B*树详解
本文详细介绍一下B*树的相关原理及实现。
1. B*树
B*树是B+树的变体,在B+树的非根和非叶子节点增加指向兄弟的指针;B*树定义了非叶子节点关键字个数至少为(2/3)*m,即块的最低使用率为2/3(代替B+树的1/2)。
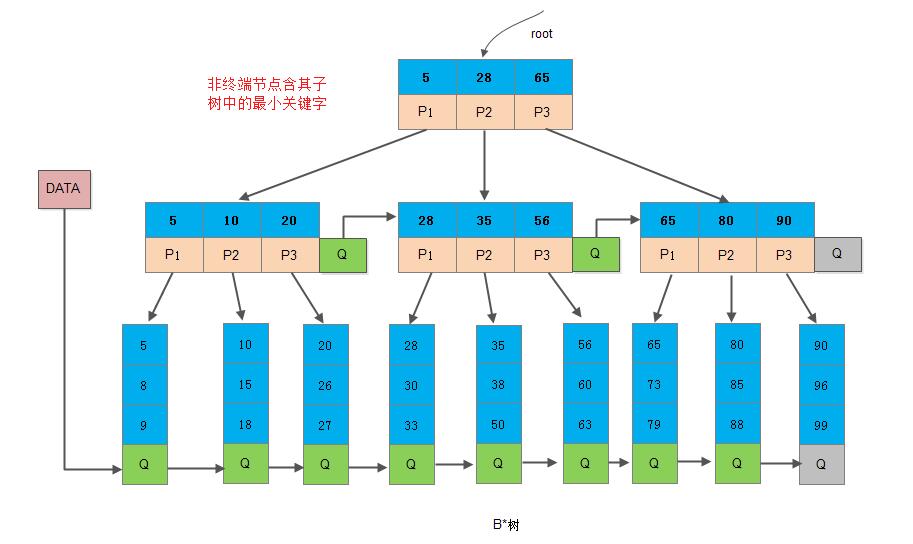
-
B+树的分裂: 当一个节点满时,则先分裂成两个节点
X和Y,并且他们各自所含的关键字个数分别为: u=⌈(m+1)/2⌉, v=⌊(m+1)/2⌋。最后在父节点中增加新节点的指针。B+树的分裂只影响原节点和父节点,而不会影响兄弟节点,所以它不需要指向兄弟节点的指针。 -
B*树的分裂: 当一个节点满时,如果它的下一个兄弟节点未满,那么将一部分数据迁移到兄弟节点中,再在原节点中插入关键字,最后修改父节点中兄弟节点的关键字(因为兄弟节点的关键字范围改变了);如果兄弟节点也满了,则在原节点与兄弟节点之间增加新节点,并各自复制
1/3数据到新节点,最后在父节点增加新节点的指针。
所以,B*树分配新节点的概率比B+树要低,空间使用效率更高。
[参看]:
