CPU cacheline技术浅析
本文我们主要简单介绍一下cpu的cacheline技术,了解其工作的基本原理。
1. cache概述
cache即高速缓冲存储器,其作用是为了更好的利用程序局部性原理,减少CPU访问主存的次数。简单的说,CPU正在访问的指令和数据,在稍后的时间也可能会被多次访问到,而该指令和数据附近的区域也可能会被多次访问。因此,第一次访问这一块区域时,将其复制到cache中,以后访问该区域的指令或数据时就不用再从主存中读取。
2. cache结构
首先我们先来看cache的组织方式:
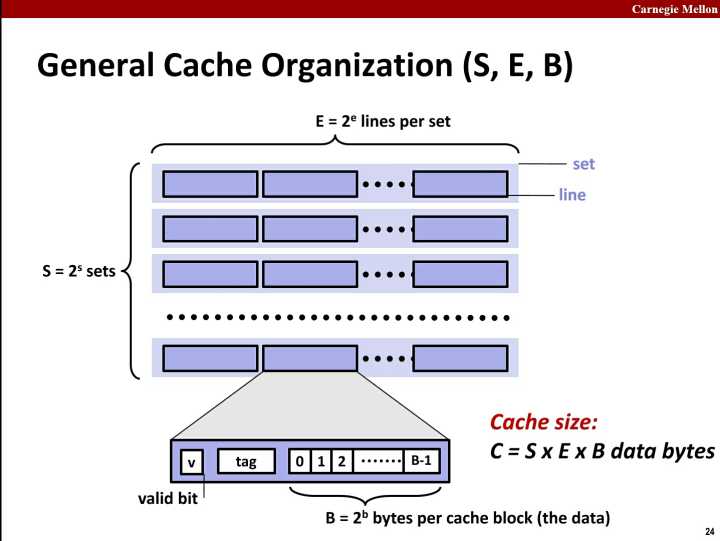
cache是由set组成,而set是由line组成, line由valid bit, tag和data组成。 其中data是真正要缓存的内存地址中的数据。而tag是用来搜索cache line的标签。
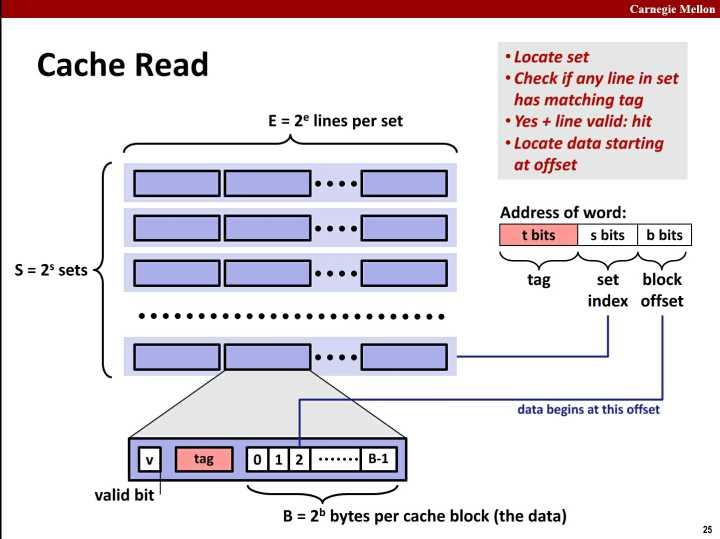
然后我们看一下内存地址如何分解:
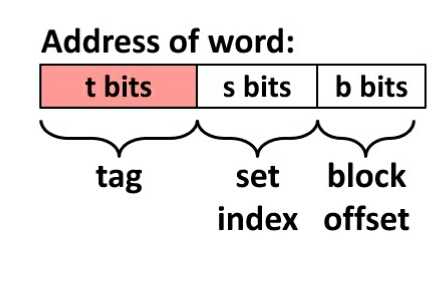
上面我们可以看到,内存地址被分成了3部分:tag, set index, block offset。这三部分分别用来在cache中定为数据。
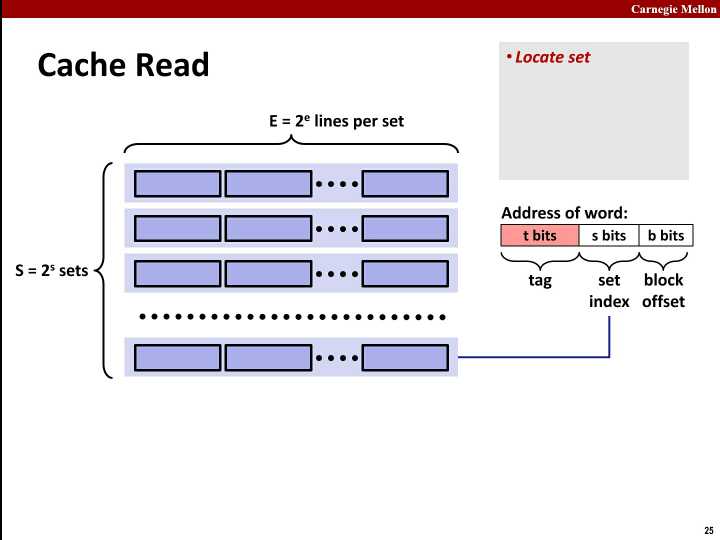
最后,看一下cache的寻址过程:
第一步: 根据set index找到set
第二步: 根据tag在set中搜索到cache line
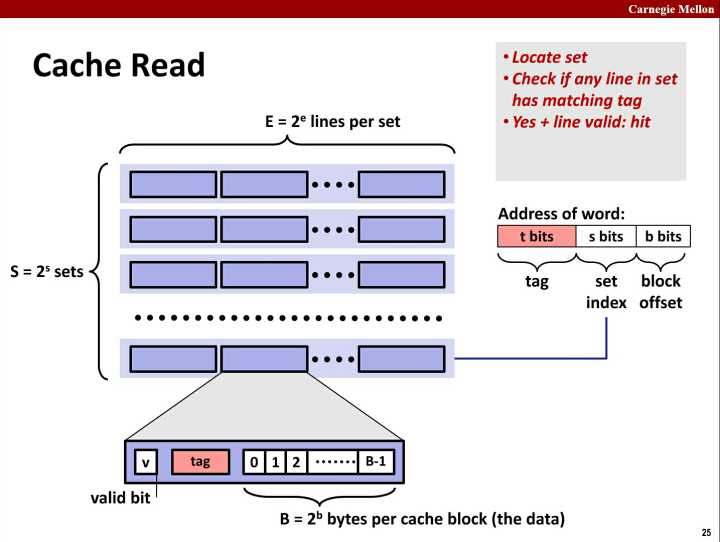
如果找到了,并且valid bit为 1 则命中; 如果没有命中,就要根据置换策略找一个cache line把内存的数据加载到cache line中。
第三步: 根据block offset在cache line的data中找到值
其实,这其中最难理解的是为什么要set,为什么不能根据tag直接找到cache line,再根据offset找到值?
我的理解是,因为硬件必须要在几个纳秒内完成这些工作,这就要求搜索是并行进行的。如果cache中有100个cache line,硬件就要并行搜索100个cache line的tag,所以进行100个并行搜索非常困难,而且很昂贵。(来源于CSAPP相关章节的理解)
这样就引入了set的层级,先根据set index找出一个set,再在set中并行搜索少量cache line就容易多了。
至于set index为什么取内存地址的中间几位,而不是头几位,这是为了照顾空间局部性下cache的利用率而进行的优化。(来源于CSAPP相关章节的理解)
cache根据寻址方式可以分成3类:
-
直接映射(direct mapped cache): 相当于每一个set只有一个cache line
-
组相联(set associative cache): 多个set, 每个set多个cache。 一般每个set有 n 个cache line,就说n-ways associative cache
-
全相联(fully associative cache): 相当于只有一个set
另外,line 与block大致是一回事。 如果要区分,按我的理解,block应该是指cache line中有效数据部分,不包括valid bit和tag index。
3. False Sharing(伪共享)问题
到现在为止,我们似乎没有提到cache如何和内存保持一致的问题。
其实在cache line中,还有其他的标志位,其中一个用于标记cacheline是否被写过。我们称为modified位。当modified=1时,表明cacheline被CPU写过。 这说明,该cacheline中的内容可能已经被CPU修改过了,这样就与内存中相应的那些存储单元不一致了。因此,如果cacheline被写过,那么我们就应该将该cacheline中的内容写回到内存中,以保持数据的一致性。
现在问题来了,我们什么时候写回到内存中呢? 当然不会是每当modified位被置为1时就写,这样会极大降低cache性能,因为内次都要进行内存读写操作。事实上,大多数系统都会在这样的情况下将cacheline中的内容写回到内存:
当该cacheline被置换出去的时,且modified位为1现在大多数系统正从单处理器环境慢慢过渡到多处理器环境。一个机器中集成2个、4个甚至16个,那么新的问题来了。
以Intel处理器为典型代表,L1级cache是CPU专有的。
先看以下例子:
系统是双核的,即为有两个CPU,CPU(例如Intel Pentium处理器)L1 cache是专有的,对其他CPU不可见,每个cacheline有8个存储单元。
我们的程序中,有一个char arr[8]的数组,这个数组当然会被映射到CPU L1 cache中相同的cacheline,因为映射机制是硬件实现的,相同的内存都会被映射到同一个cacheline.
两个线程分别对这两个数组进行写操作。当0号线程和1好线程分别运行于 0 号CPU和 1 号CPU时,假设运行序列如下:
开始CPU 0对arr[0]写; 随后CPU 1对arr[1]写; 随后CPU 0对arr[2]写; …… CPU 1对arr[7]写;
根据多处理器中cache一致性的协议:
当CPU 0对arr[0]写时,8个char单元的数组被加载到CPU 0的某一个cacheline中,该cacheline的modified位已经被置为1了;
当CPU 1对arr[1]写时,该数组应该也被加载到CPU 1的某个cacheline中,但是该数组在cpu 0的cache中已经被改变,所以cpu 0首先将cacheline中的内容写回到内存,然后再从内存中加载该数组到CPU 1的cacheline中。CPU 1的写操作又会让CPU 0对应的cacheline变为invalid状态。
注意:
由于相同的映射机制,cpu1 中的 cacheline 和cpu0 中的cacheline在逻辑上是同一行(直接映射机制中是同一行,组相联映射中则是同一组)当CPU 0对arr[2]写时,该cacheline是invalid状态,故CPU 1需要将cacheline中的数组数据传送给CPU 0,CPU 0在对其cacheline写时,又会将CPU 1中相应的cacheline置为invalid状态
….
如此往复,cache的性能遭到了极大的损伤!此程序在多核处理器下的性能还不如在单核处理器下的性能高。
多CPU同时访问同一块内存区域就是“共享”,就会产生冲突,需要控制协议来协调访问。会引起“共享”的最小内存区域大小就是一个cache line。因此,当两个以上CPU都要访问同一个cache line大小的内存区域时,就会引起冲突,这种情况就叫“共享”。但是,这种情况里面又包含了“其实不是共享”的“伪共享”情况。比如,两个处理器各要访问一个word,这两个word却存在于同一个cache line大小的区域里,这时,从应用逻辑层面说,这两个处理器并没有共享内存,因为他们访问的是不同的内容(不同的word)。但是因为cache line的存在和限制,这两个CPU要访问这两个不同的word时,却一定要访问同一个cache line块,产生了事实上的“共享”。显然,由于cache line大小限制带来的这种“伪共享”是我们不想要的,会浪费系统资源(此段摘自如下网址:http://software.intel.com/zh-cn/blogs/2010/02/26/false-sharing/)
对于伪共享问题,有2种比较好的方法:
1. 增大数组元素的间隔使得由不同线程存取的元素位于不同的cache line上。典型的空间换时间 2. 在每个线程中创建全局数组各个元素的本地拷贝,然后结束后再写回全局数组
而我们要说的linux cache机制,就与第1种方法有关。
[参看]:
