Linux Netfilter/Iptables
本章主要介绍一下Linux netfilter/iptables相关原理及使用
1. 基本概念介绍
1.1 netfilter与iptables
Netfilter是由Rusty Russell提出的Linux 2.4内核防火墙框架,该框架既简洁又灵活,可实现安全策略应用中的许多功能,如数据包过滤、数据包处理、地址伪装、透明代理、动态网络地址装换(Network Address Translation, NAT),以及基于用户及媒体访问控制(Media Access Control, MAC)地址的过滤和基于状态的过滤、包速率限制等。Iptables/Netfilter的这些规则可以通过灵活组合,形成非常多的功能、涵盖各个方面,这一切都得益于它的优秀设计思想。
Netfilter是Linux操作系统核心层内部的一个数据包处理模块,它具有如下功能:
-
数据包过滤(防火墙功能)
-
网络地址装换(NAT/NAPT): 源网络地址装换(SNAT – Source Network Address Translation)和目标地址转换(DNAT – Destination Network Address Translation)
-
数据包伪装(packet mangling)
Netfilter是Linux Kernel中的一些钩子(hooks),以允许内核模块在网络协议栈上注册回调函数。当一个网络协议栈中的数据包遍历到(traverse)对应的钩子(hook)时,相应注册的回调函数就会被调用。
iptables是一个通用的表结构,用于定义规则集(rulesets)。一个IP table中的每一个规则(rule)都有多个classifiers(iptables matches)和对应的action所构成。下面给出一个iptables的逻辑结构示意:
|------ rule(classifier_1 classififer_2 ... action)
|
|------IP table ---|------ rule(classifier_1 classififer_2 ... action)
| |
| |------ rule(classifier_1 classififer_2 ... action)
|
|
| |------ rule(classifier_1 classififer_2 ... action)
| |
iptables ----|------IP table ---|------ rule(classifier_1 classififer_2 ... action)
| |
| |------ rule(classifier_1 classififer_2 ... action)
|
|
| |------ rule(classifier_1 classififer_2 ... action)
| |
|-----IP table---- |------ rule(classifier_1 classififer_2 ... action)
|
|------ rule(classifier_1 classififer_2 ... action)iptables 和netfilter主要工作在OSI网络7层参考模型中的网络层和传输层。
1.2 ip filtering 介绍
本章我们会介绍一下ip filter的理论细节: IP filter工作原理、firewall的工作层级、policies等。
1) What is an IP filter
很重要的一点是我们必须要完全弄明白一个IP filter到底是什么。其实Iptables就是一个IP Filter,假如不能完全理解这一点的话,当我们在未来设计防火墙的时候将会碰到严重的问题。
一个IP Filter主要工作在TCP/IP网络协议栈中的传输层,而iptables可以工作在传输层和网络层。假如IP Filter的实现严格按照定义来的话,其只能够基于IP头(IP Headers)来进行包过滤。然而,由于iptables并不是严格的按照定义来实现的,导致IP filter也能够基于其他的Header来进行数据包过滤,例如TCP头、UDP头或者是MAC源地址。
iptables并不能跟踪数据包之间的联系,也不会对数据包的内容进行解析,因为这可能会耗费大量的内存及CPU。
2) IP filtering相关术语
如下我们介绍一下IP Filtering中的一些常用术语:
-
Drop/Deny: 当一个数据包被dropped或denied,则该数据包被简单的删除,而并不会再采取其他的后续动作(actions)。既不会通知源端数据包丢失,也不会通知目的端数据包被丢掉。
-
Reject: 基本上与Drop/Deny策略类似,只不过Reject会通知源端主机相应的数据包被丢掉。向源端主机返回的响应消息可以被指定或自动的计算为某个值。注意到目前为止,Reject并不会通知目的端主机相应的数据包被丢掉。
-
State: 数据流中某个数据包的指定状态。例如,假如某数据包是防火墙首次遇见,则会被认为是一个新包(TCP连接中的SYN数据包);假如某个数据包是一条已建立连接(established connection)流的一部分,则防火墙会认为其状态为
established。这种状态信息可以通过连接跟踪系统(connection tracking system)来获得,其会跟踪所有的会话信息。 -
Chain: 一个chain包含了一个
规则集(ruleset),规则集会被应用在所有经过该chain上的数据包上。每一条chain都有特定的目的(例如: 该chain被连接到哪一个表上)和特定的应用场景(例如: 只作用在转发数据包上,或者只作用于发往本主机的数据包)。在iptables中有多条不同的chain,我们后面会详细的介绍。 -
Table: 每一个table都有特定的目的,在iptables中有4张不同的table,分别是raw table、nat table、mangle table和filter table。例如,
filter table设计的初衷就是为了过滤数据包,而nat table设计的目的就是为了处理NAT包。 -
Match: 在IP Filtering中,Match这一单词有两个不同的含义。第一个含义是指一个
单独匹配(single match),用于指示某一个规则(rule)其所匹配的数据包头(header)必须包含指定的信息,例如:--source匹配用于指示数据包的源地址必须为指定的网络范围(network range)或主机地址; 第二个含义是指一个规则的全量匹配(whole match)。假如某个数据包匹配全量规则,则会执行对应的jump或target指令 -
Target: 通常一个规则集中的每一个规则都有一个对应的target。假若某个规则完全匹配成功,则target会指示我们如何处理该packet。例如,可以指示
drop掉该数据包,或者accept该数据包,或者NAT该数据包。另外,也可以是一个Jump(请参看如下) -
Rule: 通常一个规则(rule)是由一系列的匹配(match)和一个的target所组成
-
Ruleset: 一个
规则集(ruleset)是由一系列的rule所组成,存放于IP Filter的实现中。在iptables中包含了filter表、nat表、raw表以及mangle表对应chain中的所有规则集。 -
Jump: Jump指令与Target有很紧密的关系。在Iptables中,jump指令的写法与target的写法完全相同,除了其指定的是一个
chain,而target所指定的是一个target name。假如匹配对应的规则,该数据包就会被发送到第二条chain中继续进行处理 -
Connection Tracking: 实现了连接跟踪的防火墙能够跟踪
connctions/streams。连接跟踪通常要耗费大量的CPU及内存资源。 -
Accept: 接受一个数据包,并让其穿过防火墙规则。这与drop/deny/reject这样的target是完全相反的
-
Policy: 当我们实现一个防火墙的时候,通常会说到两种不同类型的策略(policy)。首先我们有
链路策略(chain policies),用于指示防火墙的默认行文(即一个数据包并没有对应的规则匹配时的动作);第二种policy就是指某种安全策略(security policy),通常我们在构建一个防火墙之前需要全盘的想好一套安全策略。
3) 如何规划一个IP Filter
当我们在规划一个防火墙方案的时候,首先就是要想好应该将防火墙架设在什么地方。通常情况下,这是相对容易的一个步骤,因为我们的网络是早已规划好的。首先我们考虑架设防火墙的位置就是在网关(gateway)上,该位置对内连接着本地网络,对外连接着Internet,因此其安全性一般要求较高。另外,在一个大型的网络中,也可以通过防火墙来做多个不同的划分。
此外,假如在你当前的网络中有一些服务器需要对外提供服务,我们也可以划设一个DMZ区域。一个DMZ区域是一个由服务器组成的小型物理网络,对外部进行一定的隔离,降低了外部用户对DMZ区域服务器访问的风险。
2. tables和chains之旅
在本章,我们会讨论数据包是如何通过不同的chains的,以及相应的通过顺序。我们也会讨论数据包通过对应table的顺序。
2.1 General
当一个数据包刚进入防火墙(filewall)时,它首先会遇到相应的硬件设备(hardware),然后再被传递到内核中相应的设备驱动程序。接着数据包会在内核中经过多个步骤,然后才会被发送到对应的应用程序(locally)或者被转发到其他主机或者丢弃等。
首先我们来看一下,当一个数据包的目的地址是我们的本地主机时,在我们的上层应用程序(application)收到该数据包之前其所经过的步骤:
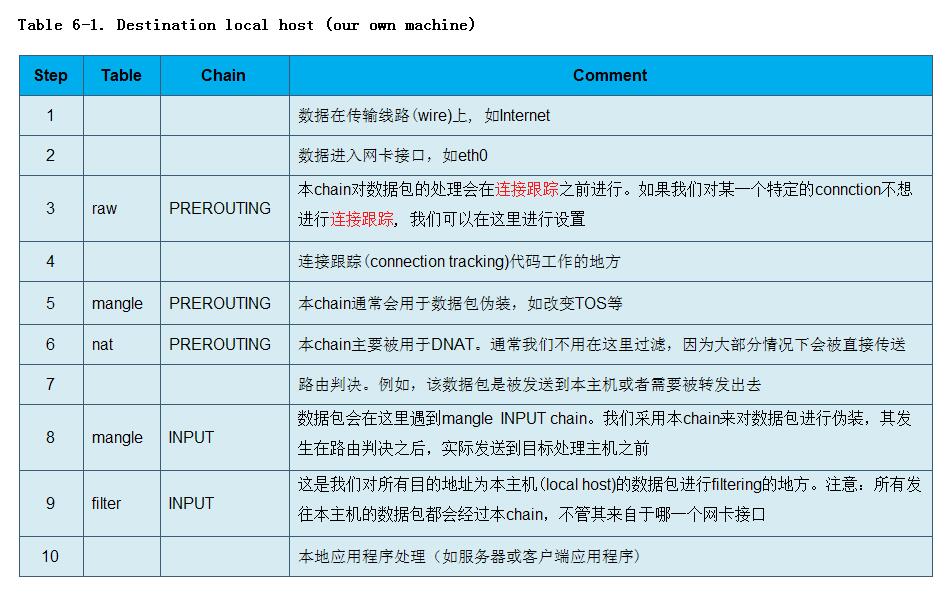
接着我们介绍一下从本主机向外发送一个数据包所经过的步骤:
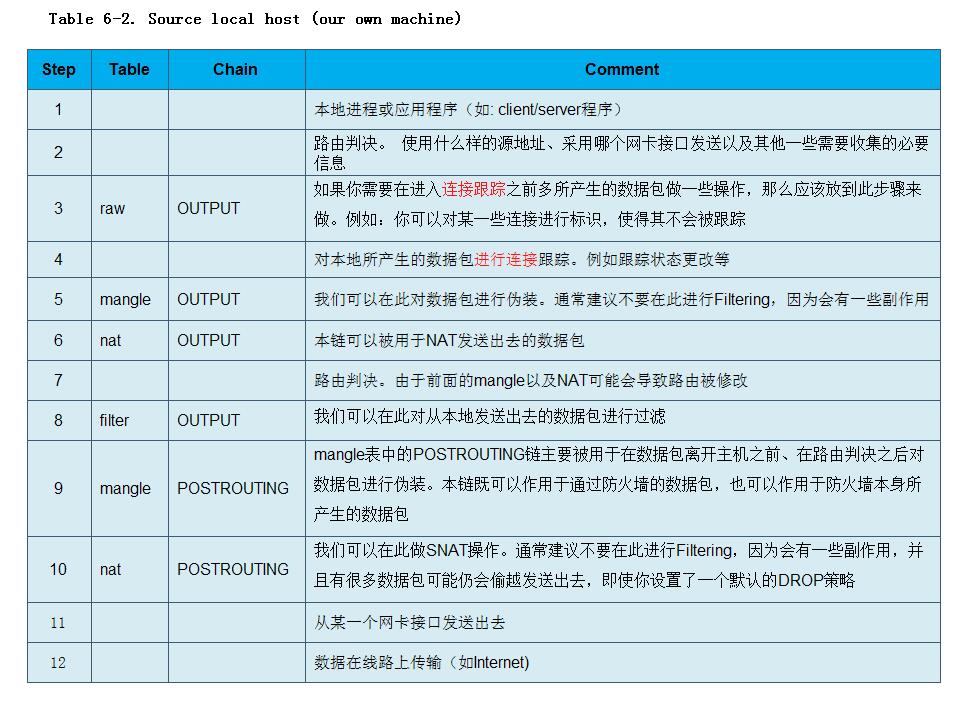
接着我们来看一下,通过本主机来转发数据包其所经过的步骤:
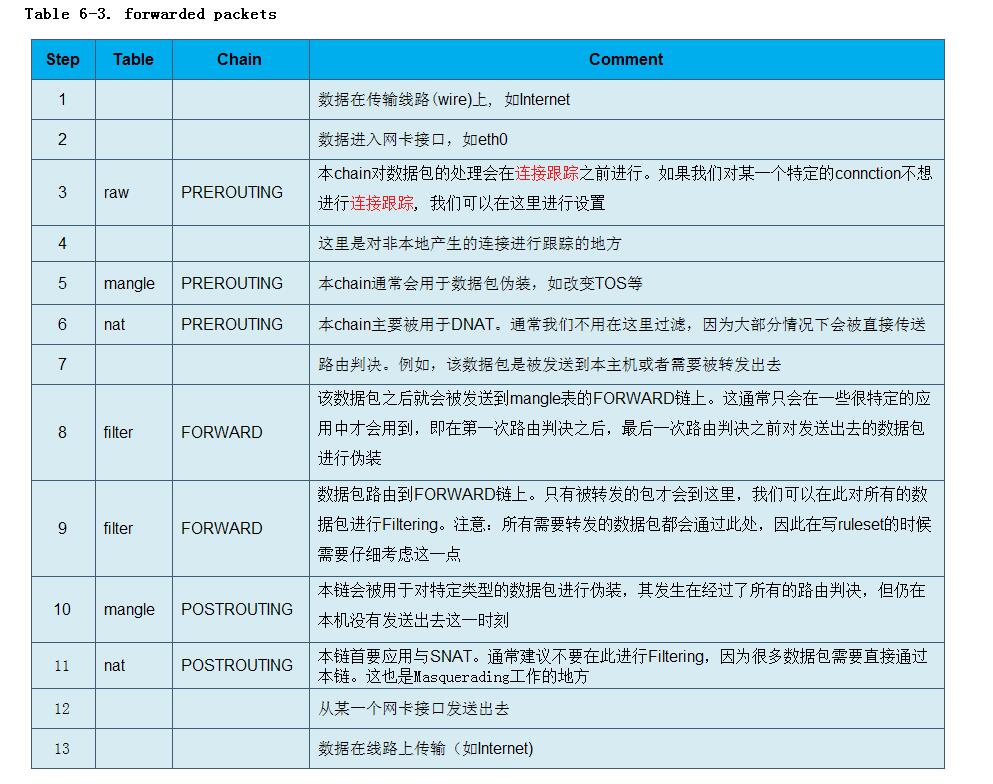
正如上面你所看到,数据包可能会经过很多步骤。数据包可能在任何一个iptables chains上面被终止。
注意: 对于forward这一情况(即转发数据包),请不要使用INPUT chain。因为INPUT chain主要被用于发送到本主机的 数据包。
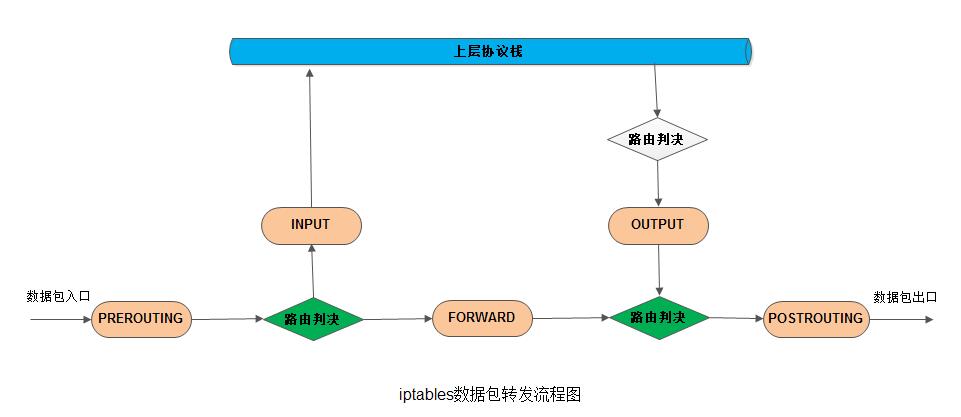
下面我们给出一张数据包通过iptables时的图示:
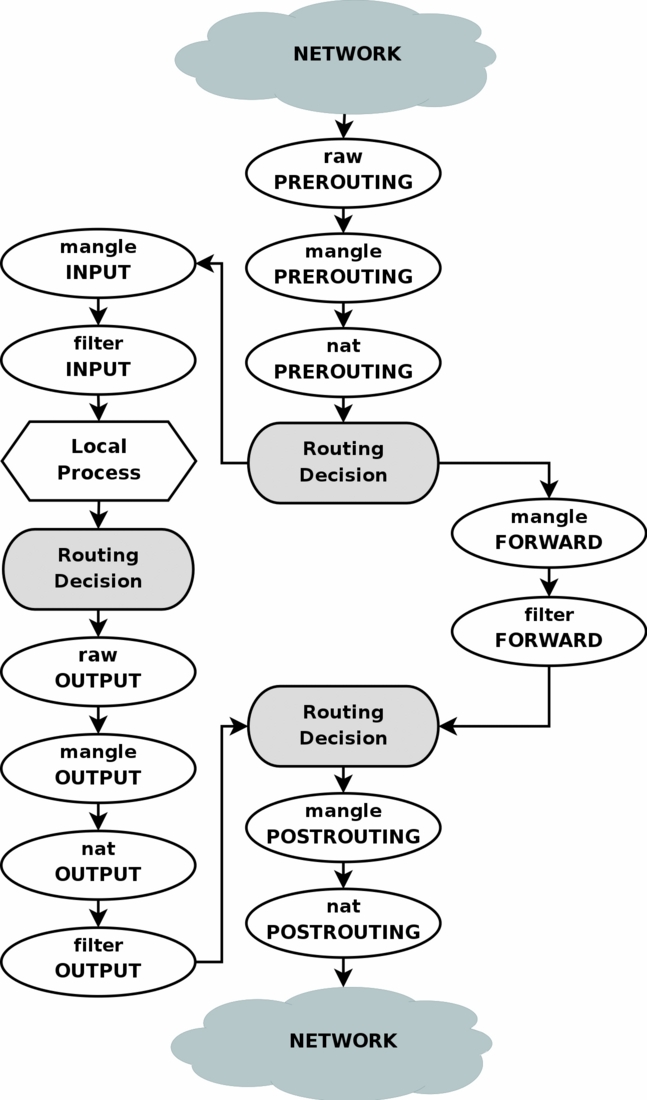
假若我们有一个数据包进入第一个路由判决之后,发现其目的地址并不是本主机,那么其将会被路由到FORWARD链,否则数据则会被发送到本主机上的INPUT链.
下面我们再给出一张简化版本示意图:
2.2 Mangle表
该表的主要用途就是对数据包进行伪装。换句话说,你可以mangle表中自由的使用mangle targets,来改变数据包的TOS等字段。
注意: 强烈建议不要使用此表来做任何的Filtering,DNAT、SNAT或者Masquerading通常也不会工作在此表
如下的一些targets只有在mangle表中才是有效的,它们不可以被用在mangle表之外的其他表中:
-
TOS: 本target会被用于设置或修改数据包的TOS字段。这可以被用于为数据包的路由建立相应的策略。值得注意的是本target并没有被很好的实现,建议不要使用
-
TTL: 本target被用于修改数据包的TTL字段。我们可以将数据包的TTL字段设置为一个特定的值。
-
MARK: 本target会被用于为packet设置特定的mark值。这些
标记(marks)可以被iproute2应用程序所识别,并以此来做不同的路由。我们也可以基于这些标记(marks)来做带宽限制和分类队列(Class Based Queuing) -
SECMARK: 本target可以用于为单个的数据包设置
安全上下文标记(security context marks),这些标记可以被SELinux与其他的一些安全系统所识别 -
CONNSECMARK: 本target被用于从单个数据包中复制
安全上下文到整个连接(connection)中(或者相反方向的复制),这些标记可以被SELINUX与其他一下安全系统所识别,从而可以在整个Connection级别获得更好的安全性。
2.3 Nat表
本表只会被用于NAT数据包。换句话说,它只能被用于转换数据包的源地址或者目的地址。值得注意的是,一个数据流中只有第一个数据包会命中本表,之后该数据流中的所有数据包将会自动的获得与第一个数据包相同的操作(action)。实际的targets可能会做如下一些类型的事情:
-
DNAT: 本target的使用场景通常为————你有一个公网IP地址,然后需要将相应的访问请求转发到防火墙之后的其他主机上(如DMZ区域的主机)。换句话说,我们修改数据包的目的地址,然后重新路由到目标主机。
-
SNAT: 本target主要被用于修改数据包源地址。大部分情况下你会隐藏本地网络或DMZ网络。一个很好的例子就是,我们只知道一个防火墙的外部IP地址,但是需要将我们本地网络的IP地址替换为该外部地址。通过本target,防火墙将会自动的对数据包进行SNAT与De-SNAT操作,这样就使得可以从本地局域网向外网Internet建立连接。
-
MASQUERADE: 本target的用法与
SNAT很相似,只是MASQUERADE target会耗费等多的一些资源来进行计算。原因在于,每当一个数据包命中本target,其都会自动的检查所使用的IP地址,而不是直接像SNAT那样仅仅使用一个单独的配置IP。MASQUERADE target使得其能够与DHCP搭配来工作。 -
REDIRECT
2.4 Raw表
raw表主要被用于做一件事情,就是在数据包上设置标志,使得其不会被连接跟踪系统(connection tracking system)所处理。这可以通过使用NOTRACK target来完成。假如某一个连接匹配了NOTRACK target,则conntrack系统将不会对该连接进行跟踪。因为raw表是唯一一个在连接跟踪之前的表,如果没有本表的话,将不能对连接跟踪做任何的控制。
Raw table只有PREROUTING以及OUTPUT两个链。
注意: 1. 如果要让此表工作,则必须要加载iptable_raw模块。假如iptables以 '-t raw' 选项启动的话,若系统中有iptable_raw模块的话, 则该模块会被自动加载 2. raw表是iptables及内核中相对新的一个东西,在Linux2.6内核版本之前可能不能够使用
2.5 Filter表
filter表主要被用于对数据包进行过滤。我们可以匹配数据包,然后对其进行过滤。这是我们通常对数据包进行操作的地方,在此我们检查数据包的相关内容来对数据包进行DROP或者ACCEPT。当然我们可以在此表之前进行过滤,但是通常不会这么做,因为本表才是专门设计被用来过滤数据包的。几乎所有的targets都可以在本表中被使用。
filter表是进行数据包过滤的主要地方。
2.6 用户自定义的chain
假如一个数据包进入了filter table中的INPUT链中,我们可以指定一个jump规则让其跳到同一个表的不同链中。这条新的链(chain)必须是用户指定的,不能是系统内置的链,比如INPUT、FORWARD链。假如我们将chain看成是指向规则的指针,那么该指针从上到下将一条一条规则(rule)连接起来,直到遇到一个target或者main chain为止(此时,将会使用内置链的默认策略)。
假如一条规则匹配指向了一条用户自定链(userspecified chain),则指针会跳转到该链,然后开始从上到下的遍历该链。例如,上图中从chain1的规则3跳转到了chain2.
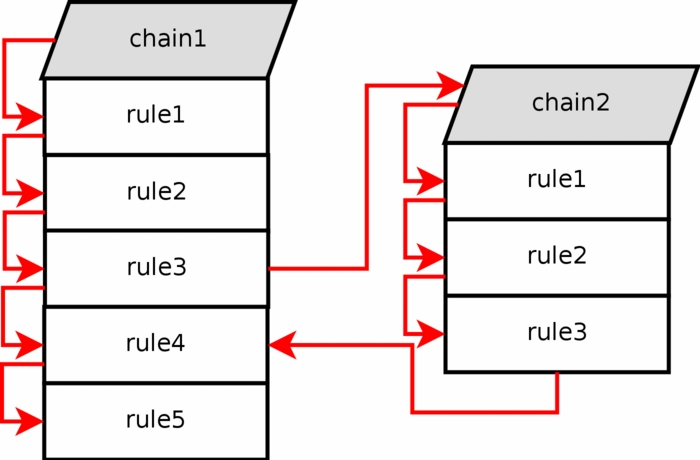
注意: Userspecified chain在链尾不能有默认的策略,只有内置链才可以有。我们通常可以在用户自定义链的末尾添加一条单独的规则,使 其不会有任何的匹配,这样看起来就像是一条默认的策略。假如在userspecified 链中没有任何规则匹配到,则默认的行为将会跳回到原来的链中。 如上图所示,从chain2的rule3又跳回到了chain1的rule4。
[参看]
