ceph recovery研究(2)
本文接续上文《ceph recovery研究(1)》,继续讲解ceph的数据修复过程。
1. Recovery过程
在前面ReplicatedPG::start_recovery_ops()函数中我们讲到会调用:
-
recover_primary()修复PG主OSD上缺失的对象
-
recover_replicas()修复PG副本OSD上缺失的对象
-
recover_backfill()执行backfill过程
在恢复PG主OSD上缺失的对象时,我们看到又会调用ReplicatedBackend::recover_object()来实现PG Primary对象的修复。函数ReplicatedBackend::recover_object()其实实现的是pull操作,另外在调用recover_replicas()进行副本对象恢复时,会调用ReplicatedBackend实现的push操作。关于pgbackend我们会在后面再进行讲解,这里我们先来看看recover_replicas()的实现。
1.1 函数recover_replicas()
函数ReplicatedPG::recover_replicas()用于恢复PG副本上的对象:
int ReplicatedPG::recover_replicas(int max, ThreadPool::TPHandle &handle)
{
dout(10) << __func__ << "(" << max << ")" << dendl;
int started = 0;
PGBackend::RecoveryHandle *h = pgbackend->open_recovery_op();
// this is FAR from an optimal recovery order. pretty lame, really.
assert(!actingbackfill.empty());
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
if (*i == get_primary()) continue;
pg_shard_t peer = *i;
map<pg_shard_t, pg_missing_t>::const_iterator pm = peer_missing.find(peer);
assert(pm != peer_missing.end());
map<pg_shard_t, pg_info_t>::const_iterator pi = peer_info.find(peer);
assert(pi != peer_info.end());
size_t m_sz = pm->second.num_missing();
dout(10) << " peer osd." << peer << " missing " << m_sz << " objects." << dendl;
dout(20) << " peer osd." << peer << " missing " << pm->second.missing << dendl;
// oldest first!
const pg_missing_t &m(pm->second);
for (map<version_t, hobject_t>::const_iterator p = m.rmissing.begin();p != m.rmissing.end() && started < max; ++p) {
handle.reset_tp_timeout();
const hobject_t soid(p->second);
if (cmp(soid, pi->second.last_backfill, get_sort_bitwise()) > 0) {
if (!recovering.count(soid)) {
derr << __func__ << ": object added to missing set for backfill, but "<< "is not in recovering, error!" << dendl;
assert(0);
}
continue;
}
if (recovering.count(soid)) {
dout(10) << __func__ << ": already recovering " << soid << dendl;
continue;
}
if (missing_loc.is_unfound(soid)) {
dout(10) << __func__ << ": " << soid << " still unfound" << dendl;
continue;
}
if (soid.is_snap() && pg_log.get_missing().is_missing(soid.get_head())) {
dout(10) << __func__ << ": " << soid.get_head() << " still missing on primary" << dendl;
continue;
}
if (soid.is_snap() && pg_log.get_missing().is_missing(soid.get_snapdir())) {
dout(10) << __func__ << ": " << soid.get_snapdir()<< " still missing on primary" << dendl;
continue;
}
if (pg_log.get_missing().is_missing(soid)) {
dout(10) << __func__ << ": " << soid << " still missing on primary" << dendl;
continue;
}
dout(10) << __func__ << ": recover_object_replicas(" << soid << ")" << dendl;
map<hobject_t,pg_missing_t::item, hobject_t::ComparatorWithDefault>::const_iterator r = m.missing.find(soid);
started += prep_object_replica_pushes(soid, r->second.need,h);
}
}
pgbackend->run_recovery_op(h, get_recovery_op_priority());
return started;
}我们来看具体的实现流程:
1)调用pgbackend->open_recovery_op()返回一个PG类型相关的PGBackend::RecoveryHandle。对于ReplicatedPG其对应的RecoveryHandle为RPGHandle,内部有两个map,保存了Push和Pull操作的封装PushOp和PullOp。
2)遍历PG::actingbackfill中除PG Primary外的每一个PG副本:
2.1) 获取到对应副本的peer_missing以及peer_info信息
2.2) 遍历对应副本的peer_missing中的每一个object:
a) 如果该object大于peer_info.last_backfill,说明该对象是需要通过backfill来恢复,直接跳过;
b) 如果该对象已经正在进行恢复,直接跳过;
c) 如果该对象处于unfound状态,暂时无法进行恢复,跳过;
d) 如果该对象是snap对象,且其对应的head对象在PG Primary上仍然处于missing状态,则优先需要primary进行修复,直接跳过;
e) 如果该对象是snap对象,且其对应的snapdir对象在PG Primary上仍然处于missing状态,则优先需要primary进行修复,直接跳过;
f) 如果该对象在PG Primary上仍让处于missing状态,则应该先修复PG Primary,直接跳过;
g) 调用ReplicatedPG::prep_object_replica_pushes()为所需要的对象版本构造PushOp请求,放入RecoveryHandle中
3)调用函数pgbackend->run_recovery_op(),把PullOp或者PushOp封装的消息发送出去;
注:这里为PushOp消息
1.1.1 函数prep_object_replica_pushes()
下面我们来看一下函数ReplicatedPG::prep_object_replica_pushes()的实现:
int ReplicatedPG::prep_object_replica_pushes(
const hobject_t& soid, eversion_t v,
PGBackend::RecoveryHandle *h)
{
assert(is_primary());
dout(10) << __func__ << ": on " << soid << dendl;
// NOTE: we know we will get a valid oloc off of disk here.
ObjectContextRef obc = get_object_context(soid, false);
if (!obc) {
pg_log.missing_add(soid, v, eversion_t());
missing_loc.remove_location(soid, pg_whoami);
bool uhoh = true;
assert(!actingbackfill.empty());
for (set<pg_shard_t>::iterator i = actingbackfill.begin();i != actingbackfill.end();++i) {
if (*i == get_primary()) continue;
pg_shard_t peer = *i;
if (!peer_missing[peer].is_missing(soid, v)) {
missing_loc.add_location(soid, peer);
dout(10) << info.pgid << " unexpectedly missing " << soid << " v" << v << ", there should be a copy on shard " << peer << dendl;
uhoh = false;
}
}
if (uhoh)
osd->clog->error() << info.pgid << " missing primary copy of " << soid << ", unfound\n";
else
osd->clog->error() << info.pgid << " missing primary copy of " << soid << ", will try copies on " <<
missing_loc.get_locations(soid) << "\n";
return 0;
}
if (!obc->get_recovery_read()) {
dout(20) << "recovery delayed on " << soid << "; could not get rw_manager lock" << dendl;
return 0;
} else {
dout(20) << "recovery got recovery read lock on " << soid << dendl;
}
start_recovery_op(soid);
assert(!recovering.count(soid));
recovering.insert(make_pair(soid, obc));
/* We need this in case there is an in progress write on the object. In fact,
* the only possible write is an update to the xattr due to a lost_revert --
* a client write would be blocked since the object is degraded.
* In almost all cases, therefore, this lock should be uncontended.
*/
obc->ondisk_read_lock();
pgbackend->recover_object(
soid,
v,
ObjectContextRef(),
obc, // has snapset context
h);
obc->ondisk_read_unlock();
return 1;
}具体流程如下:
1)本地获取所要恢复的对象的ObjectContext:
2)如果获取ObjectContext失败,则将该对象加入PG Primary的missing列表中。然后遍历PG::actingbackfill列表,看能否在peer_missing中找到该对象,之后程序结束,返回;
注:在进行Object恢复时,优先是恢复PG Primary,因此不管上面是否在peer_mising中找到该对象,都会返回
3)如果获取ObjectContext成功,但获取recovery read lock失败,直接返回
4)获取ObjectContext以及recovery read lock成功,执行如下步骤:
4.1) 调用PG::start_recovery_op()修改recovery_ops_active的个数
4.2) 将该所要恢复的对象加入ReplicatedPG::recovering列表中
4.3) 调用函数pgbackend->recover_object()把要修复的操作信息封装到PullOp或者PushOp对象中,并添加到RecoveryHandle结构中。
2. PGBackend
PGBackend封装了不同类型的pool的实现。ReplicatedBackend实现了replicate类型的PG相关的底层功能,ECBackend实现了Erasure code类型的PG相关的底层功能。
/**
* PGBackend
*
* PGBackend defines an interface for logic handling IO and
* replication on RADOS objects. The PGBackend implementation
* is responsible for:
*
* 1) Handling client operations
* 2) Handling object recovery
* 3) Handling object access
* 4) Handling scrub, deep-scrub, repair
*/
class PGBackend {
};
class ReplicatedBackend : public PGBackend {
};由前面的分析可知,不管是recover_primary()还是recover_replicas(),其都会调用到pgbackend->recover_object()函数来实现修复对象的信息封装。这里只介绍基于副本的。
void ReplicatedBackend::recover_object(
const hobject_t &hoid,
eversion_t v,
ObjectContextRef head,
ObjectContextRef obc,
RecoveryHandle *_h
)
{
dout(10) << __func__ << ": " << hoid << dendl;
RPGHandle *h = static_cast<RPGHandle *>(_h);
if (get_parent()->get_local_missing().is_missing(hoid)) {
assert(!obc);
// pull
prepare_pull(
v,
hoid,
head,
h);
return;
} else {
assert(obc);
int started = start_pushes(
hoid,
obc,
h);
assert(started > 0);
}
}在函数recover_object()中,调用get_parent()->get_local_missing()来判断是恢复自身还是恢复其他副本上的对象数据。对于PG Primary来说,如果要恢复其本身的数据,则调用ReplicatedBackend::prepare_pull()把请求封装成PullOp结构;否则调用ReplicatedBackend::start_pushes()把请求封装成PushOp的操作。
2.1 pull操作
prepare_pull()函数把要拉取的object相关的操作信息打包成PullOp类信息,如下所示:
//src/osd/osd_types.h
struct PullOp {
hobject_t soid; //需要拉取的对象
ObjectRecoveryInfo recovery_info; //对象修复的信息
ObjectRecoveryProgress recovery_progress; //对象修复进度信息
};
// Object recovery
struct ObjectRecoveryInfo {
hobject_t soid; //修复的对象
eversion_t version; //修复对象的版本
uint64_t size; //修复对象的大小
object_info_t oi; //修复对象的object_info信息
SnapSet ss; //修复对象的快照信息
//对象需要拷贝的集合,在修复快照对象时,需要从别的OSD拷贝到本地的对象的区段集合
interval_set<uint64_t> copy_subset;
//clone对象修复时,需要从本地对象拷贝来修复的区间
map<hobject_t, interval_set<uint64_t>, hobject_t::BitwiseComparator> clone_subset;
};
struct ObjectRecoveryProgress {
uint64_t data_recovered_to; //数据已修复的位置指针
string omap_recovered_to; //omap已修复的位置指针
bool first; //是否是首次修复操作
bool data_complete; //数据是否修复完成
bool omap_complete; //omap是否修复完成
};
void ReplicatedBackend::prepare_pull(
eversion_t v, //要拉取对象的版本信息
const hobject_t& soid, //要拉取的对象
ObjectContextRef headctx, //要拉取的对象的ObjectContext信息
RPGHandle *h) //封装后保存的RecoveryHandle
{
assert(get_parent()->get_local_missing().missing.count(soid));
eversion_t _v = get_parent()->get_local_missing().missing.find(soid)->second.need;
assert(_v == v);
const map<hobject_t, set<pg_shard_t>, hobject_t::BitwiseComparator> &missing_loc(
get_parent()->get_missing_loc_shards());
const map<pg_shard_t, pg_missing_t > &peer_missing(get_parent()->get_shard_missing());
map<hobject_t, set<pg_shard_t>, hobject_t::BitwiseComparator>::const_iterator q = missing_loc.find(soid);
assert(q != missing_loc.end());
assert(!q->second.empty());
// pick a pullee
vector<pg_shard_t> shuffle(q->second.begin(), q->second.end());
random_shuffle(shuffle.begin(), shuffle.end());
vector<pg_shard_t>::iterator p = shuffle.begin();
assert(get_osdmap()->is_up(p->osd));
pg_shard_t fromshard = *p;
dout(7) << "pull " << soid << " v " << v << " on osds " << q->second
<< " from osd." << fromshard << dendl;
assert(peer_missing.count(fromshard));
const pg_missing_t &pmissing = peer_missing.find(fromshard)->second;
if (pmissing.is_missing(soid, v)) {
assert(pmissing.missing.find(soid)->second.have != v);
dout(10) << "pulling soid " << soid << " from osd " << fromshard << " at version " <<
pmissing.missing.find(soid)->second.have << " rather than at version " << v << dendl;
v = pmissing.missing.find(soid)->second.have;
assert(get_parent()->get_log().get_log().objects.count(soid) &&
(get_parent()->get_log().get_log().objects.find(soid)->second->op == pg_log_entry_t::LOST_REVERT) &&
(get_parent()->get_log().get_log().objects.find(soid)->second->reverting_to ==v));
}
ObjectRecoveryInfo recovery_info;
if (soid.is_snap()) {
assert(!get_parent()->get_local_missing().is_missing(soid.get_head()) ||
!get_parent()->get_local_missing().is_missing(soid.get_snapdir()));
assert(headctx);
// check snapset
SnapSetContext *ssc = headctx->ssc;
assert(ssc);
dout(10) << " snapset " << ssc->snapset << dendl;
calc_clone_subsets(ssc->snapset, soid, get_parent()->get_local_missing(),
get_info().last_backfill,
recovery_info.copy_subset,
recovery_info.clone_subset);
// FIXME: this may overestimate if we are pulling multiple clones in parallel...
dout(10) << " pulling " << recovery_info << dendl;
assert(ssc->snapset.clone_size.count(soid.snap));
recovery_info.size = ssc->snapset.clone_size[soid.snap];
} else {
// pulling head or unversioned object.
// always pull the whole thing.
recovery_info.copy_subset.insert(0, (uint64_t)-1);
recovery_info.size = ((uint64_t)-1);
}
h->pulls[fromshard].push_back(PullOp());
PullOp &op = h->pulls[fromshard].back();
op.soid = soid;
op.recovery_info = recovery_info;
op.recovery_info.soid = soid;
op.recovery_info.version = v;
op.recovery_progress.data_complete = false;
op.recovery_progress.omap_complete = false;
op.recovery_progress.data_recovered_to = 0;
op.recovery_progress.first = true;
assert(!pulling.count(soid));
pull_from_peer[fromshard].insert(soid);
PullInfo &pi = pulling[soid];
pi.head_ctx = headctx;
pi.recovery_info = op.recovery_info;
pi.recovery_progress = op.recovery_progress;
pi.cache_dont_need = h->cache_dont_need;
}难点在于snap对象的修复处理过程。下面我们来看具体的处理过程:
1) 通过调用函数get_parent()来获取PG对象的指针。pgbackend的parent就是相应的PG对象。通过PG获取missing、peer_missing、missing_loc等信息;
2) 从soid对象对应的missing_loc的map中获取该soid对象所在的OSD集合。把该集合保存在shuffle这个向量中。调用random_shuffle()操作对OSD列表随机排序,然后选择向量中首个OSD来为缺失对象拉取源OSD的值。从这一步可知,当修复主OSD上的对象,而多个从OSD上有该对象时,随机选择其中一个源OSD来拉取。
3)当选择了一个源shard之后,查看该shard对应的peer_missing来确保该OSD上不缺失该对象,即确实拥有该版本的对象。
4)确定拉取对象的数据范围:
a) 如果是head对象,直接拷贝对象的全部,在copy_subset()加入区间(0,-1),表示全部拷贝,最后设置size为-1:
// pulling head or unversioned object.
// always pull the whole thing.
recovery_info.copy_subset.insert(0, (uint64_t)-1);
recovery_info.size = ((uint64_t)-1);b) 如果该对象是snap对象,确保head对象或者snapdir对象二者必须存在一个。如果headctx不为空,就可以获取SnapSetContext对象,它保存了snapshot相关的信息。调用函数calc_clone_subsets()来计算需要拷贝的数据范围。
5)设置PullOp的相关字段,并添加到RPGHandle中。此外,还会将当前soid添加到ReplicatedBackend::pull_from_peer和ReplicatedBackend::pulling中保存起来
2.1.1 函数ReplicatedBackend::calc_clone_subsets()
函数ReplicatedBackend::calc_clone_subsets()用于修复快照对象。在介绍它之前,这里需介绍SnapSet的数据结构和clone对象的overlap概念。
在SnapSet结构中,字段clone_overlap保存了clone对象和上一次clone对象的重叠部分:
struct SnapSet {
snapid_t seq;
bool head_exists;
vector<snapid_t> snaps; // 序号降序排列
vector<snapid_t> clones; // 序号升序排列
//写操作导致的和最新的克隆对象重叠的部分
map<snapid_t, interval_set<uint64_t> > clone_overlap;
map<snapid_t, uint64_t> clone_size;
};下面通过一个示例来说明clone_overlap数据结构的概念。
例11-2 clone_overlap数据结构如图11-2所示:

snap3从snap2对象clone出来,并修改了区间3和4,其在对象中范围的offset和length为(4,8)和(8,12)。那么在SnapSet的clone_overlap中就记录:
clone_overlap[3] = {(4,8), (8,12)}函数calc_clone_subset()用于修复快照对象时,计算应该拷贝的数据区间。在修复快照对象时,并不是完全拷贝快照对象,这里用于优化的关键在于:快照对象之间是有数据重叠,数据重叠的部分可以通过已存在的本地快照对象的数据拷贝来修复;对于不能通过本地快照对象拷贝修复的部分,才需要从其他副本上拉取对应的数据。
函数calc_clone_subsets()具体实现如下:
void ReplicatedBackend::calc_clone_subsets(
SnapSet& snapset, const hobject_t& soid,
const pg_missing_t& missing,
const hobject_t &last_backfill,
interval_set<uint64_t>& data_subset,
map<hobject_t, interval_set<uint64_t>, hobject_t::BitwiseComparator>& clone_subsets)
{
dout(10) << "calc_clone_subsets " << soid << " clone_overlap " << snapset.clone_overlap << dendl;
uint64_t size = snapset.clone_size[soid.snap];
if (size)
data_subset.insert(0, size);
if (get_parent()->get_pool().allow_incomplete_clones()) {
dout(10) << __func__ << ": caching (was) enabled, skipping clone subsets" << dendl;
return;
}
if (!cct->_conf->osd_recover_clone_overlap) {
dout(10) << "calc_clone_subsets " << soid << " -- osd_recover_clone_overlap disabled" << dendl;
return;
}
unsigned i;
for (i=0; i < snapset.clones.size(); i++)
if (snapset.clones[i] == soid.snap)
break;
// any overlap with next older clone?
interval_set<uint64_t> cloning;
interval_set<uint64_t> prev;
if (size)
prev.insert(0, size);
for (int j=i-1; j>=0; j--) {
hobject_t c = soid;
c.snap = snapset.clones[j];
prev.intersection_of(snapset.clone_overlap[snapset.clones[j]]);
if (!missing.is_missing(c) && cmp(c, last_backfill, get_parent()->sort_bitwise()) < 0) {
dout(10) << "calc_clone_subsets " << soid << " has prev " << c << " overlap " << prev << dendl;
clone_subsets[c] = prev;
cloning.union_of(prev);
break;
}
dout(10) << "calc_clone_subsets " << soid << " does not have prev " << c << " overlap " << prev << dendl;
}
// overlap with next newest?
interval_set<uint64_t> next;
if (size)
next.insert(0, size);
for (unsigned j=i+1; j<snapset.clones.size(); j++) {
hobject_t c = soid;
c.snap = snapset.clones[j];
next.intersection_of(snapset.clone_overlap[snapset.clones[j-1]]);
if (!missing.is_missing(c) && cmp(c, last_backfill, get_parent()->sort_bitwise()) < 0) {
dout(10) << "calc_clone_subsets " << soid << " has next " << c << " overlap " << next << dendl;
clone_subsets[c] = next;
cloning.union_of(next);
break;
}
dout(10) << "calc_clone_subsets " << soid << " does not have next " << c << " overlap " << next << dendl;
}
if (cloning.num_intervals() > cct->_conf->osd_recover_clone_overlap_limit) {
dout(10) << "skipping clone, too many holes" << dendl;
clone_subsets.clear();
cloning.clear();
}
// what's left for us to push?
data_subset.subtract(cloning);
dout(10) << "calc_clone_subsets " << soid << " data_subset " << data_subset << " clone_subsets " << clone_subsets << dendl;
}1) 首先获取该快照对象的size,把(0,size)加入到data_subset中:
data_subset.insert(0, size);2) 向前查找(oldest snap)和当前快照相交的区间,直到找到一个不缺失的快照对象,添加到clone_subset中。这里找的不重叠区间,是从不缺失快照对象到当前修复的快照对象之间从没修改过的区间,所以修复时,直接从已存在的快照对象拷贝所需区间数据即可。
3) 同理,向后查找(newest snap)和当前快照对象相重叠的对象,直到找到一个不缺失的对象,添加到clone_subset中。
4) 去除掉所有重叠的区间,就是需要拉取的数据区间;
data_subset.subtract(cloning);对于上述算法,下面举例来说明:
例11-3 快照对象修复示例如图11-3所示:
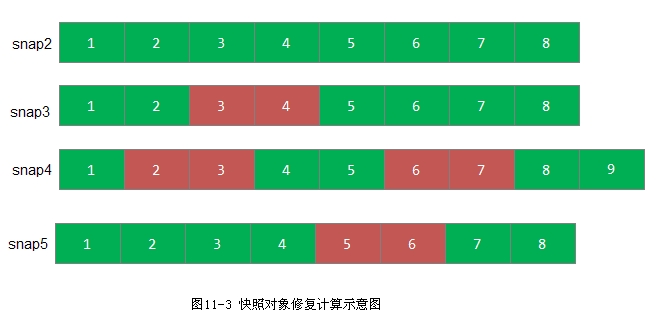
要修复的对象为snap4,不同长度代表各个clone对象的size是不同的,其中深红色的区间代表clone后修改的区间。snap2、snap3和snap5都是已经存在的非缺失对象。
算法处理流程如下:
1) 向前查找和snap4重叠的区间,直到遇到非缺失对象snap2为止。从snap4到snap2一直重叠的区间为1,5,8三个区间。因此,修复对象snap4时,修复1,5,8区间的数据,可以直接从已存在的本地非缺失对象snap2拷贝即可。
2) 同理,向后查找和snap4重叠的区间,直到遇到非缺失对象snap5为止。snap5和snap4重叠的区间为1,2,3,4,7,8六个区间。因此,修复对象4时,直接从本地对象snap4中拷贝区间1,2,3,4,7,8即可。
3) 去除上述本地就可修复的区间,对象snap4只有区间6需要从其他OSD上拷贝数据来修复。
2.2 push操作
int ReplicatedBackend::start_pushes(
const hobject_t &soid,
ObjectContextRef obc,
RPGHandle *h)
{
int pushes = 0;
// who needs it?
assert(get_parent()->get_actingbackfill_shards().size() > 0);
for (set<pg_shard_t>::iterator i =get_parent()->get_actingbackfill_shards().begin();
i != get_parent()->get_actingbackfill_shards().end();++i) {
if (*i == get_parent()->whoami_shard()) continue;
pg_shard_t peer = *i;
map<pg_shard_t, pg_missing_t>::const_iterator j = get_parent()->get_shard_missing().find(peer);
assert(j != get_parent()->get_shard_missing().end());
if (j->second.is_missing(soid)) {
++pushes;
h->pushes[peer].push_back(PushOp());
prep_push_to_replica(obc, soid, peer,&(h->pushes[peer].back()), h->cache_dont_need);
}
}
return pushes;
}函数ReplicatedBackend::start_pushes()获取actingbackfill的OSD列表,通过peer_missing查找缺失该对象的OSD,然后调用ReplicatedBackend::prep_push_to_replica()打包PushOp请求。
下面我们来看prep_push_to_replica()函数的实现:
/*
* intelligently push an object to a replica. make use of existing
* clones/heads and dup data ranges where possible.
*/
void ReplicatedBackend::prep_push_to_replica(
ObjectContextRef obc, const hobject_t& soid, pg_shard_t peer,
PushOp *pop, bool cache_dont_need)
{
const object_info_t& oi = obc->obs.oi;
uint64_t size = obc->obs.oi.size;
dout(10) << __func__ << ": " << soid << " v" << oi.version << " size " << size << " to osd." << peer << dendl;
map<hobject_t, interval_set<uint64_t>, hobject_t::BitwiseComparator> clone_subsets;
interval_set<uint64_t> data_subset;
// are we doing a clone on the replica?
if (soid.snap && soid.snap < CEPH_NOSNAP) {
hobject_t head = soid;
head.snap = CEPH_NOSNAP;
// try to base push off of clones that succeed/preceed poid
// we need the head (and current SnapSet) locally to do that.
if (get_parent()->get_local_missing().is_missing(head)) {
dout(15) << "push_to_replica missing head " << head << ", pushing raw clone" << dendl;
return prep_push(obc, soid, peer, pop, cache_dont_need);
}
hobject_t snapdir = head;
snapdir.snap = CEPH_SNAPDIR;
if (get_parent()->get_local_missing().is_missing(snapdir)) {
dout(15) << "push_to_replica missing snapdir " << snapdir << ", pushing raw clone" << dendl;
return prep_push(obc, soid, peer, pop, cache_dont_need);
}
SnapSetContext *ssc = obc->ssc;
assert(ssc);
dout(15) << "push_to_replica snapset is " << ssc->snapset << dendl;
map<pg_shard_t, pg_missing_t>::const_iterator pm = get_parent()->get_shard_missing().find(peer);
assert(pm != get_parent()->get_shard_missing().end());
map<pg_shard_t, pg_info_t>::const_iterator pi = get_parent()->get_shard_info().find(peer);
assert(pi != get_parent()->get_shard_info().end());
calc_clone_subsets(ssc->snapset, soid,
pm->second,
pi->second.last_backfill,
data_subset, clone_subsets);
} else if (soid.snap == CEPH_NOSNAP) {
// pushing head or unversioned object.
// base this on partially on replica's clones?
SnapSetContext *ssc = obc->ssc;
assert(ssc);
dout(15) << "push_to_replica snapset is " << ssc->snapset << dendl;
calc_head_subsets(
obc,
ssc->snapset, soid, get_parent()->get_shard_missing().find(peer)->second,
get_parent()->get_shard_info().find(peer)->second.last_backfill,
data_subset, clone_subsets);
}
prep_push(obc, soid, peer, oi.version, data_subset, clone_subsets, pop, cache_dont_need);
}处理流程如下:
1)如果需要push的对象是snap对象:检查如果head对象缺失,调用prep_push()推送head对象;如果headdir对象缺失,则调用prep_push()推送headdir对象;
2)如果是snap对象,调用函数calc_clone_subsets()来计算需要推送的快照对象的数据区间。
3)如果是head对象,调用calc_head_subsets()来计算需要推送的head对象的区间,其原理和计算快照对象类似,这里就不详细说明了。
4) 最后调用prep_push()封装PushInfo信息,在函数build_push_op()里读取要push的实际数据。
2.2.1 函数prep_push()
void ReplicatedBackend::prep_push(
ObjectContextRef obc,
const hobject_t& soid, pg_shard_t peer,
eversion_t version,
interval_set<uint64_t> &data_subset,
map<hobject_t, interval_set<uint64_t>, hobject_t::BitwiseComparator>& clone_subsets,
PushOp *pop,
bool cache_dont_need)
{
get_parent()->begin_peer_recover(peer, soid);
// take note.
PushInfo &pi = pushing[soid][peer];
pi.obc = obc;
pi.recovery_info.size = obc->obs.oi.size;
pi.recovery_info.copy_subset = data_subset;
pi.recovery_info.clone_subset = clone_subsets;
pi.recovery_info.soid = soid;
pi.recovery_info.oi = obc->obs.oi;
pi.recovery_info.version = version;
pi.recovery_progress.first = true;
pi.recovery_progress.data_recovered_to = 0;
pi.recovery_progress.data_complete = 0;
pi.recovery_progress.omap_complete = 0;
ObjectRecoveryProgress new_progress;
int r = build_push_op(pi.recovery_info,
pi.recovery_progress,
&new_progress,
pop,
&(pi.stat), cache_dont_need);
assert(r == 0);
pi.recovery_progress = new_progress;
}上面比较简单,就是构造一个PushInfo数据结构,然后放入ReplicatedBackend::pushing中。
2.2.2 函数build_push_op()
int ReplicatedBackend::build_push_op(const ObjectRecoveryInfo &recovery_info,
const ObjectRecoveryProgress &progress,
ObjectRecoveryProgress *out_progress,
PushOp *out_op,
object_stat_sum_t *stat,
bool cache_dont_need)
{
ObjectRecoveryProgress _new_progress;
if (!out_progress)
out_progress = &_new_progress;
ObjectRecoveryProgress &new_progress = *out_progress;
new_progress = progress;
dout(7) << "send_push_op " << recovery_info.soid << " v " << recovery_info.version
<< " size " << recovery_info.size << " recovery_info: " << recovery_info << dendl;
if (progress.first) {
store->omap_get_header(coll, ghobject_t(recovery_info.soid), &out_op->omap_header);
store->getattrs(ch, ghobject_t(recovery_info.soid), out_op->attrset);
// Debug
bufferlist bv = out_op->attrset[OI_ATTR];
object_info_t oi(bv);
if (oi.version != recovery_info.version) {
get_parent()->clog_error() << get_info().pgid << " push " << recovery_info.soid << " v "
<< recovery_info.version << " failed because local copy is " << oi.version << "\n";
return -EINVAL;
}
new_progress.first = false;
}
uint64_t available = cct->_conf->osd_recovery_max_chunk;
if (!progress.omap_complete) {
ObjectMap::ObjectMapIterator iter =store->get_omap_iterator(coll,ghobject_t(recovery_info.soid));
for (iter->lower_bound(progress.omap_recovered_to);iter->valid();iter->next(false)) {
if (!out_op->omap_entries.empty() && ((cct->_conf->osd_recovery_max_omap_entries_per_chunk > 0 &&
out_op->omap_entries.size() >= cct->_conf->osd_recovery_max_omap_entries_per_chunk) ||
available <= iter->key().size() + iter->value().length()))
break;
out_op->omap_entries.insert(make_pair(iter->key(), iter->value()));
if ((iter->key().size() + iter->value().length()) <= available)
available -= (iter->key().size() + iter->value().length());
else
available = 0;
}
if (!iter->valid())
new_progress.omap_complete = true;
else
new_progress.omap_recovered_to = iter->key();
}
if (available > 0) {
if (!recovery_info.copy_subset.empty()) {
interval_set<uint64_t> copy_subset = recovery_info.copy_subset;
bufferlist bl;
int r = store->fiemap(ch, ghobject_t(recovery_info.soid), 0,copy_subset.range_end(), bl);
if (r >= 0) {
interval_set<uint64_t> fiemap_included;
map<uint64_t, uint64_t> m;
bufferlist::iterator iter = bl.begin();
::decode(m, iter);
map<uint64_t, uint64_t>::iterator miter;
for (miter = m.begin(); miter != m.end(); ++miter) {
fiemap_included.insert(miter->first, miter->second);
}
copy_subset.intersection_of(fiemap_included);
}
out_op->data_included.span_of(copy_subset, progress.data_recovered_to,available);
if (out_op->data_included.empty()) // zero filled section, skip to end!
new_progress.data_recovered_to = recovery_info.copy_subset.range_end();
else
new_progress.data_recovered_to = out_op->data_included.range_end();
}
} else {
out_op->data_included.clear();
}
for (interval_set<uint64_t>::iterator p = out_op->data_included.begin(); p != out_op->data_included.end(); ++p) {
bufferlist bit;
store->read(ch, ghobject_t(recovery_info.soid), p.get_start(), p.get_len(), bit,
cache_dont_need ? CEPH_OSD_OP_FLAG_FADVISE_DONTNEED: 0);
if (p.get_len() != bit.length()) {
dout(10) << " extent " << p.get_start() << "~" << p.get_len() << " is actually " << p.get_start()
<< "~" << bit.length() << dendl;
interval_set<uint64_t>::iterator save = p++;
if (bit.length() == 0)
out_op->data_included.erase(save); //Remove this empty interval
else
save.set_len(bit.length());
// Remove any other intervals present
while (p != out_op->data_included.end()) {
interval_set<uint64_t>::iterator save = p++;
out_op->data_included.erase(save);
}
new_progress.data_complete = true;
out_op->data.claim_append(bit);
break;
}
out_op->data.claim_append(bit);
}
if (new_progress.is_complete(recovery_info)) {
new_progress.data_complete = true;
if (stat)
stat->num_objects_recovered++;
}
if (stat) {
stat->num_keys_recovered += out_op->omap_entries.size();
stat->num_bytes_recovered += out_op->data.length();
}
get_parent()->get_logger()->inc(l_osd_push);
get_parent()->get_logger()->inc(l_osd_push_outb, out_op->data.length());
// send
out_op->version = recovery_info.version;
out_op->soid = recovery_info.soid;
out_op->recovery_info = recovery_info;
out_op->after_progress = new_progress;
out_op->before_progress = progress;
return 0;
}具体过程如下:
1) 如果progress.first为true,就需要获取对象的元数据信息。通过store->omap_get_header()获取omap的header信息,通过store->getattrs()获取对象的扩展属性信息,并验证oi.version是否为recovery_info.version;否则返回-EINVAL值。如果成功,new_progress.first设置为false。
2) 上一步只是获取了omap的header信息,并没有获取omap信息。这一步首先判断progress.omap_complete是否完成(初始化设置为false),如果没有完成,就迭代获取omap的(key,value)信息,并检查一次获取信息的大小不能超过cct->_conf->osd_recovery_max_chunk设置的值(默认为8MB)。特别需要注意的是,当该配置参数的值小于一个对象的size时,一个对象的修复需要多次数据的push操作。为了保证数据的完整一致性,先把数据拷贝到PG的temp存储空间。当拷贝完成之后,再移动到该PG的实际空间中。
3) 开始拷贝数据:检查recovery_info.copy_subset,也就是拷贝的区间;
4) 调用函数store->fiemap()来确定有效数据的区间out_op->data_included的值,通过store->read()读取相应的数据到data里。
5) 设置PushOp的相关字段,并返回。
2.3 处理修复操作
从前面的代码分析中,我们看到不管是recover_primary()还是recover_replicas(),其都会调用函数run_recover_op()来发送PullOp和PushOp请求:
void ReplicatedBackend::run_recovery_op(
PGBackend::RecoveryHandle *_h,
int priority)
{
RPGHandle *h = static_cast<RPGHandle *>(_h);
send_pushes(priority, h->pushes);
send_pulls(priority, h->pulls);
delete h;
}当主OSD把对象推送给缺失该对象的从OSD后,从OSD需要调用函数handle_push()来实现数据的写入工作,从而完成该对象的修复。同样,当主OSD给从OSD发起拉取对象的请求来修复自己缺失的对象时,需要调用函数handle_pulls()来处理该请求的应对。
PushOp处理流程

上面看到PushOp的处理流程非常长,在函数ReplicatedBackend::handle_push()中PushOp请求,主要调用ReplicatedBackend::submit_push_data()函数来写入数据。
PullOp处理流程
上面看到函数ReplicatedBackend::handle_pull()收到一个PullOp请求,返回PushOp操作,处理流程如下:
void ReplicatedBackend::handle_pull(pg_shard_t peer, PullOp &op, PushOp *reply)
{
const hobject_t &soid = op.soid;
struct stat st;
int r = store->stat(ch, ghobject_t(soid), &st);
if (r != 0) {
get_parent()->clog_error() << get_info().pgid << " "<< peer << " tried to pull " << soid << " but got " << cpp_strerror(-r) << "\n";
prep_push_op_blank(soid, reply);
} else {
ObjectRecoveryInfo &recovery_info = op.recovery_info;
ObjectRecoveryProgress &progress = op.recovery_progress;
if (progress.first && recovery_info.size == ((uint64_t)-1)) {
// Adjust size and copy_subset
recovery_info.size = st.st_size;
recovery_info.copy_subset.clear();
if (st.st_size)
recovery_info.copy_subset.insert(0, st.st_size);
assert(recovery_info.clone_subset.empty());
}
r = build_push_op(recovery_info, progress, 0, reply);
if (r < 0)
prep_push_op_blank(soid, reply);
}
}
void ReplicatedBackend::prep_push_op_blank(const hobject_t& soid, PushOp *op)
{
op->recovery_info.version = eversion_t();
op->version = eversion_t();
op->soid = soid;
}1)首先调用store->stat()函数,验证该对象是否存在,如果不存在,则调用函数prep_push_op_blank(),直接返回空值;
2)如果该对象存在,获取ObjectRecoveryInfo和ObjectRecoveryProgress结构。如果progress.first为true并且recovery_info.size为-1,说明是全拷贝修复:将recovery_info.size设置为实际对象的size,清空recovery_info.copy_subset,并把(0, size)区间添加到recovery_info.copy_subset的拷贝区间。
3)调用函数build_push_op(),构建PushOp结构。如果出错,调用prep_push_op_blank(),直接返回空值。
注:关于ReplicatedBackend::build_push_op()我们在前面已经讲述过,这里不再赘述。
2. Backfill过程
当PG完成了Recovery过程之后,如果backfill_targets不为空,表明有需要Backfill过程的OSD,就需要启动Backfill的任务,来完成PG的全部修复。可参看前面介绍的start_recovery_ops()函数:
bool ReplicatedPG::start_recovery_ops(int max, ThreadPool::TPHandle &handle,int *ops_started)
{
}下面我们介绍Backfill过程相关的数据结构和具体处理过程。
2.1 相关数据结构
数据结构BackfillInterval用来记录每个peer上的Backfill过程:
//src/osd/pg.h
/**
* BackfillInterval
*
* Represents the objects in a range [begin, end)
*
* Possible states:
* 1) begin == end == hobject_t() indicates the the interval is unpopulated
* 2) Else, objects contains all objects in [begin, end)
*/
struct BackfillInterval {
// info about a backfill interval on a peer
eversion_t version; /// version at which the scan occurred
map<hobject_t,eversion_t,hobject_t::Comparator> objects;
bool sort_bitwise;
hobject_t begin;
hobject_t end;
};其字段说明如下:
-
version: 记录扫描对象列表时,当前PG对象更新的最新版本,一般为last_update。由于此时PG处于active状态,可能正在进行写操作。其用来检查从上次扫描到现在是否有对象写操作。如果有,完成写操作的对象在已扫描的对象列表中,进行Backfill操作时,该对象就需要更新为最新版本。
-
objects: 扫描到的准备进行Backfill操作的对象列表
-
begin: 本次扫描的起始对象
-
end: 本次扫描的起始对象的结束对象,用于作为下次扫描对象的开始
注:如果begin==end==hobject_t(),表明在interval内没有对象要恢复
2.2 Backfill的具体实现
函数ReplicatedPG::recover_backfill()作为Backfill过程的核心函数,控制整个Backfill修复进程:
/**
* recover_backfill
*
* Invariants:
*
* backfilled: fully pushed to replica or present in replica's missing set (both
* our copy and theirs).
*
* All objects on a backfill_target in
* [MIN,peer_backfill_info[backfill_target].begin) are either
* not present or backfilled (all removed objects have been removed).
* There may be PG objects in this interval yet to be backfilled.
*
* All objects in PG in [MIN,backfill_info.begin) have been backfilled to all
* backfill_targets. There may be objects on backfill_target(s) yet to be deleted.
*
* For a backfill target, all objects < MIN(peer_backfill_info[target].begin,
* backfill_info.begin) in PG are backfilled. No deleted objects in this
* interval remain on the backfill target.
*
* For a backfill target, all objects <= peer_info[target].last_backfill
* have been backfilled to target
*
* There *MAY* be objects between last_backfill_started and
* MIN(peer_backfill_info[*].begin, backfill_info.begin) in the event that client
* io created objects since the last scan. For this reason, we call
* update_range() again before continuing backfill.
*/
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
}其具体工作流程如下:
1) 初始设置
hobject_t ReplicatedPG::earliest_backfill() const
{
hobject_t e = hobject_t::get_max();
for (set<pg_shard_t>::iterator i = backfill_targets.begin();i != backfill_targets.end();++i) {
pg_shard_t bt = *i;
map<pg_shard_t, pg_info_t>::const_iterator iter = peer_info.find(bt);
assert(iter != peer_info.end());
if (cmp(iter->second.last_backfill, e, get_sort_bitwise()) < 0)
e = iter->second.last_backfill;
}
return e;
}
void ReplicatedPG::on_activate()
{
...
if (!backfill_targets.empty()) {
last_backfill_started = earliest_backfill();
new_backfill = true;
assert(!last_backfill_started.is_max());
dout(5) << "on activate: bft=" << backfill_targets << " from " << last_backfill_started << dendl;
for (set<pg_shard_t>::iterator i = backfill_targets.begin(); i != backfill_targets.end(); ++i) {
dout(5) << "target shard " << *i << " from " << peer_info[*i].last_backfill << dendl;
}
}
...
}
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
// Initialize from prior backfill state
if (new_backfill) {
// on_activate() was called prior to getting here
assert(last_backfill_started == earliest_backfill());
new_backfill = false;
// initialize BackfillIntervals (with proper sort order)
for (set<pg_shard_t>::iterator i = backfill_targets.begin(); i != backfill_targets.end(); ++i) {
peer_backfill_info[*i].reset(peer_info[*i].last_backfill,get_sort_bitwise());
}
backfill_info.reset(last_backfill_started,get_sort_bitwise());
// initialize comparators
backfills_in_flight = set<hobject_t, hobject_t::Comparator>(hobject_t::Comparator(get_sort_bitwise()));
pending_backfill_updates = map<hobject_t, pg_stat_t, hobject_t::Comparator>(hobject_t::Comparator(get_sort_bitwise()));
}
...
}在PG Peering完成进行激活时会调用到ReplicatedPG::on_activate(),在其中设置了PG的属性值new_backfill为true,设置了last_backfill_started值为earliest_backfill()的值。从上面我们看到earliest_backfill()就是计算需要backfill的OSD中,peer_info信息里保存的last_backfill的最小值。
peer_backfill_info的map中保存各个需要Backfill的OSD所对应的BackfillInterval对象信息。首先初始化begin和end都为peer_info.last_backfill,由PG的Peering过程可知,在PG::activate()里,设置该OSD的peer_info.last_backfill为hobject_t(),也就是MIN对象。
backfills_in_flight保存了正在进行Backfill操作的对象,pending_backfill_updates保存了需要删除的对象。
2)设置backfill_info.begin为last_backfill_started,调用函数ReplicatedPG::update_range()来更新需要进行Backfill操作的对象列表
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
// update our local interval to cope with recent changes
backfill_info.begin = last_backfill_started;
update_range(&backfill_info, handle);
...
}
void ReplicatedPG::update_range(
BackfillInterval *bi,
ThreadPool::TPHandle &handle)
{
int local_min = cct->_conf->osd_backfill_scan_min;
int local_max = cct->_conf->osd_backfill_scan_max;
if (bi->version < info.log_tail) {
dout(10) << __func__<< ": bi is old, rescanning local backfill_info" << dendl;
if (last_update_applied >= info.log_tail) {
bi->version = last_update_applied;
} else {
osr->flush();
bi->version = info.last_update;
}
scan_range(local_min, local_max, bi, handle);
}
if (bi->version >= info.last_update) {
dout(10) << __func__<< ": bi is current " << dendl;
assert(bi->version == info.last_update);
} else if (bi->version >= info.log_tail) {
if (pg_log.get_log().empty()) {
/* Because we don't move log_tail on split, the log might be
* empty even if log_tail != last_update. However, the only
* way to get here with an empty log is if log_tail is actually
* eversion_t(), because otherwise the entry which changed
* last_update since the last scan would have to be present.
*/
assert(bi->version == eversion_t());
return;
}
assert(!pg_log.get_log().empty());
dout(10) << __func__<< ": bi is old, (" << bi->version << ") can be updated with log" << dendl;
list<pg_log_entry_t>::const_iterator i = pg_log.get_log().log.end();
--i;
while (i != pg_log.get_log().log.begin() && i->version > bi->version) {
--i;
}
if (i->version == bi->version)
++i;
assert(i != pg_log.get_log().log.end());
dout(10) << __func__ << ": updating from version " << i->version << dendl;
for (; i != pg_log.get_log().log.end(); ++i) {
const hobject_t &soid = i->soid;
if (cmp(soid, bi->begin, get_sort_bitwise()) >= 0 && cmp(soid, bi->end, get_sort_bitwise()) < 0) {
if (i->is_update()) {
dout(10) << __func__ << ": " << i->soid << " updated to version " << i->version << dendl;
bi->objects.erase(i->soid);
bi->objects.insert(make_pair(i->soid,i->version));
} else if (i->is_delete()) {
dout(10) << __func__ << ": " << i->soid << " removed" << dendl;
bi->objects.erase(i->soid);
}
}
}
bi->version = info.last_update;
} else {
assert(0 == "scan_range should have raised bi->version past log_tail");
}
}3)根据各个peer的peer_backfill_info信息进行trim操作。根据last_backfill_started来更新backfill_info里相关字段
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
for (set<pg_shard_t>::iterator i = backfill_targets.begin();i != backfill_targets.end();++i) {
peer_backfill_info[*i].trim_to(MAX_HOBJ(peer_info[*i].last_backfill, last_backfill_started,get_sort_bitwise()));
}
backfill_info.trim_to(last_backfill_started);
...
}4) 如果backfill_info.begin小于等于earliest_peer_backfill(),说明需要扫描更多的对象,backfill_info重新设置。这里特别注意的是,backfill_info的version字段也重新设置为(0,0),这会导致在随后调用的update_range()函数时再次调用scan_range()函数来扫描对象。
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
int ops = 0;
vector<boost::tuple<hobject_t, eversion_t, ObjectContextRef, vector<pg_shard_t> > > to_push;
vector<boost::tuple<hobject_t, eversion_t, pg_shard_t> > to_remove;
set<hobject_t, hobject_t::BitwiseComparator> add_to_stat;
...
while (ops < max) {
if (cmp(backfill_info.begin, earliest_peer_backfill(),get_sort_bitwise()) <= 0 &&
!backfill_info.extends_to_end() && backfill_info.empty()) {
hobject_t next = backfill_info.end;
backfill_info.reset(next, get_sort_bitwise());
backfill_info.end = hobject_t::get_max();
update_range(&backfill_info, handle);
backfill_info.trim();
}
...
}
...
}5) 进行比较, 如果pbi.begin小于backfill_info.begin,需要向各个OSD发送MOSDPGScan::OP_SCAN_GET_DIGEST消息来获取该OSD目前所拥有的对象列表
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
int ops = 0;
vector<boost::tuple<hobject_t, eversion_t, ObjectContextRef, vector<pg_shard_t> > > to_push;
vector<boost::tuple<hobject_t, eversion_t, pg_shard_t> > to_remove;
set<hobject_t, hobject_t::BitwiseComparator> add_to_stat;
...
while (ops < max) {
...
bool sent_scan = false;
for (set<pg_shard_t>::iterator i = backfill_targets.begin(); i != backfill_targets.end(); ++i) {
pg_shard_t bt = *i;
BackfillInterval& pbi = peer_backfill_info[bt];
dout(20) << " peer shard " << bt << " backfill " << pbi << dendl;
if (cmp(pbi.begin, backfill_info.begin, get_sort_bitwise()) <= 0 && !pbi.extends_to_end() && pbi.empty()) {
dout(10) << " scanning peer osd." << bt << " from " << pbi.end << dendl;
epoch_t e = get_osdmap()->get_epoch();
MOSDPGScan *m = new MOSDPGScan(
MOSDPGScan::OP_SCAN_GET_DIGEST, pg_whoami, e, e,
spg_t(info.pgid.pgid, bt.shard),
pbi.end, hobject_t());
osd->send_message_osd_cluster(bt.osd, m, get_osdmap()->get_epoch());
assert(waiting_on_backfill.find(bt) == waiting_on_backfill.end());
waiting_on_backfill.insert(bt);
sent_scan = true;
}
}
...
}
...
}6) 当获取所有OSD的对象列表后,就对比当前主OSD的对象列表来进行修复
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
while (ops < max) {
...
// Count simultaneous scans as a single op and let those complete
if (sent_scan) {
ops++;
start_recovery_op(hobject_t::get_max()); // XXX: was pbi.end
break;
}
}
...
}7) check对象指针,就当前OSD中最小的需要进行Backfill操作的对象:
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
while (ops < max) {
...
// Get object within set of peers to operate on and
// the set of targets for which that object applies.
hobject_t check = earliest_peer_backfill();
if (cmp(check, backfill_info.begin, get_sort_bitwise()) < 0) {
set<pg_shard_t> check_targets;
for (set<pg_shard_t>::iterator i = backfill_targets.begin(); i != backfill_targets.end(); ++i) {
pg_shard_t bt = *i;
BackfillInterval& pbi = peer_backfill_info[bt];
if (pbi.begin == check)
check_targets.insert(bt);
}
assert(!check_targets.empty());
dout(20) << " BACKFILL removing " << check << " from peers " << check_targets << dendl;
for (set<pg_shard_t>::iterator i = check_targets.begin(); i != check_targets.end(); ++i) {
pg_shard_t bt = *i;
BackfillInterval& pbi = peer_backfill_info[bt];
assert(pbi.begin == check);
to_remove.push_back(boost::make_tuple(check, pbi.objects.begin()->second, bt));
pbi.pop_front();
}
last_backfill_started = check;
// Don't increment ops here because deletions
// are cheap and not replied to unlike real recovery_ops,
// and we can't increment ops without requeueing ourself
// for recovery.
} else {
eversion_t& obj_v = backfill_info.objects.begin()->second;
vector<pg_shard_t> need_ver_targs, missing_targs, keep_ver_targs, skip_targs;
for (set<pg_shard_t>::iterator i = backfill_targets.begin();i != backfill_targets.end();++i) {
pg_shard_t bt = *i;
BackfillInterval& pbi = peer_backfill_info[bt];
// Find all check peers that have the wrong version
if (check == backfill_info.begin && check == pbi.begin) {
if (pbi.objects.begin()->second != obj_v) {
need_ver_targs.push_back(bt);
} else {
keep_ver_targs.push_back(bt);
}
} else {
pg_info_t& pinfo = peer_info[bt];
// Only include peers that we've caught up to their backfill line
// otherwise, they only appear to be missing this object
// because their pbi.begin > backfill_info.begin.
if (cmp(backfill_info.begin, pinfo.last_backfill,get_sort_bitwise()) > 0)
missing_targs.push_back(bt);
else
skip_targs.push_back(bt);
}
}
....
}
}
...
}a) 检查check对象,如果小于backfill_info.begin,就在各个需要Backfill操作的OSD上删除该对象,加入到to_remove队列中;
b) 如果check对象大于或者等于backfill_info.begin,检查拥有check对象的OSD,如果版本不一致,加入need_ver_targ中。如果版本相同,就加入keep_ver_targs中;
c) 那些begin对象不是check对象的OSD,如果pinfo.last_backfill小于backfill_info.begin,那么该对象缺失,加入missing_targs列表中;
d) 如果pinfo.last_backfill大于backfill_info.begin,说明该OSD修复的进度已经超越当前主OSD指示的修复进度,加入skip_targs中;
8)对于keep_ver_targs列表中的OSD,不做任何操作。对于need_ver_targs和missing_targs中的OSD,该对象需要加入到to_push中修复
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
while (ops < max) {
...
// Get object within set of peers to operate on and
// the set of targets for which that object applies.
hobject_t check = earliest_peer_backfill();
if (cmp(check, backfill_info.begin, get_sort_bitwise()) < 0) {
....
} else {
....
if (!keep_ver_targs.empty()) {
// These peers have version obj_v
dout(20) << " BACKFILL keeping " << check<< " with ver " << obj_v << " on peers " << keep_ver_targs << dendl;
//assert(!waiting_for_degraded_object.count(check));
}
if (!need_ver_targs.empty() || !missing_targs.empty()) {
ObjectContextRef obc = get_object_context(backfill_info.begin, false);
assert(obc);
if (obc->get_recovery_read()) {
if (!need_ver_targs.empty()) {
dout(20) << " BACKFILL replacing " << check << " with ver " << obj_v << " to peers " << need_ver_targs << dendl;
}
if (!missing_targs.empty()) {
dout(20) << " BACKFILL pushing " << backfill_info.begin << " with ver " << obj_v << " to peers " << missing_targs << dendl;
}
vector<pg_shard_t> all_push = need_ver_targs;
all_push.insert(all_push.end(), missing_targs.begin(), missing_targs.end());
to_push.push_back(boost::tuple<hobject_t, eversion_t, ObjectContextRef, vector<pg_shard_t> >
(backfill_info.begin, obj_v, obc, all_push));
// Count all simultaneous pushes of the same object as a single op
ops++;
} else {
*work_started = true;
dout(20) << "backfill blocking on " << backfill_info.begin << "; could not get rw_manager lock" << dendl;
break;
}
}
dout(20) << "need_ver_targs=" << need_ver_targs<< " keep_ver_targs=" << keep_ver_targs << dendl;
dout(20) << "backfill_targets=" << backfill_targets<< " missing_targs=" << missing_targs
<< " skip_targs=" << skip_targs << dendl;
last_backfill_started = backfill_info.begin;
add_to_stat.insert(backfill_info.begin); // XXX: Only one for all pushes?
backfill_info.pop_front();
vector<pg_shard_t> check_targets = need_ver_targs;
check_targets.insert(check_targets.end(), keep_ver_targs.begin(), keep_ver_targs.end());
for (vector<pg_shard_t>::iterator i = check_targets.begin();i != check_targets.end();++i) {
pg_shard_t bt = *i;
BackfillInterval& pbi = peer_backfill_info[bt];
pbi.pop_front();
}
}
}
...
}9) 调用函数send_remove_op()给OSD发送删除的消息来删除to_remove中的对象;
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
backfill_pos = MIN_HOBJ(backfill_info.begin, earliest_peer_backfill(),get_sort_bitwise());
for (set<hobject_t, hobject_t::BitwiseComparator>::iterator i = add_to_stat.begin();i != add_to_stat.end();++i) {
ObjectContextRef obc = get_object_context(*i, false);
assert(obc);
pg_stat_t stat;
add_object_context_to_pg_stat(obc, &stat);
pending_backfill_updates[*i] = stat;
}
for (unsigned i = 0; i < to_remove.size(); ++i) {
handle.reset_tp_timeout();
// ordered before any subsequent updates
send_remove_op(to_remove[i].get<0>(), to_remove[i].get<1>(), to_remove[i].get<2>());
pending_backfill_updates[to_remove[i].get<0>()]; // add empty stat!
}
...
}10) 调用函数prep_backfill_object_push()把操作打包成PushOp,调用函数pgbackend->run_recovery_op()把请求发送出去。其流程和Recovery流程类似
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
PGBackend::RecoveryHandle *h = pgbackend->open_recovery_op();
for (unsigned i = 0; i < to_push.size(); ++i) {
handle.reset_tp_timeout();
prep_backfill_object_push(to_push[i].get<0>(), to_push[i].get<1>(),
to_push[i].get<2>(), to_push[i].get<3>(), h);
}
pgbackend->run_recovery_op(h, get_recovery_op_priority());
...
}11) 最后用new_last_backfill更新各个OSD的pg_info的last_backfill值。如果pinfo.last_backfill为MAX,说明backfill操作完成,给该OSD发送MOSDPGBackfill::OP_BACKFILL_FINISH消息;否则发送MOSDPGBackfill::OP_BACKFILL_PROGRESS来更新各个OSD上的pg_info的last_backfill字段。
int ReplicatedPG::recover_backfill(
int max,
ThreadPool::TPHandle &handle, bool *work_started)
{
...
// If new_last_backfill == MAX, then we will send OP_BACKFILL_FINISH to
// all the backfill targets. Otherwise, we will move last_backfill up on
// those targets need it and send OP_BACKFILL_PROGRESS to them.
for (set<pg_shard_t>::iterator i = backfill_targets.begin();i != backfill_targets.end();++i) {
pg_shard_t bt = *i;
pg_info_t& pinfo = peer_info[bt];
if (cmp(new_last_backfill, pinfo.last_backfill, get_sort_bitwise()) > 0) {
pinfo.set_last_backfill(new_last_backfill, get_sort_bitwise());
epoch_t e = get_osdmap()->get_epoch();
MOSDPGBackfill *m = NULL;
if (pinfo.last_backfill.is_max()) {
m = new MOSDPGBackfill(
MOSDPGBackfill::OP_BACKFILL_FINISH,
e,
e,
spg_t(info.pgid.pgid, bt.shard));
// Use default priority here, must match sub_op priority
/* pinfo.stats might be wrong if we did log-based recovery on the
* backfilled portion in addition to continuing backfill.
*/
pinfo.stats = info.stats;
start_recovery_op(hobject_t::get_max());
} else {
m = new MOSDPGBackfill(
MOSDPGBackfill::OP_BACKFILL_PROGRESS,
e,
e,
spg_t(info.pgid.pgid, bt.shard));
// Use default priority here, must match sub_op priority
}
m->last_backfill = pinfo.last_backfill;
m->stats = pinfo.stats;
osd->send_message_osd_cluster(bt.osd, m, get_osdmap()->get_epoch());
dout(10) << " peer " << bt << " num_objects now " << pinfo.stats.stats.sum.num_objects
<< " / " << info.stats.stats.sum.num_objects << dendl;
}
}
...
}2.2.1 recover_backfill()示例
下面举例说明recover_backfill()的处理过程。
例11-4 如下图11-4所示,该PG分布在5个OSD上(也就是5个副本,这里为了方便列出各种处理情况),每一行上的对象列表都是相应OSD当前对应backfillInterval的扫描对象列表。osd5为主OSD,是权威的对象列表,其他OSD都对照主OSD上的对象列表来修复。

下面举例来说明步骤7)中的不同的修复方法:
1)当前check对象指针为主OSD上保存的peer_backfill_info中begin的最小值。图中check对象应为obj4对象;
2)比较check对象和主osd5上的backfill_info.begin对象,由于check小于obj5,所以obj4为多余的对象,所有拥有该check对象的OSD都必须删除该对象。故osd0和osd2上的obj4对象被删除,同时对应的begin指针前移。

3) 当前各个OSD的状态如图11-5所示:此时check对象为obj5,比较check和backfill_info.begin的值:
a) 对于当前begin为check对象的osd0、osd1、osd4:
* 对于osd0和osd4,check对象和backfill_info.begin对象都是obj5,且版本号都为(1,4),加入到keep_ver_targs列表中,不需要修复;
* 对于osd1,版本号不一致,加入need_ver_targs列表中,需要修复;
b) 对于当前begin不是check对象的osd2和osd3:
* 对于osd2,其last_backfill小于backfill_info.begin,显然对象obj5缺失,加入missing_targs修复;
* 对于osd3,其last_backfill大于backfill_info.begin,也就是说其已经修复到obj6了,obj5应该已经修复了,加入skip_targs跳过;
4)步骤3处理完成后,设置last_backfill_started为当前的backfill_info.begin的值。backfill_info.begin指针前移,所有begin等于check对象的begin指针前移,重复以上步骤继续修复。
函数update_range()调用函数scan_range()更新BackfillInterval修复的对象列表,同时检查上次扫描对象列表中,如果有对象发生写操作,就更新该对象修复的版本。
void ReplicatedPG::update_range(
BackfillInterval *bi,
ThreadPool::TPHandle &handle)
{
int local_min = cct->_conf->osd_backfill_scan_min;
int local_max = cct->_conf->osd_backfill_scan_max;
if (bi->version < info.log_tail) {
dout(10) << __func__<< ": bi is old, rescanning local backfill_info"<< dendl;
if (last_update_applied >= info.log_tail) {
bi->version = last_update_applied;
} else {
osr->flush();
bi->version = info.last_update;
}
scan_range(local_min, local_max, bi, handle);
}
if (bi->version >= info.last_update) {
dout(10) << __func__<< ": bi is current " << dendl;
assert(bi->version == info.last_update);
} else if (bi->version >= info.log_tail) {
if (pg_log.get_log().empty()) {
/* Because we don't move log_tail on split, the log might be
* empty even if log_tail != last_update. However, the only
* way to get here with an empty log is if log_tail is actually
* eversion_t(), because otherwise the entry which changed
* last_update since the last scan would have to be present.
*/
assert(bi->version == eversion_t());
return;
}
assert(!pg_log.get_log().empty());
dout(10) << __func__<< ": bi is old, (" << bi->version << ") can be updated with log" << dendl;
list<pg_log_entry_t>::const_iterator i = pg_log.get_log().log.end();
--i;
while (i != pg_log.get_log().log.begin() && i->version > bi->version) {
--i;
}
if (i->version == bi->version)
++i;
assert(i != pg_log.get_log().log.end());
dout(10) << __func__ << ": updating from version " << i->version << dendl;
for (; i != pg_log.get_log().log.end(); ++i) {
const hobject_t &soid = i->soid;
if (cmp(soid, bi->begin, get_sort_bitwise()) >= 0 && cmp(soid, bi->end, get_sort_bitwise()) < 0) {
if (i->is_update()) {
dout(10) << __func__ << ": " << i->soid << " updated to version " << i->version << dendl;
bi->objects.erase(i->soid);
bi->objects.insert(make_pair(i->soid,i->version));
} else if (i->is_delete()) {
dout(10) << __func__ << ": " << i->soid << " removed" << dendl;
bi->objects.erase(i->soid);
}
}
}
bi->version = info.last_update;
} else {
assert(0 == "scan_range should have raised bi->version past log_tail");
}
}具体实现步骤如下:
1)bi->version记录了扫描要修复的对象列表时PG最新更新的版本号,一般设置为last_update_applied或者info.last_update的值。初始化时,bi->version的默认值为(0,0),所以小于info.log_tail,就更新bi->version的设置,调用函数scan_range()扫描对象;
2)检查如果bi->version的值等于info.last_update,说明从上次扫描对象开始到当前时间,PG没有写操作,直接返回;
3)如果bi->version小于info.last_update,说明PG有写操作,需要检查从bi->version到log_head这段日志中的对象:如果该对象有更新操作,修复时就修复最新的版本;如果该对象已经删除,就不需要修复,在修复队列中删除。
下面举例说明ReplicatedPG::update_range()的处理过程。
2.2.2 update_range()示例
例11-5 update_range的处理过程
1) 日志记录如下图所示:

BackfillInterval的扫描的对象列表:bi->begin为对象obj1(1,3),bi->end为对象obj4(1,6),当前info.last_update的版本为(1,6),所以bi->version这只为(1,6)。由于本次扫描的对象列表不一定能修复完,只能等下次修复。
2)日志记录如下图所示:

第二次进入函数recover_backfill,此时begin对象指向了obj2对象。说明上次只完成了对象obj1的修复。继续修复时,期间有对象发生更新操作:
a) 对象obj3有写操作,版本更新为(1,7)。此时对象列表中要修复的对象obj3版本为(1,5),需要更新为版本(1,7)的值;
b) 对象obj4发送删除操作,不需要修复了,所以需从对象列表中删除。
综上所述可知,Ceph的Backfill过程是扫描OSD上该PG的所有对象列表,和主OSD做对比,修复不存在的或者版本不一致的对象,同时删除多余的对象。
3. 小结
本章介绍了ceph的修复数据的过程,有两个过程:Recovery过程和Backfill过程。Recovery过程根据missing记录,先完成主副本的修复,然后完成从副本的修复。对于不能通过日志修复的OSD,Backfill过程通过扫描各个部分上的对象来全量修复。整个Ceph的数据修复过程比较清晰,比较复杂的部分可能就是涉及快照对象的修复处理。
目前这部分代码是ceph最核心的代码,除非必要,都不会轻易修改。目前社区也提出修复时的一种优化方法。就是在日志里记录修改的对象范围,这样在Recovery过程中不必拷贝整个对象来修复,只修复修改过的对象对应的范围即可,这样在某些情况下可以减少修复的数据量。
[参看]
