kafka体系架构及集群环境的搭建
本文主要介绍一下如下两个方面的内容:
-
kafka体系架构
-
kafka集群环境的搭建
1. kafka体系架构
kafka是一个分布式的、基于发布订阅的消息系统,主要解决应用解耦、异步消息、流量削峰等问题。
1.1 发布订阅模型
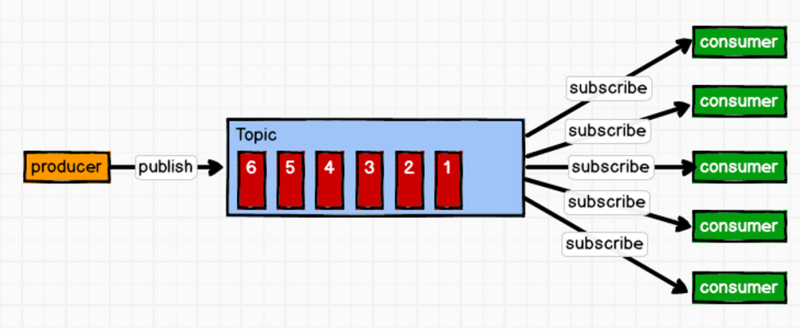
消息生产者将消息发布到topic中,同时有多个消息消费者订阅该消息,消费者消费数据之后,并不会清除消息。属于一对多的模式,如下图所示:
1.2 系统架构
如下是kafka的一个整体架构:
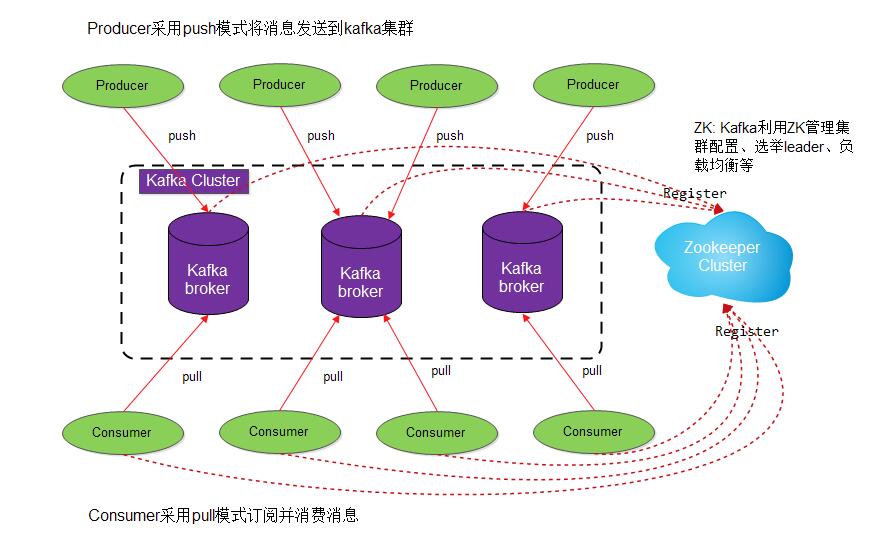
上图中标识了一个kafka体系架构,包括若干producer、broker、consumer和一个zookeeper集群。如下再贴出两张带有topic和partition的架构图:
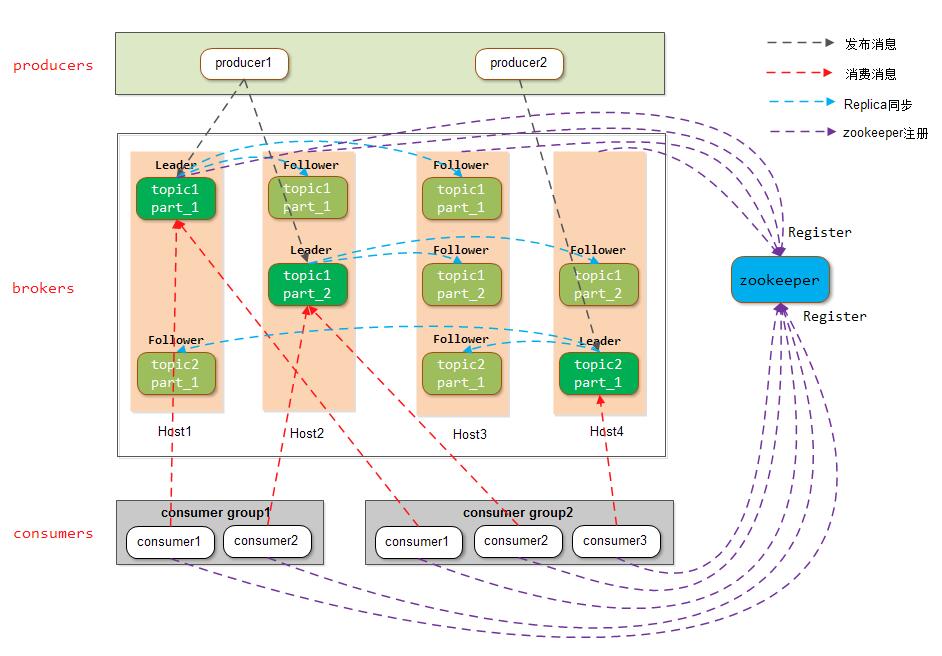
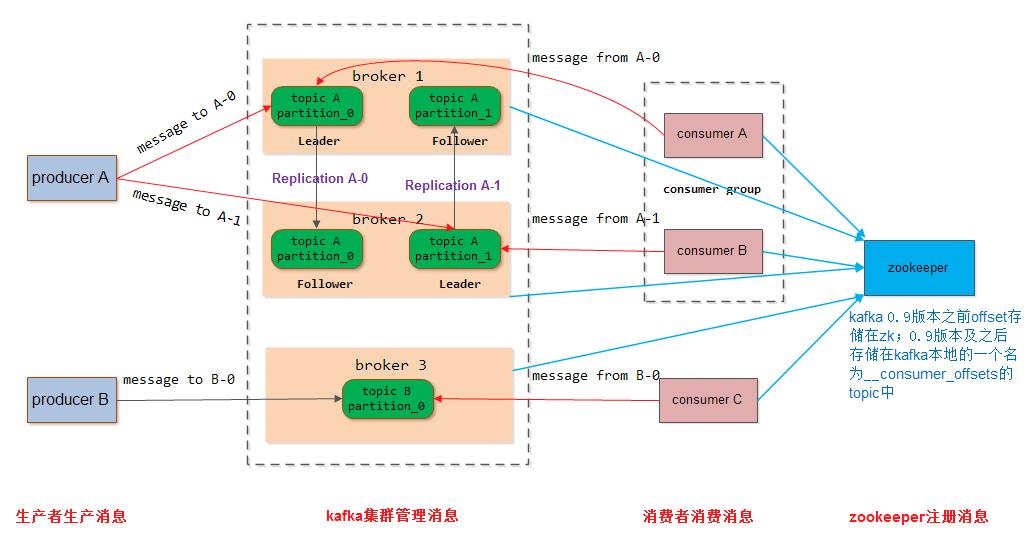
下面介绍一下各个角色:
1) Producer
消息生产者,将消息push到kafka集群中的broker。
2) Consumer
消息消费者,从kafka集群中pull消息,消费消息。
3) Consumer Group
消费组,由一到多个consumer组成,每个consumer都属于一个consumer group。消费组在逻辑上是一个订阅者。消费组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费组之间互不影响。即每条消息只能被consumer group中的一个consumer,但是可以被多个consumer group消费。这样就实现了单播和多播。
4) Broker
一台kafka服务器就是一个Broker,一个集群由多个Broker组成,每个Broker可以容纳多个topic。
5) Topic
消息的类别或主题,逻辑上可以理解为队列。Producer只关注消息到哪个Topic,Consumer只关注订阅了哪个Topic。
6) Partition
负载均衡与扩展性考虑,一个Topic可以分为多个Partition,物理存储在kafka集群中的多个Broker上。从可靠性上考虑,每个partition都会有备份Replica。
7) Replica
Partition的副本,为了保证集群中某个节点发生故障时,该节点上的Partition数据不会丢失,且kafka仍能继续工作,所以kafka提供了副本机制。一个Topic的每个Partition都有若干个副本: 一个Leader和若干个Follower。
8) Leader
Replica的主角色,Producer与Consumer只跟Leader进行交互。
9) Follower
Replica的从角色,实时从Leader中同步数据,保持和Leader数据的同步。Leader发生故障时,某个Follower会变成新的Leader。
10) Controller
kafka集群中的其中一台服务器,用来进行Leader election以及各种Failover(故障转移)
11) Zookeeper
kafka通过zookeeper存储集群的meta信息。
1.3 Topic和Partition
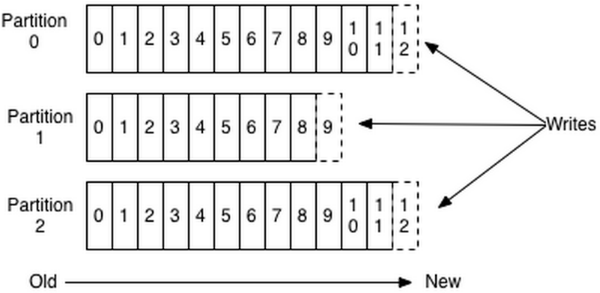
一个topic可以认为是一类信息,逻辑上的队列,每条消息都要指定topic。为了使得kafka的吞吐量可以线性提高,物理上将topic分成一个或多个partition。每个partition在存储层面是append log文件,消息push进来后,会被追加到log文件的尾部。每条消息在文件中的位置称为offset(偏移量),offset是一个long型数字,唯一的标识一条信息。因为每条信息都追加到partition的尾部,所以属于磁盘的顺序写,效率很高。如图:
1.4 网络模型
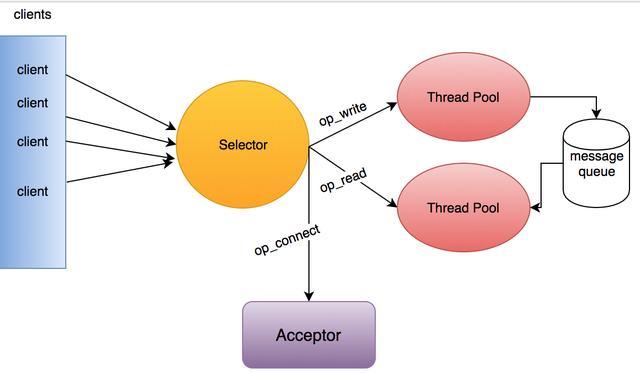
kafka的网络模型基于reactor模型。以下来自:消息中间件—简谈Kafka中的NIO网络通信模型
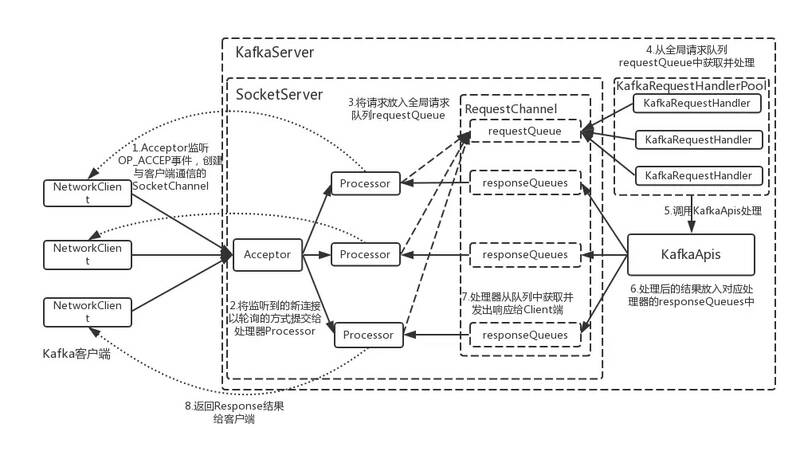
1) Acceptor
1个接收线程,负责监听新的连接请求,同时注册OP_ACCEPT事件,将新的连接按照round robin方式交给对应的Processor线程处理。
2) Processor
N个处理线程,其中每个Processor都有自己的selector,它会向Acceptor分配的SocketChannel注册相应的OP_READ事件,N的大小由num.network.threads决定;
3) KafkaRequestHandler
M个处理线程,包含在线程池KafkaRequestHandlerPool内部,从RequestChannel的全局请求队列requestQueue中获取请求数据并交给KafkaApis处理,M的大小由num.io.threads决定。
4) RequestChannel
其为Kafka服务端的请求通道,该数据结构中包含了一个全局的请求队列requestQueue和多个与Processor处理器相对应的响应队列responseQueue,提供给Processor与请求处理线程KafkaRequestHandler、Processor与KafkaApis交换数据的地方。
5) NetworkClient
其底层是对Java NIO进行相应的封装,位于kafka的网络接口层。Kafka消息生产者对象KafkaProducer的send()方法主要调用NetworkClient完成消息发送。
6) SocketServer
其是一个NIO的服务,它同时启动一个Acceptor接收线程和多个Processor处理线程。提供了一种典型的reactor多线程模式,将接收客户端请求和处理请求相分离。
7) KafkaServer
代表了一个Kafka Broker实例。其startup方法为实例启动的入口。
8) KafkaApis
Kafka的业务逻辑处理API,负责处理不同类型的请求。比如,“发送消息”、“获取消息偏移量offset”和“处理心跳请求”等。
2. kafka集群环境的搭建
这里我们介绍一下kafka集群环境的搭建。
2.1 前提条件
1) 部署kafka集群搭建一般需要至少3台服务器,并且通常为奇数台
2) kafka的安装需要java环境(JDK1.8)
3) zookeeper集群环境的搭建
4) kafka集群环境的搭建。这里我们会在如下3台机器上分别部署kafka
kafka服务器名 IP地址 域名
--------------------------------------------------------------------------------------
kafka0 192.168.79.128 (未设置)
kafka1 192.168.79.129 (未设置)
kafka2 192.168.79.131 (未设置)
5) hosts配置(可选)
如果我们要采用域名的话,我们可以修改/etc/hosts文件,在其中加入类似如下:
# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.79.128 kafka0.cn 192.168.79.129 kafka1.cn 192.168.79.131 kafka2.cn
注: 这里我们暂未采用域名
2.2 详细步骤
java环境搭建
关于Linux下java环境的搭建,这里我们不做介绍。这里我们安装的JDK版本是:
# javac -version javac 1.8.0_231
zookeeper集群环境的搭建
关于zookeeper集群环境的搭建及验证,在其他章节我们已经有相关详细说明,这里不再赘述。这里我们安装的zookeeper版本是:
# ls apache-zookeeper-3.5.6-bin apache-zookeeper-3.5.6-bin.tar.gz
kafka集群安装
1) 下载kafka安装包
这里我们下载当前最新版本的kafka二进制安装包:kafka_2.13-2.4.0
# mkdir /app/kafka # cd /app/kafka # wget http://mirror.bit.edu.cn/apache/kafka/2.4.0/kafka_2.13-2.4.0.tgz # ls kafka_2.13-2.4.0.tgz
下载完成之后,我们解压:
# tar -zxvf kafka_2.13-2.4.0.tgz # cd kafka_2.13-2.4.0/ # ls bin config libs LICENSE NOTICE site-docs # ls bin/ connect-distributed.sh kafka-console-producer.sh kafka-log-dirs.sh kafka-server-start.sh windows connect-mirror-maker.sh kafka-consumer-groups.sh kafka-mirror-maker.sh kafka-server-stop.sh zookeeper-security-migration.sh connect-standalone.sh kafka-consumer-perf-test.sh kafka-preferred-replica-election.sh kafka-streams-application-reset.sh zookeeper-server-start.sh kafka-acls.sh kafka-delegation-tokens.sh kafka-producer-perf-test.sh kafka-topics.sh zookeeper-server-stop.sh kafka-broker-api-versions.sh kafka-delete-records.sh kafka-reassign-partitions.sh kafka-verifiable-consumer.sh zookeeper-shell.sh kafka-configs.sh kafka-dump-log.sh kafka-replica-verification.sh kafka-verifiable-producer.sh kafka-console-consumer.sh kafka-leader-election.sh kafka-run-class.sh trogdor.sh # ls config/ connect-console-sink.properties connect-file-sink.properties connect-mirror-maker.properties log4j.properties tools-log4j.properties connect-console-source.properties connect-file-source.properties connect-standalone.properties producer.properties trogdor.conf connect-distributed.properties connect-log4j.properties consumer.properties server.properties zookeeper.properties
2) 创建kafka日志目录
kafka日志目录用于存放kafka的topic数据、日志数据等:
# mkdir -p /opt/kafka/logs # ls /opt/kafka
3) 修改kafka配置文件
我们修改config/server.properties配置文件,主要是修改如下几项:
-
broker.id: 集群中每一个broker的ID都必须唯一
-
listeners: broker所监听的地址
-
log.dirs: kafka数据存储位置
-
num.partitions: 所创建的topic的默认分区数。默认配置的分区数是1。虽然
一般我们在创建topic时都会自行指定分区数和副本数,但这里我们最好还是改成3,因为有一些topic可能并不直接由用户创建(如consumer消费时的offset会存放到一个名叫__consumer_offsets的topic中,该topic由kafka自动创建),为了保证数据的可靠性,我们对默认值进行修改。 -
zookeeper.connect: zookeeper集群的地址
-
auto.create.topics.enable: 是否允许自动创建topic
其他暂时都可以采用默认值。注: 默认配置中num.partitions=1,说明默认的分区数是1,通常我们并不需要进行修改,因为。
如下是各节点kafka的配置:
- kafka0
broker.id=0 listeners=PLAINTEXT://192.168.79.128:9092 auto.create.topics.enable=false log.dirs=/opt/kafka num.partitions=3 zookeeper.connect=192.168.79.128:2181,192.168.79.129,192.168.79.131
修改完成后类似于如下:
# cat config/server.properties | grep -v ^# | grep -v ^$
broker.id=0
listeners=PLAINTEXT://192.168.79.128:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/kafka
num.partitions=3
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
auto.create.topics.enable=false
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.79.128:2181,192.168.79.129:2181,192.168.79.131:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0- kafka1
broker.id=0 listeners=PLAINTEXT://192.168.79.128:9092 auto.create.topics.enable=false log.dirs=/opt/kafka/logs num.partitions=3 zookeeper.connect=192.168.79.128:2181,192.168.79.129,192.168.79.131
- kafka2
broker.id=2 listeners=PLAINTEXT://192.168.79.128:9092 auto.create.topics.enable=false log.dirs=/opt/kafka/logs num.partitions=3 zookeeper.connect=192.168.79.128:2181,192.168.79.129,192.168.79.131
4) 启动kafka
- 以前台方式启动
# bin/kafka-server-start.sh config/server.properties [2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties) [2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
- 以后台方式启动
# nohup bin/kafka-server-start.sh config/server.properties >/dev/null 2>&1 &
启动后,我们看到在$KAFKA_HOME/logs目录下会有很多日志:
# ls logs/ controller.log kafka-authorizer.log kafka-request.log kafkaServer-gc.log.0.current log-cleaner.log server.log state-change.log
要查看kafka server的启动运行信息可以看server.log日志。
同时在kafka数据存储目录/opt/kafka/logs下会有如下文件:
# ls -al /opt/kafka/logs total 4 drwxr-xr-x 2 root root 187 Dec 25 00:11 . drwxr-xr-x 3 root root 18 Dec 25 00:11 .. -rw-r--r-- 1 root root 0 Dec 25 00:11 cleaner-offset-checkpoint -rw-r--r-- 1 root root 0 Dec 25 00:11 .lock -rw-r--r-- 1 root root 0 Dec 25 00:11 log-start-offset-checkpoint -rw-r--r-- 1 root root 88 Dec 25 00:11 meta.properties -rw-r--r-- 1 root root 0 Dec 25 00:11 recovery-point-offset-checkpoint -rw-r--r-- 1 root root 0 Dec 25 00:11 replication-offset-checkpoint
5) 停止kafka
执行如下命令停止kafka:
# bin/kafka-server-stop.sh
2.3 kafka的测试
1) 创建topic
如下我们在kafka0上创建测试topic: test-ken-io,这里我们指定3个副本,1个分区:
# bin/kafka-topics.sh --create --bootstrap-server 192.168.79.128:9092 --replication-factor 3 --partitions 1 --topic test-ken-io
创建完毕之后,通过执行如下命令查看是否创建成功:
# bin/kafka-topics.sh --describe --bootstrap-server 192.168.79.128:9092
Topic: test-ken-io PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test-ken-io Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
# bin/kafka-topics.sh --list --bootstrap-server 192.168.79.128:9092
test-ken-io
上面我们看到成功创建了test-ken-io这个topic,该topic具有3个副本,1个分区,即partition 0分区,该分区的的Leader是broker0。通过Isr: 1,2,0我们知道,partition 0分区的其他两个副本均已同步上Leader。下面对--describe选项的输出的一些字段做一个简单的介绍:
-
Leader: 表明该broker节点负责指定分区的所有读写操作。每一个broker节点都有可能会被随机选择为Leader。
-
Replicas: 某一个partition的所有副本节点。副本节点有可能当前并不是处于alive状态,因此单纯通过本选项是不知道一个节点是否是存活的。
-
Isr(In-sync Replica): 处于
in-sync状态的副本集,其是Replicas的一个子集。该集合中的元素是处于alive状态,并且当前保持着与Leader的同步
另外还可以通过如下来创建topic:
# bin/kafka-topics.sh --create --zookeeper 192.168.79.128:2181,192.168.79.129:2181,192.168.79.131:2181 --replication-factor 3 --partitions 1 --topic test2-ken-io
Created topic test2-ken-io.
# bin/kafka-topics.sh --describe --zookeeper 192.168.79.128:2181,192.168.79.129:2181,192.168.79.131:2181
Topic: test-ken-io PartitionCount: 1 ReplicationFactor: 3 Configs:
Topic: test-ken-io Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 0,2,1
Topic: test2-ken-io PartitionCount: 1 ReplicationFactor: 3 Configs:
Topic: test2-ken-io Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
# bin/kafka-topics.sh --list --zookeeper 192.168.79.128:2181,192.168.79.129:2181,192.168.79.131:2181
test-ken-io
test2-ken-io
上面两种方法之间有一些微妙的区别。从kafka的版本演进历程来看,早期的kafka客户端API都是通过zookeeper地址来访问kafka的,而目前新版本的kafka都是直接通过broker地址来访问的,早已经弃用了通过zookeeper来访问的方法。
2) 创建producer
我们在broker 0上为test-ken-io创建producer,并产生一些message:
# bin/kafka-console-producer.sh --broker-list 192.168.79.128:9092 --topic test-ken-io
>test 0
>test 1
>test 2
>test 3
>test 43) 创建consumer
我们在broker 1上为test-ken-io创建consumer:
# bin/kafka-console-consumer.sh --bootstrap-server 192.168.79.129:9092 --topic test-ken-io --from-beginning test 0 test 1 test 2 test 3 test 4
注: 上面并未指明consumer group,在不同窗口同时执行会创建不同的匿名消费组,可以同时消费test-ken-io中的消息。并且这里创建的consumer group是临时的,当bin/kafka-console-consumer.sh执行退出后,对应的消费组也会在一定时间后被自动删除。
如下我们也可以在创建consumer时指定消费组:
# bin/kafka-console-consumer.sh --bootstrap-server 192.168.79.129:9092 --topic test-ken-io --from-beginning --consumer-property group.id=test-group1 test 0 test 1 test 2 test 3 test 4
注: 此种方式创建的consumer group是永久的(没明确证据!)。
4) 查询consumer消费信息
我们知道在kafka 0.9版本之后,kafka的consumer group和offset信息就不保存在zookeeper中了。因此我们要查看所有消费组,我们得先区分kafka版本:
- 0.9版本之前kafka查看所有消费组
# ./kafka-consumer-groups.sh --zookeeper 192.168.79.128:2181 --list
- 0.9及之后版本kakfa查看所有消费组
//# kafka-consumer-groups.sh --new-consumer --bootstrap-server 192.168.79.128:9092 --list //说明2.4.0版本已经不支持--new-consumer选项 # bin/kafka-consumer-groups.sh --bootstrap-server 192.168.79.128:9092 --list console-consumer-54559 console-consumer-97891 test-group2 test-group1 console-consumer-81258
在我们知道consumer group之后,我们就可以查询对应group下某个topic的消息消费情况。同样,针对kafka版本的不同,也有不同的查看方式:
- 0.9版本之前kafka查看consumer的消费情况
# bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper 192.168.79.128:2181 --group logstash-new
- 0.9及之后版本kakfa查看consumer消费情况
//# bin/kafka-consumer-groups.sh --new-consumer --bootstrap-server 192.168.79.128:9092 --describe --group console-consumer-99512 //说明2.4.0版本已经不支持--new-consumer选项 # bin/kafka-consumer-groups.sh --bootstrap-server 192.168.79.128:9092 --describe --group test-group1 Consumer group 'test-group1' has no active members. GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID test-group1 test-ken-io 0 10 10 0 - - -
5) 测试容错性
通过上面我们知道test-ken-io有3个副本,1个分区partition 0,且该分区的Leader是broker 1。这里我们通过如下命令将broker1 kill掉:
# ps -aux | grep kafka root 90523 2.6 19.9 5207444 772552 pts/0 Sl Dec25 25:54 /usr/java/jdk1.8.0_131//bin/java -Xmx1G ... # kill -9 90523
重新执行如下命令看当前test-ken-io这个topic的partition 0的Leader:
# bin/kafka-topics.sh --describe --bootstrap-server 192.168.79.128:9092
Topic: test-ken-io PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test-ken-io Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
这里我们看到Leader变成了broker 2,且Isr也变成了2,0。
然后我们再用producer发送消息,用consumer消费消息,可以看到均能够正常运行。
6) 删除topic
执行如下命令删除topic:
# bin/kafka-topics.sh --delete --bootstrap-server 192.168.79.128:9092 --topic test2-ken-io
或通过如下命令:
# bin/kafka-topics.sh --delete --zookeeper 192.168.79.128:2181,192.168.79.129:2181,192.168.79.131:2181 --topic test2-ken-io Topic test2-ken-io is marked for deletion. Note: This will have no impact if delete.topic.enable is not set to true.
注: 通过上面的命令,(随kafka版本不同)可能并没有真正彻底的将该topic的相关信息移除。要想彻底删除,请参看相关文章。
3. 设置kafka日志输出路径
我们知道在kafka配置文件config/server.properties中有log.dirs这一配置选项,但该选项并不是用来配置kafka日志输出的保存位置,而是用来配置kafka消息存储的位置。
默认kafka运行的时候都会通过log4j打印很多日志文件,比如server.log、controller.log、state-change.log等,而且都会将其输出到$KAFKA_HOME/logs/目录下,这样很不利于线上运维,因为经常容易出现压爆文件系统的情况,一般kafka安装的盘都比较小,因此需要将日志数据存放到另一个或多个更大空间的分区盘。
具体方法是,打开$KAFKA_HOME/bin/kafka_run_class.sh,找到base_dir=$(dirname $0)/..这一行,然后在下面加入:
base_dir=$(dirname $0)/.. LOG_DIR=/web/kafka/log
这样就会把日志存放到所指定的位置了。
4. 补充: kafka的版本号
在kafka的下载页面我们看到如下:
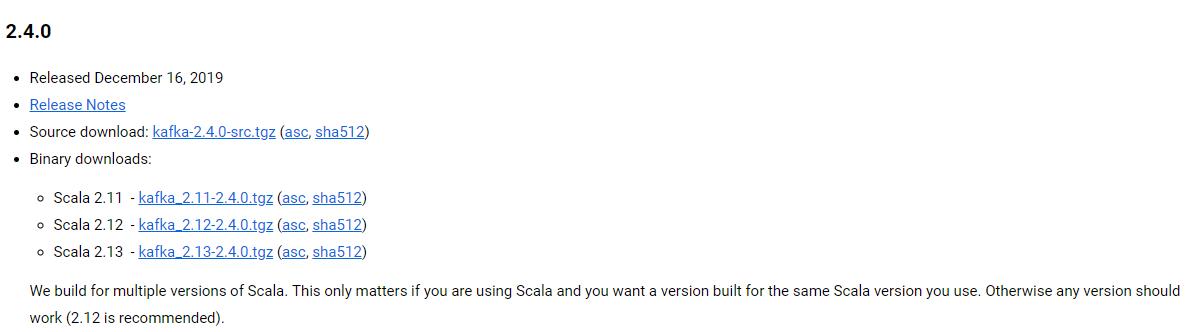
当前Apache Kafka的最新版本是2.4.0。但是当我们看到上图中Scala 2.11 - kafka_2.11-2.4.0.tgz时,我们可能会有些疑惑,难道kafka的版本号不是2.11吗?其实不然,前面的版本号是编译kafka源代码的Scala编译器的版本。
注:kafka服务器端的代码完全由Scala语言编写,Scala同时支持面向对象编程和函数式编程,用Scala写的源代码编译之后也是普通
.class文件,因此我们说Scala是JVM系的语言,它的很多设计思想都是为人称道的。
上面Scala 2.11 - kafka_2.11-2.4.0.tgz中2.4.0才是真正的kafka版本号。那么这个2.4.0又表示什么呢?最前面的2表示大版本号,即major version;中间的4表示表示的是小版本号或者次版本号,即minor version;最后的0表示修订版本号,也就是patch号。kafka社区在发布1.0.0版本后特意写过一篇文章,宣布kafka版本命名规则正式从4位演进到3位,比如0.11.0.0版本就是4位版本号
3.1 kafka版本演进
kafka目前总共演进了7个大版本,分别是0.7、0.8、0.9、0.10、0.11、1.0和2.0,其中的小版本和patch版本很多。哪些版本引入了哪些重大的功能改进?建议你最好做到如数家珍,因为这样不仅令你在和别人交谈时显得很酷,而且如果你要向架构师转型或者已然是架构师,那么这些都是能够帮助你进行技术选型、架构评估的重要依据。
我们先从0.7版本说起,实际上也没有太多可说的,这是最早开源时的上古版本了。这个版本只提供了最基础的消息队列功能,甚至连副本机制都没有,我实在想不出来有什么理由你要使用这个版本,因此如果有人要向你推荐这个版本,果断走开好了。
kafka从0.7时代演进到0.8之后正式引入了副本机制,至此kafka成为了一个真正意义上完备的分布式、高可靠消息队列解决方案。有了副本备份机制,kafka就能够比较好地做到消息无丢失。那时候生产和消费消息使用的还是老版本客户端的api,所谓老版本是指当你使用它们的api开发生产者和消费者应用时,你需要指定zookeeper的地址而非broker的地址。
如果你现在尚不能理解这两者的区别也没关系,我会在后续继续介绍它们。老版本的客户端有很多的问题,特别是生产者api,它默认使用同步方式发送消息,可以想到其吞吐量一定不会太高。虽然它也支持异步的方式,但实际场景中消息有可能丢失,因此0.8.2.0版本社区引入了新版本producer api,即需要指定broker地址的producer。
据我所知,国内依然有少部分用户在使用0.8.1.1、0.8.2版本。我的建议是尽量使用比较新的版本,如果你不能升级大版本,我也建议你至少要升级到0.8.2.2这个版本,因为该版本中老版本消费者的api是比较稳定的。另外即使升级到了0.8.2.2,也不要使用新版本consumer api,此时它的bug还非常的多。
时间来到了2015年11月,社区正式发布了0.9.0.0版本,在我看来这是一个重量级的大版本更迭,0.9大版本增加了基础的安全认证/权限功能,同时使用java重写了新版本消费者的api,另外还引入了kafka connect组件用于实现高性能的数据抽取。如果这么眼花缭乱的功能你一时无暇顾及,那么我希望你记住这个版本另一个好处,那就是新版本的producer api在这个版本中算比较稳定了。如果你使用0.9作为线上环境不妨切换到新版本producer,这是此版本一个不太为人所知的优势。但和0.8.2引入新api问题类似,不要使用新版本的consumer api,因为bug超级多,绝对用到你崩溃。即使你反馈问题到社区,社区也不管的,它会无脑的推荐你升级到新版本再试试,因此千万别用0.9新版本的consumer api。对于国内一些使用比较老的CDH的创业公司,鉴于其内嵌的就是0.9版本,所以要格外注意这些问题。
0.10.0.0是里程碑式的大版本,因为该版本引入了kafka streams。从这个版本起,kafka正式升级成为分布式流处理平台,虽然此时的kafka streams还不能上线部署使用。0.10大版本包含两个包含两个小版本:0.10.1和0.10.2,它们的主要功能变更都是在kafka streams组件上。如果把kafka作为消息引擎,实际上该版本并没有太多的功能提升。不过在我的印象中,自从0.10.2.2版本起,新版本consumer api算是比较稳定了。如果你依然在使用0.10大版本,那么我强烈建议你至少升级到0.10.2.2然后再使用新版本的consumer api。还有个事情不得不提,0.10.2.2修复了一个可能导致producer性能降低的bug。基于性能的缘故你也应该升级到0.10.2.2。
在2017年6月,社区发布了0.11.0.0版本,引入了两个重量级的功能变更:一个是提供幂等性producer api;另一个是对kafka消息格式做了重构。
-
前一个好像更加吸引眼球一些,毕竟producer实现幂等性以及支持事务都是kafka实现流处理结果正确性的基石。没有它们,kafka streams在做流处理时无法像批处理那样保证结果的正确性。当然同样是由于刚推出,此时的事务api有一些bug,不算十分稳定。另外事务api主要是为kafka streams应用服务的,实际使用场景中用户利用事务api自行编写程序的成功案例并不多见
-
第二个改进是消息格式的变化。虽然它对用户是透明的,但是它带来的深远影响将一直持续。因为格式变更引起消息格式转换而导致的性能问题在生产环境中屡见不鲜,所以一定要谨慎对待0.11这个版本的变化。不得不说的是,在这个版本中,各个大功能组件都变得相当稳定了,国内该版本的用户也很多,应该算是目前最主流的版本之一了。也正是因为这个缘故,社区为0.11大版本特意推出了3个patch版本,足见它的受欢迎程度。我的建议是,如果你对1.0版本是否适用于线上环境依然感到困惑,那么至少将你的环境升级到0.11.0.3,因为这个版本的消息引擎功能已经非常完善了。
最后合并说一下1.0和2.0版本吧,因为在我看来这两个大版本主要还是kafka streams的各种改进,在消息引擎方面并未引入太多的重大功能特性。kafka streams的确在这两个版本有着非常大的变化,也必须承认kafka streams目前依然还在积极地发展着。如果你是kafka streams的用户,只要选择2.0.0版本吧。
去年8月国外出了一本书叫做kafka streams in action,中文译名:kafka streams实战,它是基于kafka streams1.0版本撰写的,但是用2.0版本去运行书中的很多例子,居然很多都已经无法编译了,足见两个版本的差别之大。不过如果你在意的依然是消息引擎,那么这两个大版本都是可以用于生产环境的。
最后还有个建议,不论你使用的是哪个版本,都请尽量保持服务器端版本和客户端版本一致,否则你将损失很多kafka为你提供的性能优化收益。

[参考]
