数据结构之图的遍历
本章我们介绍一下图的两种遍历方式:
-
深度优先搜索
-
广度优先搜索
1. 图的遍历
和树的遍历类似,在此,我们希望从图中某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次。这一过程就叫做图的遍历(Traversing Graph)。图的遍历算法是求解图的连通性问题、拓扑排序和求关键路径等算法的基础。
然而,图的遍历要比树的遍历复杂得多。因为图的任一顶点都可能和其余的顶点相邻接,所以在访问了某个顶点之后,可能沿着某条路径搜索之后,又回到该顶点上。例如下图中的G2,
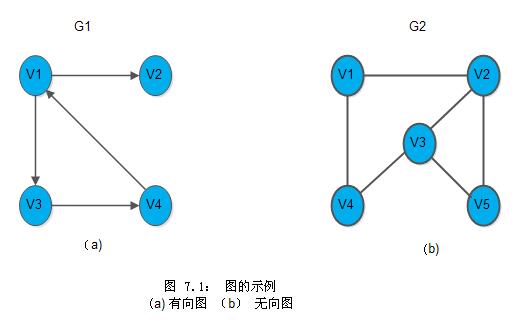
由于图中存在回路,因此在访问了v1,v2,v3,v4之后,沿着边<v4,v1>又可访问到v1。为了避免同一顶点被多次访问,在遍历图的过程中,必须记下每个已访问过的顶点。为此,我们可以设一个辅助数组visited[0..n-1],它的初始值置为“假”或者零,一旦访问了顶点vi,便置visited[i]为“真”或者为被访问时的次序号。
通常有两条遍历图的路径: 深度优先搜索和广度优先搜索。它们对无向图和有向图都适用。
2. 深度优先搜索
深度优先搜索(Depth First Search)遍历类似于树的先根遍历,是树的先根遍历的推广。
假设初始状态是图中所有顶点未曾被访问,则深度优先搜索可从图中某个顶点v出发,访问此顶点,然后依次从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和v有路径相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
以下图7.13(a)中无向图G4为例,深度优先搜索遍历图的过程如图7.13(b)所示。假设从顶点v1出发进行搜索,在访问了顶点v1之后,选择邻接点v2。因为v2未曾访问,
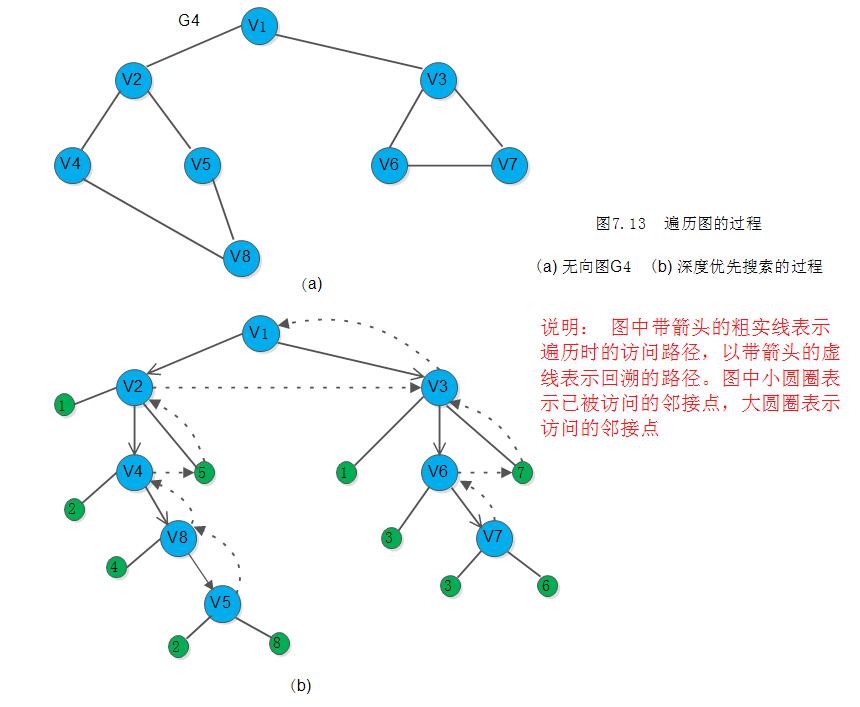
则从v2出发进行搜索。依次类推,接着从v4,v8,v5出发进行搜索。在访问了v5之后,由于v5的邻接点都已被访问,则搜索回到v8。由于同样的理由,搜索继续回到v4,v2直至v1,此时由于v1的另一个邻接点未被访问,则搜索又从v1到v3,再继续进行下去。由此,得到的顶点访问序列为:
v1 ——> v2 ———> v4 ——> v8 ——> v5 ——> v3 ——> v6 ——> v7显然,这是一个递归的过程。为了在遍历过程中便于区分顶点是否已被访问,需附设访问标志数组visited[0..n-1],其初值为“false”,一旦某个顶点被访问,则其相应的分量置为“true”。整个图的遍历如算法7.4和算法7.5所示,其中w>=0表示存在邻接点。
- 算法7.4
//---- 算法7.4 和 算法7.5 使用的全局变量
Boolean visited[MAX]; //访问标志数组
Status (*VisitFunc)(int v); //函数变量
//对图G作深度优先遍历
void DFSTraverse(Graph G, Status (*Visit)(int v))
{
VisitFunc = Visit; //使用全局变量VisitFunc,使DFS不必设函数指针参数
//访问标志数组初始化
for(v = 0; v < G.vexnum; v++)
visited[v] = FALSE;
for(v = 0; v < G.vexnum; v++)
{
if(!visited[v])
DFS(G, v); //对尚未访问的顶点调用DFS
}
}- 算法7.5
//从第v个顶点出发递归地深度优先遍历图G
void DFS(Graph G, int v)
{
visited[v] = TRUE;
VisitFunc(v); //访问第v个顶点
for(w = FirstAdjVex(G, v); w >= 0; w = NextAdjVex(G, v, w))
{
if(!visited[w])
DFS(G, w); //对v的尚未访问的邻接顶点w递归调用DFS
}
}分析上述算法,在遍历图时,对图中每个顶点至多调用一次DFS函数,因为一旦某个顶点被标志成已被访问,就不再从它出发进行搜索。因此,遍历图的过程实质上是对每个顶点查找其邻接点的过程。其耗费的时间则取决于所采用的存储结构。当用二维数组表示邻接矩阵作图的存储结构时,查找每个顶点的邻接点所需时间为O(n^2),其中n为图中顶点数。而当以邻接表作图的存储结构时,找邻接点所需时间为O(e),其中e为无向图中边的数或有向图中弧的数。由此,当以邻接表作存储结构时,深度优先搜索遍历图的时间复杂度为O(n+e)。
3. 广度优先搜索
广度优先搜索(Breadth First Search)遍历类似于树的按层次遍历的过程。
假设从图中某顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使“先被访问的顶点的邻接点” 先于 “后被访问的顶点的邻接点” 被访问,直至图中所有已被访问的顶点的邻接点都被访问到。若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。换句话说,广度优先搜索遍历图的过程是以v为起始点,由近至远,依次访问和v有路径相通且路径长度为1,2,…的顶点。例如,对下图G4进行广度优先搜索遍历的过程如下图7.13(c)所示:
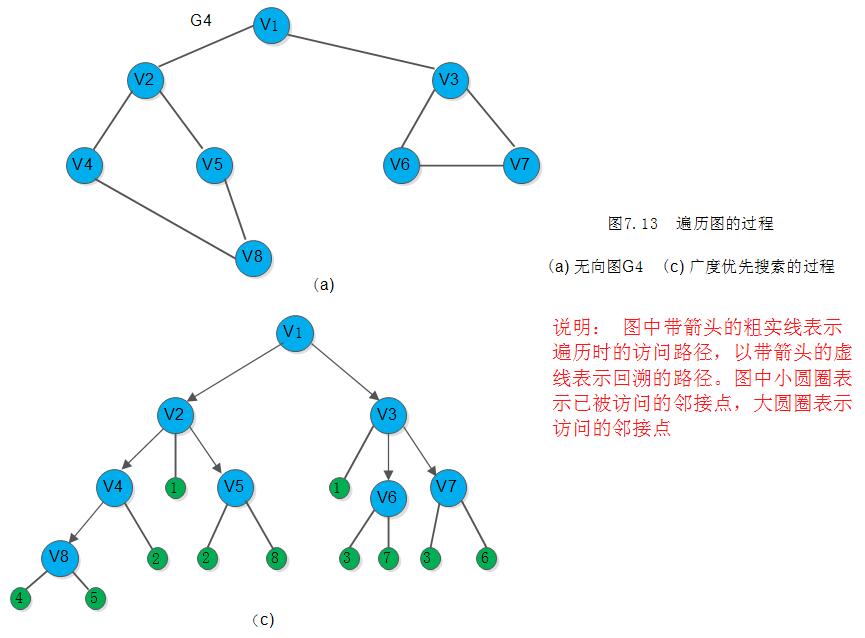
首先访问 v1 和 v1 的邻接点 v2 和 v3,然后依次访问 v2 的邻接点 v4 和 v5 以及 v3的邻接点 v6 和 v7,最后访问 v4 的邻接点v8。由于这些顶点的邻接点均已被访问,并且图中所有顶点都被访问,由此完成了图的遍历。得到的顶点访问序列为:
v1 ——> v2 ———> v3 ——> v4 ——> v5 ——> v6 ——> v7 ——> v8和深度优先搜索类似,在遍历的过程中也需要一个访问标志数组。并且,为了顺序访问路径长度为2、3、…的顶点,需附设队列以存储已被访问的路径长度为1、2、…的顶点。广度优先遍历的算法如算法7.6所示。
- 算法7.6
void BFSTraverse(Graph G , Status (*Visit)(int v))
{
//按广度优先非递归遍历图G。使用辅助队列Q和访问标志数组visited。
for(v = 0; v < G.vexnum; ++v)
visited[v] = FALSE;
InitQueue(Q);
for(v = 0; v < G.vexnum; ++v)
{
if(!visited[v]) //v尚未被访问
{
visited[v] = TRUE;
Visit(v);
EnQueue(Q, v); //v入队列
while(!QueueEmpty(Q))
{
DeQueue(Q, u); //队头元素出队列
for(w = FirstAdjVex(G, u); w >= 0; w = NextAdjVex(G, u, w))
{
if(!visited[w]) //w为u的尚未访问的邻接顶点
{
visited[w] = TRUE;
Visit(w);
EnQueue(Q, w);
}
}
}
}
}
}分析上述算法,每个顶点至多进一次队列。遍历图的过程实质上是通过弧或边找邻接点的过程,因此广度优先搜索遍历图的时间复杂度和深度优先搜索遍历相同,两者不同之处仅仅在于对顶点访问的顺序不同。
