PG *pg = context< RecoveryMachine >().pg;
pg->check_full_transition(advmap.lastmap, advmap.osdmap);
if (pg->should_restart_peering(
advmap.up_primary,
advmap.acting_primary,
advmap.newup,
advmap.newacting,
advmap.lastmap,
advmap.osdmap)) {
dout(10) << "should_restart_peering, transitioning to Reset" << dendl;
post_event(advmap);
return transit< Reset >();
}
pg->remove_down_peer_info(advmap.osdmap);
return discard_event();
}当处于Started状态,接收到AdvMap事件,调用函数pg->should_restart_peering()检查,如果时new_interval,就跳转到Reset状态,重新开始一次Peering过程。
5. 小结
本章介绍了Ceph的Peering流程,其核心过程就是通过各个OSD上保存的PG日志选择出一个权威日志的OSD。以该OSD上的日志为基础,对比其他OSD上的日志记录,计算出各个OSD上缺失的对象信息。这样,PG就使各个OSD的数据达成了一致。
[参看]
