赫夫曼树及其应用
本章我们主要介绍一下赫夫曼树及其应用。赫夫曼(Huffman)树,又称最优树,是一类带权路径长度最短的树,有着广泛的应用。
1. 最优二叉树(赫夫曼树)
首先给出路径和路径长度的概念。从树中一个节点到另一个节点之间的分支构成这两个节点之间的路径,路径上的分支数目称作路径长度。树的路径长度是从树根到每一节点的路径长度之和。完全二叉树就是这种路径长度最短的二叉树。
若将上述概念推广到一般情况,考虑带权的节点。节点的带权路径长度为从该节点到树根之间的路径长度与节点上权的乘积。树的带权路径长度为树中所有叶子节点的带权路径长度之和,通常记作: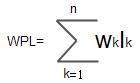
假设有n个权值{W1,W2,…, Wn},试构造一棵有n个叶子节点的二叉树,每个叶子节点带权路径长度为Wi,则其中带权路径长度WPL最小的二叉树称作最优二叉树或赫夫曼树。
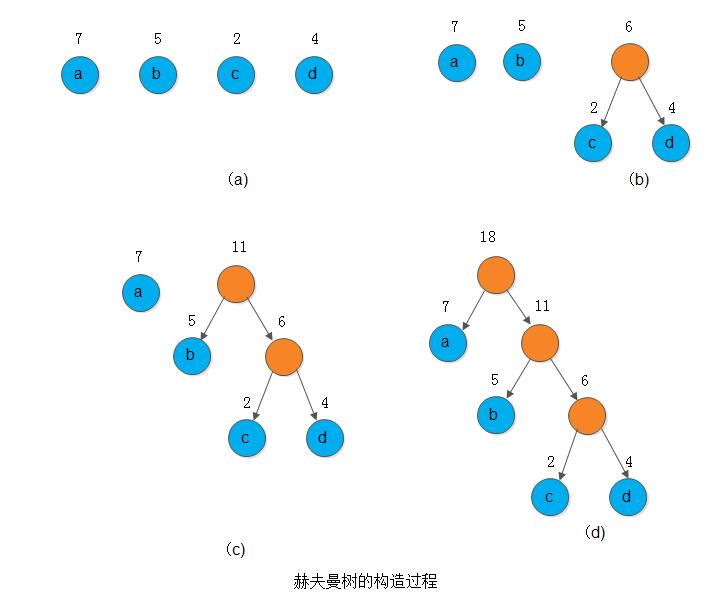
例如,下图所示的3棵二叉树,都有4个叶子节点a、b、c、d,分别带权7、5、2、4,它们的带权路径长度分别为:
(a) WPL = 7 x 2 + 5 x 2 + 2 x 2 + 4 x 2 = 36 (b) WPL = 7 x 3 + 5 x 3 + 2 x 1 + 4 x 2 = 46 (c) WPL = 7 x 1 + 5 x 2 + 2 x 3 + 4 x 3 = 35
其中以(c)树的带权路径长度为最小。可以验证,它恰为赫夫曼树,即其带权路径长度在所有带权为7、5、2、4的4个叶子节点的二叉树中居最小。
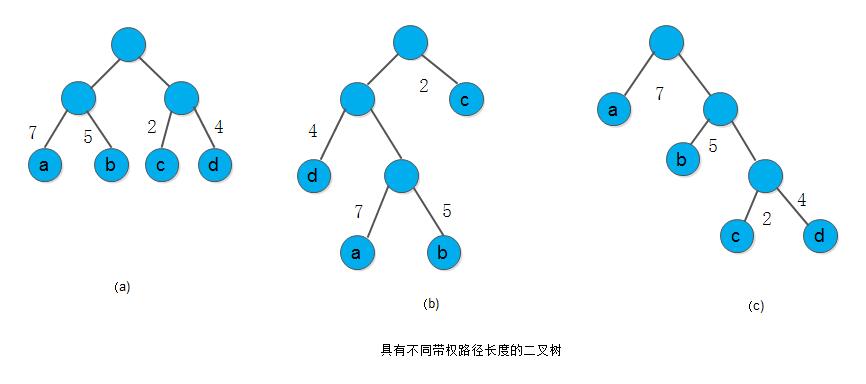
在解某些判问题时,利用赫夫曼树可以得到最佳判定算法。例如,要编制一个将百分制转换成五级分制的程序。显然,此程序很简单,只要利用条件语句便可完成。如:
if(a < 60)
b = "bad";
else if(a < 70)
b = "pass";
else if(a < 80)
b = "general";
else if(a < 90)
b = "good";
else
b = "excellent";这个判定过程可以下图(a)的判定树来表示。如果上述程序反复使用,而且每次的输入量很大,则应考虑上述程序的质量问题,即其操作所需的时间。因为在实际生活中,学生的成绩在5个等级上的分布是不均匀的。假设其分布规律如下表所示:
| 分数 | 0-59 | 60-69 | 70-79 | 80-89 | 90-100 |
|---|---|---|---|---|---|
| 比例数 | 0.05 | 0.15 | 0.40 | 0.30 | 0.10 |
则80%以上的数据需进行3次或3次以上的比较才能得出结果。假定以5,15,40,30和10为权构造一颗有5个叶子节点的赫夫曼树,则可得到下图(b)所示的判定过程,它可使大部分的数据经过较少的比较次数得出结果。但由于每个判定框都有两次比较,将这两次比较分开,我们得到下图(c)所示的判定树,按此判定树可写出相应的程序。假设现有10000个输入数据,若按图(a)的判定过程进行操作,则总共需进行31500次比较;而若按图(c)的判定过程进行操作,则总共需进行22000次比较。
那么,如何构造赫夫曼树呢?赫夫曼最早给出了一个带有一般规律的算法,俗称赫夫曼算法。现叙述如下:
1) 根据给定的n个权值{W1, W2, …, Wn}构成n棵二叉树的集合F={T1,T2, …, Tn},其中每棵二叉树Ti中只有一个带权为Wi的根节点,其左右子树均空。
2) 在F中选取两棵根节点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根节点的权值为其左、右子树上根节点的权值之和。
3) 在F中删除这两棵树,同时将新得到的二叉树加入F中
4) 重复2)和3),直到F中只含一棵树为止。这棵树便是赫夫曼树。
例如,下图展示了权值为7、5、2、4的节点构造赫夫曼树的过程。其中,根节点上标注的数字是所赋的权。
2. 赫夫曼编码
目前,进行快速远距离通信的主要手段是电报,即将需传送的文字转换成由二进制的字符组成的字符串。例如,假设需传送的电文为’A B A C C D A’,它只有4种字符,只需两个字符的串便可分辨。假设A、B、C、D的编码分别为00、01、10和11,则上述7个字符的电文便为’00010010101100’,总长14位,对方接收时,可按二位一分进行译码。
当然,在传送电文时,希望总长尽可能短。如果对每个字符设计长度不等的编码,且让电文中出现次数较多的字符采用尽可能短的编码,则传送电文的总长便可减少。如果设计A、B、C、D的编码分别为0、00、1和01,则上述7个字符的电文可转换成总长为9的字符串’00001101’。但是,这样的电文无法翻译,例如传送过去的字符串中前4个字符的子串’0000’就有多种译法,或是AAAA,或是ABA,也可以是BB等。因此,若要设计长短不等的编码,则必须是任一个字符的编码都不能是另一个字符的编码的前缀,这种编码称作前缀编码。
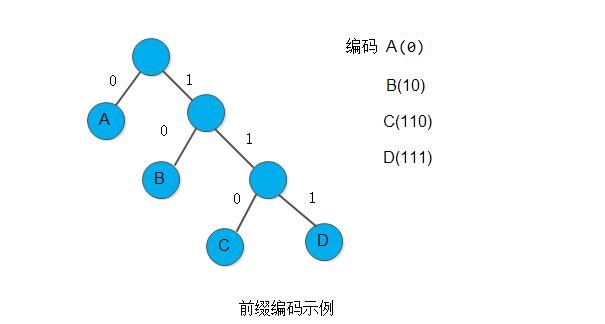
可以利用二叉树来设计二进制的前缀编码。假设有一棵如下图所示的二叉树,其四个叶子节点分别表示A、B、C、D这4个字符,且约定左分支表示字符’0’,右分支表示字符’1’,则可以从根节点到叶子节点的路径上分支字符组成字符串作为该叶子节点字符的编码。可以证明,如此得到的必为二进制前缀编码。如下图所示,所得到的A、B、C、D的二进制前缀编码分别为0、10、110和111。
又如何得到使电文总长度最短的二进制前缀编码呢? 假设每种字符在电文中出现的次数为Wi,其编码长度为Li,电文中只有n种字符,则电文总长度为W1L1 + W2L2 + ... + WnLn。对应的二叉树上,若置Wi为叶子节点的权,Li恰为从根到叶子节点的路径长度。则W1L1 + W2L2 + ... + WnLn恰为二叉树上带权路径长度。由此可见,设计电文总长度最短的二进制前缀编码即为以n种字符出现的频率作权,设计一颗赫夫曼树的问题,由此得到的二进制前缀编码称为赫夫曼编码。
下面讨论具体做法。
由于赫夫曼树中没有度为1的节点(这类树又称严格的(strict)或正则的二叉树),则一颗有n个叶子节点的赫夫曼树共有2n-1个节点,可以存储在一个大小为2n-1的一维数组中。如何选定节点结构? 由于在构造赫夫曼树之后,为求编码需从叶子节点出发走一条从叶子到根的路径; 而为译码需从根出发走一条从根到叶子的路径。则对每个节点而言,既需知双亲的信息,又需知孩子节点的信息。由此,设定下述存储结构:
typedef struct{
unsigned int weight;
unsigned int parent,lchild,rchild;
}HTNode, *HuffmanTree; //动态分配数组存赫夫曼树
typedef char **HuffmanCode; //动态分配数组存储赫夫曼编码表求赫夫曼编码算法如下:
//w存放n个字符的权值(均>0),构造赫夫曼树HT,并求出n个字符的赫夫曼编码HC。
void HuffmanCoding(HuffmanTree *HT, HuffmanCode *HC,int *w, int n)
{
if(n <= 1)
return;
m = 2*n -1;
(*HT) = (HuffmanTree)malloc((m+1) * sizeof(HTNode)); //0号单元未用
for(p = *HT, i = 1; i<=n; ++i, ++p, ++w)
*p = {*w, 0, 0,0};
for(; i<=m;++i, ++p)
*p = {0,0,0,0};
//1) 构建赫夫曼树
for(i = n+1; i<=m;++i)
{
//在HT[1..i-1]中选择parent为0且weight最小的两个节点,其序号分别为s1和s2,且s1 <= s2
Select(HT, i-1, s1, s2);
HT[s1].parent = i;
HT[s2].parent =i;
HT[i].lchild = s1;
HT[i].rchild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
//2) 从叶子到根逆向求每个字符的赫夫曼编码
*HC = (HuffmanCode)malloc((n+1)*sizeof(char *)); //分配n个字符编码的头指针向量,0号单元未用
//分配求编码的空间(除第一层外,每层最少有两个节点,因此层高最大为(2n-2)/2=n-1
cd = (char *)malloc(n*sizeof(char));
cd[n-1] = '\0'; //编码结束符
for(i = 1;i<=n;i++) //逐个字符求赫夫曼编码
{
start = n-1; //编码结束符位置
for(c = i, f = HT[i].parent; f != 0; c = f, f = HT[f].parent)
{
if(HT[f].lchild == c)
cd[--start] = '0';
else
cd[--start] = '1';
}
HC[i] = (char *)malloc((n-start)*sizeof(char)); //为第i个字符编码分配空间
strcpy(HC[i], &cd[start]); //从cd复制编码(串)到HC
}
free(cd); //释放工作空间
}向量HT的前n个分量表示叶子节点,最后一个分量表示根节点。各字符编码长度不等,所以按实际长度动态分配空间。

在上面的算法中求每个字符的赫夫曼编码是从叶子到根逆向处理的。也可以从根出发,遍历整棵赫夫曼树,求得各个叶子节点所表示的字符的赫夫曼编码。如下所示:
//w存放n个字符的权值(均>0),构造赫夫曼树HT,并求出n个字符的赫夫曼编码HC。
void HuffmanCoding(HuffmanTree *HT, HuffmanCode *HC,int *w, int n)
{
if(n <= 1)
return;
m = 2*n -1;
(*HT) = (HuffmanTree)malloc((m+1) * sizeof(HTNode)); //0号单元未用
for(p = *HT, i = 1; i<=n; ++i, ++p, ++w)
*p = {*w, 0, 0,0};
for(; i<=m;++i, ++p)
*p = {0,0,0,0};
//1) 构建赫夫曼树
for(i = n+1; i<=m;++i)
{
//在HT[1..i-1]中选择parent为0且weight最小的两个节点,其序号分别为s1和s2,且s1 <= s2
Select(HT, i-1, s1, s2);
HT[s1].parent = i;
HT[s2].parent =i;
HT[i].lchild = s1;
HT[i].rchild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
//2) 无栈非递归遍历赫夫曼树,求赫夫曼编码
*HC = (HuffmanCode)malloc((n+1)*sizeof(char *)); //分配n个字符编码的头指针向量,0号单元未用
p = m;
cdlen = 0;
for(i = 1;i<=m;++i)
HT[i].weight = 0; //遍历赫夫曼树时用作节点状态标志
while(p)
{
if(HT[p].weight == 0) //向左
{
HT[p].weight = 1;
if(HT[p].lchild != 0)
{
p = HT[p].lchild;
cd[cdlen++] = '0';
}
else if(HT[p].rchild == 0) //登记叶子节点的字符的编码
{
(*HC)[p] = (char *)malloc((cdlen + 1) * sizeof(char));
cd[cdlen] = '\0';
strcpy((*HC)[p], cd);
}
}
else if(HT[p].weight == 1) //向右
{
HT[p].weight =2;
if(HT[p].rchild != 0)
{
p = HT[p].rchild;
cd[cdlen++] = '1';
}
}
else{ //退回
HT[p].weight = 0;
p = HT[p].parent;
--cdlen;
}
}
}译码的过程是分解电文中字符串,从根出发,按字符’0’或’1’确定找左孩子或右孩子,直至叶子节点,便求得该子串相应的字符。
3. 赫夫曼编码举例
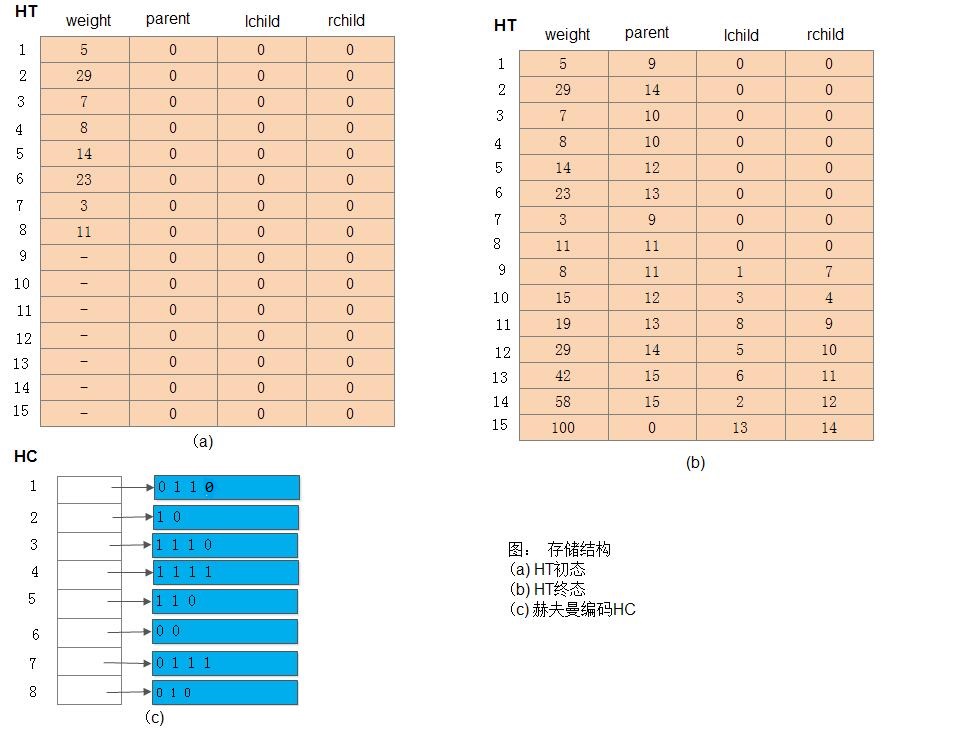
例: 已知某系统在通信联络中只可能出现8种字符,其概率分别为0.05,0.29,0.07,0.08, 0.14,0.23,0.03,0.11,试设计赫夫曼编码。
如下我们构造赫夫曼树:设权w=(5,29,7,8,14,23,3, 11),n=8,则m=15,按上述算法可构建一棵赫夫曼树,如下图所示:
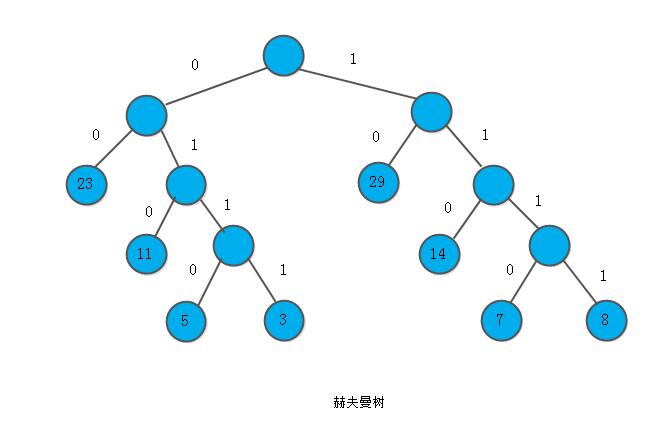
其存储结构HT的初始状态如下图(a)所示,其终结状态如下图(b)所示,所得赫夫曼编码如图(c)所示: